 小白學大模型:什么是生成式人工智能?
小白學大模型:什么是生成式人工智能?
來源:Coggle數據科學
什么是生成式人工智能?
在過去幾年中,機器學習領域取得了迅猛進步,創造了人工智能的一個新的子領域:生成式人工智能。這些程序通過分析大量的數字化材料產生新穎的文本、圖像、音樂和軟件,我將這些程序簡稱為“GAIs”。
革命開始
第一波GAIs主要致力于進行自然語言對話。被稱為“大型語言模型”(LLMs)的這些模型已經展示出在各種任務上超凡的表現,擁有超越人類的能力,同時也顯示出對虛假、不合邏輯的傾向,以及表達虛假情感的傾向,比如對對話者表達愛意。它們用通俗的語言與用戶交流,并輕松解決各種復雜問題。
但這只是GAI革命的開始。支撐GAIs的技術是相當通用的,任何可以收集和準備進行處理的數據集,GAIs都能夠學習,這在現代數字世界是一個相對簡單的任務。
AGI vs GAI
AGI(人工通用智能)與GAI(生成式人工智能)不可混淆,AGI一直是科學家們世代追求的幻想,更不用說無數科幻電影和書籍了。值得注意的是,答案是“有條件的肯定”。在實際應用中,這些系統是多才多藝的“合成大腦”,但這并不意味著它們具有人類意義上的“思想”。它們沒有獨立的目標和欲望、偏見和愿望、情感和感覺:這些是獨特的人類特征。但是,如果我們用正確的數據對它們進行訓練并指導它們追求適當的目標,這些程序可以表現得好像具有這些特征一樣。
GAIs vs 早期構建智能機器
GAIs可以被指示執行(或至少描述如何執行)你幾乎能想到的任何任務……盡管它們可能會耐心地解釋,它們是萬事通,也是大多數領域的專家。
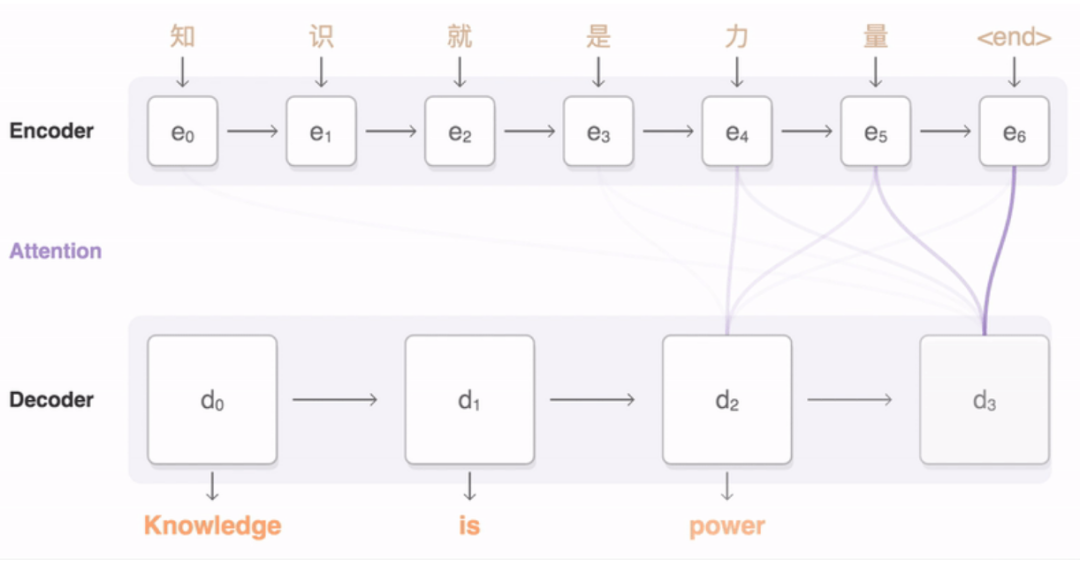
LLMs只是進行統計單詞預測,根據你提供的提示的上下文選擇下一個最有可能的單詞。但這種描述充其量是過于簡化了,并掩蓋了更深層次的真相。
LLMs是在大量信息的基礎上進行訓練的。它們處理并壓縮其龐大的訓練集,形成一種被稱為神經網絡的緊湊表示,但該網絡不僅僅代表單詞——它代表了它們的意義,以一種稱為嵌入的巧妙形式表達出來。
LLM了解其“世界”(在訓練階段);然后,它評估您提示的含義,選擇其答案的含義,并將該含義轉換為單詞。
人工智能的歷史
什么是人工智能?這是一個容易問出但難以回答的問題,有兩個原因。首先,對于智能是什么,人們幾乎沒有達成共識。其次,憑借目前的情況,很少有理由相信機器智能與人類智能有很大的關系,即使看起來很像。
人工智能(AI)有許多提議的定義,每個定義都有其自己的側重點,但大多數都大致圍繞著創建能夠表現出人類智能行為的計算機程序或機器的概念。學科的奠基人之一約翰·麥卡錫(John McCarthy)在1955年描述了這一過程,“就像制造一臺機器以人類的方式行為一樣”。術語“人工智能”起源于何處?“人工智能”一詞的首次使用可以歸因于一個特定的個人——約翰·麥卡錫(John McCarthy),他是一位1956年在新罕布什爾州漢諾威達特茅斯學院(Dartmouth College)的助理數學教授。與其他三位更資深的研究人員(哈佛大學的馬文·明斯基、IBM的內森·羅切斯特和貝爾電話實驗室的克勞德·香農)一起,麥卡錫提議在達特茅斯舉辦一次關于這個主題的夏季會議。早期人工智能研究者是如何解決這個問題的?
在達特茅斯會議之后,對該領域的興趣(以及某些領域對它的反對)迅速增長。研究人員開始著手各種任務,從證明定理到玩游戲等。一些早期的突破性工作包括阿瑟·塞繆爾(Arthur Samuel)于1959年開發的跳棋程序。
當時許多演示系統都專注于所謂的“玩具問題”,將其適用性限制在某些簡化或自包含的世界中,如游戲或邏輯。這種簡化在一定程度上受到當時有限的計算能力的驅使,另一方面也因為這并不涉及收集大量相關數據,而當時電子形式的數據很少。機器學習是什么?
從其早期起源開始,人工智能研究人員就認識到學習能力是人類智能的重要組成部分。問題是人們是如何學習的?我們能否以與人類相同的方式,或至少與人類一樣有效地編寫計算機來學習?
在機器學習中,學習是中心問題——顧名思義。說某物被學習了意味著它不僅僅被捕捉并存儲在數據庫中的數據一樣——它必須以某種方式表示出來,以便可以加以利用。一般來說,學習的計算機程序會從數據中提取模式。
生成式人工智能的原理
大型語言模型(LLMs)
大型語言模型(LLMs)是一種生成人工智能系統,用于以純文本形式生成對問題或提示的回應。這些系統使用專門的多層次和多方面的神經網絡,在非常大的自然語言文本集合上進行訓練,通常從互聯網和其他合適的來源收集而來。
基礎模型
訓練一個LLM可能非常耗時和昂貴——如今,最常見的商業可用系統在數千臺強大處理器上同時訓練數周,耗資數百萬美元。但不用擔心,這些程序通常被稱為“基礎模型”,具有廣泛的適用性和長期的使用壽命。它們可以作為許多不同類型的專業LLM的基礎,盡管直接與它們交互也是完全可能的(而且很有用和有趣)。
人類反饋強化學習
LLM完成了對大型文本語料庫的“基礎訓練”后,就要進入“修身養性”的階段。這包括向它提供一系列示例,說明它應該如何禮貌地和合作地回答問題(響應“提示”),以及最重要的是,它不被允許說什么(當然,這充滿了反映其開發者態度和偏見的價值判斷)。與初始訓練步驟形成對比,初始訓練步驟大多是自動化過程,這個社交化步驟是通過所謂的人類反饋強化學習(RLHF)來完成的。RLHF就是其名,人類審查LLM對一系列可能引起不當行為的提示的反應,然后一個人向它解釋回應的問題(或禁止的內容),幫助LLM改進。
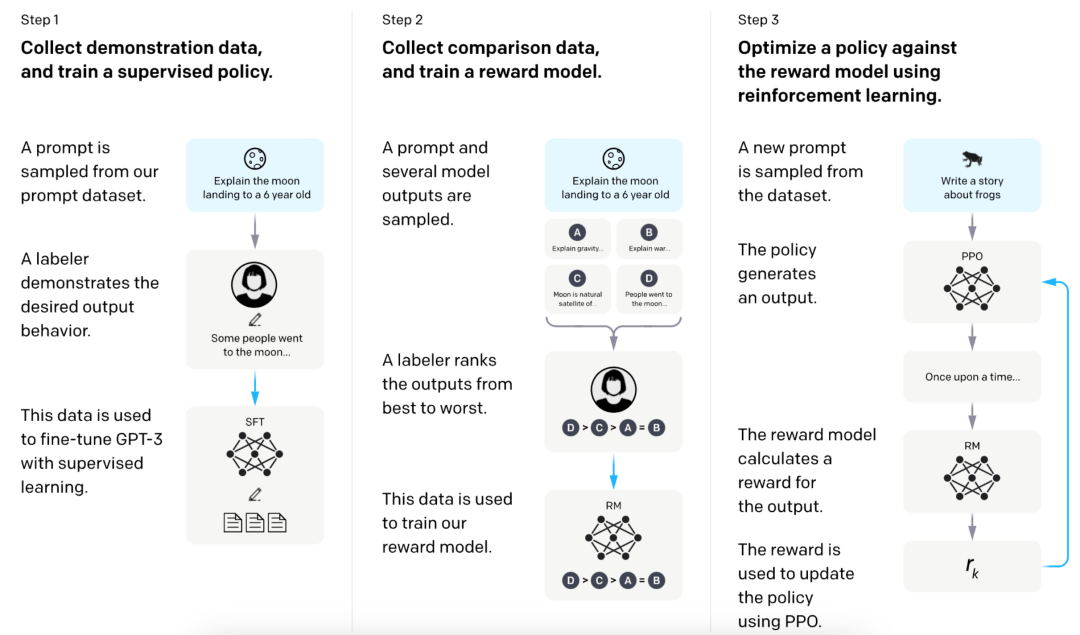
模型輸入與輸出
完成訓練后,LLM接受用戶(你)的提示或問題作為輸入,然后對其進行轉換,并生成一個回應。與訓練步驟相比,這個過程快速而簡單。但是它是如何將你的輸入轉換為回應的呢?
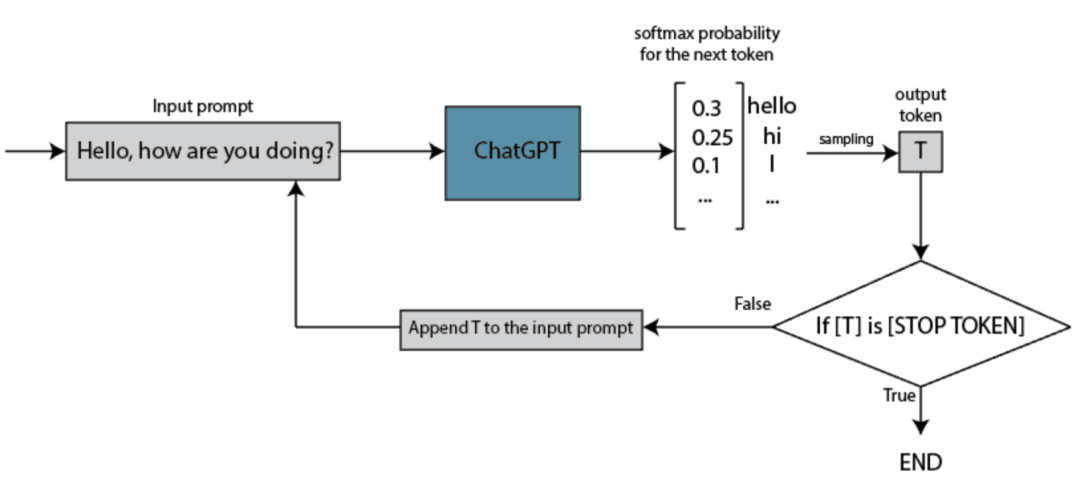
它們將這種“猜測下一個詞”的技術擴展到更長的序列上。然而,重要的是要理解,分析和猜測實際上不是在詞本身上進行的;而是在所謂的標記上進行的——它們代表詞的部分,并且這些標記進一步以“嵌入”形式表達,旨在捕捉它們的含義。大型語言模型(LLMs)如何工作?
簡化的單詞級解釋忽略了LLMs如何在我們今天的計算機類別中表示這些大量的單詞集合。在任何現有或想象中的未來計算機系統中,存儲數千個單詞的所有可能序列都是不現實的:與之相比,這些序列的數量使得宇宙中的原子數量看起來微不足道。因此,研究人員重新利用了神經網絡的試驗和真實方法,將這些巨大的集合減少為更易管理的形式。
神經網絡最初被應用于解決分類問題——決定某物是什么。例如,您可能會輸入一張圖片,網絡將確定它是否是狗還是貓的圖像。為了有用,神經網絡必須以一種使相關的輸入產生相似結果的方式壓縮數據。
什么是“嵌入”?
LLMs將每個單詞表示為一種特定形式的向量(列表),稱為嵌入。嵌入將給定的單詞轉換為具有特殊屬性的向量(有序數字列表):相似的單詞具有相似的向量表示。想象一下,“朋友”,“熟人”,“同事”和“玩伴”這些詞的嵌入。目標是,嵌入應該將這些單詞表示為彼此相似的向量。這通過代數組合嵌入來促進某些類型的推理。
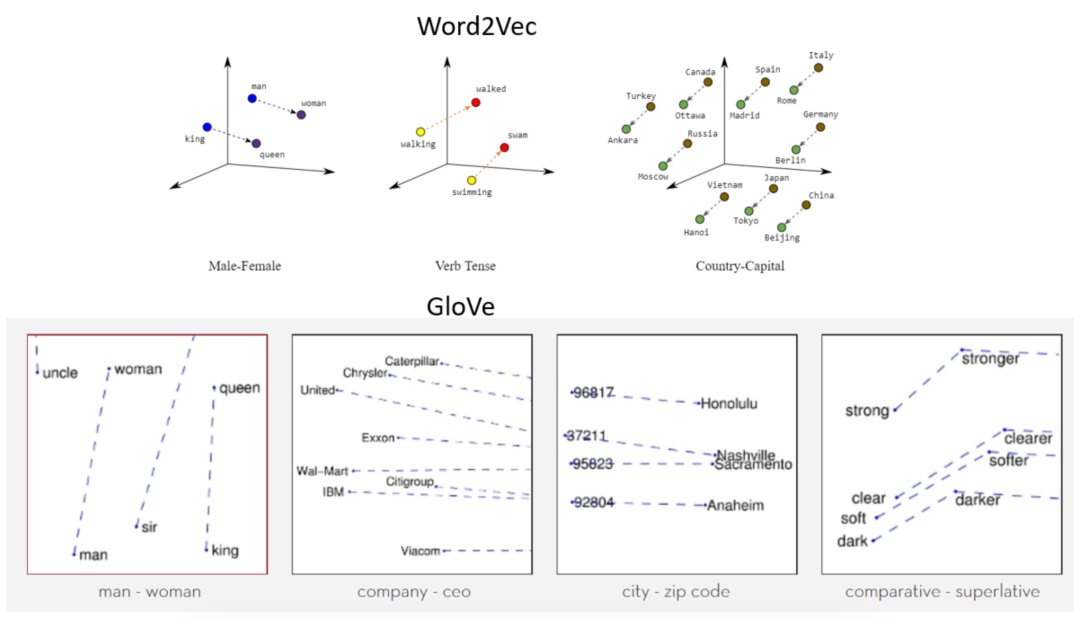
單詞嵌入的一個缺點是它們并不固有地解決多義性的問題——單詞具有多個含義的能力。處理這個問題有幾種方法。例如,如果訓練語料庫足夠詳細,單詞出現的上下文將傾向于聚合成統計簇,每個簇代表同一個單詞的不同含義。這允許LLM以模棱兩可的方式表示單詞,將其與多個嵌入相關聯。多義性的計算方法是一個持續研究的領域。單詞嵌入是如何表示含義的?
當您想知道一個詞的含義時,您會怎么做?當然是查字典。在那里,您會找到什么?關于詞義的描述,當然是用詞語表達的。您讀了定義后相信您理解了一個詞的含義。換句話說,就是,通過與其他單詞的關系來表示單詞的含義通常被認為是語義的一種滿意的實際方法。
當然,有些詞確實指的是現實世界中的真實事物。但是,如果您只是在單詞的領域內工作,那么事實證明這并不像您想象的那么重要。在相互關聯的定義的混亂中有太多的內在結構,以至于您關于給定單詞的幾乎所有需要知道的東西都可以通過它與其他單詞的關系來編碼。人工神經網絡(ANN)
人工神經網絡(ANN)是受到真實神經網絡的某些假定組織原則啟發的計算機程序,簡而言之,就是生物大腦。盡管如此,人工神經網絡與真實神經網絡之間的關系大多是希望的,因為對大腦實際功能了解甚少。
人工神經網絡中的神經元通常組織成層。底層也稱為“輸入”層,因為我們要將要分類的圖片輸入到這里。現在就像真正的神經元一樣,我們必須表示每個輸入神經元是否被激活(“發射”)或不被激活。其他內部層是行動發生的地方。這些被稱為“隱藏”層,因為它們夾在輸入層和輸出層之間。每個隱藏層中的神經元與它們上面和下面的層中的所有神經元相連。這些相互連接被建模為數值權重,例如,零表示“未連接”,一表示“強連接”,負一表示負連接。
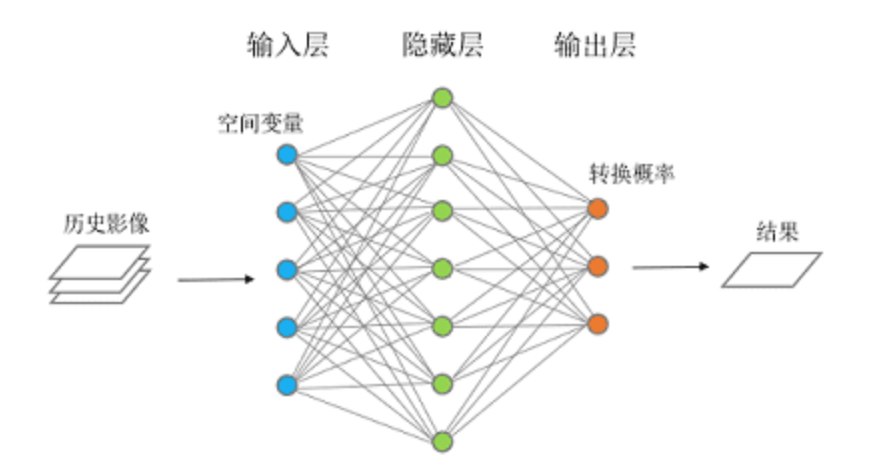
神經網絡的工作原理如下:我們根據要分類的圖片設置輸入(底層)級別的神經元的值。然后對于上一級的每個神經元,我們通過計算下一級神經元與較低級神經元之間的連接的權重乘積來計算其激活值。我們繼續這個過程,從每一級橫跨,然后向上一級工作。當我們到達頂部時,如果一切都按預期進行,頂層的一個神經元將被高度激活,而另一個不會,這就給了我們答案。
Transformer
Transformer是一種特殊類型的神經網絡,通常用于大型語言模型(LLM)。當一個Transformer模型被給予一句話進行處理時,它不會單獨查看每個單詞。相反,它一次查看所有單詞,并為每對單詞計算一個“注意分數”。注意分數確定了句子中每個單詞應該對其他每個單詞的解釋產生多大影響。
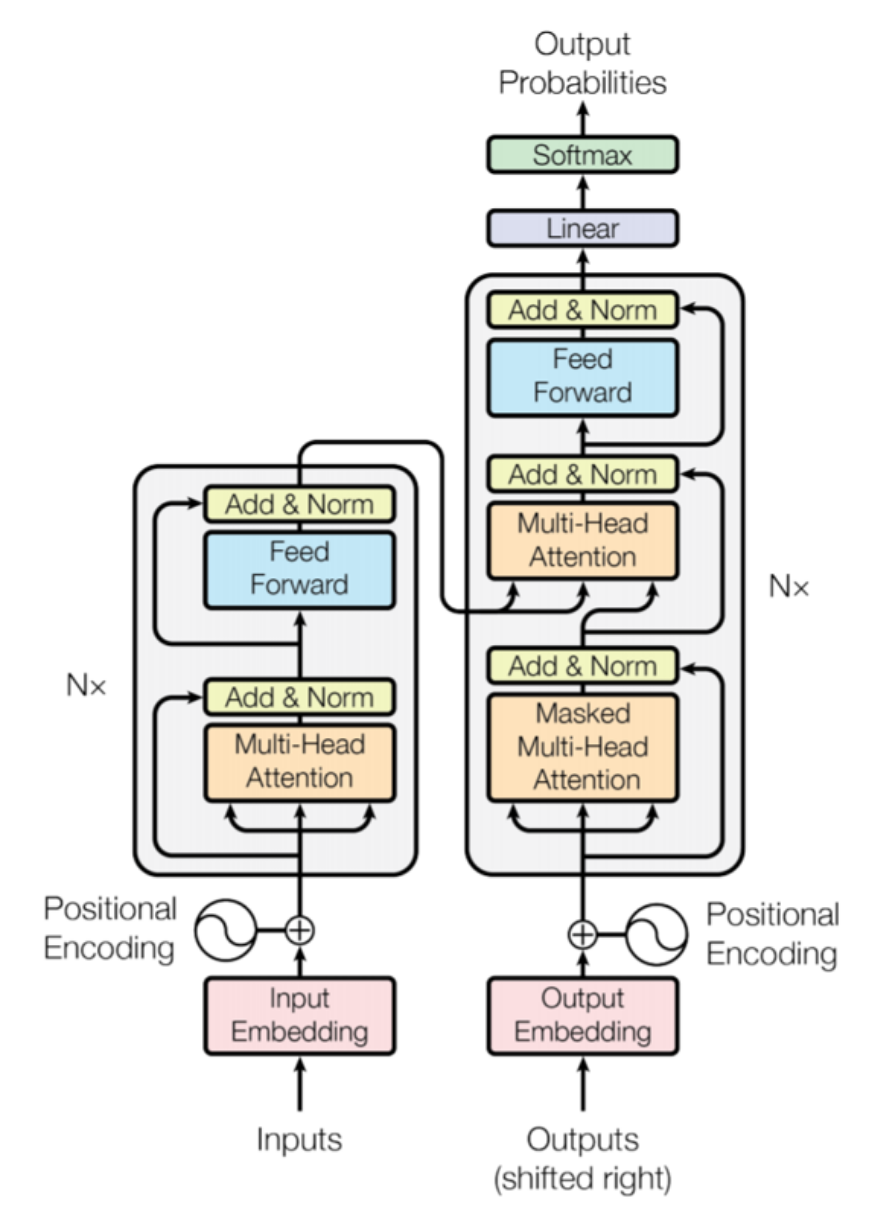
例如,如果句子是“貓坐在墊子上”,當模型處理單詞“坐”時,它可能會更多地關注單詞“貓”(因為“貓”是坐的對象),而對單詞“墊子”關注較少。但是當處理單詞“上”時,它可能會更多地關注“墊子”。
當你要求LLM回答問題時,類似的過程也會發生。LLM首先將您的單詞轉換為嵌入,就像它對其訓練示例所做的那樣。然后,它以相同的方式處理您的詢問,使其能夠專注于輸入的最重要部分,并使用這些來預測如果您開始回答問題,則輸入的下一個單詞可能是什么。Transformer vs 詞嵌入
Transformer模型利用詞嵌入來表達語言中的復雜概念。在Transformer中,每個單詞都被表示為一個高維向量,而這些向量在表示空間中的位置反映了單詞之間的語義關系。例如,具有相似含義的單詞在表示空間中可能會更加接近,而含義不同的單詞則會相對遠離。
通過使用這種高維表示,Transformer能夠更好地理解和生成自然語言。它們通過學習大量文本數據,自動調整詞嵌入向量的參數,使得模型能夠根據上下文理解單詞的含義,并生成連貫的語言輸出。Transformer模型中的注意力機制允許模型集中注意力于輸入中與當前任務相關的部分,從而提高了模型在處理長文本序列和復雜語境中的性能。什么是token?
在語言模型中,"tokens"是指單詞、單詞部分(稱為子詞)或字符轉換成的數字列表。每個單詞或單詞部分都被映射到一個特定的數字表示,稱為token。這種映射關系通常是通過預定義的規則或算法完成的,不同的語言模型可能使用不同的tokenization方案,但重要的是要保證在相同的語境下,相同的單詞或單詞部分始終被映射到相同的token。
大多數語言模型傾向于使用子詞(tokenization),因為這種方法既高效又靈活。子詞tokenization能夠處理單詞的變形、錯字等情況,從而更好地識別單詞之間的關系。
幻覺
幻覺是指LLMs在回答問題或提示時,并不會查閱其訓練時接觸到的所有詞序列,這是不切實際的。這意味著它們并不一定能夠訪問所有原始內容,而只能訪問那些信息的統計摘要。與你一樣,LLMs可能“知道”很多詞,但它們無法重現創建它們的確切序列。
LLMs很難區分現實和想象。至少目前來說,它們沒有很好的方法來驗證它們認為或相信可能是真實的事物的準確性。即使它們能夠咨詢互聯網等其他來源,也不能保證它們會找到可靠的信息。
-
AI
+關注
關注
88文章
34592瀏覽量
276337 -
人工智能
+關注
關注
1805文章
48843瀏覽量
247527 -
大模型
+關注
關注
2文章
3062瀏覽量
3927
發布評論請先 登錄
生成式人工智能認證:重構AI時代的人才培養與職業躍遷路徑
小白學大模型:從零實現 LLM語言模型

我國生成式人工智能的發展現狀與趨勢
生成式人工智能模型的安全可信評測

長城汽車Coffee Agent大模型通過生成式人工智能服務備案
嵌入式和人工智能究竟是什么關系?
Vicor技術如何改進生成式人工智能的供電

《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
生成式人工智能的概念_生成式人工智能主要應用場景
中興星云大模型通過生成式人工智能服務備案
聲智完成多項生成式算法和大模型服務備案






 工商網監
工商網監
評論