") 交換機與路由器緩沖區(qū):尋找完美大小
交換機與路由器緩沖區(qū):尋找完美大小
*本文系SDNLAB編譯自瞻博網(wǎng)絡(luò)技術(shù)專家兼高級工程總監(jiān)Sharada Yeluri領(lǐng)英
在路由器和交換機中,緩沖區(qū)至關(guān)重要,可以防止網(wǎng)絡(luò)擁塞期間的數(shù)據(jù)丟失。緩沖區(qū)到底要多大?這個問題在學術(shù)界和工業(yè)界一直備受爭議。本文探討了高端路由器中數(shù)據(jù)包緩沖的歷史和演變,以期概述當前的實踐和未來的趨勢。
網(wǎng)絡(luò)芯片中的緩沖區(qū)
在典型的路由器/交換機 ASIC 中,會發(fā)現(xiàn)三種類型的數(shù)據(jù)包緩沖區(qū)。
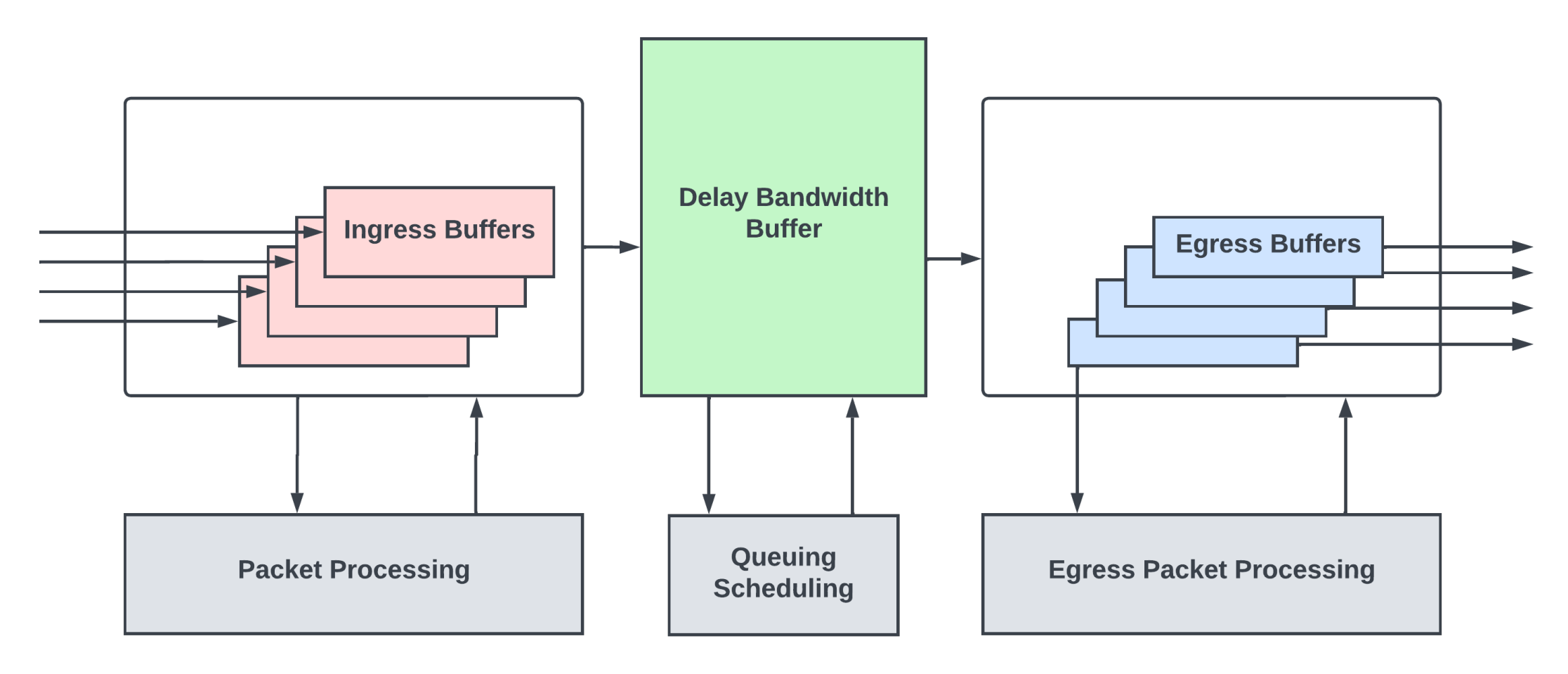
入口緩沖區(qū)
入口緩沖區(qū)保存來自輸入鏈路的傳入數(shù)據(jù)包,而數(shù)據(jù)包頭(通常是數(shù)據(jù)包的前128-256 字節(jié))由數(shù)據(jù)包處理邏輯處理。該處理邏輯檢查數(shù)據(jù)包頭中的各種協(xié)議頭來計算下一跳。然后為數(shù)據(jù)包分配出口隊列/優(yōu)先級,并確定數(shù)據(jù)包必須從哪個出口輸出鏈路轉(zhuǎn)發(fā)出去。
數(shù)據(jù)包在入口緩沖區(qū)中駐留一段時間,直到處理完成。在固定的pipeline架構(gòu)中,數(shù)據(jù)包處理延遲約為 1-2 微秒。確定入口緩沖區(qū)的大小是為了在處理數(shù)據(jù)包頭時保存數(shù)據(jù)包內(nèi)容。
網(wǎng)絡(luò)芯片性能的衡量標準是在不丟失數(shù)據(jù)包的情況下,每秒按線路速率可以處理多少比特的流量,以及滿足該速率的最小數(shù)據(jù)包的大小。盡管以太網(wǎng)鏈路上 IP 數(shù)據(jù)包最小可低至 64 字節(jié),但許多網(wǎng)絡(luò)芯片都會考慮到典型的網(wǎng)絡(luò)負載,并設(shè)計數(shù)據(jù)包處理pipeline以滿足遠大于 64字節(jié)的數(shù)據(jù)包性能要求,有效地減少了每秒通過芯片的數(shù)據(jù)包數(shù)量。這樣做可以優(yōu)化數(shù)據(jù)包處理邏輯,以節(jié)省芯片的面積和功耗。
雖然典型工作負載的平均數(shù)據(jù)包大于 350字節(jié),但可能會出現(xiàn)小數(shù)據(jù)包的瞬時突發(fā)(通常是保持網(wǎng)絡(luò)活動的控制數(shù)據(jù)包或 TCP 協(xié)議的 syn/ack 數(shù)據(jù)包),這可能超額訂閱數(shù)據(jù)包處理邏輯,因為它們不是為處理如此高的每秒數(shù)據(jù)包轉(zhuǎn)發(fā)而設(shè)計的。
在網(wǎng)絡(luò)芯片中,“超額訂閱(oversubscription)”意味著資源/邏輯所承受的負載超出了其處理能力。在數(shù)據(jù)包處理超額訂閱的瞬時期間,入口緩沖區(qū)會吸收數(shù)據(jù)包突發(fā)。當緩沖區(qū)已滿時,它們會進行優(yōu)先級感知丟棄。
延遲帶寬緩沖區(qū) (DBB)
在完成數(shù)據(jù)包處理并確定下一跳后,數(shù)據(jù)包一般會進入一個深度緩沖區(qū),通常稱為延遲帶寬緩沖區(qū)(DBB)。當路由器的部分/全部輸出鏈路被超額訂閱,該緩沖區(qū)將在網(wǎng)絡(luò)瞬時擁塞期間提供緩沖。
當流經(jīng)網(wǎng)絡(luò)的流量超過網(wǎng)絡(luò)的最大容量時,就會發(fā)生網(wǎng)絡(luò)擁塞。造成擁堵的原因有很多:
為了降低系統(tǒng)成本,網(wǎng)絡(luò)中可能會存在故意的超額訂閱。當某些用戶使用的帶寬超過平均分配的帶寬,就會導致?lián)砣?/p>
當多個主機開始相互通信時,多播/廣播流量也可能導致?lián)砣?/p>
當端點上的某些接口出現(xiàn)故障時,需要將流量分配到剩余的接口,這可能會導致上游網(wǎng)絡(luò)設(shè)備擁塞;
用戶錯誤,如網(wǎng)絡(luò)配置錯誤,也可能會導致?lián)砣?/p>
由于應用程序和用戶流量的突發(fā)性,某些路由器/交換機也可能會出現(xiàn)流量超過其鏈路容量的情況。
在擁塞期間,路由器可能會發(fā)現(xiàn)其部分/全部輸出鏈路被超額訂閱。在極端擁塞的情況下,所有輸入流量可能都希望通過單個輸出離開。在路由器芯片中設(shè)置數(shù)據(jù)包緩沖區(qū)吸收瞬時擁塞,有助于整體網(wǎng)絡(luò)的健康和吞吐量。
出口緩沖區(qū)
在網(wǎng)絡(luò)擁塞期間,路由器需要確保高優(yōu)先級流量和其他控制流量不會出現(xiàn)丟包,并且需要滿足不同優(yōu)先級下不同用戶的服務質(zhì)量(QoS)。路由器/高端交換機具有復雜的排隊和調(diào)度子系統(tǒng),可以在DBB內(nèi)針對不同的流維護不同的隊列。調(diào)度程序以不超過該接口鏈路容量的速率,將流量從這些緩沖區(qū)分發(fā)到輸出端口接口處的淺出口緩沖區(qū)。這些出口緩沖區(qū)的大小正好足以掩蓋DBB到輸出接口之間的往返時延,以便流量可以從輸出接口流出,而不會出現(xiàn)突發(fā)情況。
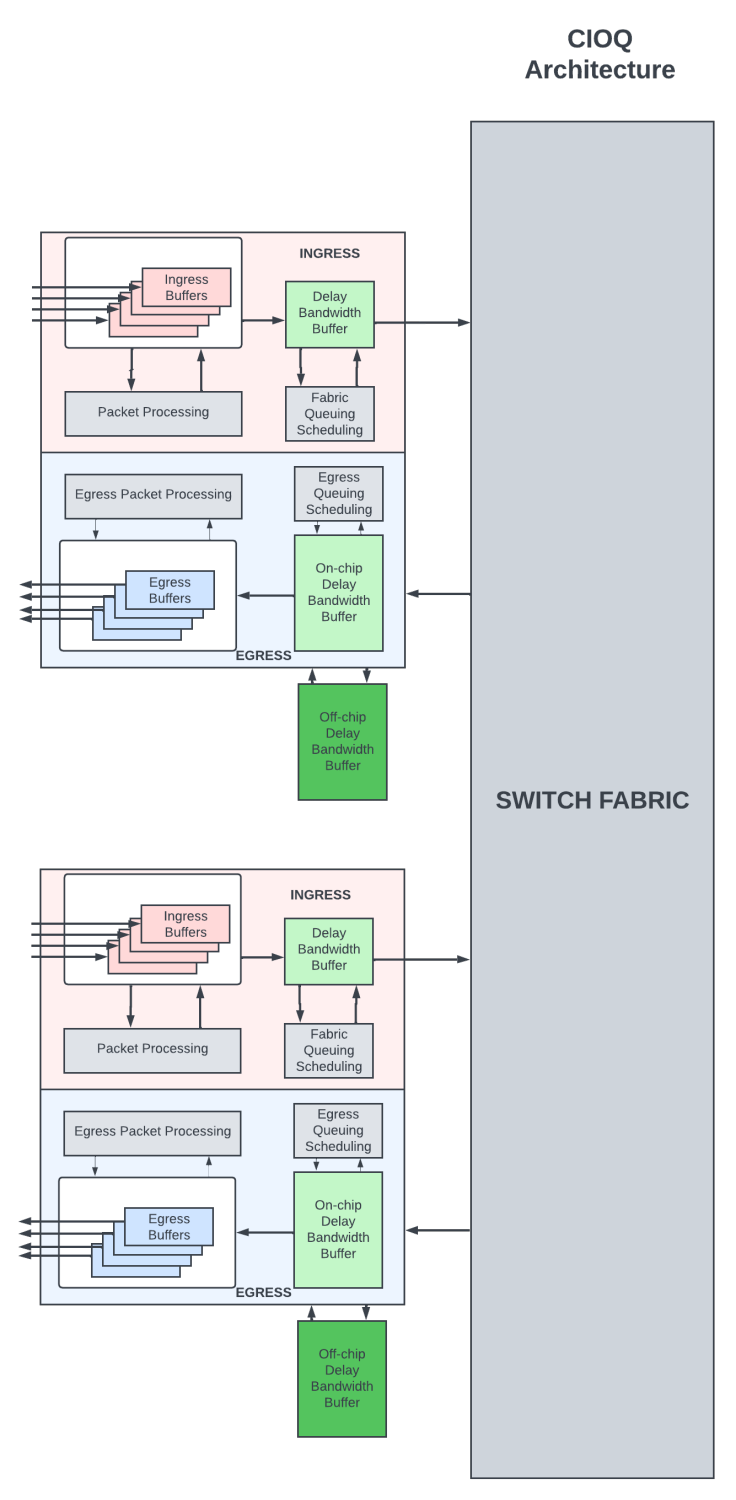
可以使用通過交換fabric互連的多個模塊化路由芯片來構(gòu)建大型路由器。下面將使用PFE來指代這些模塊化路由芯片。
在組合輸入/輸出 (CIOQ) 架構(gòu)中,數(shù)據(jù)包在入口 PFE 和出口 PFE上都有緩沖。如果路由器內(nèi)出現(xiàn)短暫擁塞,淺入口延遲帶寬緩沖區(qū)會保留數(shù)據(jù)包,從而通過交換fabric將數(shù)據(jù)包從入口移動到出口。出口 PFE 處的DBB是深度緩沖區(qū),在網(wǎng)絡(luò)擁塞期間,數(shù)據(jù)包在其中排隊較長時間。
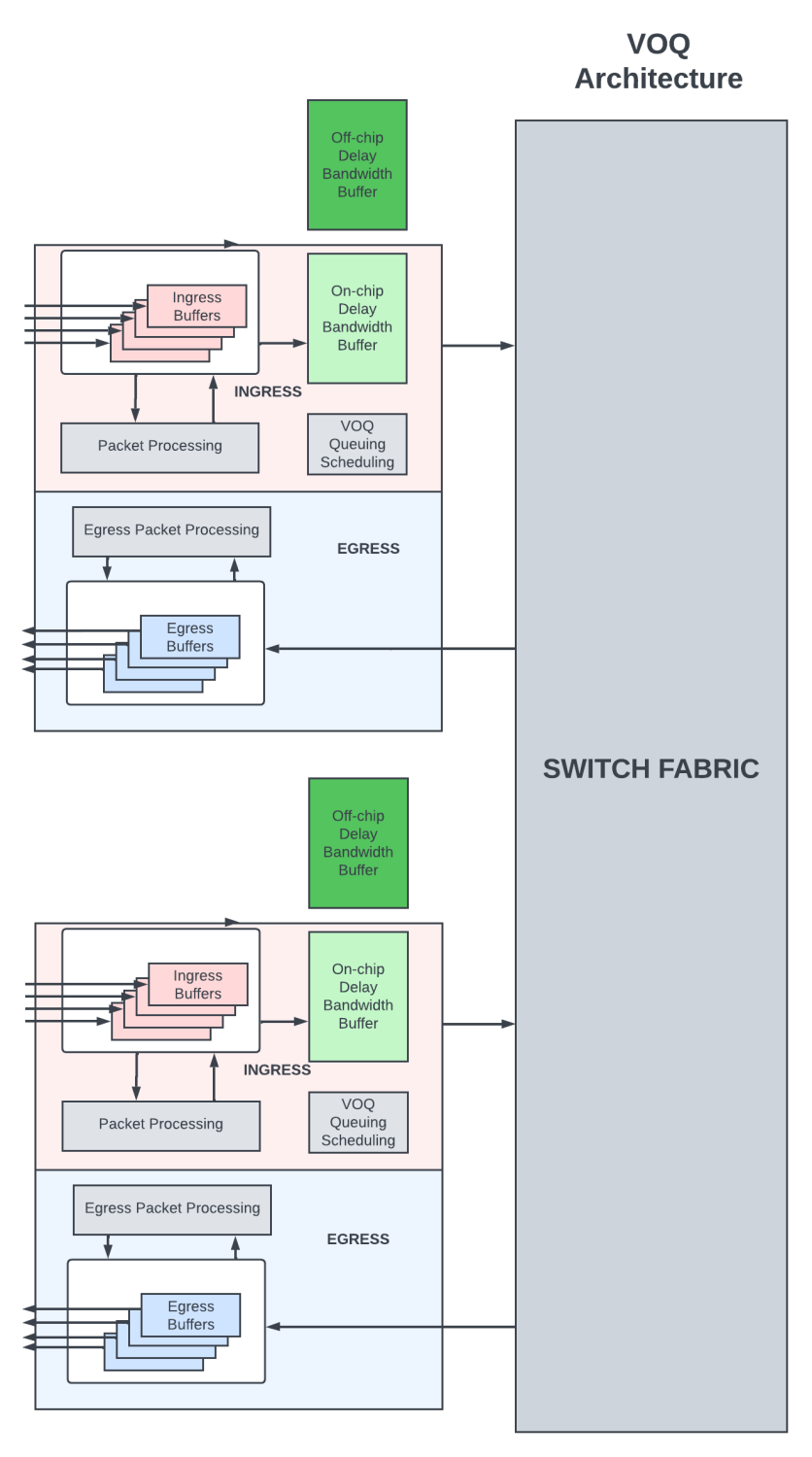
在虛擬輸出隊列 (VOQ) 架構(gòu)中,所有延遲帶寬緩沖都在入口 PFE 中完成。在這里,數(shù)據(jù)包在入口 PFE 的虛擬輸出隊列中排隊。VOQ 唯一對應于數(shù)據(jù)包需要離開的最終 PFE/輸出鏈路/輸出隊列。數(shù)據(jù)包通過出口處的復雜調(diào)度程序從入口 PFE 移動到出口 PFE,只有在能夠?qū)?shù)據(jù)包調(diào)度出輸出鏈路時,該調(diào)度器才會從入口 PFE 接受數(shù)據(jù)包。在 VOQ 架構(gòu)中,發(fā)往輸出隊列的數(shù)據(jù)包可在 VOQ 中的多個入口 PFE 中進行緩沖。
調(diào)整數(shù)據(jù)包緩沖區(qū)的大小
兩大陣營
當談到交換機和路由器的數(shù)據(jù)包緩沖區(qū)大小時,存在著持有不同觀點的兩大陣營:
以學者為首的陣營認為,緩沖區(qū)總體來說是臃腫的;
數(shù)據(jù)中心 (DC) 網(wǎng)絡(luò)運營商則要求提供充足的緩沖,以避免通過其路由器/交換機的任何流出現(xiàn)數(shù)據(jù)包丟失,特別是高度分布式的云/數(shù)據(jù)挖掘應用。
在大數(shù)據(jù)應用中,數(shù)百臺處理查詢的服務器可能會向單個服務器發(fā)送大量流量,該服務器匯總所有流的響應,這可能會導致持續(xù)數(shù)十毫秒的短暫擁塞情況。但重要的是,流量不能丟失!
DC內(nèi)的存儲應用對丟包也非常敏感。一般來說,現(xiàn)代數(shù)據(jù)中心的流量是雙峰的,由短期、低速率的“老鼠”流和長期、高速率的“大象”流組成。大多數(shù)流是老鼠流,但它們僅承載10-15%的數(shù)據(jù)流量負載。剩余90%的流量負載由少量大象流承載。大象流對應于大數(shù)據(jù)傳輸,需要高吞吐量,例如備份。老鼠流對延遲敏感,由查詢和控制消息組成,并且需要最少的數(shù)據(jù)包丟失,以避免整體應用程序性能下降。DC 運營商更喜歡更大的緩沖區(qū),以避免老鼠流的數(shù)據(jù)包丟失,因為許多傳統(tǒng)交換機不支持動態(tài)區(qū)分隊列中的老鼠流和大象流。
互聯(lián)網(wǎng)服務提供商在緩沖方面有不同的要求,因為其路由器的重點是盡快交換大量數(shù)據(jù),并滿足視頻/語音呼叫等高優(yōu)先級流量的服務級別協(xié)議(SLA),他們傾向于盡可能地利用昂貴/高容量的 WAN 鏈路,以降低設(shè)備成本。但鏈路使用越頻繁,丟包的可能性就越大。因此,互聯(lián)網(wǎng)服務提供商也要求路由器中有足夠的緩沖,以區(qū)分可以容忍數(shù)據(jù)包丟失的盡力而為的流量和必須以接近零流量丟失方式傳送的高優(yōu)先級流量。
在過去的二十年中,緩沖區(qū)大小一直是個熱門話題。隨著路由芯片帶寬的增長,內(nèi)存的擴展程度卻無法跟上,提供大量緩沖變得越來越昂貴。
無論是何種應用(交換/路由),整個行業(yè)的趨勢都是在不影響 QoS 的情況下盡可能減少緩沖。這在很大程度上依賴流量工程、先進的端到端擁塞控制算法和主動隊列管理 (AQM) 來提前向端點通知擁塞情況,并通過較小的延遲帶寬緩沖區(qū)來保持鏈路飽和。
擁塞控制算法
擁塞控制算法使用的協(xié)議是閉環(huán)的,其中接收方將收到的數(shù)據(jù)包信息發(fā)送給發(fā)送方。TCP/IP 就是這種流行的協(xié)議套件。TCP 是一種面向連接的協(xié)議。在數(shù)據(jù)傳輸之前,需要在發(fā)送方和接收方之間建立連接。TCP 從應用層的數(shù)據(jù)流接收數(shù)據(jù),將其劃分為塊,并添加 TCP報頭以創(chuàng)建 TCP 段。然后,TCP 段被封裝到 IP 數(shù)據(jù)報中,并通過網(wǎng)絡(luò)傳輸?shù)蕉它c。
TCP 報頭包含許多字段,有助于建立和維護連接,并檢測丟失的段以進行重傳和擁塞控制。其中一個字段是序列號字段。TCP 使用遞增的序列號標記數(shù)據(jù)流的每個字節(jié)。當發(fā)送一個報文段時,它發(fā)送該報文段中數(shù)據(jù)第一個字節(jié)的序列號。接收方使用序列號將無序接收的 TCP 段組合在一起。對于接收到的每個數(shù)據(jù)段,接收方都會發(fā)送一個確認 ( ACK ),表示它期望從發(fā)送方收到的下一個數(shù)據(jù)段。ACK丟失則表示網(wǎng)絡(luò)中出現(xiàn)數(shù)據(jù)包丟失或網(wǎng)絡(luò)擁塞。發(fā)送方使用此信息來降低傳輸速率,并重新傳輸丟失的段。
自 TCP/IP 誕生以來,已經(jīng)開發(fā)出許多的擁塞控制算法,幫助端點在擁塞期間調(diào)節(jié)進入網(wǎng)絡(luò)的數(shù)據(jù)傳輸速率。這些算法依賴于更改擁塞窗口大小,即發(fā)送方在不等待網(wǎng)絡(luò)擁塞確認的情況下即可發(fā)送的 TCP 段數(shù)量。
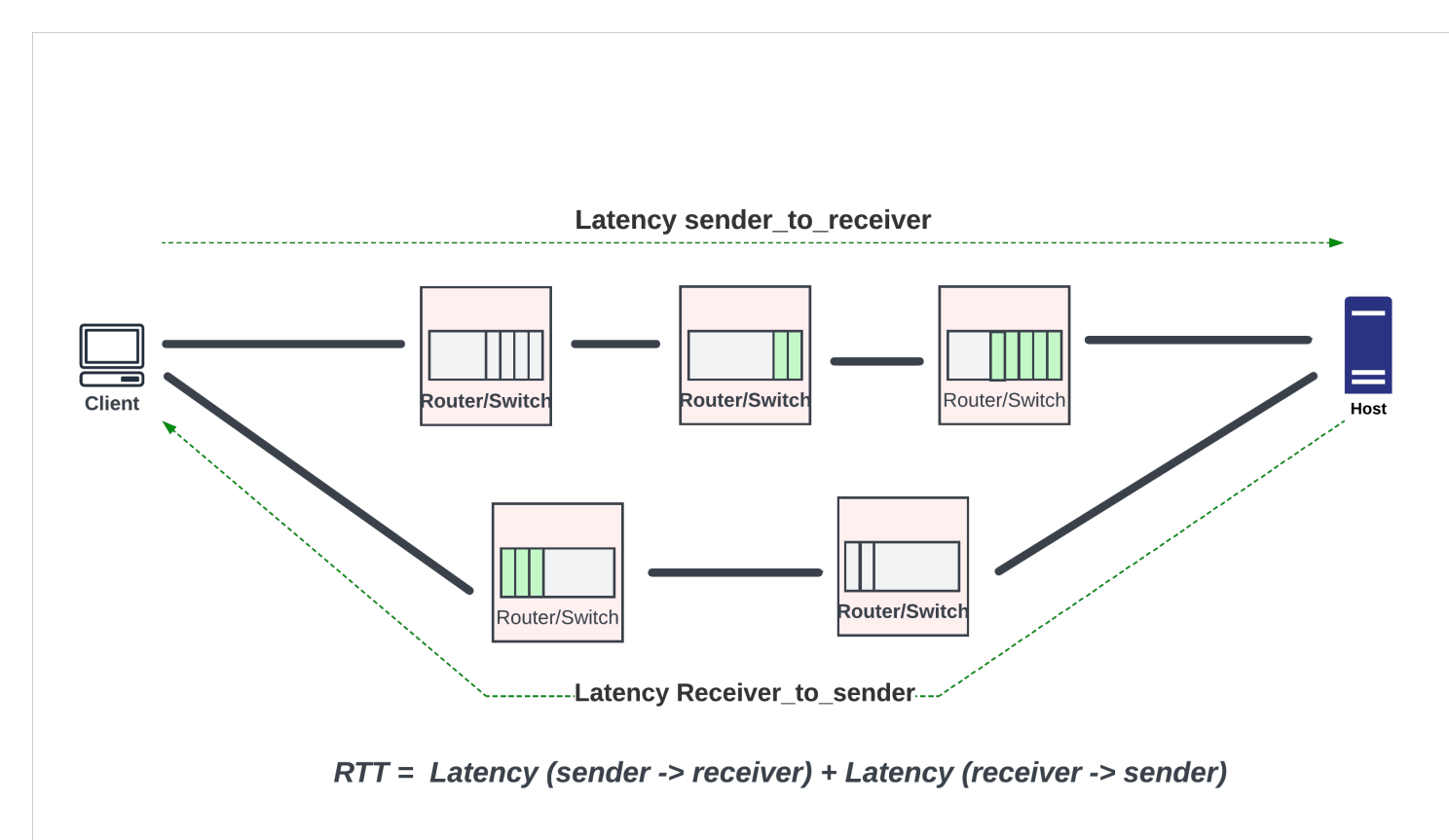
往返時間 (RTT)
了解往返時間對確定緩沖區(qū)大小和開發(fā)擁塞控制算法至關(guān)重要。RTT 是數(shù)據(jù)包從發(fā)送方傳輸?shù)浇邮辗揭约皩⒋_認返回發(fā)送方所需的往返時間。RTT 變化很大,具體取決于端點的位置以及路徑中網(wǎng)絡(luò)設(shè)備的擁塞程度。
TCP 流的端點使用擁塞避免模式和Slow_start(慢開始)避免擁塞。
發(fā)送方一開始并不清楚網(wǎng)絡(luò)的負荷情況,如果立即把大量數(shù)據(jù)直接注入到網(wǎng)絡(luò),很有可能會引起網(wǎng)絡(luò)擁塞。所以可以由小到大逐漸增大發(fā)送的擁塞窗口值。通常一開始發(fā)送分段時,先把擁塞窗口設(shè)置為一個MSS(最大傳輸分段)值,收到ACK后擁塞窗口加一個分段大小,此時可以發(fā)出兩個分段數(shù)據(jù),收到兩個ACK后擁塞窗口又加二,這樣一輪一輪下去擁塞窗口呈指數(shù)增長,直到窗口大小達到閾值。
此時,進入擁塞避免階段。擁塞窗口大小對每個 RTT 線性增加一個 MSS,使得每一輪不再增加一倍,而是增加一個MSS。 在此階段,如果通過丟包檢測到擁塞,則發(fā)送方將擁塞窗口減半(傳輸速率減半)并重新開始。
主動隊列管理(AQM)
如果路由器等到其DBB滿了后才丟棄數(shù)據(jù)包,那么在發(fā)送方對丟包做出反應之前,網(wǎng)絡(luò)內(nèi)將有更多的流量進入已經(jīng)滿的隊列,導致大量的尾部丟棄(Tail-Drop)。幾乎所有具有深度數(shù)據(jù)包緩沖區(qū)的交換機/路由器都支持加權(quán)隨機早期丟棄 (WRED),以便盡早向發(fā)送方通知擁塞情況。WRED 通過使用 WRED 曲線在隊列滿之前概率性地丟棄數(shù)據(jù)包,防止隊列完全填滿。
一些路由器和 DC 交換機還支持顯式擁塞通知 (ECN)。在 ECN 中,當路由器經(jīng)歷擁塞時,它可能會將某些數(shù)據(jù)包標記為“經(jīng)歷擁塞”并按原樣轉(zhuǎn)發(fā)它們。IP 報頭的流分類字段用于 ECN 標記。當端點收到這些設(shè)置了 ECN 位的數(shù)據(jù)包時,它們會在發(fā)送ACK的同時將擁塞情況反饋給發(fā)送方。發(fā)送方通過這些信息來降低網(wǎng)絡(luò)傳輸速率。
ECN 有助于減少擁塞,且不會造成與 WRED 相關(guān)的數(shù)據(jù)包丟失,但它也有一些局限性。如果網(wǎng)絡(luò)丟包率較高,ECN可能無法正常工作,因為標記的數(shù)據(jù)包也可能丟失,擁塞信息無法準確傳達。此外,如果不同的 ECN 實現(xiàn)使用不同的標記算法或?qū)砣捻憫煌瑒t可能存在互操作性問題。
一些供應商集成了先進的 AQM 技術(shù),可以實現(xiàn)流量感知的早期丟棄,例如區(qū)分隊列中的老鼠流和大象流(基于輸入流量速率),并通過動態(tài)調(diào)整不同流的隊列長度來防止老鼠流被丟棄。
緩沖區(qū)大小
確定路由器 ASIC 內(nèi)部延遲帶寬緩沖區(qū)大小的關(guān)鍵是確保當發(fā)送方因網(wǎng)絡(luò)擁塞而暫停或減少進入網(wǎng)絡(luò)的流量時,緩沖區(qū)不會變空。當發(fā)送方因擁塞而減小窗口大小時,緩沖區(qū)充當一個儲存庫,以保持鏈路繁忙。如果緩沖區(qū)變空,則路由器的輸出鏈路沒有得到充分利用。
經(jīng)驗法則
過去比較流行的規(guī)則是,一個總端口速度為C(以每秒比特為單位)的路由器,承載往返時間為RTT的流量,就需要一個相當于RTT * C的緩沖區(qū)以保持其輸出鏈路繁忙。這稱為延遲帶寬積 (DBP) 或帶寬延遲積 (BDP)。該規(guī)則在早期路由器中廣泛使用,當時路由器的總?cè)萘啃∮诿棵霂装偌忍亍?/p>
例如,在Juniper配備paradise芯片組的第一代PTX路由器中,具有 400Gbps 端口密度的 PFE 在外部存儲器中提供了 4GB的數(shù)據(jù)包緩沖。這可以覆蓋 80ms的 RTT ,可以滿足大多數(shù)核心路由器應用。
這種根據(jù)DBP調(diào)整緩沖區(qū)大小的模型適用于兩個端點之間的一些長期TCP 流,以及遇到瓶頸的單個路由器。
局限性
上述緩沖區(qū)大小的經(jīng)驗法則不能很好地應用到當前具有每秒TB級聚合端口帶寬的路由器。例如,具有 100 毫秒 RTT 的 14.4Tbps 路由芯片將需要 144GB 的延遲帶寬緩沖,這是一個非常大的緩沖區(qū),需要放在片上或外部存儲器中。
如今,HBM 存儲器因其高密度和帶寬被廣泛用于數(shù)據(jù)包緩沖。下一代HBM3可以提供每個部件24GB的總?cè)萘俊R獙崿F(xiàn) 144Gb 的數(shù)據(jù)包緩沖,需要 6 個 HBM3 部件。即使使用最大reticle-sized芯片,也很難在芯片邊緣為6個 HBM3 接口騰出空間,因為大多數(shù)邊緣將被高速WAN鏈路所需的 Serdes 占用。因此,路由器芯片必須在端口密度和提供的延遲帶寬緩沖之間做出權(quán)衡。
更新的理論
路由器通常承載數(shù)千個數(shù)據(jù)流,每個流的 RTT 差異很大(這些流的端點可能不同),并且這些流很少同步。緩沖區(qū)大小的經(jīng)驗法則不適用于這些情況。在多流量情況下,關(guān)于緩沖區(qū)大小有著不同的研究。
斯坦福大學研究人員于 2004 年發(fā)表的 SIGGCOM 論文聲稱,對于N 個長期存在的非同步流,只需C*RTT(min)/sqrt(N)的緩沖區(qū)即可保持鏈路繁忙。這意味著長期流越多,緩沖就越少。例如,當 10000 個長期流通過 14.4Tb路由器時,只需要 1.44GB 的延遲帶寬緩沖區(qū)。這完全可以通過片上和外部存儲器的組合來實現(xiàn)。作者還得出結(jié)論,在短期流(仍處于Slow_start階段時結(jié)束的流)或非 TCP 流中,延遲帶寬緩沖區(qū)的大小與路由器鏈路上的負載和流的長度成正比,并且小于C * RTT_min/sqrt(N)。
隨后,其他研究人員也發(fā)現(xiàn),緩沖區(qū)大小取決于輸出/輸入容量比以及鏈路的飽和度。例如,如果數(shù)據(jù)中心運營商能夠通過在scale-out 架構(gòu)中添加更多交換機來運行未充分利用的鏈路,那么這些芯片中的緩沖要求可能會下降。
盡管這些論文發(fā)表于幾十年前,但服務提供商和網(wǎng)絡(luò)芯片供應商還沒有準備好減少設(shè)備中的緩沖。直到最近幾年,當內(nèi)存不再隨著工藝節(jié)點的進步而擴展時,他們別無選擇。廠商們猶豫不決的原因是很難確定N 的值,該值在時間間隔內(nèi)變化很大,具體取決于客戶流量和運行在這些路由器上的應用。
學術(shù)論文通常沒有考慮到現(xiàn)實的流量場景,大多數(shù)論文還認為短暫的數(shù)據(jù)包丟失或鏈路未充分利用是可接受的行為。但事實是,許多應用程序在丟包的情況下無法正常運行。這些應用需要更大的緩沖區(qū)(大約數(shù)十毫秒),以在擁塞期間緩沖對丟失敏感的流量。因此,確定緩沖區(qū)的大小是一個復雜的決定,一個公式并不適合所有的應用!
現(xiàn)代路由器和超額訂閱緩沖區(qū)
正如上文中提到的,高端路由芯片供應商面臨著一個艱難的選擇,即在芯片/封裝內(nèi)的交換和緩沖能力之間進行權(quán)衡。
它們可以完全依賴片上 SRAM 進行延遲帶寬緩沖。但是,片上 SRAM 的擴展跟不上工藝節(jié)點的進步。例如,在先進的 3nm 工藝中,256MB的存儲器和控制器可以占據(jù)reticle-sized 芯片的 15-20%。在 7.2Tbps 流量下,這相當于大約 35 微秒的 DBB。數(shù)據(jù)中心的高帶寬交換機大多數(shù)流量的 RTT 小于 50 微秒。
對于支持數(shù)千個具有不同QoS屬性和RTT(幾十毫秒)的隊列以及頻繁發(fā)生瞬時擁塞事件的高帶寬路由芯片來說,50微秒是行不通的。這些路由芯片有兩種選擇:
他們可以完全依賴 HBM 等外部存儲器來進行延遲帶寬緩沖。但是,如果每個數(shù)據(jù)包都需要往返于 HBM,對于 14.4Tbps 的路由芯片來說,將需要足夠的 HBM 接口來支持 14.4Tbps 的讀寫帶寬。從核心芯片到 HBM 部件,很難提供如此多的 HBM 接口,同樣也不可能將如此多的 HBM 部件封裝在 2.5D 封裝中。此外,外部存儲器延遲很大,會顯著增加通過路由器的排隊延遲。
因此,許多高端路由 ASIC 開始使用混合緩沖方法,其中延遲帶寬緩沖分布在片上和外部存儲器之間。數(shù)據(jù)包在各自隊列中的片上延遲帶寬緩沖區(qū)中進行緩沖。排隊子系統(tǒng)監(jiān)視每個隊列的隊列長度。當隊列超過可配置閾值時,到達該隊列的新數(shù)據(jù)包將被發(fā)送到外部存儲器。隨著數(shù)據(jù)包從隊列中脫離,并且當隊列不再擁塞,到達率低于出隊率,隊列長度將減少。當隊列長度低于片上閾值時,該隊列的新數(shù)據(jù)包將保留在片上存儲器。該架構(gòu)僅提供總帶寬的一小部分用于外部存儲器,從而減少了芯片的外部存儲器接口的數(shù)量。
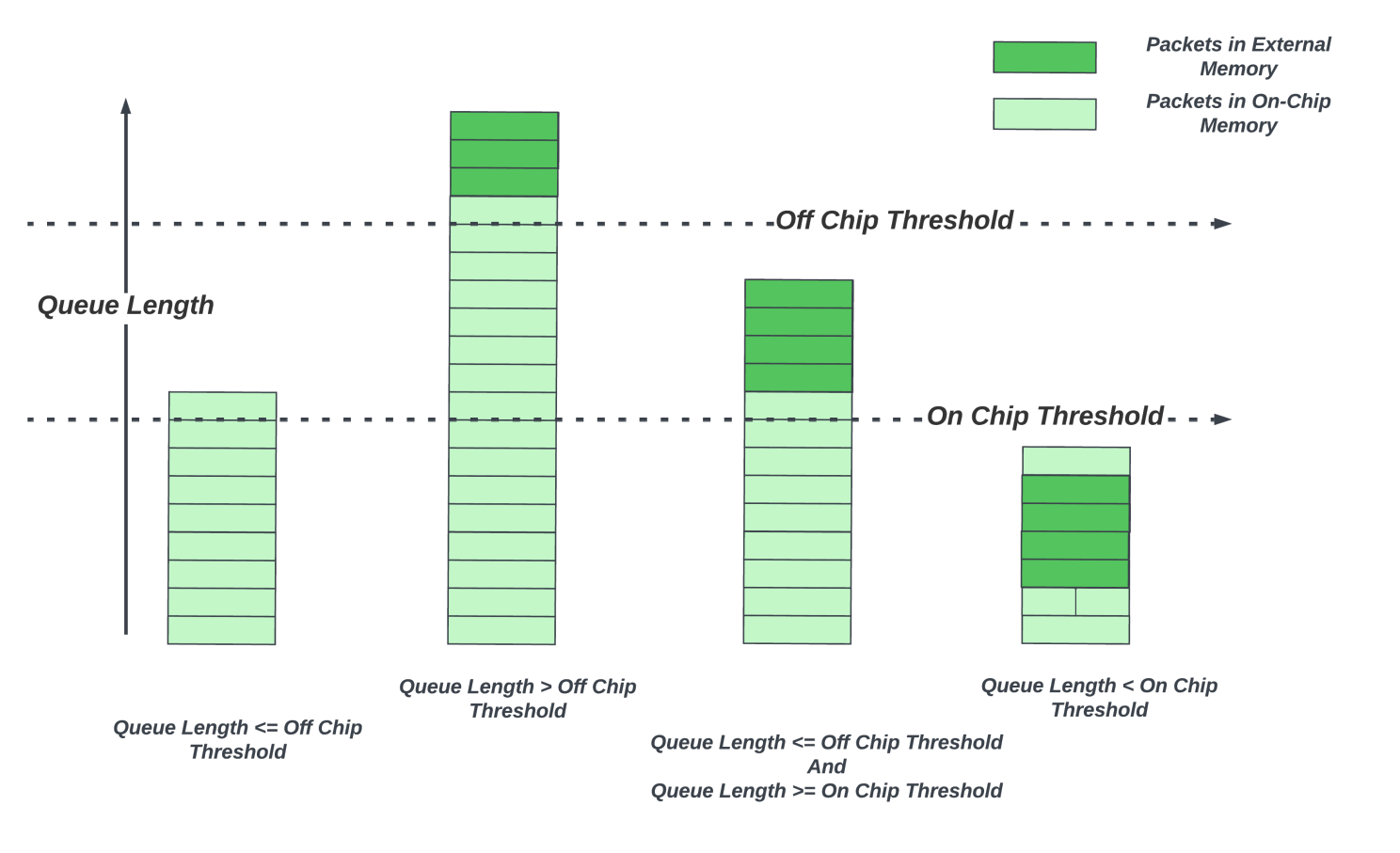
盡管可能有成千上萬個流量流經(jīng)路由器,但先進的擁塞控制算法和更智能的網(wǎng)絡(luò)管理可以讓網(wǎng)絡(luò)流量均勻分布,因此許多流量不會出現(xiàn)持續(xù)擁塞的情況。小規(guī)模的瞬時擁塞事件可以僅由片上緩沖器吸收。只有一小部分隊列會出現(xiàn)持續(xù)擁堵。隨著這些隊列的增長,它們可以從深度緩沖區(qū)中受益。
帶寬為 6.5Tbps 的下一代 24GByte HBM3 部件可為約 2.5Tbps 的輸出鏈路提供約 70 毫秒的延遲帶寬緩沖。假設(shè)在任何時間點擁塞的流量不超過 25%,那么對于 10Tbps 路由 ASIC 來說,一個外部存儲器就足夠了。
構(gòu)建混合緩沖系統(tǒng)
想在路由芯片中構(gòu)建一個混合緩沖子系統(tǒng),使其能夠有效地利用片上和外部存儲器延遲帶寬緩沖并滿足所有的 QoS 要求,還存在著許多挑戰(zhàn)。
共享片上內(nèi)存
一個理想的狀態(tài)是讓所有輸入和輸出鏈路完全共享延遲帶寬緩沖內(nèi)存的片上部分,因為可能會存在擁塞情況,即來自所有輸入端口的數(shù)據(jù)包可能希望從某幾個輸出端口離開。在這些情況下,最好讓這些隊列占用大部分緩沖區(qū)以避免數(shù)據(jù)包丟失。
對于具有 144 個 100G 端口的 14.4Tbps 路由器來說,同時訪問所有這些端口的共享延遲帶寬緩沖區(qū)是一項挑戰(zhàn)。許多高端架構(gòu)使用了兩種技術(shù)讓這種緩沖設(shè)計更加可行。使用寬數(shù)據(jù)總線(wide data buses)允許來自多個 100G 端口的數(shù)據(jù)包共享到共享緩沖區(qū)的同一寬接口。共享緩沖區(qū)本身被靜態(tài)地劃分為許多存儲區(qū),數(shù)據(jù)包被分成更小的塊,并噴灑(spray)到這些存儲區(qū)中,以在多個存儲區(qū)上分配讀/寫。但這樣做有一個副作用,同一數(shù)據(jù)包的不同塊從這些存儲區(qū)中亂序?qū)懭牒妥x取。緩沖區(qū)外部的控制邏輯需要將這些事務按順序排列,然后再呈現(xiàn)給下游區(qū)塊。
一些供應商進一步采用中央共享緩沖區(qū)方法,在延遲帶寬緩沖區(qū)和出口緩沖區(qū)之間共享同一組片上存儲器。這允許針對芯片的不同用例靈活地劃分內(nèi)存。
外部內(nèi)存超額訂閱管理
對于超額訂閱的外部存儲器,需要復雜的算法來決定隊列何時移動到片外延遲帶寬緩沖區(qū)。可以給每個輸出隊列分配一個配置文件,該配置文件告訴隊列在移動到外部存儲器之前可以在片上填充多少。
但是,如果算法僅根據(jù)每個輸出隊列的隊列長度做出獨立決策,那么在多個輸出鏈路極度擁塞時,它可能會決定將傳入流量的很大一部分發(fā)送到片外,而外部存儲器接口不一定可以處理。這給緩沖區(qū)管理邏輯增加了額外的復雜性,需要仔細規(guī)劃跨擁塞隊列的片外移動。
跨隊列分配片上緩沖區(qū)
在業(yè)務邊緣應用程序中,在給定的時間間隔內(nèi)可能有數(shù)千個活動流。由于片上緩沖有限,不可能提供相同的隊列閾值。這些芯片架構(gòu)必須為網(wǎng)絡(luò)運營商提供靈活性,以便為他們配置的每個隊列選擇“配置文件”。但是,通過配置隊列的實際流量可能與預配置速率有很大差異,這會導致緩沖區(qū)空間和資源的使用效率低下。
高級架構(gòu)在基于實時隊列耗盡率動態(tài)調(diào)整混合隊列長度和片外閾值的算法上投入了大量資金,以有效地利用延遲帶寬緩沖區(qū)。一些供應商還實現(xiàn)了高級算法來動態(tài)區(qū)分大象流和老鼠流,并通過調(diào)整這些流的緩沖區(qū)分配來防止老鼠流丟棄數(shù)據(jù)包。
數(shù)據(jù)包抖動
路由器不得對流內(nèi)的數(shù)據(jù)包重新排序。但是,如果隊列在片內(nèi)和外部存儲器之間移動,由于從外部存儲器讀取時會產(chǎn)生數(shù)百個周期的額外延遲,因此需要額外的邏輯來從外部存儲器預取內(nèi)容并保持數(shù)據(jù)包之間的順序要求。該預取向出口緩沖區(qū)添加了額外的緩沖區(qū)。
盡管實施過程中面臨著一定挑戰(zhàn),但在當前工藝節(jié)點/存儲器和封裝技術(shù)下,混合緩沖可能是唯一適用于高容量路由芯片的方法。高端路由芯片供應商正不斷投資高級算法,以有效利用芯片上有限的內(nèi)存資源和有限的外部存儲器帶寬。
未來
在芯片方面,隨著 3D 封裝的發(fā)展,可以將多個芯片(邏輯芯片和存儲芯片的混合)堆疊在一起。當存儲器芯片層堆疊在邏輯芯片上時,邏輯芯片可從存儲器獲得更高的數(shù)據(jù)吞吐量,因為存儲器到邏輯芯片的互連可以使用芯片的整個表面區(qū)域。目前,該技術(shù)主要應用于針對HPC的CPU芯片。用不了多久,高端網(wǎng)絡(luò)芯片供應商將使用這項技術(shù)來增加帶寬和延遲帶寬緩沖區(qū)的容量,以跟上核心內(nèi)聚合的端口容量的增加。
在擁塞控制方面,過去幾十年內(nèi)取得了許多進展,迄今為止已有 20 多種擁塞控制和主動隊列管理 (AQM) 算法。
基于延遲的算法,即發(fā)送者通過密切監(jiān)視流量的往返延遲來調(diào)制進入網(wǎng)絡(luò)的流量,變得越來越流行。FQ-CoDel/PIE 是兩種針對緩沖區(qū)膨脹的 AQM 算法。由谷歌開發(fā)的TCP BBRv2實時構(gòu)建網(wǎng)絡(luò)模型,動態(tài)調(diào)整發(fā)送速率。與傳統(tǒng)的基于數(shù)據(jù)包丟失的算法產(chǎn)生的突發(fā)相比,這些算法還可以更均勻地調(diào)配帶寬,并有助于緩解大型網(wǎng)絡(luò)中的擁塞。
學術(shù)界和工業(yè)界正在不斷努力提高具有不同流量的大型網(wǎng)絡(luò)中的擁塞控制算法的性能、效率和公平性。基于機器學習的網(wǎng)絡(luò)模型也正在開發(fā)中,該模型可以學習實時擁塞情況。任何由端點持續(xù)緩解的擁塞都可以減少路由器中的緩沖區(qū)要求。
因此,隨著混合緩沖和主動隊列管理技術(shù)的進步、高端的3D封裝技術(shù)以及擁塞控制算法的改進,即使高端路由芯片的帶寬每2到3年翻一番,也不需要在緩存上做出取舍。
題外
ADOP(前沿光學科技有限公司)是一家專注于光纖通信設(shè)備和光纖傳輸解決方案的公司。他們提供的產(chǎn)品包括動態(tài)光學平臺(Dynamic Optical Platform)、固態(tài)光學平臺(Fixed Optical Platform)、無源波分復用器、線路保護器、光纖放大器、色散補償、衰減器以及各種光纖交換機
ADOP的交換機設(shè)計理念是提供高性能、高穩(wěn)定性和易于管理的網(wǎng)絡(luò)解決方案。它們通常具有以下特點:
1.高性能處理能力:配備了強大的處理器和高速的內(nèi)存,能夠快速處理大量的網(wǎng)絡(luò)流量,確保數(shù)據(jù)傳輸?shù)母咝省?br />
2.豐富的端口配置:從千兆到萬兆,提供多種端口配置,支持多種網(wǎng)絡(luò)標準,滿足不同網(wǎng)絡(luò)架構(gòu)的接入需求。
此外,ADOP還提供基于InfiniBand和RoCE(RDMA over Converged Ethernet)架構(gòu)的先進AI光交換,光傳輸和相關(guān)配件,專注于利用這些技術(shù)為全球客戶提供成熟、可靠、高效的光互聯(lián)產(chǎn)品和解決方案。他們的使命是通過創(chuàng)新的技術(shù),加速數(shù)據(jù)中心的性能,支持高性能計算(HPC)、人工智能(AI)、機器學習(ML)和大數(shù)據(jù)分析等先進應用
審核編輯 黃宇
-
芯片
+關(guān)注
關(guān)注
459文章
52282瀏覽量
437447 -
光纖
+關(guān)注
關(guān)注
19文章
4122瀏覽量
74816 -
交換機
+關(guān)注
關(guān)注
21文章
2728瀏覽量
101520 -
路由器
+關(guān)注
關(guān)注
22文章
3825瀏覽量
116169
發(fā)布評論請先 登錄
以太網(wǎng)交換機:網(wǎng)絡(luò)世界的指揮家,90%的人不知道它的重要性!
如何實現(xiàn)POE交換機串聯(lián)?
RTOS的流緩沖區(qū)機制解析

工業(yè)路由器和工業(yè)交換機,打造高效穩(wěn)定的工業(yè)網(wǎng)絡(luò)?
進網(wǎng)許可認證、交換路由設(shè)備檢測項目更新25年1月起

交換機與路由器的區(qū)別 交換機的基本工作原理
PCIe交換機與路由器的區(qū)別
VLAN 交換機與路由器的區(qū)別
智算中心網(wǎng)絡(luò)交換機需要什么樣的緩存架構(gòu)

交換機的工作原理是什么?3類交換機故障詳解
二層交換機和三層交換機有什么區(qū)別
ISM交換機如何添加VLAN呢?
ESP8266有雙緩沖區(qū)嗎?
如何將ESP用作Internet交換機?
園區(qū)交換機 VS 數(shù)據(jù)中心交換機






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論