 自編碼器的原理和類型
自編碼器的原理和類型
一、自編碼器概述
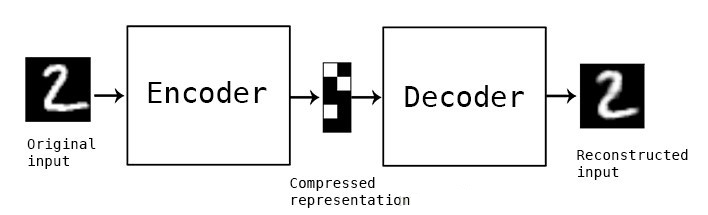
自編碼器(Autoencoder, AE)是一種無監督學習的神經網絡模型,它通過編碼器和解碼器的組合,實現了對輸入數據的壓縮和重構。自編碼器由兩部分組成:編碼器(Encoder)和解碼器(Decoder)。編碼器負責將輸入數據映射到一個低維的潛在空間(latent space),而解碼器則負責將這個低維表示映射回原始輸入空間,從而實現對輸入數據的重構。自編碼器的目標是最小化重構誤差,即使得解碼器的輸出盡可能接近原始輸入數據。
自編碼器最早由Yann LeCun在1987年提出,用于解決表征學習中的“編碼器問題”,即基于神經網絡的降維問題。隨著深度學習的發展,自編碼器在數據壓縮、特征提取、圖像生成等領域得到了廣泛應用。
二、自編碼器的原理
1. 編碼器
編碼器的主要作用是將輸入數據映射到一個低維的潛在空間。這一過程通常通過多層神經網絡實現,每一層都會對數據進行一定的變換和壓縮,最終得到一個低維的編碼表示。這個編碼表示是輸入數據的一種壓縮形式,它包含了輸入數據的主要特征信息,但去除了冗余和噪聲。
2. 解碼器
解碼器的作用是將編碼器的輸出(即低維表示)映射回原始輸入空間。與編碼器相反,解碼器通過多層神經網絡逐層上采樣和變換,將低維表示恢復成原始輸入數據的近似形式。解碼器的目標是使得重構后的數據與原始輸入數據盡可能接近,即最小化重構誤差。
3. 重構誤差
重構誤差是衡量自編碼器性能的重要指標。它表示了原始輸入數據與重構數據之間的差異程度。在訓練過程中,自編碼器通過不斷調整編碼器和解碼器的參數來減小重構誤差,從而實現對輸入數據的更好重構。
4. 學習過程
自編碼器的訓練過程是一個無監督學習的過程。在訓練過程中,不需要額外的標簽信息,只需要輸入數據本身即可。通過前向傳播計算重構誤差,然后通過反向傳播算法調整網絡參數以減小重構誤差。這個過程會不斷迭代進行,直到重構誤差達到一個可接受的范圍或者訓練輪次達到預設的上限。
三、自編碼器的類型
自編碼器根據其結構和功能的不同可以分為多種類型,包括但不限于以下幾種:
1. 基本自編碼器(Vanilla Autoencoder)
基本自編碼器是最簡單的自編碼器形式,由一個編碼器和一個解碼器組成。它主要用于數據壓縮和去噪等任務。
2. 稀疏自編碼器(Sparse Autoencoder)
稀疏自編碼器在基本自編碼器的基礎上增加了稀疏性約束,通過限制隱藏層神經元的激活程度來避免過擬合和提高特征表示的稀疏性。
3. 收縮自編碼器(Contractive Autoencoder)
收縮自編碼器通過添加對編碼器輸出關于輸入數據變化的懲罰項來鼓勵學習到的表示對數據變化具有魯棒性。這種自編碼器對于異常值檢測等任務特別有效。
4. 變分自編碼器(Variational Autoencoder, VAE)
變分自編碼器是一種生成模型,它通過引入隨機變量來生成輸入數據的潛在表示。VAE可以生成與原始數據分布相似的新數據樣本,因此在圖像生成、文本生成等領域具有廣泛應用。
5. 卷積自編碼器(Convolutional Autoencoder)
卷積自編碼器特別適用于圖像數據的處理。它通過卷積層和池化層來實現對圖像數據的壓縮和重構,能夠保留圖像的主要特征信息并去除噪聲。
四、自編碼器的應用
自編碼器在多個領域都有廣泛的應用,包括但不限于以下幾個方面:
1. 數據壓縮
自編碼器通過將輸入數據映射到低維潛在空間來實現數據壓縮。與傳統的數據壓縮方法相比,自編碼器能夠學習到更加緊湊和有效的數據表示方式。
2. 特征提取
自編碼器在特征提取方面表現出色。通過訓練自編碼器,可以得到輸入數據的有效特征表示,這些特征表示可以用于后續的分類、聚類等任務。
3. 圖像生成
變分自編碼器等生成模型可以生成與原始圖像相似的新圖像樣本。這對于圖像增強、圖像修復等任務具有重要意義。
4. 異常值檢測
收縮自編碼器等類型的自編碼器可以通過學習輸入數據的正常分布來檢測異常值。當輸入數據偏離正常分布時,自編碼器的重構誤差會顯著增加,從而可以識別出異常值。
五、代碼實現
下面是一個使用Python和TensorFlow實現的基本自編碼器的示例代碼:
import tensorflow as tf
# 定義編碼器和解碼器
def encoder(x, encoding_dim):
hidden = tf.layers.dense(x, 1
hidden = tf.layers.dense(x, encoding_dim, activation='relu')
return hidden
def decoder(x, decoding_dim, input_shape):
hidden = tf.layers.dense(x, decoding_dim, activation='relu')
output = tf.layers.dense(hidden, np.prod(input_shape), activation='sigmoid')
output = tf.reshape(output, [-1, *input_shape])
return output
# 輸入數據的維度
input_shape = (28, 28, 1) # 例如,MNIST數據集的圖像大小
input_img = tf.keras.layers.Input(shape=input_shape)
# 編碼維度
encoding_dim = 32 # 可以根據需要調整
# 通過編碼器獲取編碼
encoded = encoder(input_img, encoding_dim)
# 解碼器輸出重構的圖像
decoded = decoder(encoded, encoding_dim, input_shape)
# 自編碼器模型
autoencoder = tf.keras.Model(input_img, decoded)
# 編碼器模型
encoder_model = tf.keras.Model(input_img, encoded)
# 解碼器模型(需要自定義輸入層)
encoder_output = tf.keras.layers.Input(shape=(encoding_dim,))
decoder_layer = decoder(encoder_output, encoding_dim, input_shape)
decoder_model = tf.keras.Model(encoder_output, decoder_layer)
# 編譯模型
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 假設我們有一些MNIST數據用于訓練
# 這里僅展示模型構建過程,數據加載和訓練過程略去
# ...
# data_x = ... # 訓練數據
# autoencoder.fit(data_x, data_x, epochs=50, batch_size=256, shuffle=True, validation_split=0.2)
# 使用自編碼器進行預測(重構)
# reconstructed_imgs = autoencoder.predict(data_x)
# 注意:上述代碼是一個框架示例,實際使用時需要根據你的具體數據和需求進行調整。
# 例如,你可能需要加載MNIST數據集,預處理數據,然后訓練模型。
在這個示例中,我們定義了一個基本自編碼器的編碼器和解碼器部分。編碼器通過一個全連接層將輸入圖像壓縮成一個低維的編碼表示,而解碼器則通過另一個全連接層和重塑操作將編碼表示恢復成原始圖像的大小。
我們使用了TensorFlow的高級API tf.keras 來構建和編譯模型。模型autoencoder是一個完整的自編碼器,它包含了編碼器和解碼器兩部分。此外,我們還分別構建了只包含編碼器的encoder_model和只包含解碼器的decoder_model,以便在需要時單獨使用它們。
請注意,這個示例代碼并沒有包含數據加載和訓練的部分,因為那將取決于你具體使用的數據集和訓練環境。在實際應用中,你需要加載你的數據集(如MNIST手寫數字數據集),將其預處理為適合模型輸入的格式,并使用autoencoder.fit()方法來訓練模型。
自編碼器的性能很大程度上取決于其結構和超參數的選擇,如編碼維度encoding_dim、隱藏層的大小和激活函數等。這些參數需要通過實驗和調整來找到最優的組合。
-
編碼器
+關注
關注
45文章
3780瀏覽量
137302 -
神經網絡
+關注
關注
42文章
4810瀏覽量
102926 -
模型
+關注
關注
1文章
3499瀏覽量
50071
發布評論請先 登錄
基于變分自編碼器的異常小區檢測
是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?

自編碼器介紹
稀疏自編碼器及TensorFlow實現詳解
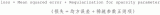
基于稀疏自編碼器的屬性網絡嵌入算法SAANE
自編碼器基礎理論與實現方法、應用綜述
自編碼器神經網絡應用及實驗綜述
六種不同類型的編碼器 對應旋轉和線性編碼器有什么區別?
旋轉編碼器如何工作?有哪些類型?
堆疊降噪自動編碼器(SDAE)
自編碼器 AE(AutoEncoder)程序

旋轉編碼器的常見類型
編碼器類型詳解:探索不同編碼技術的奧秘






 工商網監
工商網監
評論