 特斯拉的Occupancy Network占用網絡如何解決無法識別物體的難題呢?
特斯拉的Occupancy Network占用網絡如何解決無法識別物體的難題呢?
Occupancy Network并非特斯拉發明,最先提出Occupancy Network的是2018年的論文《Occupancy Networks: Learning 3D Reconstruction in Function Space》,主要作者是Tubingen大學和博世旗下軟件公司ETAS。更早可以追溯至2012年的論文《Indoor Segmentation and Support Inference from RGBD Images》,主要作者是紐約大學。而最早可以追溯到1986年的論文《A computational approach to edge detection》。Occupancy Network源自語義分割,語義分割需要連續邊界而不是傳統的Bounding Box(一般會縮寫為BBox),語義分割再加上2D或3D重建,就是Occupancy Network。不過讓Occupancy Network揚名天下的是特斯拉。
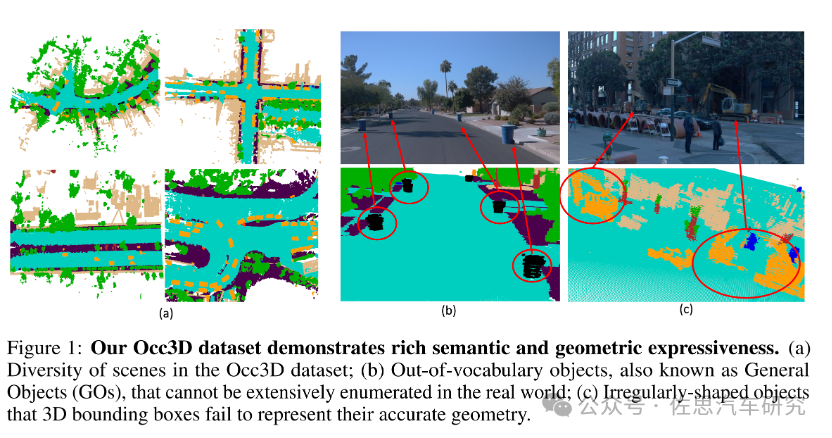
圖片來源:Occ3D
目前,傳統的3D目標感知算法缺點是過于依賴數據集,但數據集的分類有限,通常不超過30類,總有不常見的物體類別沒被標注,這些未被標注的物體再次出現在實際場景中,會因為數據集中沒有標注,無法識別而被感知系統忽略掉,導致車輛不減速直接撞向物體。這種事故經常發生,最典型的是當車輛有故障,駕駛員下車站在車尾,打開后備箱找維修工具,對于計算機視覺來說就是一個難題,這是個打開的后備箱加人的影像,或者人推著電動車或自行車過馬路,人眼可以一眼看出,但機器就徹底傻眼,復合目標,從未被標注的物體或從未出現在數據集的物體,要探測目標距離,必須先識別目標,探測和識別是一體的,無法分割,畫出BBox,機器無法識別,畫不出BBox,會認為前方沒有物體,自然不會減速,直接撞上去。
BBox的致命缺陷,一是無法忽略掉物體的幾何細節,二是探測和識別一體,遇到未被標注的物體就會視而不見。Occupancy Network就是為了解決BBox的缺陷而產生的,Occupancy Network學術上講就是建模物體詳細幾何和語義的通用且連貫的表征。一個需要從輸入圖像中聯合估計場景中每個voxel的占據狀態和語義標簽的模型,其中占據狀態分為free,occupied和unobserved三種,對于occupied的voxel,還需要分配其語義標簽。而對于沒有標注的物體類別,統一劃分為General Objects(GOs),GOs少見但為了安全起見是必須的,否則檢測時經常檢測不到。Occupancy Network理論上能解決無法識別物體的難題,但實際中不能。很簡單,Occupancy Network是一種預測性質的神經網絡,它不可能達到100%的準確度,自然也就有漏網之魚,還是有無法識別的物體無法探測。
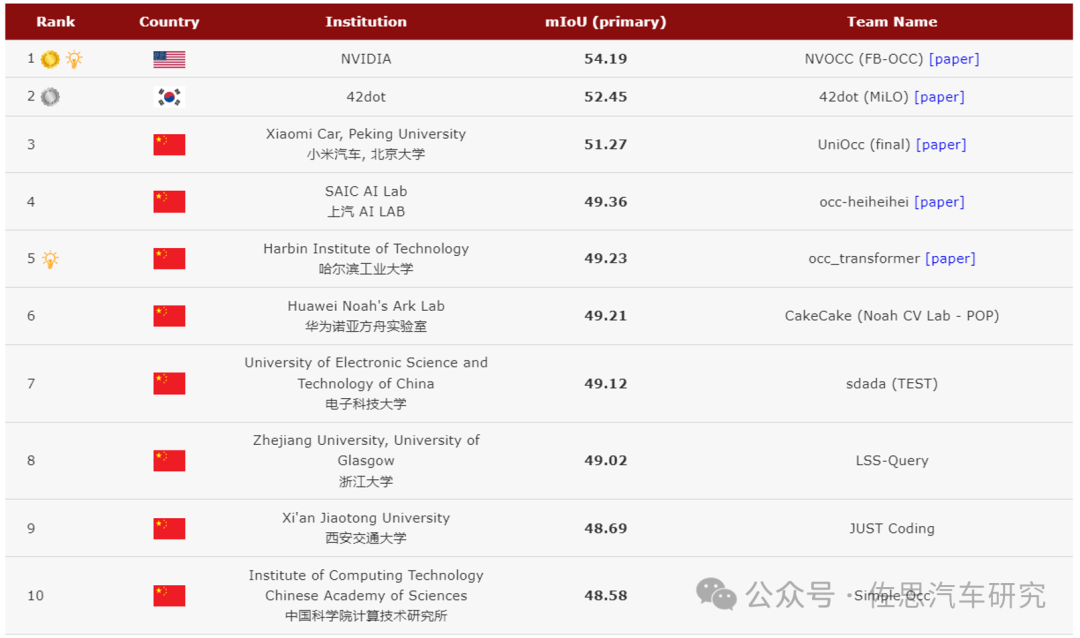
圖片來源:網絡
占用網絡算法排名,第一名是英偉達的FB-OCC,小米和北大聯合的UniOcc排名第三,華為僅排名第六。目前基于BEV的解決方案很多。這些解決方案在經過一定的修改后都可以適用于 3D occupancy 預測,門檻不高。
目前Occupancy Network準確度有多少呢?目前最頂級的Occupancy Network的mIoU是54.19%。mIoU是預測值與真值的交并比,某種意義上可以看做是準確度。這和傳統激光雷達語義分割差距極大,2021年的激光雷達語義分割就能達到80%以上。
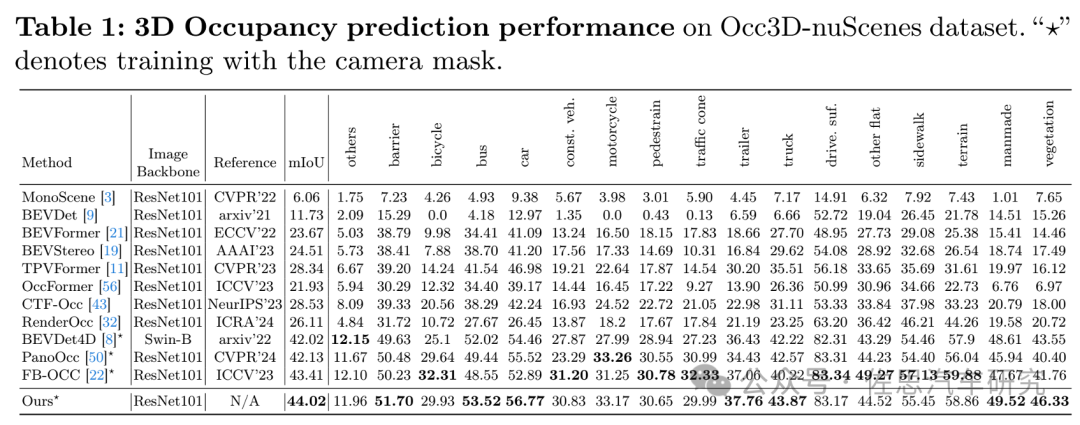
圖片來源:OctreeOcc
另一份資料,OctreeOcc論文中提到,目前得分最高的是上海科技大學的OctreeOcc,也就是上表中的“Ours”。排名第二的是英偉達的FB-OCC,與OctreeOcc差距很小。
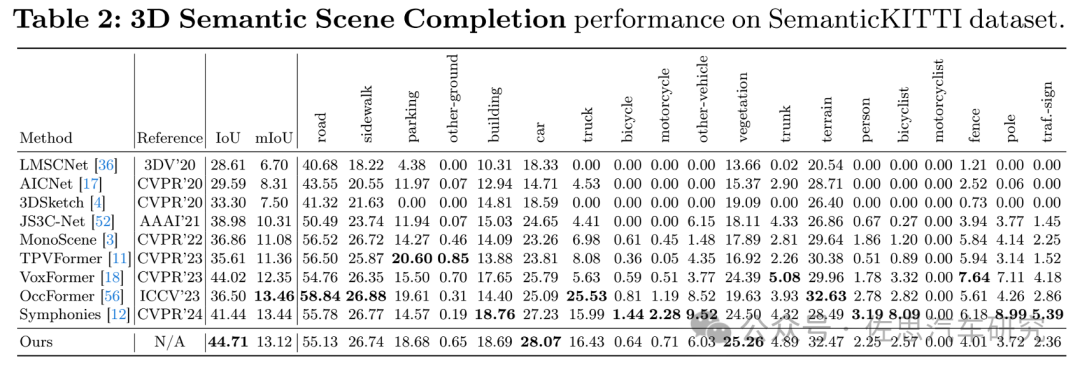
圖片來源:KITTI
KITTI數據集3D語義場景完成的mIoU上得分最高的是鑒智機器人的OccFormer。
我們就來深入了解一下這OctreeOcc、FB-OCC和OccFormer三個模型。
先來看英偉達的FB-OCC,論文《FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation》,論文很簡短,只有5頁。
FB-OCC整體架構
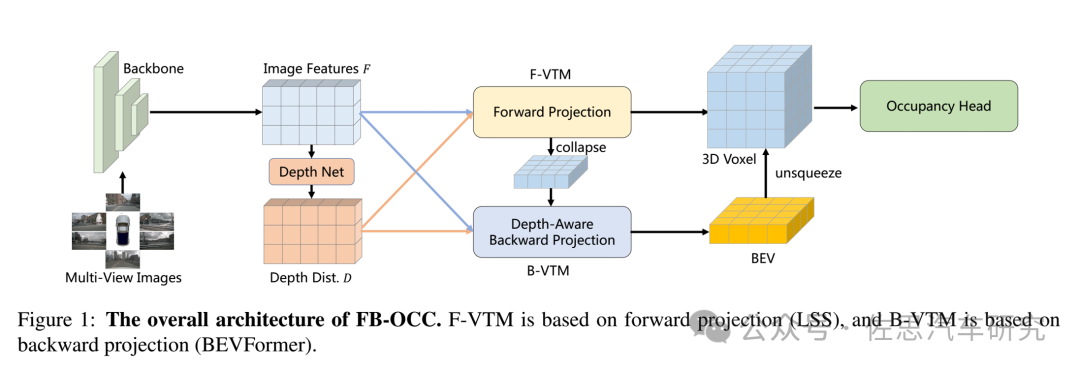
圖片來源:《FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation》論文
FB-OCC的預測頭
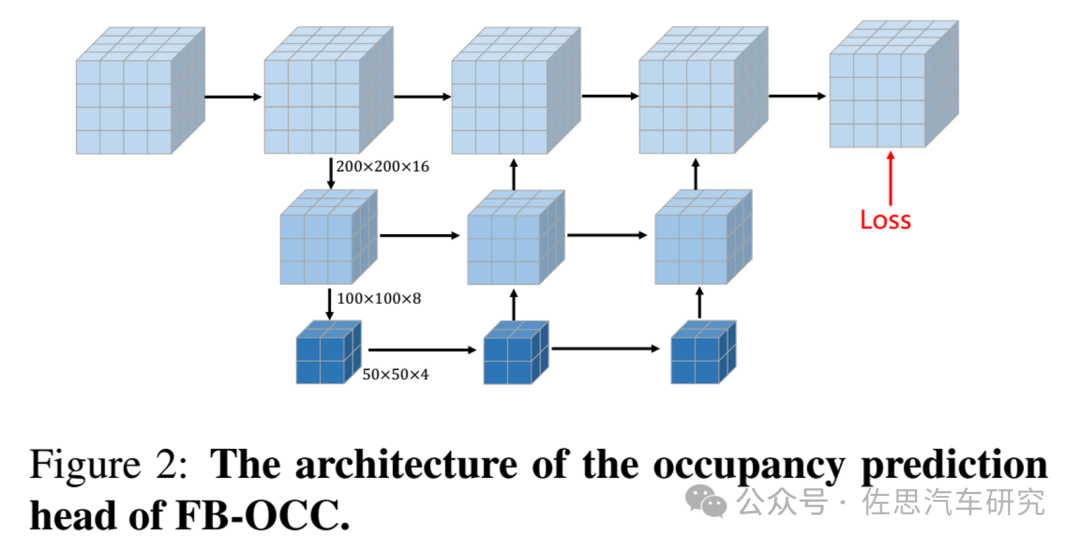
圖片來源:《FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation》論文
語義和深度聯合預訓練
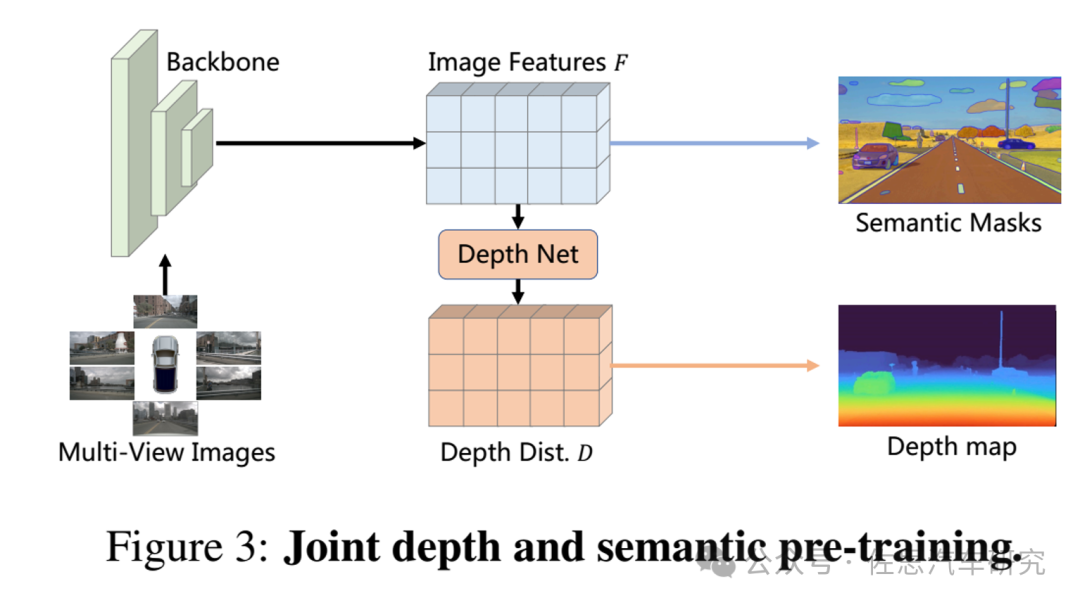
圖片來源:《FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation》論文
英偉達的FB-OCC非常簡潔,基本上就是BEVFormer加了一個占用網絡head。純視覺的3D感知模型的核心模塊是 view transformation 模塊。這個模塊包括兩個主要的視圖轉換方式:正向投影(LSS)和反向投影(BEVFormer)。FB-BEV 提供了一個統一的設計,利用這兩種方法,揚長避短。在FB-OCC中,使用前向投影來生成初始的3D體素表征,然后將其壓縮為一個扁平的 BEV 特征圖。BEV特征圖被視為BEV空間內的queries,并與圖像編碼器特征一起獲得密集的幾何信息。然后將3D體素表征和優化后的BEV表征的融合特征輸入到后續的任務頭中。
英偉達采用了預訓練,通過深度估計任務增強模型的幾何意識。英偉達對nuScenes數據集進行了廣泛的預訓練,主要集中在深度估計上。值得注意的是,深度預訓練缺乏語義層面的監督。為了減輕模型過度偏向深度信息的風險,可能導致語義先驗的損失(特別是考慮到模型的大規模特性,容易出現過擬合),在進行深度預測任務的同時,也要致力于預測二維語義分割標簽,如上圖3所示。
鑒智機器人的OccFormer框架
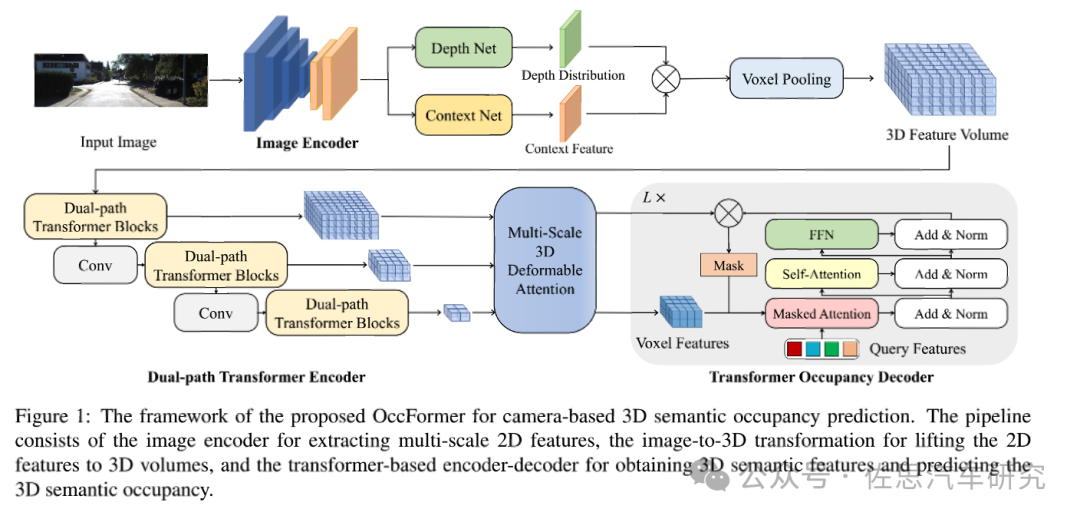
圖片來源:OccFormer
OccFormer以單目圖像或環視圖像作為輸入,首先由圖像編碼器提取多尺度特征,然后基于深度預測和體素Voxel池化得到三維場景特征。隨后,該三維特征首先經過dual-path transformer encoder進行三維視角下的特征提取,得到多尺度體素特征。最終transformer occupancy decoder融合多尺度特征,預測不同類別的binary mask并結合得到最終的occupancy預測。
圖像編碼器的輸出為輸入分辨率的 1/16 的融合特征圖: 來表示提取的特征。
然后是英偉達提出的LSS BEV算法,編碼后的圖像特征被處理以生成 context feature
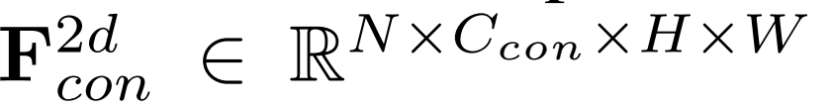
N 是相機視角的數量,C是通道數,(H,W) 代表分辨率。
離散的深度分布是
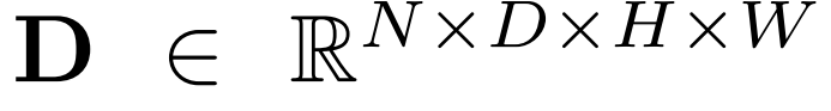
二者相乘得到點云的表示:
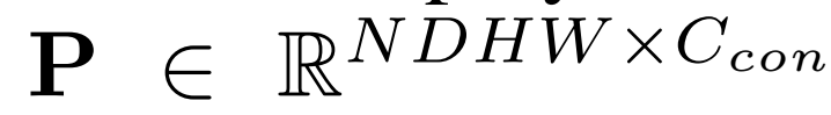
最終進行體素池化以創建三維特征 3D feature volume

其中(X, Y, Z) 表示三維體的分辨率。

圖片來源:OccFormer
由于駕駛場景中沿著水平方向的信息變化最劇烈,而高度方向上信息密度相對較低,因此三維特征編碼的重點應該放在水平方向上。但由于occupancy需要三維的細粒度信息,將三維特征完全壓平進行處理是不可取的。輸入的三維特征會經過局部和全局兩條路徑、沿著水平方向進行語義特征提取,兩條路徑的輸出會通過自適應融合得到輸出的三維場景特征。對于輸入的三維特征,局部 local 和全局 global 路徑首先沿水平方向并行地聚集語義信息。接下來,雙路徑輸出通過 sigmoid-weighted 進行融合。局部路徑主要針對提取細粒度的語義結構。由于水平方向包含最多的變化,通過一個共享編碼器并行處理所有BEV切片能夠保留大部分語義信息。將高度維度合并到批處理維度,并使用窗口化自注意力作為局部特征提取器,它可以利用較小的計算量動態地關注遠距離區域;另一方面,全局路徑旨在高效捕獲場景級語義布局。為此,全局路徑首先通過沿高度維度進行平均池化來獲取BEV特征,并采用相同的窗口化自注意力實現特征提取,為了進一步增大全局感受野,還使用了ASPP結構來捕獲全局上下文。
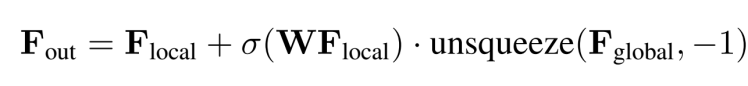
W指的是沿高度維度生成聚合權重的 FFN;σ(·) 是 sigmoid 函數;“unsqueeze” 是沿高度方向擴展全局 2D 特征。
語義分割方面采用了META提出的Mask2Former ,Mask2Former建立在一個簡單的元框架 (MaskFormer)和一個新的 Transformer 解碼器上,其關鍵組成部分為掩碼注意力(Masked-attention),通過將交叉注意力限制在預測的掩碼區域內來提取局部特征。與為每個任務(全景、實例或語義)設計專門模型相比,Mask2Former 節省了3倍的研究工作,并且有效節省計算資源。Mask2Former 在全景分割(COCO上的 57.8 PQ)、實例分割(COCO 上的 50.1 AP)和語義分割(ADE20K 上的 57.7 mIoU)上都實現了SOTA。
利用輸入的多尺度體素特征 (multi-scale voxel features) 和參數化的查詢特征 (parameterized query features) ,transformer decoder 對查詢特征進行迭代更新,以達到預期的類別語義。在每個迭代內,查詢特征 (queries features)Q1, 通過 masked attention 來關注它們相對應前景區域。
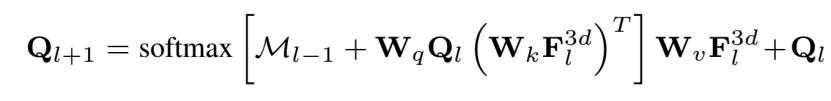
然后進行 self-attention,以交換上下文信息,然后用FFN進行特征投影。在每個迭代結束時,每個Q1被投影來預測它的語義分對數 (semantic logits)Pi,和掩膜嵌入 (mask embedding)εmask,后者通過 一個 per-voxel 嵌入εvoxel和 sigmoid 函數的點積進一步轉化為二進制的三維掩膜Mi。
OctreeOcc框架
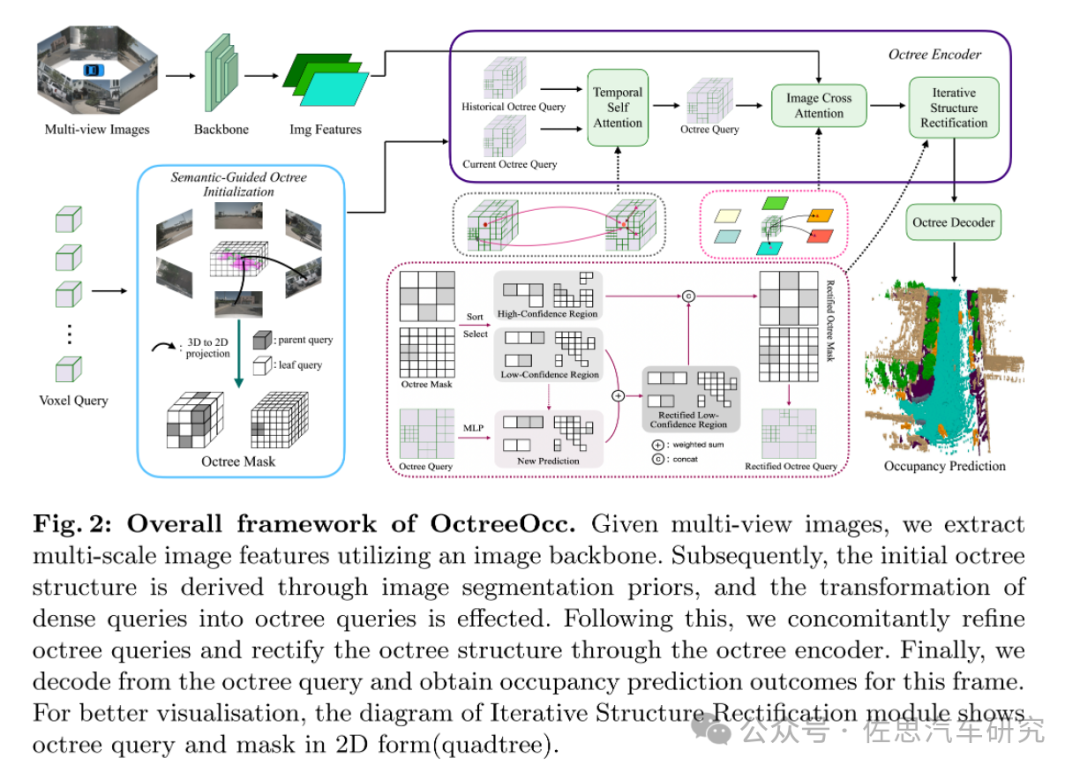
圖片來源:OctreeOcc
OctreeOcc框架如上圖, 實際就是用傳統的八叉數空間表示法取代了傳統的BEV或Voxel。
不過目前這些前沿試驗性質的論文都無法落地。
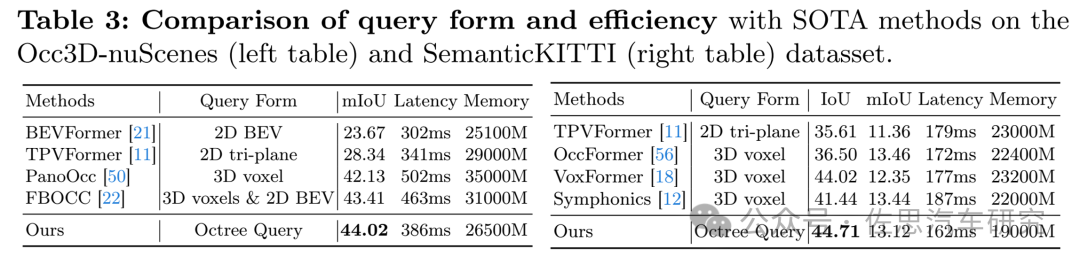
圖片來源:OctreeOcc
左邊的是Occ3D-nuScenes,專為占用網絡測試搞的數據集,右邊的是KITTI的語義分割測試數據集,占用網絡模型消耗內存驚人,最少都需要25GB,對運算資源消耗驚人,即便是用英偉達8張A100,最快的也要386毫秒,自動駕駛最低門檻10Hz都達不到。這個每幀都需要讀出模型一次,也就說需要容量至少超過48GB的高寬帶存儲,最好是HBM3,GDDR6都非常勉強,而HBM價格驚人,英偉達H100的HBM內存容量也不過80GB。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3739瀏覽量
136333 -
神經網絡
+關注
關注
42文章
4793瀏覽量
102044 -
特斯拉
+關注
關注
66文章
6360瀏覽量
127936 -
激光雷達
+關注
關注
970文章
4123瀏覽量
191415
原文標題:特斯拉的Occupancy Network占用網絡真能解決無法識別物體難題?
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
網絡分析器無法識別模型
怎樣去解決無法使用內置Bootloader的DFU方式進行固件升級的問題
基于深度神經網絡的激光雷達物體識別系統
新能源車車牌無法識別怎么辦_新能源車牌識別不了

華為云虛擬專用網絡VPN,如何解決企業出海難題






 工商網監
工商網監
評論