") 采用創(chuàng)新的FPGA 器件來實現(xiàn)更經(jīng)濟且更高能效的大模型推理解決方案
采用創(chuàng)新的FPGA 器件來實現(xiàn)更經(jīng)濟且更高能效的大模型推理解決方案
作者:Bob Siller,Achronix半導(dǎo)體產(chǎn)品營銷總監(jiān)
摘要:本文根據(jù)完整的基準(zhǔn)測試,將Achronix Semiconductor公司推出的Speedster7t FPGA與GPU解決方案進(jìn)行比較,在運行同一個Llama2 70B參數(shù)模型時,該項基于FPGA的解決方案實現(xiàn)了超越性的LLM推理處理。
采用 FPGA器件來加速LLM性能,在運行 Llama2 70B參數(shù)模型時,Speedster7t FPGA如何與 GPU解決方案相媲美?證據(jù)是令人信服的——Achronix Speedster7t FPGA通過提供計算能力、內(nèi)存帶寬和卓越能效的最佳組合,在處理大型語言模型(LLM)方面表現(xiàn)出色,這是當(dāng)今LLM復(fù)雜需求的基本要求。
像 Llama2這樣的 LLM的快速發(fā)展正在為自然語言處理(NLP)開辟一條新路線,有望提供比以往任何時候都更像人類的交互和理解。這些復(fù)雜的 LLM是創(chuàng)新的催化劑,推動了對先進(jìn)硬件解決方案的需求,以滿足其密集處理需求。
我們的基準(zhǔn)測試突出了 Speedster7t系列處理 Llama2 70B模型復(fù)雜性的能力,重點關(guān)注 FPGA和 LLM性能。這些測試(可根據(jù)要求提供結(jié)果)顯示了Achronix FPGA對于希望將LLM的強大功能用于其NLP應(yīng)用程序的開發(fā)人員和企業(yè)的潛力。這些基準(zhǔn)測試展示了 Speedster7t FPGA如何超越市場,提供無與倫比的性能,同時降低運營成本和環(huán)境影響。
Llama2 70B LLM運行在 Speedster7t FPGA上
2023年 7月,Microsoft和 Meta推出了他們的開源 LLM,Llama2開創(chuàng)了 AI驅(qū)動語言處理的新先例。Llama2采用多種配置設(shè)計,以滿足各種計算需求,包括 700億、130億和 700億個參數(shù),使其處于 LLM創(chuàng)新的最前沿。Achronix和我們的合作伙伴 Myrtle.ai對700億參數(shù)的Llama2模型進(jìn)行了深入的基準(zhǔn)分析,展示了使用Speedster7t FPGA進(jìn)行LLM加速的優(yōu)勢。
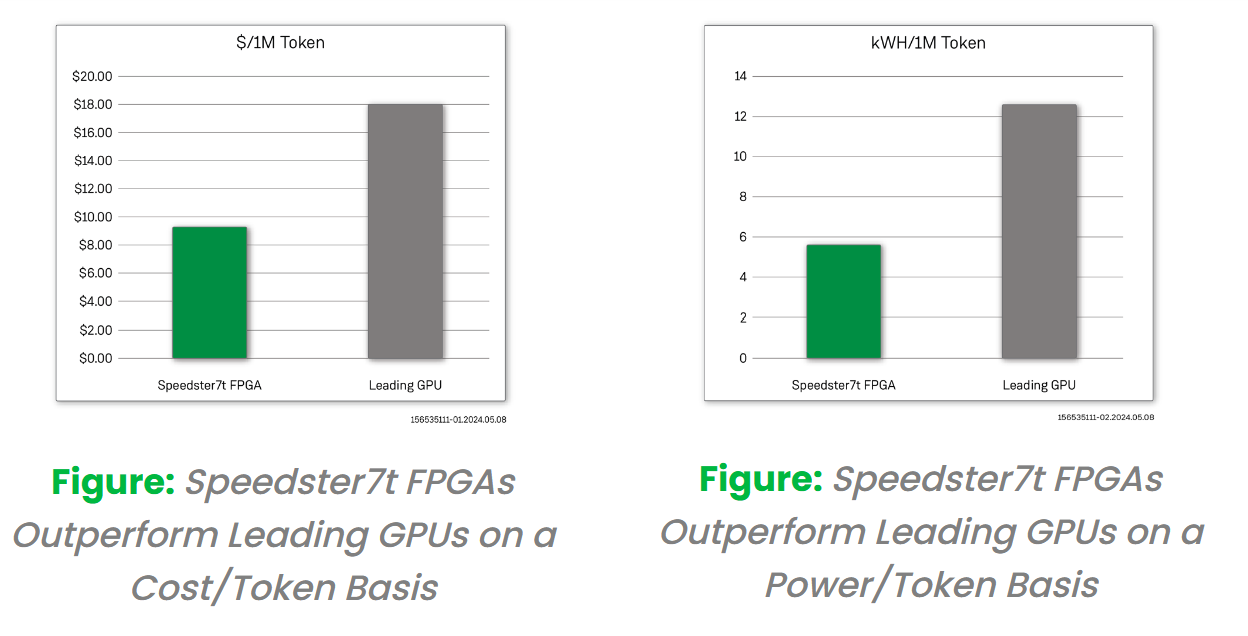
基準(zhǔn)測試結(jié)果:Speedster7t FPGA與業(yè)界領(lǐng)先的 GPU對比
我們在 Speedster7t FPGA上測試了 Llama2 70B模型的推理性能,并將其與領(lǐng)先的 GPU進(jìn)行了比較。該基準(zhǔn)測試是通過對輸入、輸出序列長度(1,128)和批處理大小 =1進(jìn)行建模來完成的。結(jié)果表明,Speedster7t AC7t1500在LLM處理中的有效性。
FPGA成本基于由 Speedster7t FPGA提供支持的 VectorPath加速卡的標(biāo)價。同樣,我們在此分析中使用了可比GPU卡的標(biāo)價。使用這些成本信息和每秒產(chǎn)生的輸出令牌數(shù)量,我們計算出基于 FPGA的解決方案的 $/token提高了 200%。除了成本優(yōu)勢外,在比較 FPGA和 GPU卡的相對功耗時,我們觀察到與基于 GPU的解決方案相比,產(chǎn)生的 kWh/token提高了 200%。這些優(yōu)勢表明 FPGA如何成為一種經(jīng)濟且能效高效的 LLM解決方案。
面向 LLM的 FPGA:Speedster7t的優(yōu)勢
Achronix Speedster7t系列FPGA旨在優(yōu)化LLM操作,平衡LLM硬件的關(guān)鍵要求,包括:
高性能計算 –具有高性能計算能力的尖端硬件對于管理 LLM推理核心的復(fù)雜矩陣計算至關(guān)重要。
高帶寬內(nèi)存 –高效的 LLM推理依賴于高帶寬內(nèi)存,通過模型的網(wǎng)絡(luò)參數(shù)快速饋送數(shù)據(jù),而不會出現(xiàn)瓶頸。
擴展和適應(yīng)能力 –現(xiàn)代 LLM推理需要能夠隨著模型規(guī)模的增長而擴展并靈活適應(yīng) LLM架構(gòu)的持續(xù)進(jìn)步的硬件。
高能效處理 –可持續(xù)的 LLM推理需要硬件能夠最大限度地提高計算輸出,同時最大限度地降低能耗,從而降低運營成本和環(huán)境影響。
Speedster7t FPGA提供以下功能,以應(yīng)對實施現(xiàn)代 LLM處理解決方案的挑戰(zhàn):
計算性能–通過其靈活的機器學(xué)習(xí)處理器(MLP)模塊支持復(fù)雜的 LLM任務(wù)。
高 GDDR6 DRAM帶寬 –確保以 4 Tbps的內(nèi)存帶寬快速處理大型 LLM數(shù)據(jù)集。
大量的 GDDR6 DRAM容量 –可容納 Llama2等擴展的 LLM,每個 FPGA的容量為 32 GB。
用于 LLM的集成 SRAM –提供低延遲、高帶寬的存儲,具有 190 Mb的 SRAM,非常適合存儲激活和模型權(quán)重。
多種本機數(shù)字格式 –適應(yīng) LLM需求,支持塊浮點(BFP)、FP16、bfloat16等。
高效的片上數(shù)據(jù)傳輸 – 2D NoC超過 20 Tbps,簡化片上數(shù)據(jù)流量。
擴展橫向擴展帶寬 –支持多達(dá)32個112 Gbps SerDes滿足 LLM需求,增強連接性。
自適應(yīng)邏輯級可編程性 –使用 690K 6輸入 LUT為 LLM的快速發(fā)展做好準(zhǔn)備。
針對 LLM推理優(yōu)化的 FPGA
在快速變化的人工智能和自然語言處理領(lǐng)域,使用 FPGA而不是 GPU來加速 LLM是一個相當(dāng)新的想法。該基準(zhǔn)測試展示了設(shè)計人員如何從使用Achronix的FPGA技術(shù)中受益。Achronix Speedster7t系列FPGA是這一變化的關(guān)鍵技術(shù),在高性能、高帶寬存儲器、易于擴展和電源效率之間實現(xiàn)了出色的平衡。
基于詳細(xì)的基準(zhǔn)分析,將 Speedster7t FPGA與領(lǐng)先的 GPU在處理 Llama2 70B模型方面的能力進(jìn)行比較,結(jié)果表明 Speedster7t FPGA能夠提供高水平的性能,同時大大降低運營成本和環(huán)境影響,突出了它在未來 LLM創(chuàng)建和使用中的重要作用。
如果希望進(jìn)一步了解如何使用FPGA器件來加速您的LLM程序,以及 FPGA加速 LLM解決方案的未來發(fā)展機遇。請聯(lián)系A(chǔ)chronix,獲取詳細(xì)的基準(zhǔn)測試結(jié)果,并幫助您確定Achronix FPGA技術(shù)如何加速您的LLM設(shè)計。
審核編輯 黃宇
-
FPG
+關(guān)注
關(guān)注
1文章
54瀏覽量
80254 -
大模型
+關(guān)注
關(guān)注
2文章
3046瀏覽量
3870
發(fā)布評論請先 登錄
優(yōu)化電機控制以提高能效
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測......
安科瑞基站能耗監(jiān)控解決方案,全面監(jiān)控、分析和優(yōu)化基站能效

當(dāng)我問DeepSeek AI爆發(fā)時代的FPGA是否重要?答案是......

摩爾線程宣布成功部署DeepSeek蒸餾模型推理服務(wù)
中國電信發(fā)布復(fù)雜推理大模型TeleAI-t1-preview
新品| LLM630 Compute Kit,AI 大語言模型推理開發(fā)平臺

IGBT模塊在頗具挑戰(zhàn)性的逆變器應(yīng)用中提供更高能效
FPGA和ASIC在大模型推理加速中的應(yīng)用

解決方案丨EasyGo新能源系統(tǒng)實時仿真應(yīng)用
使用TPS2116實現(xiàn)建筑自動化應(yīng)用的高能效

AMD助力HyperAccel開發(fā)全新AI推理服務(wù)器

【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)知識學(xué)習(xí)
基于瑞薩RZ/V2H AI微處理器的解決方案:高性能視覺AI系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論