 Java開發者LLM實戰——使用LangChain4j構建本地RAG系統
Java開發者LLM實戰——使用LangChain4j構建本地RAG系統
1、引言
由于目前比較火的chatGPT是預訓練模型,而訓練一個大模型是需要較長時間(參數越多學習時間越長,保守估計一般是幾個月,不差錢的可以多用點GPU縮短這個時間),這就導致了它所學習的知識不會是最新的,最新的chatGPT-4o只能基于2023年6月之前的數據進行回答,距離目前已經快一年的時間,如果想讓GPT基于近一年的時間回復問題,就需要RAG(檢索增強生成)技術了。

此外,對于公司內部的私有數據,為了數據安全、商業利益考慮,不能放到互聯網上的數據,因此GPT也沒有這部分的知識,如果需要GPT基于這部分私有的知識進行回答,也需要使用RAG技術。

本文將通過實戰代碼示例,意在幫助沒有大模型實戰經驗的Java工程師掌握使用LangChain4j框架進行大模型開發。
2、基本概念
2.1 什么是RAG
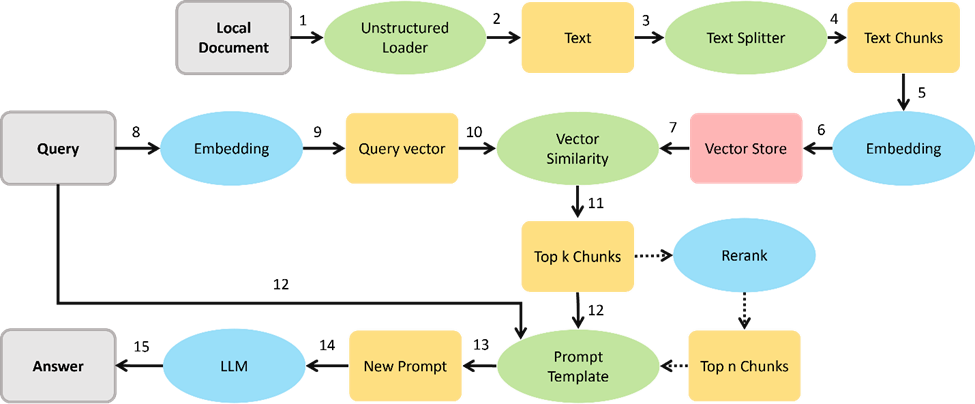
RAG(Retrieval-Augmented Generation)的核心思想是:將傳統的信息檢索(IR)技術與現代的生成式大模型(如chatGPT)結合起來。
具體來說,RAG模型在生成答案之前,會首先從一個大型的文檔庫或知識庫中檢索到若干條相關的文檔片段。再將這些檢索到的片段作為額外的上下文信息,輸入到生成模型中,從而生成更為準確和信息豐富的文本。
RAG的工作原理可以分為以下幾個步驟:
1.接收請求:首先,系統接收到用戶的請求(例如提出一個問題)。
2.信息檢索(R):系統從一個大型文檔庫中檢索出與查詢最相關的文檔片段。這一步的目標是找到那些可能包含答案或相關信息的文檔。
3.生成增強(A):將檢索到的文檔片段與原始查詢一起輸入到大模型(如chatGPT)中,注意使用合適的提示詞,比如原始的問題是XXX,檢索到的信息是YYY,給大模型的輸入應該類似于:請基于YYY回答XXXX。
4.輸出生成(G):大模型基于輸入的查詢和檢索到的文檔片段生成最終的文本答案,并返回給用戶。
第2步驟中的信息檢索,不一定必須使用向量數據庫,可以是關系型數據庫(如MySQL)或全文搜索引擎(如Elasticsearch, ES),
但大模型應用場景廣泛使用向量數據庫的原因是:在大模型RAG的應用場景中,主要是要查詢相似度高的某幾個文檔,而不是精確的查找某一條(MySQL、ES擅長)。
相似度高的兩個文檔,可能不包含相同的關鍵詞。 例如,句子1: "他很高興。" 句子2: "他感到非常快樂。" 雖然都是描述【他】很開心快樂的心情,但是不包含相同的關鍵詞;
包含相同的關鍵詞的兩個文檔可能完全沒有關聯,例如:句子1: "他喜歡蘋果。" 句子2: "蘋果是一家大公司。" 雖然都包含相同的關鍵詞【蘋果】,但兩句話的相似度很低。
2.2 LangChain4j簡介
LangChain4j是LangChiain的java版本,
LangChain的Lang取自Large Language Model,代表大語言模型,
Chain是鏈式執行,即把語言模型應用中的各功能模塊化,串聯起來,形成一個完整的工作流。
它是面向大語言模型的開發框架,意在封裝與LLM對接的細節,簡化開發流程,提升基于LLM開發的效率。
更多介紹,詳見: https://github.com/langchain4j/langchain4j/blob/main/README.md?
2.3 大模型開發 vs. 傳統JAVA開發
大模型開發——大模型實現業務邏輯:
開發前,開發人員關注數據準備(進行訓練)、選擇和微調模型(得到更好的效果,更能匹配業務預期),
開發過程中(大多數時候),重點在于如何有效的與大模型(LLM)進行溝通,利用LLM的專業知識解決特定的業務問題,
開發中更關注如何描述問題(提示工程 Propmt Engineering)進行有效的推理,關注如何將大模型的使用集成到現有的業務系統中。
傳統的JAVA開發——開發者實現業務邏輯:
開發前,開發人員關注系統架構的選擇(高并發、高可用),功能的拆解、模塊化等設計。
開發過程中(大多數時候)是根據特定的業務問題,設計特定的算法、數據存儲等以實現業務邏輯,以編碼為主。
3. 實戰經驗
3.1 環境搭建
3.1.1 向量庫(Chroma)
Windows:
先安裝python,參考: https://docs.python.org/zh-cn/3/using/windows.html#the-full-installer
PS:注意需要配置環境變量
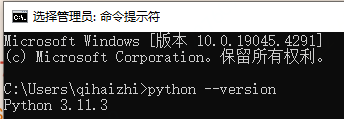
驗證-執行:
python --version
再安裝chroma,參考:https://docs.trychroma.com/getting-started
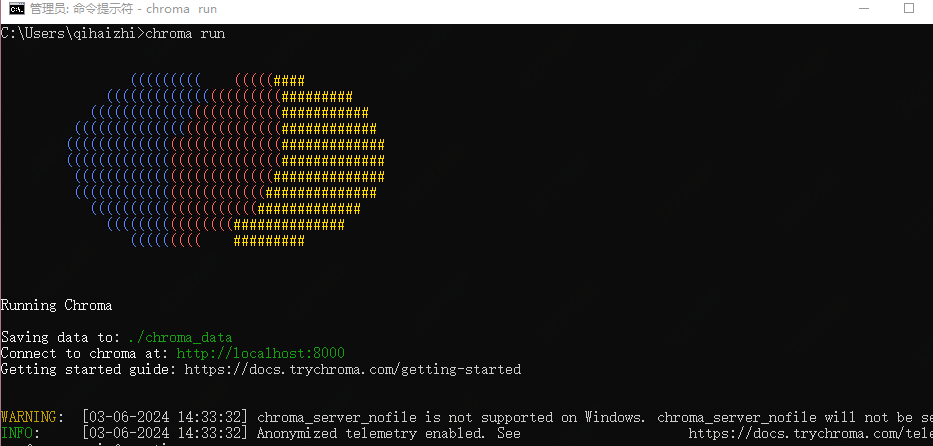
驗證-執行:
chroma run
Mac:
現先安裝python
brew install python
或者下載安裝: https://www.python.org/downloads/macos/
驗證-執行:
python --version

安裝chroma(同上),參考:https://docs.trychroma.com/getting-started
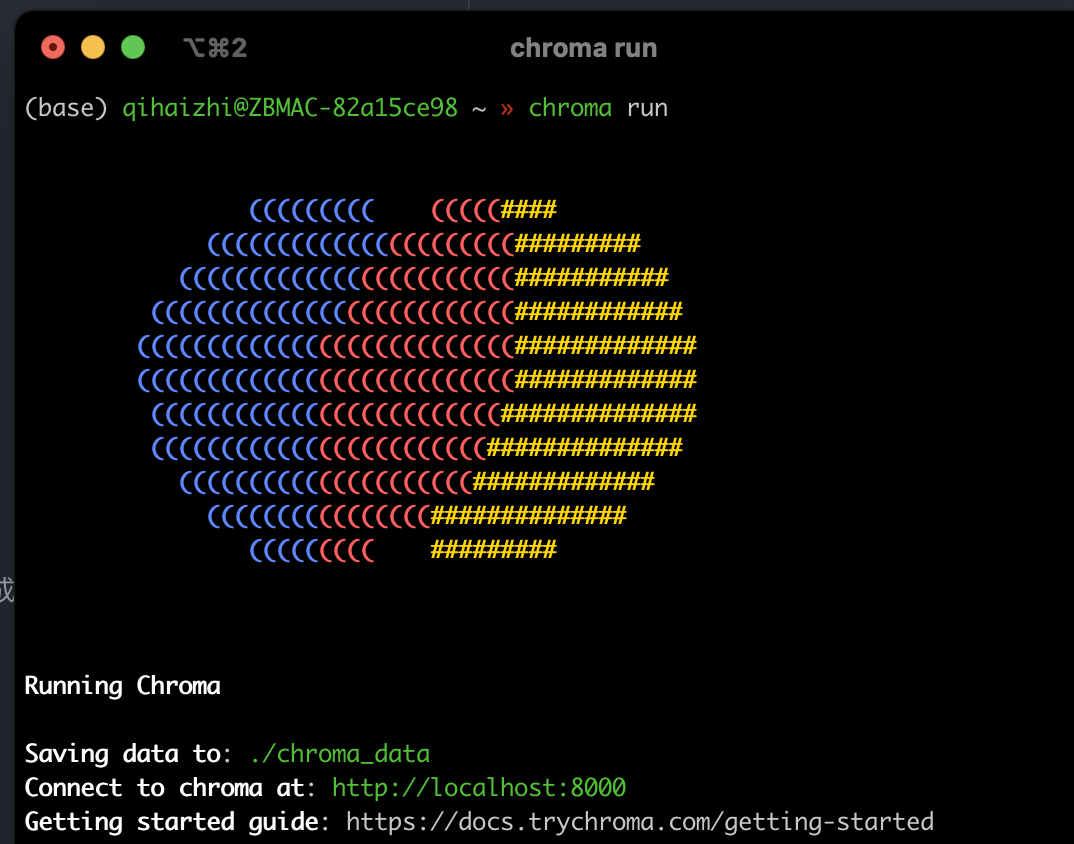
驗證-執行:
chroma run
?
3.1.2 集成LangChain4j
0.31.0
dev.langchain4j
langchain4j-core
${langchain4j.version}
dev.langchain4j
langchain4j
${langchain4j.version}
dev.langchain4j
langchain4j-open-ai
${langchain4j.version}
dev.langchain4j
langchain4j-embeddings
${langchain4j.version}
dev.langchain4j
langchain4j-chroma
${langchain4j.version}
io.github.amikos-tech
chromadb-java-client
${langchain4j.version}
3.2 程序編寫
3.2.1 項目結構
LangChain ├── core │ ├── src │ │ ├── main │ │ │ ├── java │ │ │ │ └── cn.jdl.tech_and_data.ka │ │ │ │ ├── ChatWithMemory │ │ │ │ ├── Constants │ │ │ │ ├── Main │ │ │ │ ├── RagChat │ │ │ │ └── Utils │ │ │ ├── resources │ │ │ │ ├── log4j2.xml │ │ │ │ └── 笑話.txt │ │ ├── test │ │ │ └── java │ ├── target ├── pom.xml ├── parent [learn.langchain.parent] ├── pom.xml
?
3.2.2 知識采集
一般是公司內網的知識庫中或互聯網上進行數據采集,獲取到的文本文件、WORD文檔或PDF文件,本文使用resources目錄下的【笑話.txt】作為知識采集的結果文件
URL docUrl = Main.class.getClassLoader().getResource("笑話.txt");
if(docUrl==null){
log.error("未獲取到文件");
}
Document document = getDocument(docUrl);
if(document==null){
log.error("加載文件失敗");
}
private static Document getDocument(URL resource) {
Document document = null;
try{
Path path = Paths.get(resource.toURI());
document = FileSystemDocumentLoader.loadDocument(path);
}catch (URISyntaxException e){
log.error("加載文件發生異常", e);
}
return document;
}
3.2.3 文檔切分
使用dev.langchain4j.data.document.splitter.DocumentSplitters#recursize
它有三個參數:分段大小(一個分段中最大包含多少個token)、重疊度(段與段之前重疊的token數)、分詞器(將一段文本進行分詞,得到token)
其中,重疊度的設計是為了減少按大小拆分后切斷原來文本的語義,使其盡量完整。

DocumentSplitter splitter = DocumentSplitters.recursive(150,10,new OpenAiTokenizer()); splitter.split(document);
關于Token(標記):
Token是經過分詞后的文本單位,即將一個文本分詞后得到的詞、子詞等的個數,具體取決于分詞器(Tokenizer),
比如:我喜歡吃蘋果,可以拆分成我/喜歡/吃/蘋果,token數量=4, 也可以拆分成我/喜/歡/吃/蘋果,token數量=5
chatGPT使用的是BPE(Byte Pair Encoding)算法進行分詞,參見: https://en.wikipedia.org/wiki/Byte_pair_encoding
對于上面文本的分詞結果如下:
18:17:29.371 [main] INFO TokenizerTest - 待分詞的文本:我喜歡吃蘋果 18:17:30.055 [main] INFO cn.jdl.tech_and_data.ka.Utils - 當前的模型是:gpt-4o 18:17:31.933 [main] INFO TokenizerTest - 分詞結果:我 / 喜歡 / 吃 / 蘋果
關于token與字符的關系:GPT-4o的回復:

關于文檔拆分的目的:
由于與LLM交互的時候輸入的文本對應的token長度是有限制的,輸入過長的內容,LLM會無響應或直接該報錯,
因此不能將所有相關的知識都作為輸入給到LLM,需要將知識文檔進行拆分,存儲到向量庫,
每次調用LLM時,先找出與提出的問題關聯度最高的文檔片段,作為參考的上下文輸入給LLM。
入參過長,LLM報錯:

雖然根據響應,允許輸入1048576個字符=1024K個字符=1M個字符,
但官網文檔給的32K tokens,而一般1個中文字符對應1-2個Token,因此字符串建議不大于64K,實際使用中,為了保障性能,也是要控制輸入不要過長。
如下是常見LLM給定的token輸入上限:
| 模型名稱 | Token 輸入上限(最大長度) |
|---|---|
| GPT-3 (davinci) | 4096 tokens |
| GPT-3.5 (text-davinci-003) | 4096 tokens |
| GPT-4 (8k context) | 8192 tokens |
| GPT-4 (32k context) | 32768 tokens |
| LLaMA (7B) | 2048 tokens |
| LLaMA (13B) | 2048 tokens |
| LLaMA (30B) | 2048 tokens |
| LLaMA (65B) | 2048 tokens |
| 訊飛星火(SparkDesk) | 8192 tokens |
| 文心一言(Ernie 3.0) | 4096 tokens |
| 智源悟道(WuDao 2.0) | 2048 tokens |
| 阿里巴巴 M6 | 2048 tokens |
| 華為盤古(Pangu-Alpha) | 2048 tokens |
| 言犀大模型(ChatJd) | 2048 tokens |
文檔拆分的方案langchain4j中提供了6種:
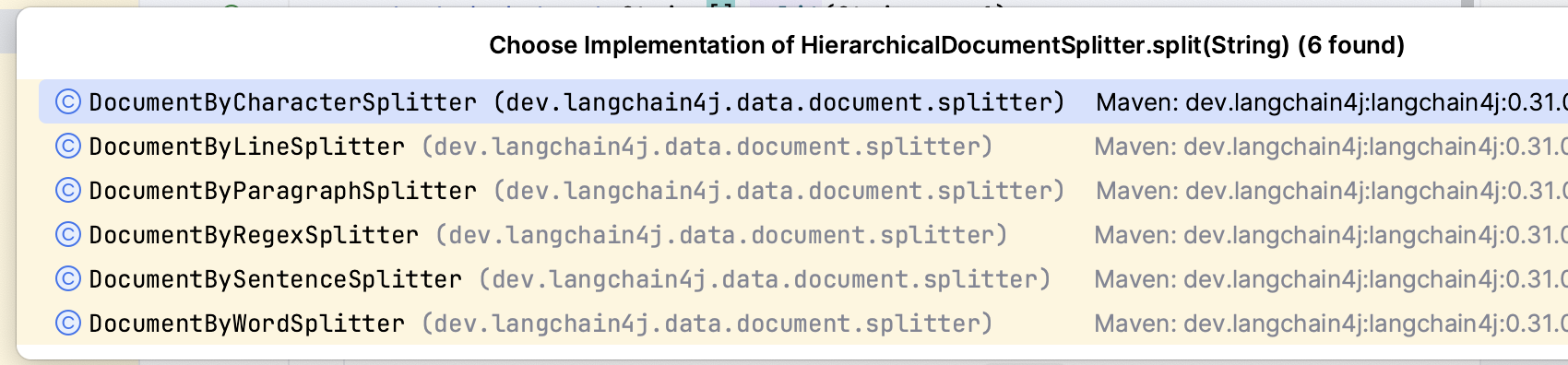
1、基于字符的:逐個字符(含空白字符)分割
2、基于行的:按照換行符(n)分割
3、基于段落的:按照連續的兩個換行符(nn)分割
4、基于正則的:按照自定義正則表達式分隔
5、基于句子的(使用Apache OpenNLP,只支持英文,所以可以忽略
審核編輯 黃宇
-
JAVA
+關注
關注
20文章
2986瀏覽量
107069 -
ChatGPT
+關注
關注
29文章
1588瀏覽量
8829 -
LLM
+關注
關注
1文章
321瀏覽量
700
發布評論請先 登錄
【書籍評測活動NO.61】Yocto項目實戰教程:高效定制嵌入式Linux系統
Java開發者必備的效率工具——Perforce JRebel是什么?為什么很多Java開發者在用?

DevEco Studio AI輔助開發工具兩大升級功能 鴻蒙應用開發效率再提升
《AI Agent 應用與項目實戰》閱讀心得3——RAG架構與部署本地知識庫
利用OpenVINO和LlamaIndex工具構建多模態RAG應用

【「基于大模型的RAG應用開發與優化」閱讀體驗】RAG基本概念
【「基于大模型的RAG應用開發與優化」閱讀體驗】+第一章初體驗
開發者的開源鴻蒙故事
《HarmonyOS第一課》煥新升級,賦能開發者快速掌握鴻蒙應用開發
RAG的概念及工作原理
使用OpenVINO和LlamaIndex構建Agentic-RAG系統
KaihongOS 4.1.2開發者預覽版正式上線,誠邀開發者免費試用!

OpenVINO? C++ 在哪吒開發板上推理 Transformer 模型|開發者實戰

KaihongOS 4.1.2開發者預覽版正式上線,誠邀開發者免費試用!
LangChain框架關鍵組件的使用方法





 工商網監
工商網監
評論