") 系統(tǒng)中的latency是如何產(chǎn)生的
系統(tǒng)中的latency是如何產(chǎn)生的

在當(dāng)今數(shù)字時(shí)代,手機(jī)已成為人們?nèi)粘I钪胁豢苫蛉保嗳蝿?wù)處理和實(shí)時(shí)響應(yīng)對(duì)于用戶體驗(yàn)越來(lái)越重要,搶占(preemption)機(jī)制在提升系統(tǒng)性能和用戶體驗(yàn)方面發(fā)揮了至關(guān)重要的作用。內(nèi)核搶占機(jī)制使得系統(tǒng)能夠有效地管理多任務(wù)處理,確保系統(tǒng)對(duì)用戶操作的快速響應(yīng),并在資源緊張的情況下仍能保持穩(wěn)定和流暢的運(yùn)行。
本篇文檔旨在詳細(xì)探討Linux內(nèi)核中的搶占機(jī)制,涵蓋其基本概念、實(shí)現(xiàn)細(xì)節(jié)、性能影響以及相關(guān)的調(diào)試方法。通過(guò)對(duì)搶占機(jī)制的深入解析,我們希望能夠幫助讀者更好地理解和優(yōu)化Linux系統(tǒng)的性能,并在實(shí)際工作應(yīng)用這些知識(shí)。
為了使內(nèi)容組織更清晰,本文檔將使用Linux6.1內(nèi)核,按照以下結(jié)構(gòu)展開(kāi):
1.基本概念:首先講解系統(tǒng)中的latency是如何產(chǎn)生的,為什么會(huì)產(chǎn)生
2.內(nèi)核搶占的實(shí)現(xiàn)機(jī)制:從latency的角度說(shuō)明了為什么需要搶占,什么是搶占,內(nèi)核的搶占模型是怎么樣的,內(nèi)核中搶占點(diǎn)的設(shè)置、搶占計(jì)數(shù)的機(jī)制,以及如何在內(nèi)核代碼中控制搶占
3.Linux內(nèi)核中的搶占實(shí)現(xiàn):什么是內(nèi)核搶占和實(shí)現(xiàn)方式,包括在什么情況下會(huì)發(fā)生搶占以及搶占的觸發(fā)條件
4.實(shí)例分析:通過(guò)實(shí)際案例中一個(gè)高優(yōu)先級(jí)的線程長(zhǎng)時(shí)間搶占不到資源,來(lái)看如何定位類似問(wèn)題
1. latency in linux
內(nèi)核搶占允許高優(yōu)先級(jí)任務(wù)中斷正在執(zhí)行的低優(yōu)先級(jí)任務(wù),從而減少調(diào)度延遲,提高系統(tǒng)響應(yīng)性,那么我們就需要知道對(duì)于Linux內(nèi)核中有哪些因素會(huì)導(dǎo)致響應(yīng)不及時(shí)。首先,我們來(lái)看看典型應(yīng)用場(chǎng)景如下:
一個(gè)硬件中斷發(fā)生,并通過(guò)喚醒一個(gè)更高優(yōu)先級(jí)的任務(wù),一段時(shí)間后,高優(yōu)先級(jí)的任務(wù)才得以執(zhí)行,那么latency是實(shí)時(shí)響應(yīng)關(guān)注的重點(diǎn)。
接下來(lái)細(xì)化該過(guò)程,初始狀態(tài)時(shí),進(jìn)程處于睡眠等待,中斷發(fā)生,到喚醒這個(gè)進(jìn)程,等待選核選到這個(gè)任務(wù),最后發(fā)生上下文切換,直到該進(jìn)程運(yùn)行,這個(gè)時(shí)間經(jīng)歷了以下幾個(gè)完整的完成,這個(gè)統(tǒng)稱為一次Scheduling latency。
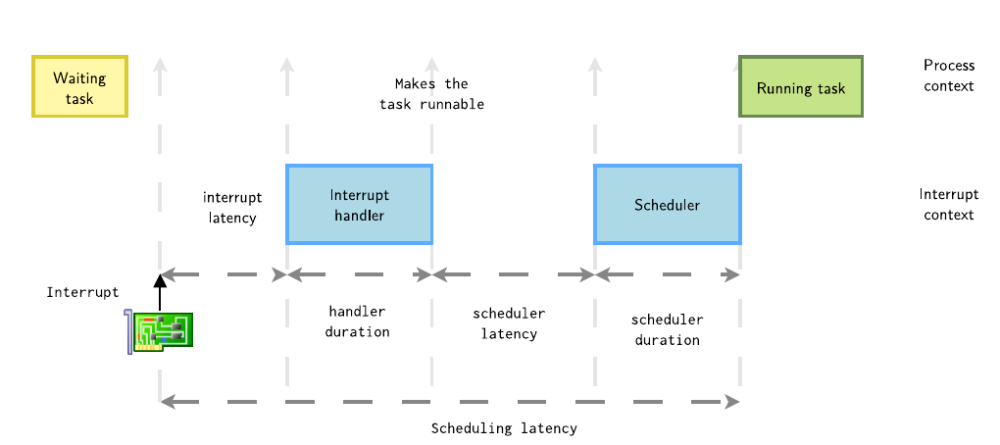
這一次的內(nèi)核調(diào)度延遲 = 中斷延遲(interrupt latency) + 處理程序持續(xù)時(shí)間(handler duration) + 調(diào)度程序延遲(scheduler latency) + 調(diào)度程序持續(xù)時(shí)間(scheduler duration),每一個(gè)過(guò)程都會(huì)影響這個(gè)高優(yōu)先級(jí)任務(wù)的實(shí)時(shí)響應(yīng)。
1.1 中斷延遲
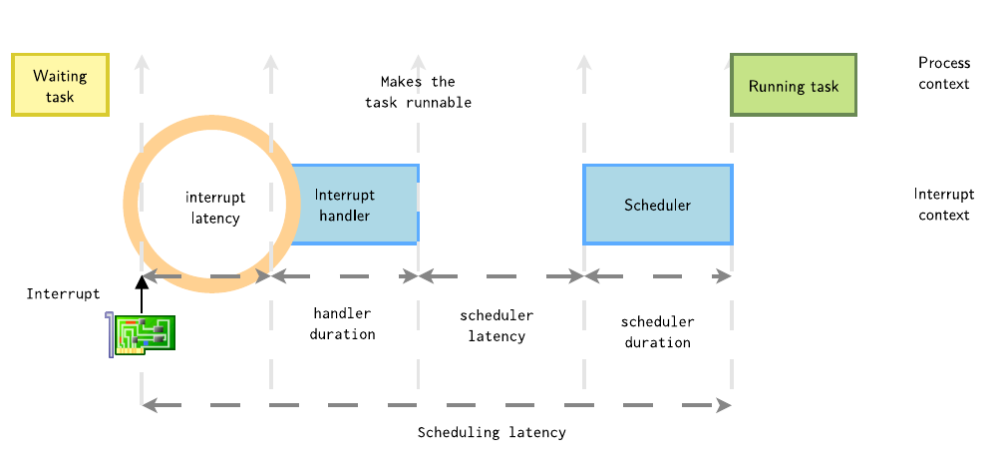
在T0時(shí)刻,外設(shè)中斷發(fā)生,從中斷發(fā)生到linux內(nèi)核響應(yīng)這個(gè)中斷,之間有一個(gè)延時(shí),稱為中斷延時(shí),中斷延遲的來(lái)源主要有以下原因:
1. 內(nèi)核中大量使用了并發(fā)預(yù)防機(jī)制之一就是自旋鎖,并且這個(gè)是一個(gè)common的接口供所有的模塊使用,所以主要的來(lái)源就是中斷在內(nèi)核中被disable,如spinlock_irq()和spinlock_irq_irqsave(),此時(shí)當(dāng)中斷發(fā)生時(shí)候,內(nèi)核處于關(guān)中斷狀態(tài)。
2. 中斷控制器的調(diào)度延遲,現(xiàn)代的中斷控制器支持中斷優(yōu)先級(jí)調(diào)度,當(dāng)多個(gè)中斷同時(shí)發(fā)生時(shí),內(nèi)核會(huì)通過(guò)比較中斷的優(yōu)先級(jí)來(lái)決定處理的順序。較高優(yōu)先級(jí)的中斷會(huì)被優(yōu)先處理,以保證對(duì)緊急事件的及時(shí)響應(yīng)。因此,它可能會(huì)被高優(yōu)先級(jí)中斷
3. 中斷處理會(huì)切換模式,保存寄存器狀態(tài)等,這個(gè)時(shí)間很短
4. Shared Interrupt Line:當(dāng)多個(gè)設(shè)備共享同一個(gè)中斷時(shí),中斷控制器需要識(shí)別和區(qū)分不同的中斷源,這個(gè)能有效地減少系統(tǒng)中斷線的數(shù)量,節(jié)省硬件成本。然而,它也帶來(lái)了一些潛在的問(wèn)題,其中之一就是中斷延遲的增加
1.2 中斷處理程序持續(xù)時(shí)間
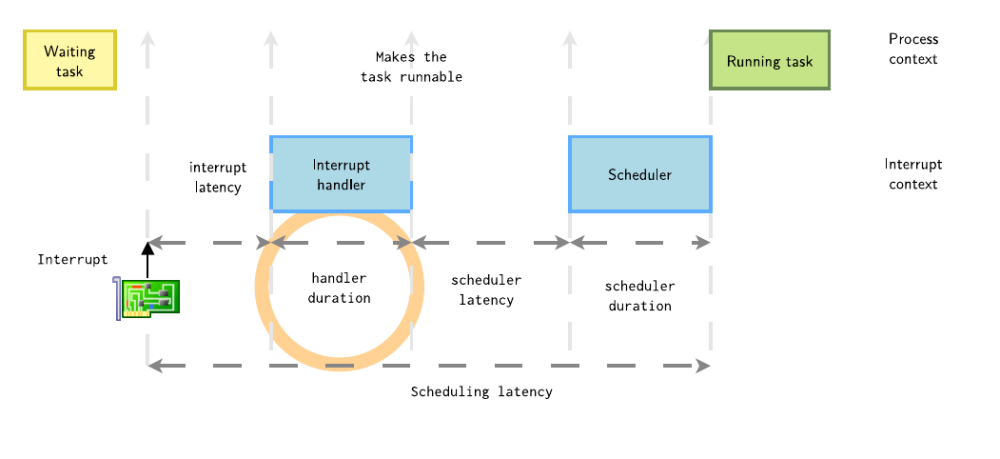
在T1時(shí)刻,CPU響應(yīng)了這個(gè)中斷,在Linux內(nèi)核的中斷處理分為上半部和下半部
1. 上半部分,它在禁用中斷的情況下運(yùn)行,并且應(yīng)該盡快完成
2. 由上半部分調(diào)度的下半部分,在所有待處理的上半部分完成執(zhí)行后開(kāi)始,下半部分是開(kāi)中斷情況下執(zhí)行,可能被其他中斷打斷
如下圖,在處理完中斷A上部分后,其他外設(shè)中斷發(fā)生,CPU轉(zhuǎn)而處理其他中斷,這樣延遲處理中斷A下半部,我們把開(kāi)始響應(yīng)中斷到這個(gè)處理的時(shí)間稱為中斷處理延遲,其處理的整個(gè)過(guò)程如下圖所示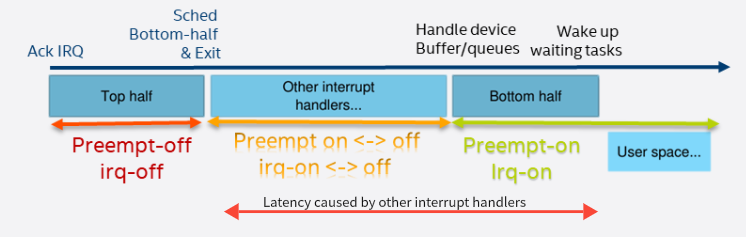 ? ?
? ?
對(duì)于前面兩個(gè)過(guò)程,我們?cè)诰帉懲庠O(shè)驅(qū)動(dòng)的時(shí)候,要特別注意,里面設(shè)計(jì)大量的關(guān)中斷和關(guān)搶占的過(guò)程,特別我們?cè)谝恍┳孕i以及變體的接口,使用不當(dāng)會(huì)導(dǎo)致響應(yīng)不及時(shí),例如中斷響應(yīng)不及時(shí),高優(yōu)先級(jí)任務(wù)遲遲得不到調(diào)度,給用戶的直接感受就是卡頓。
1.3 調(diào)度延遲
在T2時(shí)刻,中斷處理完后,喚醒了進(jìn)程。從喚醒進(jìn)程到進(jìn)程被調(diào)度器選中的這段延時(shí)稱為調(diào)度延時(shí)。
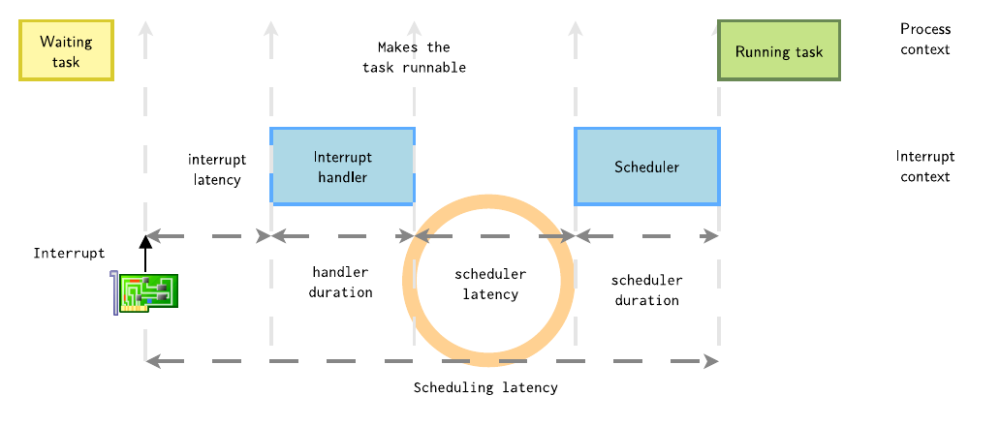
其產(chǎn)生調(diào)度延時(shí)的主要原因如下:
調(diào)度器選中進(jìn)程A的時(shí)間也是不確定的,可能就緒隊(duì)列中有比進(jìn)程A優(yōu)先級(jí)更高的進(jìn)程
對(duì)于這個(gè),就需要了解搶占,盡快的通過(guò)搶占來(lái)完成任務(wù)的切換工作。對(duì)于Linux內(nèi)核是一個(gè)支持搶占式操作系統(tǒng),當(dāng)一個(gè)任務(wù)運(yùn)行在用戶空間并被中斷打斷時(shí),如果中斷處理程序喚醒另外一個(gè)任務(wù),我們從中斷處理返回后可以立即調(diào)度該任務(wù)。對(duì)于不同內(nèi)核支持不同的搶占方式,處理方式也會(huì)不同,這個(gè)后面會(huì)詳細(xì)介紹,這里只是作為一個(gè)引子,目前存在以下情況會(huì)影響調(diào)度延遲
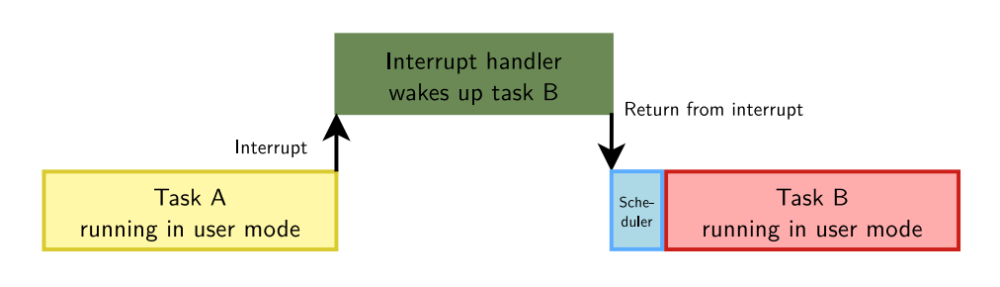
當(dāng)中斷發(fā)生時(shí),linux內(nèi)核正在自旋鎖臨界區(qū)里執(zhí)行,這樣,中斷完成后,不能馬上搶占調(diào)度,必須等待linux內(nèi)核執(zhí)行完自旋鎖臨界區(qū)才能搶占調(diào)度,這也會(huì)導(dǎo)致延遲的增加,并且很難被發(fā)現(xiàn)如下圖所示
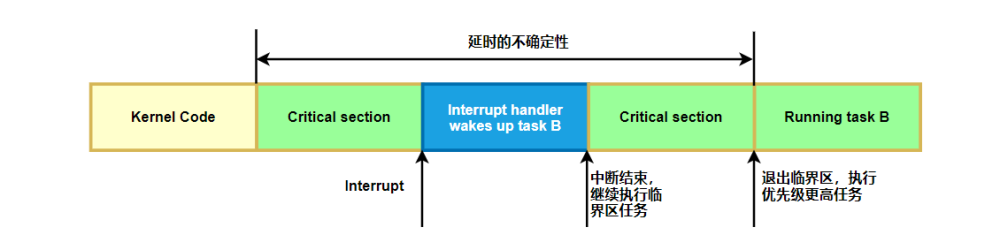
1.4 調(diào)度持續(xù)時(shí)間
在T3時(shí)刻,調(diào)度器選中了進(jìn)程A,還需要進(jìn)行上下文切換后才能執(zhí)行進(jìn)程A,上下文切換也是具有一定的延時(shí)性
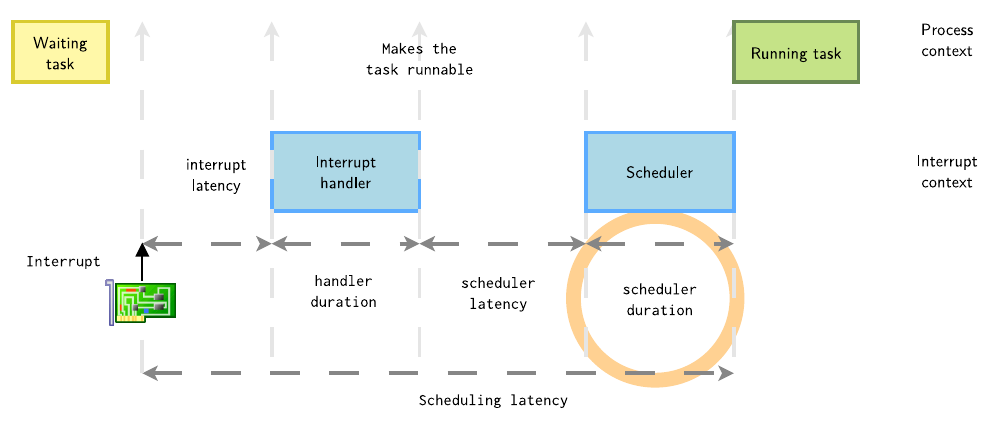 ? ?
? ?
除了前面詳細(xì)講解的關(guān)鍵路徑之外,Linux的其他非確定性機(jī)制也會(huì)影響實(shí)時(shí)任務(wù)的執(zhí)行時(shí)間,例如linux是一個(gè)基于虛擬內(nèi)存,由MMU提供,因此內(nèi)存是按需分配的。每當(dāng)應(yīng)用程序首次訪問(wèn)代碼和數(shù)據(jù)時(shí),它都是按需加載的,這也會(huì)導(dǎo)致巨大的延時(shí),同時(shí)C庫(kù)服務(wù)和內(nèi)核服務(wù)在設(shè)計(jì)的時(shí)候并未考慮實(shí)時(shí)約束。
1.5優(yōu)先級(jí)倒置
內(nèi)核搶占是指操作系統(tǒng)內(nèi)核能夠在某些情況下?lián)屨颊谶\(yùn)行的任務(wù)并切換到更高優(yōu)先級(jí)的任務(wù)。但是在實(shí)際的場(chǎng)景中,可能會(huì)存在優(yōu)先級(jí)翻轉(zhuǎn)的問(wèn)題導(dǎo)致系統(tǒng)響應(yīng)下降。
例如,低優(yōu)先級(jí)的進(jìn)程可能持有高優(yōu)先級(jí)所需要的鎖,從而有效地降低該進(jìn)程的優(yōu)先級(jí),如果中等優(yōu)先級(jí)進(jìn)程使用CPU,情況可能會(huì)更糟。在簡(jiǎn)單的情況下,只要低優(yōu)先級(jí)任務(wù)(任務(wù) L)持有鎖,高優(yōu)先級(jí)任務(wù)(任務(wù) H)就會(huì)被阻塞。這被稱為“有界優(yōu)先級(jí)反轉(zhuǎn)”,因?yàn)榉崔D(zhuǎn)的時(shí)間長(zhǎng)度受低優(yōu)先級(jí)任務(wù)在臨界區(qū)(持有鎖)中的時(shí)間長(zhǎng)度的限制。
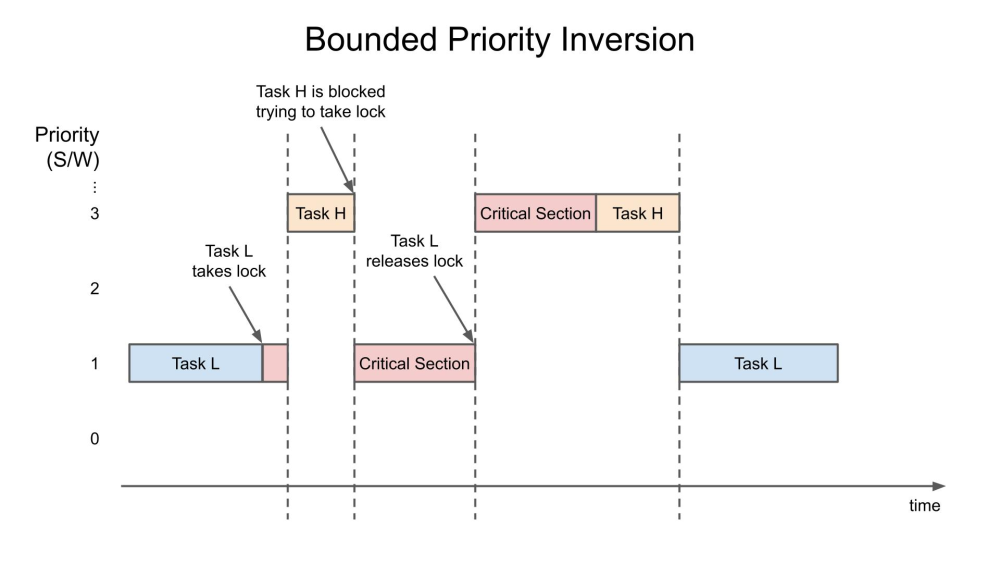
當(dāng)中等優(yōu)先級(jí)任務(wù)(任務(wù) M)在持有鎖時(shí)中斷任務(wù) L 時(shí),會(huì)發(fā)生無(wú)限優(yōu)先級(jí)反轉(zhuǎn)。之所以稱為“無(wú)界”,是因?yàn)槿蝿?wù) M 現(xiàn)在可以有效地阻止任務(wù) H 任意時(shí)間,因?yàn)槿蝿?wù) M 正在搶占任務(wù) L(它仍然持有鎖)。下面簡(jiǎn)化了這種危險(xiǎn)的事件序列,其過(guò)程如下:
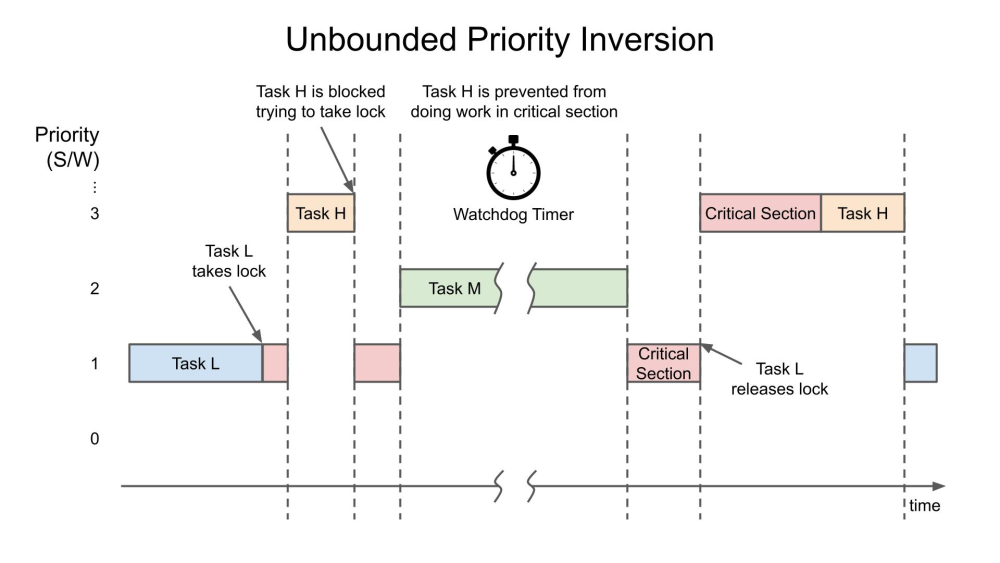
低優(yōu)先級(jí)任務(wù)L和高優(yōu)先級(jí)的任務(wù)H共享資源,在任務(wù)L獲取資源后不久,任務(wù)H就開(kāi)始運(yùn)行。但是任務(wù)H必須等待任務(wù)L完成資源,因此它被掛起
在任務(wù)L完成資源之前,任務(wù)M準(zhǔn)備好運(yùn)行,搶占任務(wù)L,當(dāng)任務(wù)M(可能還有其他中等優(yōu)先級(jí)的任務(wù))運(yùn)行時(shí),系統(tǒng)中的最高優(yōu)先級(jí)任務(wù)H仍然處于掛起狀態(tài)。
2. 為什么需要內(nèi)核搶占
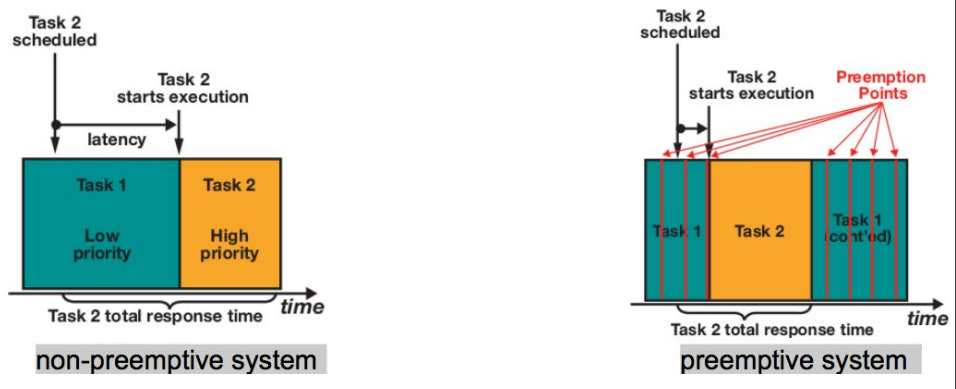
當(dāng)一個(gè)以優(yōu)先級(jí)為主的調(diào)度器中,當(dāng)一個(gè)新的進(jìn)程(下圖中的task2)進(jìn)入到可執(zhí)行(running)的狀態(tài),核心的調(diào)度器會(huì)檢查它的優(yōu)先級(jí),若該進(jìn)程的優(yōu)先權(quán)比目前正在執(zhí)行的進(jìn)程(下圖中的task1)還高,核心調(diào)度器便會(huì)觸發(fā)搶占(preempt),使得正在執(zhí)行的進(jìn)程被打斷,而擁有更高優(yōu)先級(jí)的進(jìn)程會(huì)開(kāi)始執(zhí)行。
 ? ?
? ?
在不支持內(nèi)核搶占模型中,搶占點(diǎn)比較少,對(duì)于內(nèi)核搶占,如右圖會(huì)在系統(tǒng)中添加很多搶占點(diǎn),同時(shí)會(huì)導(dǎo)致執(zhí)行時(shí)間會(huì)比左圖多一點(diǎn),可搶占會(huì)導(dǎo)致每隔一定時(shí)間去檢查是否需要搶占,這樣也會(huì)影響cache,pipeline,這樣就會(huì)犧牲吞吐量。從上面圖可以看出,操作系統(tǒng)演進(jìn)過(guò)程中,不是新的就一定比舊的好,需要考量場(chǎng)景選擇合適的方案。從這張圖我們可以看出,內(nèi)核搶占主要解決以下問(wèn)題:
提高系統(tǒng)響應(yīng)實(shí)時(shí)性和用戶體驗(yàn):在不支持內(nèi)核搶占式內(nèi)核中,低優(yōu)先級(jí)任務(wù)可能會(huì)長(zhǎng)時(shí)間占用CPU,導(dǎo)致高優(yōu)先級(jí)任務(wù)無(wú)法及時(shí)得到處理,主要解決的是latency問(wèn)題。這種情況會(huì)顯著影響系統(tǒng)的響應(yīng)速度,特別是在實(shí)時(shí)應(yīng)用中,可能導(dǎo)致嚴(yán)重的性能問(wèn)題。對(duì)于手機(jī)場(chǎng)景中,當(dāng)用戶在使用應(yīng)用程序時(shí),內(nèi)核搶占可以確保用戶界面關(guān)鍵線程得到足夠的CPU時(shí)間,避免界面卡頓和延遲。
避免優(yōu)先級(jí)翻轉(zhuǎn):內(nèi)核搶占結(jié)合優(yōu)先級(jí)繼承(Priority Inheritance)等機(jī)制,可以有效緩解優(yōu)先級(jí)翻轉(zhuǎn)問(wèn)題。當(dāng)?shù)蛢?yōu)先級(jí)任務(wù)持有高優(yōu)先級(jí)任務(wù)需要的資源時(shí),內(nèi)核搶占機(jī)制可以提高低優(yōu)先級(jí)任務(wù)的優(yōu)先級(jí),使其盡快釋放資源,從而減少高優(yōu)先級(jí)任務(wù)的等待時(shí)間。在Linux中,從2.6開(kāi)始,rtmutex支持優(yōu)先級(jí)繼承,解決優(yōu)先級(jí)翻轉(zhuǎn)的問(wèn)題。
所以需要內(nèi)核搶占的根本原因就是系統(tǒng)在吞吐量和及時(shí)響應(yīng)之間進(jìn)行權(quán)衡的結(jié)果,對(duì)于Linux作為一個(gè)通用的操作系統(tǒng),其最初設(shè)計(jì)就是為了throughput而非確定性時(shí)延而設(shè)計(jì)。但是越來(lái)越多的場(chǎng)景對(duì)及時(shí)響應(yīng)的要求越來(lái)越高,讓更高優(yōu)先級(jí)的任務(wù)和關(guān)鍵的任務(wù)及時(shí)得到調(diào)度,特別對(duì)于我們手機(jī)這種交互式的場(chǎng)景中。
3.搶占模型
將搶占視為減少調(diào)度程序延遲的一種方法可能很有用,但減少延遲通常也會(huì)影響吞吐量,因此需要在完成大量工作(高吞吐量)和在任務(wù)準(zhǔn)備好運(yùn)行時(shí)立即調(diào)度任務(wù)(低延遲)之間保持平衡。Linux 內(nèi)核支持多種搶占模型,以便您可以根據(jù)工作負(fù)載調(diào)整搶占行為。為了讓用戶根據(jù)自己的需求進(jìn)行配置,Linux 提供了 3 種 Preemption Model:
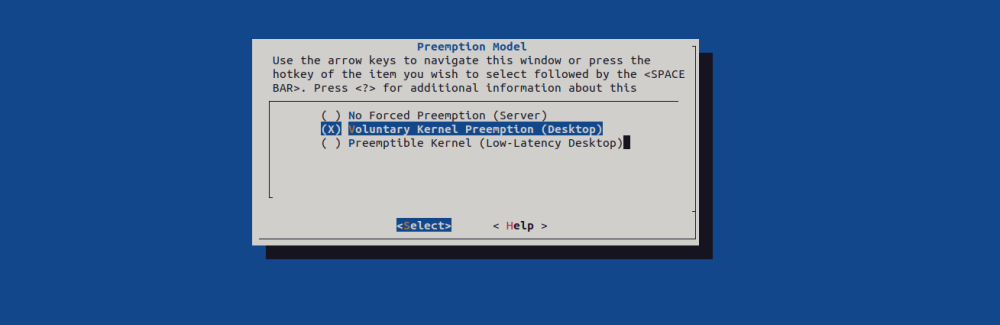
CONFIG_PREEMPT_NONE=y:不允許內(nèi)核搶占,吞吐量最大的 Model,一般用于 Server 系統(tǒng),其特點(diǎn)如下(紅色:non-preemptible,綠色:preemptible):

該模式下只支持用戶搶占,系統(tǒng)調(diào)用返回和中斷是唯一的搶占點(diǎn)
CONFIG_PREEMPT_VOLUNTARY=y:內(nèi)核核心系統(tǒng)的開(kāi)發(fā)者開(kāi)始著手做低延遲優(yōu)化,其中一個(gè)優(yōu)化點(diǎn)就是如果有高優(yōu)先級(jí)進(jìn)程需要處理器,內(nèi)核代碼也可以被搶占。在一些耗時(shí)較長(zhǎng)的內(nèi)核代碼中主動(dòng)調(diào)用cond_resched()讓出CPU,對(duì)吞吐量有輕微影響,但是系統(tǒng)響應(yīng)會(huì)稍微快一些。主動(dòng)搶占(voluntary preemption)功能,它為內(nèi)核增加了一個(gè)受限的內(nèi)核搶占模式,并且一直使用到現(xiàn)在。

通過(guò)向運(yùn)行在內(nèi)核模式下的幾個(gè)代碼添加顯式搶占點(diǎn),目前內(nèi)核中有近千個(gè)搶占點(diǎn),檢查是否經(jīng)常需要重新調(diào)度,并且通過(guò)增加必須使用搶占的頻率,減少搶占延遲。
CONFIG_PREEMPT=y:除了處于持有 spinlock 時(shí)的 critical section,其他時(shí)候都允許內(nèi)核搶占,響應(yīng)速度進(jìn)一步提升,吞吐量進(jìn)一步下降,一般用于 Desktop / Embedded 系統(tǒng),目前Andorid中使用的這個(gè)配置項(xiàng)
 ? ?
? ?
正如搶占選項(xiàng)名稱所暗示的那樣,這些設(shè)置中的每一項(xiàng)都有適當(dāng)?shù)挠美7?wù)器搶占可用于吞吐量是最重要的。另一方面,實(shí)時(shí)搶占應(yīng)該用在嵌入式系統(tǒng)中,其中絕對(duì)吞吐量并不重要,但最大體驗(yàn)延遲才是關(guān)鍵。因此,Linux中不同的搶占級(jí)別可以在不同的環(huán)境中提供很大的靈活性

另外,還有一個(gè)沒(méi)有合并進(jìn)主線內(nèi)核的 Model: CONFIG_PREEMPT_RT,這個(gè)模式幾乎將所有的 spinlock 都換成了 preemptable mutex,只剩下一些極其核心的地方仍然用禁止搶占的 spinlock,所以基本可以認(rèn)為是隨時(shí)可被搶占,這部分不在本文討論的范圍之內(nèi)。
4. 什么是內(nèi)核搶占
說(shuō)起這個(gè)搶占,在 Linux 內(nèi)核的 2.4 時(shí)代,除非主動(dòng)調(diào)度schedule,否則通常只允許從 system call 或者 interrupt 返回用戶態(tài)的時(shí)候發(fā)生搶占(即產(chǎn)生中斷前,也在用戶態(tài)),這可稱之為 "User Preemption"。對(duì)于用戶搶占,只支持程序執(zhí)行在用戶態(tài)空間的時(shí)候,才可以被搶占,如果進(jìn)程在Kernel空間執(zhí)行(系統(tǒng)調(diào)用),是不允許搶占的。其執(zhí)行過(guò)程如下:
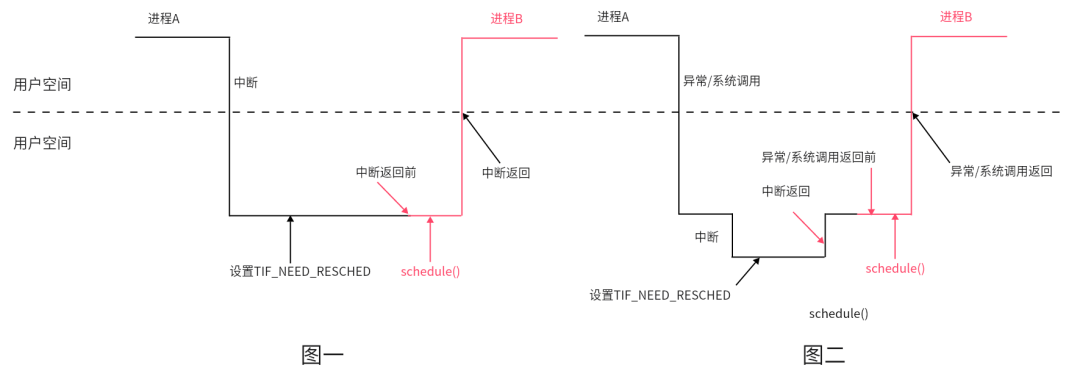
如上圖一,假設(shè)周期性中斷發(fā)生在進(jìn)程A用戶空間,此時(shí)進(jìn)入到內(nèi)核空間,在周期性調(diào)度器實(shí)現(xiàn)函數(shù)中設(shè)置了進(jìn)程A的TIF_NEED_RESCHED標(biāo)記位,則在時(shí)鐘中斷處理程序返回用戶空間前夕,將調(diào)用schedule()函數(shù)執(zhí)行進(jìn)程調(diào)度
如上圖二,假設(shè)周期性中斷發(fā)生在進(jìn)程A在內(nèi)核空間運(yùn)行之時(shí),時(shí)鐘中斷返回前并不會(huì)執(zhí)行進(jìn)程調(diào)度,因?yàn)檫@時(shí)返回的是內(nèi)核空間,而不是用戶空間。在進(jìn)程A從內(nèi)核空間返回用戶空間前的工作中,才會(huì)檢測(cè)TIF_NEED_RESCHED標(biāo)記位,置位則執(zhí)行進(jìn)程調(diào)度
何為內(nèi)核搶占?簡(jiǎn)單地說(shuō)就是當(dāng)進(jìn)程進(jìn)入內(nèi)核空間運(yùn)行時(shí),能否被搶占,被剝奪CPU控制權(quán),執(zhí)行進(jìn)程調(diào)度,從而運(yùn)行其它進(jìn)程。還是以中斷和異常為例,對(duì)比其差異
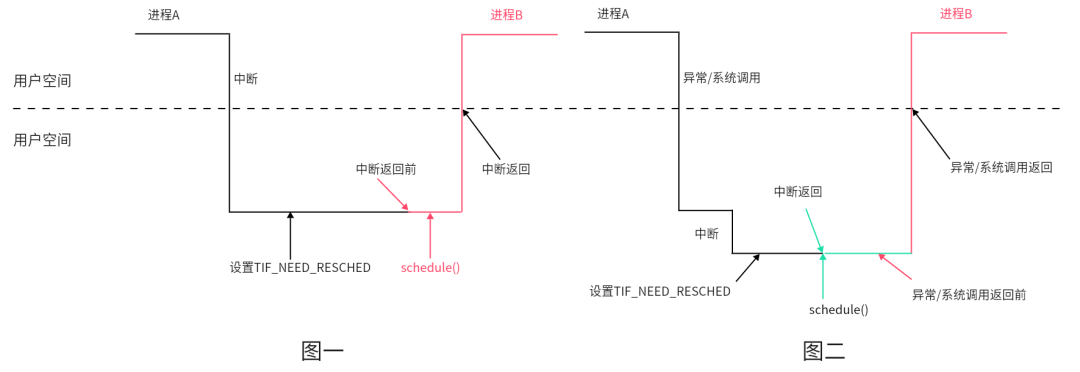
如上圖一,假設(shè)周期時(shí)鐘中斷發(fā)生在進(jìn)程A用戶空間,此時(shí)的處理與不支持內(nèi)核搶占時(shí)相同,在中斷處理程序返回用戶空間前夕的工作中,執(zhí)行進(jìn)程調(diào)度。
如上圖二,假設(shè)周期時(shí)鐘中斷發(fā)生在進(jìn)程A在內(nèi)核空間運(yùn)行時(shí),在時(shí)鐘中斷處理程序返回內(nèi)核空間前的工作中就可能會(huì)執(zhí)行進(jìn)程調(diào)度(搶占計(jì)數(shù)需為0)。如果在中斷處理程序返回內(nèi)核空間前沒(méi)有執(zhí)行進(jìn)程調(diào)度,則在返回用戶空間前執(zhí)行,與不支持內(nèi)核搶占時(shí)相同。
5.Linux搶占標(biāo)志位--TIF_NEED_RESCHED
首先,我們從數(shù)據(jù)結(jié)構(gòu)開(kāi)始,我們會(huì)詳細(xì)探討thread_info數(shù)據(jù)結(jié)構(gòu)和它在Linux搶占中的作用和關(guān)系
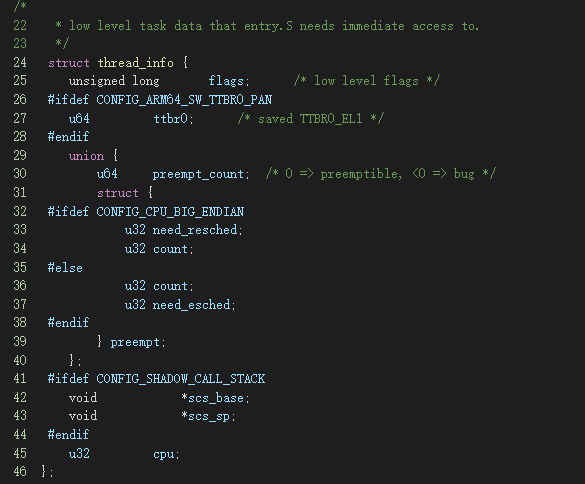
這個(gè)數(shù)據(jù)結(jié)構(gòu)與搶占的發(fā)展歷程也有關(guān)系,其提供功能如下:
調(diào)度標(biāo)志位設(shè)置:早期的Linux,只需要調(diào)用set_tsk_need_resched 給當(dāng)前任務(wù)設(shè)置 struct thread_info 的 TIF_NEED_RESCHED 標(biāo)志,所以就提供了一個(gè)thread_info的flags中有一個(gè)是TIF_NEED_RESCHED,后面會(huì)詳細(xì)介紹
搶占計(jì)數(shù):為了實(shí)現(xiàn)內(nèi)核搶占,新加入preempt_count,這筆提交請(qǐng)參考arm64: preempt: Provide our own implementation of asm/preempt.h,可以發(fā)現(xiàn)它是一個(gè)共用體,內(nèi)核某些路徑使用preempt_count,有的是preempt,為何會(huì)使用這么奇怪的定義呢?后面將詳細(xì)揭曉答案
內(nèi)核如何檢查一個(gè)進(jìn)程是否需要被調(diào)度呢?早期的Linux,在即將返回用戶空間時(shí),檢查進(jìn)程是否需要重新調(diào)度,如果設(shè)置了,就會(huì)發(fā)生調(diào)度,內(nèi)核主要是在thread_info的flag重設(shè)置標(biāo)識(shí)來(lái)標(biāo)記進(jìn)程是否需要被調(diào)度,即重新調(diào)度need_resched標(biāo)識(shí)TI_NEED_RESCHED,其主要的接口函數(shù)為

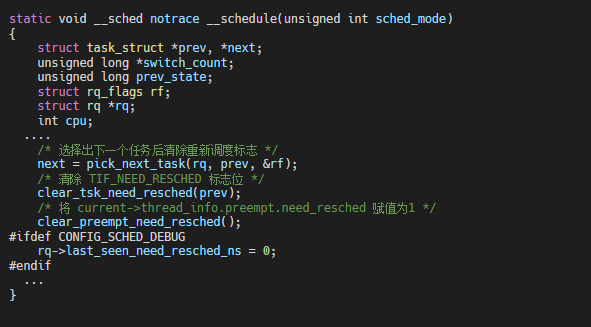
當(dāng)內(nèi)核的某個(gè)路徑設(shè)置重新調(diào)度標(biāo)志(如時(shí)鐘中斷tick 時(shí)),會(huì)調(diào)用到resched_curr 來(lái)設(shè)置重新調(diào)度標(biāo)志:可以看到除了設(shè)置任務(wù)的flags 的TIF_NEED_RESCHED 標(biāo)志外,還設(shè)置了preempt.need_resched 為0

清搶占標(biāo)志,__schedule 中pick到下一個(gè)任務(wù)后會(huì)清除搶占標(biāo)志,其代碼實(shí)現(xiàn)為:
6. 搶占計(jì)數(shù)preempt_count
在像Linux這樣的多任務(wù)系統(tǒng)中,任何執(zhí)行線程都不能保證只要它想運(yùn)行就可以獨(dú)占訪問(wèn)處理器。內(nèi)核總是有能力(多數(shù)情況下)搶占一個(gè)正在運(yùn)行的線程,而選擇一個(gè)優(yōu)先級(jí)更高的線程來(lái)執(zhí)行。新線程可能是另一個(gè)不同的進(jìn)程,但也可能是一個(gè)硬件中斷,或者其他外部事件。
為了正確協(xié)調(diào)系統(tǒng)中所有任務(wù)能正確運(yùn)行,內(nèi)核必須跟蹤當(dāng)前的執(zhí)行狀態(tài),包括已經(jīng)被搶占或可能阻止線程被搶占的各種情況。用來(lái)進(jìn)行這個(gè)追蹤記錄的基礎(chǔ),就是在系統(tǒng)中每個(gè)任務(wù)里存儲(chǔ)的 preemption counter。這個(gè)計(jì)數(shù)器是通過(guò) preempt_count() 函數(shù)來(lái)訪問(wèn)的,它的通用定義是這樣的:

這個(gè) counter 可以用來(lái)指示當(dāng)前線程的狀態(tài)、它是否可以被搶占,以及它是否被允許睡眠。要實(shí)現(xiàn)這個(gè)功能的話,就必須在這個(gè) counter 里面記錄若干種不同狀態(tài),因此這個(gè) preempt_count 也被分成了幾個(gè)字段(sub-fields):
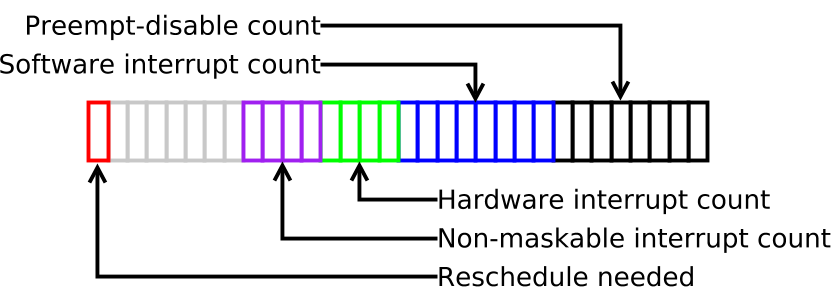
最低位的這個(gè) byte 是用來(lái)記錄 preempt_disable()嵌套調(diào)用的次數(shù),也就是到目前為止 preemption 被 disable 的次數(shù)。
SOFTIRQ:當(dāng)CPU進(jìn)入軟中處理程序時(shí),對(duì)該位域加1,退出時(shí)減1
HARDIRQ:當(dāng)CPU進(jìn)入硬件中斷處理函數(shù)時(shí),對(duì)該位域加1,退出時(shí)減1,位域數(shù)值表示中斷嵌套層級(jí)
NMI:CPU進(jìn)入不可屏蔽中斷處理函數(shù)時(shí),此位置1,退出時(shí)清0。
最后,最高位表示內(nèi)核是否已經(jīng)決定當(dāng)前進(jìn)程需要在后面執(zhí)行時(shí)一有機(jī)會(huì)就馬上被調(diào)度出去,讓給其他任務(wù)。
接下來(lái),我們看看內(nèi)核是如何定義這塊的,其定義在include/linux/preempt.h

其每個(gè)bit的定義如下:
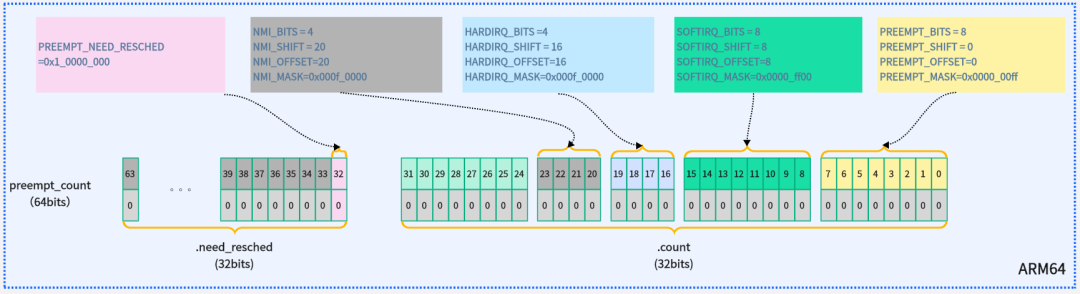
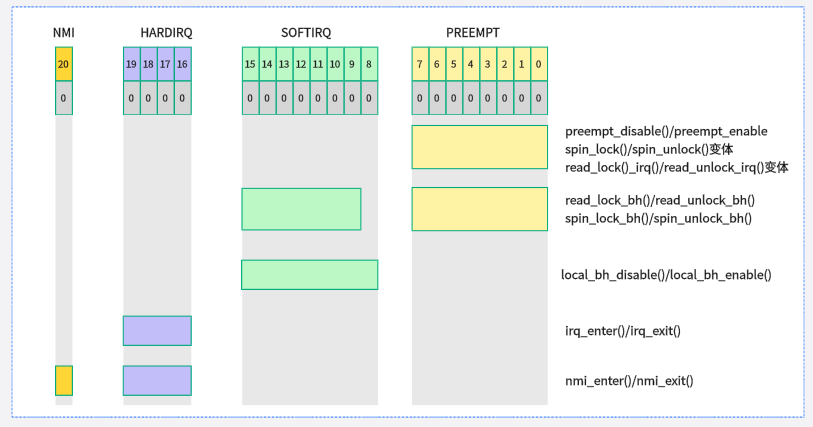
這里需要特別注意,preempt_count是允許嵌套的,在進(jìn)入臨界區(qū),被中斷打斷,軟中斷都會(huì)存在preempt_count。下圖展示了preempt_count相關(guān)的操作函數(shù)

這里要特別注意irq這個(gè),它包含了NMI、IRQ和SOFTIRQ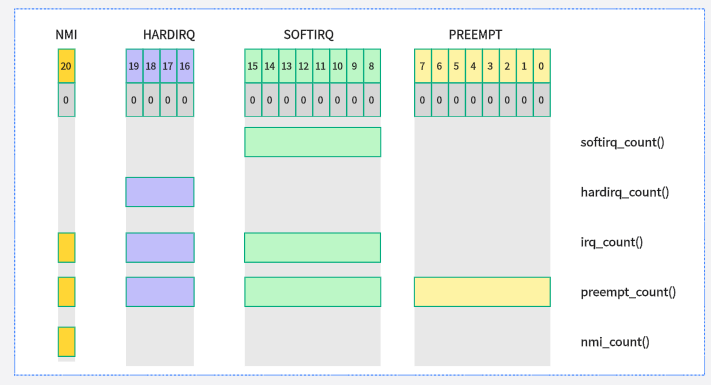 ? ?
? ?
下圖是preempt_count相關(guān)的條件判斷函數(shù),這個(gè)在搶占中會(huì)頻繁用到

以下接口函數(shù)用于檢測(cè)preempt_count成員相應(yīng)位域值,用于檢測(cè)CPU是否處于硬件中斷、軟中斷等處理函數(shù)中(include/linux/preempt.h):
in_irq():當(dāng)前CPU是否處于硬件中斷處理程序內(nèi),返回HARDIRQ計(jì)數(shù)值。
in_softirq():當(dāng)前CPU是否處于軟中斷處理函數(shù)內(nèi)或禁止軟中斷,返回SOFTIRQ計(jì)數(shù)值。
in_serving_softirq():當(dāng)前CPU是否處于軟中斷處理函數(shù)內(nèi)。
in_nmi():CPU是否處于不可屏蔽中斷處理程序內(nèi),返回NMI計(jì)數(shù)值。
in_interrupt():CPU是否處于中斷處理程序內(nèi)(或禁止軟中斷狀態(tài)),包括硬件中斷、軟中斷和不可屏蔽中斷。
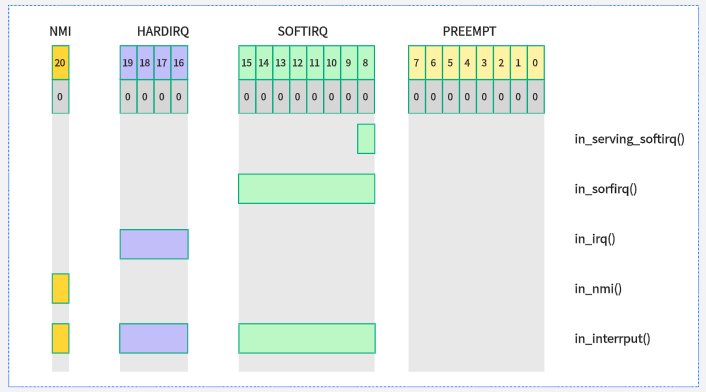
只要看一下 preempt_count 的值,內(nèi)核就可知道當(dāng)前的情況如何。比如,preempt_count 是非零值,就表示當(dāng)前線程不能被 scheduler 搶占:要么是 preemption 已經(jīng)被明確 disable 了,要么是 CPU 當(dāng)前正在處理某種中斷。
同理,非零值也表示當(dāng)前線程不能睡眠,因?yàn)樗丝淘谶\(yùn)行的上下文必須要持續(xù)執(zhí)行完成。"reschedule needed" 這個(gè) bit 告訴內(nèi)核,當(dāng)前有一個(gè)優(yōu)先級(jí)較高的進(jìn)程應(yīng)該在第一時(shí)間獲得 CPU。必須要在 preempt_count 為非零值的情況下,才會(huì)設(shè)置這個(gè) bit。否則的話,內(nèi)核早就可以直接對(duì)這個(gè)進(jìn)程進(jìn)行 prempt 搶占,而不是設(shè)置此 bit 并等待。
那么哪些情況下,會(huì)操作preempt_count,下面是preempt_count相關(guān)操作函數(shù)
 ? ?
? ?
對(duì)于這些接口以及相關(guān)變體,都是內(nèi)核中通用的接口API,所以系統(tǒng)實(shí)時(shí)性會(huì)受驅(qū)動(dòng)中如何使用這些接口的影響。這里我們來(lái)看看經(jīng)常討論的中斷上下文、進(jìn)程上下文和atomic上下文的關(guān)系,首先我們來(lái)看看代碼實(shí)現(xiàn):
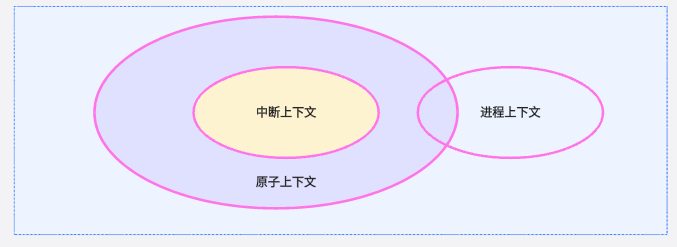
所以總結(jié)一下,對(duì)于內(nèi)核什么時(shí)候不允許搶占,在哪些時(shí)機(jī)是不可調(diào)度的,想要搞清這個(gè)問(wèn)題,首先需要介紹一下linux中的四類區(qū)間:
中斷
軟中斷
進(jìn)程上下文中的spin_lock
進(jìn)程上下文中的其他區(qū)域
上述四類區(qū)間中,只有第四類區(qū)間支持搶占調(diào)度,對(duì)于1,2,3也就是atomic上下文。當(dāng)可以調(diào)度的事情發(fā)生在前3類區(qū)間中,即如果在這3類區(qū)間中喚醒了高優(yōu)先級(jí)的可以搶占的task,實(shí)際上卻不能搶占,直到這3類區(qū)間結(jié)束。那么對(duì)于4類區(qū)間是不是一定能發(fā)生搶占呢?
7. preempt_enable
為了支持內(nèi)核搶占 而引入了 preempt_count ,如果為 0,就允許 Kernel Preemption,否則就不允許。內(nèi)核函數(shù)preempt_enable/preempt_disable用來(lái)內(nèi)核代碼臨界區(qū)動(dòng)態(tài)關(guān)閉和打開(kāi)內(nèi)核搶占,詳細(xì)的用法請(qǐng)參考preempt-locking。
內(nèi)核代碼中preempt_disable()和preempt_enable()函數(shù)總是成對(duì)出現(xiàn)的,用于保證進(jìn)程在執(zhí)行這兩個(gè)函數(shù)之間的代碼時(shí),不會(huì)發(fā)生進(jìn)程調(diào)度(當(dāng)前進(jìn)程不會(huì)被搶占,不被搶占不是說(shuō)不能被中斷,硬件中斷還是允許的,只是中斷還是返回原進(jìn)程)
preempt_disable()函數(shù)用于禁止內(nèi)核搶占,函數(shù)定義如下(include/linux/preempt.h)

這個(gè)比較簡(jiǎn)單,preempt_count加一,然后做了一個(gè)內(nèi)存屏障,增加搶占計(jì)數(shù)器以防止重新調(diào)度,不管處于哪種搶占模式,都不允許搶占。
內(nèi)核搶占函數(shù)preempt_enable()定義在include/linux/preempt.h頭文件內(nèi):
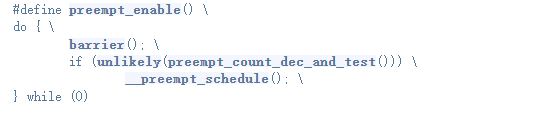
preempt_enable()函數(shù)內(nèi)對(duì)搶占計(jì)數(shù)值減1,如果減1后為0,并且進(jìn)程TIF_NEED_RESCHED標(biāo)記置位了,則調(diào)用__preempt_schedule()函數(shù)執(zhí)行進(jìn)程調(diào)度(搶占當(dāng)前進(jìn)程)。

對(duì)于ARM64,使用64位的preempt_count,通過(guò)將其劃分為count和need_resched來(lái)管理,判斷 preempt_count 和 TIF_NEED_RESCHED 看是否可以被搶占
 ? ?
? ?
這個(gè)首先來(lái)檢查若當(dāng)前CPU處于關(guān)中斷狀態(tài)和preempt_count不為0,就禁止搶占,反之就執(zhí)行搶占。
內(nèi)核代碼里面通常直接調(diào)用preempt_enable比較少,但是調(diào)用鎖的地方比較多,例如常見(jiàn)的spinlock等,目前內(nèi)核的這種鎖機(jī)制又是一個(gè)處于泛濫的趨勢(shì),所以可以認(rèn)為每次調(diào)用spinlock結(jié)束時(shí)默認(rèn)都會(huì)發(fā)起一次隱式搶占

8. Linux內(nèi)核中的搶占實(shí)現(xiàn)
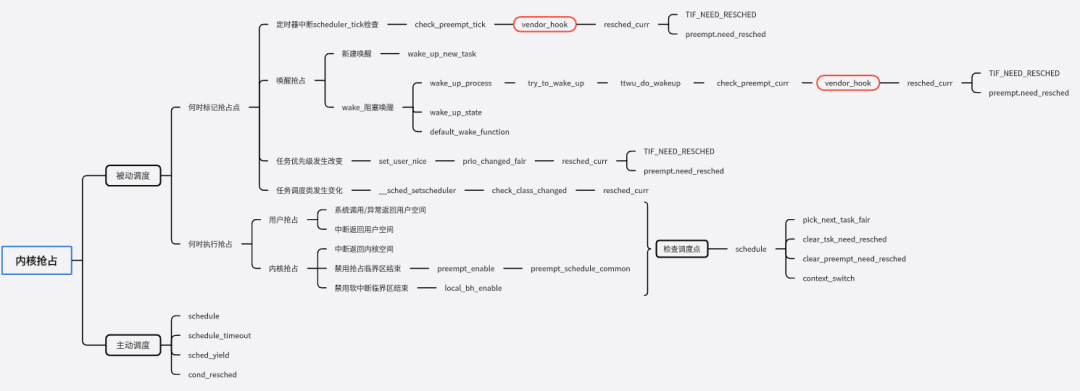
在當(dāng)前進(jìn)程被搶占的場(chǎng)景下,調(diào)度并不是立刻發(fā)生,而是延遲執(zhí)行,具體的方法是設(shè)定當(dāng)前進(jìn)程的need_resched等于1,然后靜靜的等待最近一個(gè)調(diào)度點(diǎn)的來(lái)臨,當(dāng)調(diào)度點(diǎn)到來(lái)的時(shí)候,內(nèi)核會(huì)調(diào)用schedule函數(shù),搶占當(dāng)前task的執(zhí)行。這部分的內(nèi)容比較多,有興趣的同學(xué)可以自行查看源碼,大致梳理了一個(gè)相關(guān)知識(shí)的導(dǎo)圖。
9. 案例分析
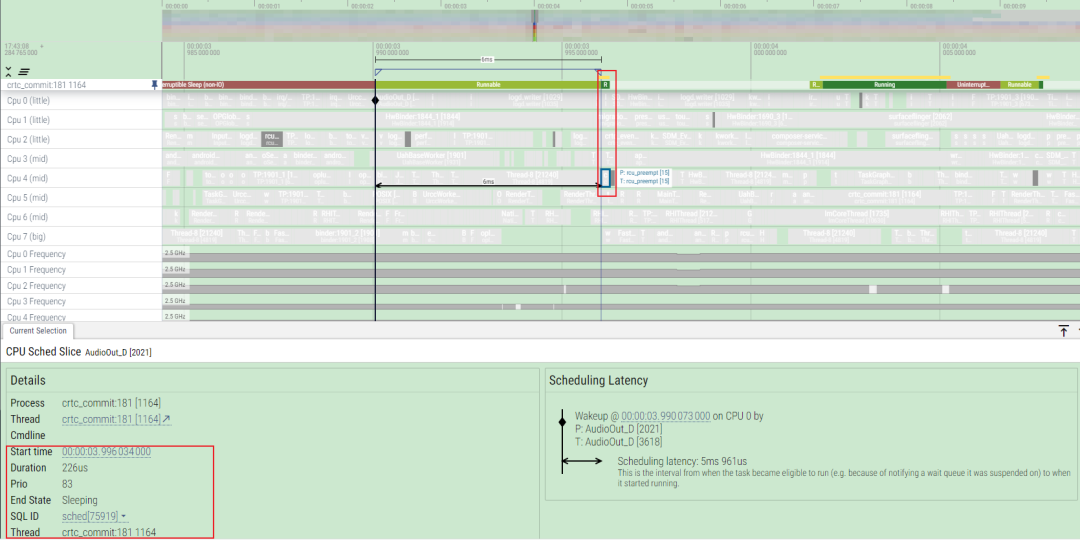
對(duì)于性能開(kāi)發(fā)的同學(xué),經(jīng)常會(huì)遇到這種runnable很長(zhǎng)的問(wèn)題,那么我們以下面這個(gè)為例,crtc_commit的RT線程長(zhǎng)時(shí)間runnable,為什么沒(méi)搶占cfs的線程
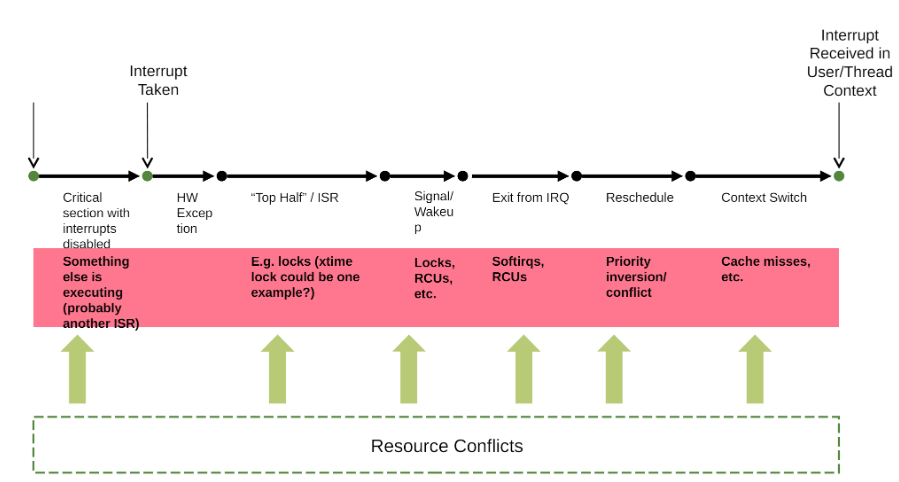
首先,我們來(lái)看看結(jié)合梳理下整個(gè)流程是如何的,有什么影響因素,關(guān)鍵問(wèn)題卡在哪個(gè)環(huán)節(jié)
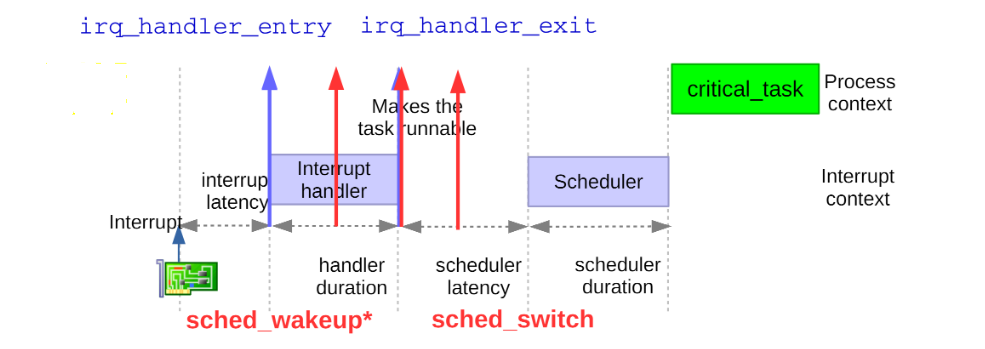
結(jié)合目前的ftrace下相關(guān)tracepoint,大致就可以有一個(gè)分析問(wèn)題的思路
 ? ?
? ?
首先從日志來(lái)看,當(dāng)喚醒的時(shí)刻,這個(gè)crtc_commit線程會(huì)發(fā)生選核,從選核邏輯上看,這個(gè)線程選擇了cpu1,而后差不多6ms后被做了loadbalance遷移到cpu4上

為什么會(huì)出現(xiàn)在選核完成后,沒(méi)有第一時(shí)間內(nèi)搶占cpu1上的HwBinder:1844_1這個(gè)線程,為什么沒(méi)有發(fā)生正常的一次調(diào)度?如何看這個(gè)問(wèn)題?還有這個(gè)線程為什么能運(yùn)行這么久?
目前對(duì)于內(nèi)核ftrace提供分析的方法

這個(gè)代碼的實(shí)現(xiàn)如下,詳細(xì)的可以參考代碼和ftrace.txt
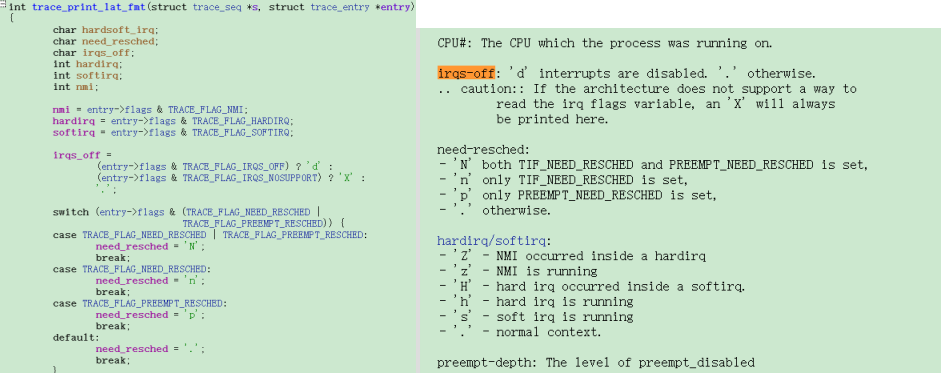
那我們就可以通過(guò)這個(gè)方法來(lái)看看,這個(gè)HwBinder:1844_1在選核的時(shí)候發(fā)生了什么情況?可以看到這個(gè)時(shí)候中斷被關(guān)閉了,同時(shí)preempt也被disable了

同時(shí)arch定時(shí)器中斷也有延遲,通常至少需要 4ms 會(huì)出現(xiàn) arch 定時(shí)器中斷,而出現(xiàn)問(wèn)題這段時(shí)間內(nèi),系統(tǒng)arch_timer也出現(xiàn)問(wèn)題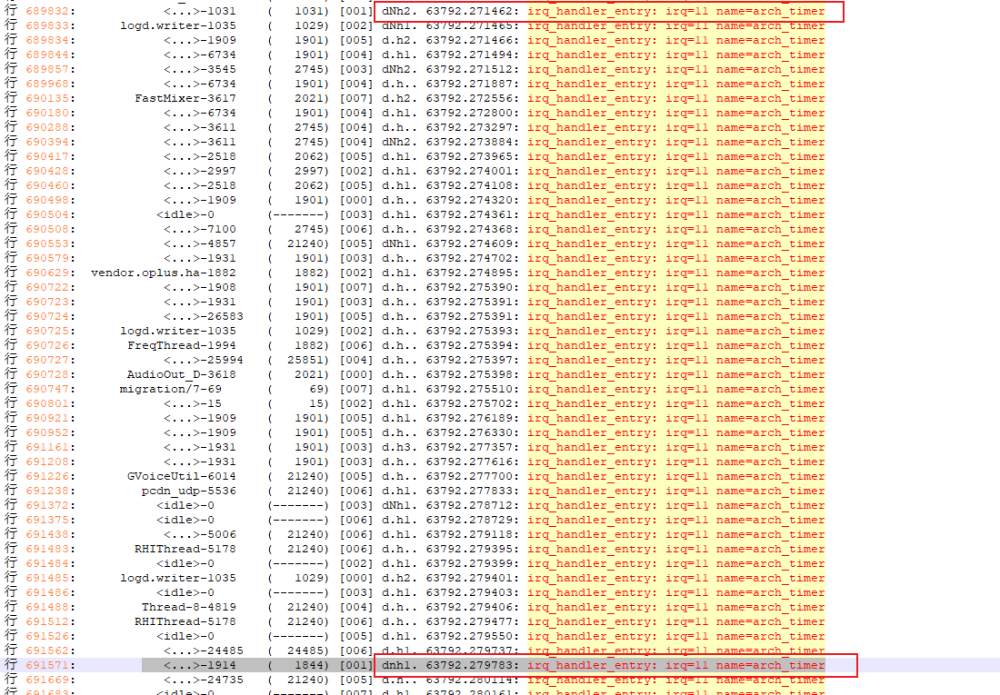
下一步就需要去排查驅(qū)動(dòng)中是哪里會(huì)關(guān)這么長(zhǎng)時(shí)間的中斷,可以開(kāi)啟preemptirq和preemptirq_long相關(guān)的tracepoint進(jìn)行復(fù)現(xiàn)debug,所以在寫內(nèi)核代碼的時(shí)候,需要關(guān)注preempt_count相關(guān)操作函數(shù)及其變體函數(shù),這個(gè)會(huì)切身影響到系統(tǒng)的實(shí)時(shí)性。
10. 總結(jié)
本文檔主要探討了Linux 6.1內(nèi)核中搶占特性的原理和實(shí)現(xiàn),重點(diǎn)關(guān)注latency產(chǎn)生原因、內(nèi)核搶占模型與機(jī)制以及實(shí)例分析,而目前遇到的痛點(diǎn)問(wèn)題是搶占造成資源競(jìng)爭(zhēng),以及鎖和中斷延遲對(duì)于實(shí)時(shí)性的影響,特別目前鎖是一個(gè)通用的API接口,任何驅(qū)動(dòng)都可以隨便使用,導(dǎo)致得不到及時(shí)搶占。
Linux內(nèi)核的搶占機(jī)制與中斷、鎖機(jī)制之間的矛盾是提高系統(tǒng)實(shí)時(shí)性和系統(tǒng)優(yōu)化的的一大挑戰(zhàn),也希望PREEMPT_RT的實(shí)時(shí)補(bǔ)丁能盡快合進(jìn)內(nèi)核主線,增強(qiáng)了Linux內(nèi)核的實(shí)時(shí)性能,通過(guò)減少不可搶占的臨界區(qū)和優(yōu)化中斷處理來(lái)提高搶占性。
審核編輯:彭菁
-
Linux
+關(guān)注
關(guān)注
87文章
11485瀏覽量
213137 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4375瀏覽量
64465 -
模型
+關(guān)注
關(guān)注
1文章
3501瀏覽量
50161 -
API接口
+關(guān)注
關(guān)注
1文章
85瀏覽量
10822
原文標(biāo)題:全方位剖析內(nèi)核搶占機(jī)制
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
在計(jì)算指令周期時(shí)(Delay_Slot),其是否包括了功能單元的延時(shí)時(shí)間(Function Uint Latency)?
[DM385] Latency Performance
什么是諧波_電力系統(tǒng)中諧波產(chǎn)生的原因和危害
請(qǐng)問(wèn)修改DEFAULT_DESIRED_SLAVE_LATENCY 值?
Latency TestUAC設(shè)備的相關(guān)資料分享
TMOS設(shè)置DEFAULT_DESIRED_SLAVE_LATENCY會(huì)不會(huì)造成什么不良后果?
i.MX8MP EQOS MAC_Ingress_Timestamp_Latency和MAC_Egress_Timestamp_Latency始終為0的原因?
一種可用于相關(guān)檢測(cè)系統(tǒng)中的波門產(chǎn)生電路
JESD204B SystemC module Deterministic Latency(四)
Zero Latency與微軟、惠普和英特爾合作 共同打造下一代VR娛樂(lè)平臺(tái)
Zero Latency VR與育碧合作 共同打造沉浸式VR游戲
Low Latency High Bandwidth Memory 數(shù)據(jù)表(Digest Edition)

時(shí)序分析基本概念介紹<Latency>
Low Latency High Bandwidth Memory 數(shù)據(jù)表(Digest Edition)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論