") 深度學(xué)習(xí)模型中的過擬合與正則化
深度學(xué)習(xí)模型中的過擬合與正則化
在深度學(xué)習(xí)的廣闊領(lǐng)域中,模型訓(xùn)練的核心目標(biāo)之一是實(shí)現(xiàn)對(duì)未知數(shù)據(jù)的準(zhǔn)確預(yù)測。然而,在實(shí)際應(yīng)用中,我們經(jīng)常會(huì)遇到一個(gè)問題——過擬合(Overfitting)。過擬合是指模型在訓(xùn)練數(shù)據(jù)上表現(xiàn)優(yōu)異,但在測試數(shù)據(jù)或新數(shù)據(jù)上表現(xiàn)不佳的現(xiàn)象。為了解決這個(gè)問題,正則化(Regularization)技術(shù)應(yīng)運(yùn)而生,成為深度學(xué)習(xí)中不可或缺的一部分。本文將從過擬合的原因、表現(xiàn)、正則化的原理、方法及其在深度學(xué)習(xí)中的應(yīng)用等方面展開詳細(xì)論述。
一、過擬合的原因與表現(xiàn)
1.1 過擬合的原因
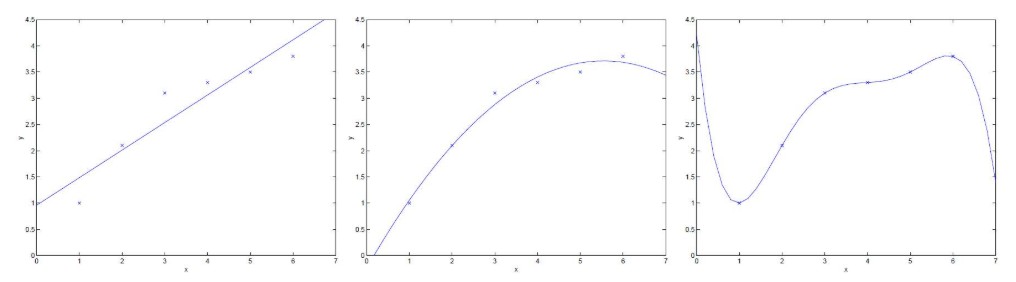
過擬合的主要原因可以歸結(jié)為模型復(fù)雜度與數(shù)據(jù)復(fù)雜度之間的不匹配。當(dāng)模型復(fù)雜度遠(yuǎn)高于數(shù)據(jù)復(fù)雜度時(shí),模型會(huì)過度擬合訓(xùn)練數(shù)據(jù)中的噪聲和細(xì)節(jié),而忽略了數(shù)據(jù)的真實(shí)分布規(guī)律。具體來說,過擬合的原因包括但不限于以下幾點(diǎn):
- 訓(xùn)練數(shù)據(jù)不足 :當(dāng)訓(xùn)練數(shù)據(jù)量較少時(shí),模型容易學(xué)習(xí)到訓(xùn)練數(shù)據(jù)的特有特征而非泛化特征。
- 模型參數(shù)過多 :模型參數(shù)過多會(huì)導(dǎo)致模型具有過強(qiáng)的擬合能力,容易捕捉到訓(xùn)練數(shù)據(jù)中的噪聲。
- 學(xué)習(xí)時(shí)間過長 :在訓(xùn)練過程中,如果迭代次數(shù)過多,模型可能會(huì)過度擬合訓(xùn)練數(shù)據(jù)。
- 特征選擇不當(dāng) :選擇了一些對(duì)模型預(yù)測沒有實(shí)質(zhì)性幫助的特征,增加了模型的復(fù)雜度。
1.2 過擬合的表現(xiàn)
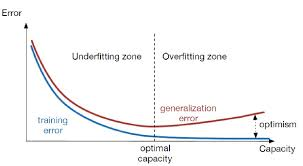
過擬合的直觀表現(xiàn)是模型在訓(xùn)練集上的準(zhǔn)確率非常高,甚至接近100%,但在測試集或新數(shù)據(jù)上的準(zhǔn)確率卻大幅下降。這表明模型已經(jīng)記住了訓(xùn)練數(shù)據(jù)的細(xì)節(jié),而無法泛化到新的數(shù)據(jù)上。此外,過擬合的模型通常具有復(fù)雜的決策邊界,這些邊界能夠精確劃分訓(xùn)練數(shù)據(jù),但在實(shí)際應(yīng)用中卻缺乏魯棒性。
二、正則化的原理與方法
2.1 正則化的原理
正則化的基本思想是在損失函數(shù)中加入一個(gè)與模型復(fù)雜度相關(guān)的正則項(xiàng),從而控制模型的復(fù)雜度,防止其過度擬合訓(xùn)練數(shù)據(jù)。正則項(xiàng)通常是對(duì)模型參數(shù)的一種約束,旨在使模型參數(shù)在訓(xùn)練過程中保持較小的值。這樣,即使模型在訓(xùn)練數(shù)據(jù)上有所波動(dòng),也不會(huì)對(duì)整體預(yù)測結(jié)果產(chǎn)生太大影響,從而提高模型的泛化能力。
2.2 正則化的方法
正則化的方法多種多樣,根據(jù)正則項(xiàng)的不同可以分為L1正則化、L2正則化、Dropout等。
- L1正則化 :L1正則化通過在損失函數(shù)中加入模型參數(shù)的絕對(duì)值之和作為正則項(xiàng)來約束模型復(fù)雜度。L1正則化傾向于產(chǎn)生稀疏的權(quán)值矩陣,即許多參數(shù)會(huì)變?yōu)?,這有助于減少模型的復(fù)雜度并提高泛化能力。此外,L1正則化還具有特征選擇的作用,可以自動(dòng)剔除對(duì)模型預(yù)測沒有實(shí)質(zhì)性幫助的特征。
- L2正則化 :L2正則化通過在損失函數(shù)中加入模型參數(shù)的平方和作為正則項(xiàng)來約束模型復(fù)雜度。與L1正則化不同,L2正則化不會(huì)使參數(shù)變?yōu)?,而是使參數(shù)值趨于接近0。這有助于減少模型的過擬合風(fēng)險(xiǎn),同時(shí)保持模型的平滑性。L2正則化在深度學(xué)習(xí)中應(yīng)用廣泛,特別是在卷積神經(jīng)網(wǎng)絡(luò)(CNN)和全連接網(wǎng)絡(luò)(FCN)中。
- Dropout :Dropout是一種特殊的正則化方法,它通過在訓(xùn)練過程中隨機(jī)丟棄神經(jīng)網(wǎng)絡(luò)中的一部分神經(jīng)元來防止過擬合。具體來說,在每次迭代中,以一定的概率將神經(jīng)網(wǎng)絡(luò)中的某些神經(jīng)元置為0(即丟棄這些神經(jīng)元),然后僅使用剩余的神經(jīng)元進(jìn)行前向傳播和反向傳播。這種方法可以減少神經(jīng)元之間的共適應(yīng)(co-adaptation),即避免某些神經(jīng)元過度依賴其他神經(jīng)元的信息,從而提高模型的泛化能力。Dropout在深度學(xué)習(xí)領(lǐng)域的應(yīng)用非常廣泛,特別是在深度神經(jīng)網(wǎng)絡(luò)(DNN)和循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)中。
三、正則化在深度學(xué)習(xí)中的應(yīng)用
3.1 在卷積神經(jīng)網(wǎng)絡(luò)中的應(yīng)用
在卷積神經(jīng)網(wǎng)絡(luò)(CNN)中,正則化方法的應(yīng)用尤為重要。由于CNN通常包含大量的卷積層和全連接層,模型參數(shù)數(shù)量龐大,容易出現(xiàn)過擬合現(xiàn)象。因此,在訓(xùn)練CNN時(shí),通常會(huì)采用L2正則化、Dropout等方法來防止過擬合。此外,數(shù)據(jù)增強(qiáng)(如圖像旋轉(zhuǎn)、縮放、裁剪等)也是一種有效的正則化手段,可以增加訓(xùn)練數(shù)據(jù)的多樣性,提高模型的泛化能力。
3.2 在循環(huán)神經(jīng)網(wǎng)絡(luò)中的應(yīng)用
在循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)中,過擬合問題同樣不容忽視。由于RNN在處理序列數(shù)據(jù)時(shí)容易學(xué)習(xí)到數(shù)據(jù)中的長期依賴關(guān)系,因此也容易受到噪聲和異常值的影響。為了解決這個(gè)問題,研究者們提出了多種正則化方法,如L2正則化、Dropout等。特別是在長短期記憶網(wǎng)絡(luò)(LSTM)和門控循環(huán)單元(GRU)等改進(jìn)的RNN模型中,正則化方法的應(yīng)用更加廣泛。
3.3 Dropout的應(yīng)用細(xì)節(jié)
在Dropout的應(yīng)用中,有幾個(gè)關(guān)鍵點(diǎn)需要注意。首先,Dropout通常應(yīng)用于全連接層(Dense層),而在卷積層(Convolutional層)中則較少使用,因?yàn)榫矸e層中的參數(shù)數(shù)量相對(duì)較少,且卷積操作本身具有一定的正則化效果。其次,Dropout的比例(即丟棄神經(jīng)元的概率)是一個(gè)重要的超參數(shù),需要根據(jù)具體情況進(jìn)行調(diào)整。一般來說,較大的Dropout比例可以更有效地防止過擬合,但也可能導(dǎo)致模型欠擬合;反之,較小的Dropout比例則可能無法充分抑制過擬合。因此,在實(shí)際應(yīng)用中,通常需要通過交叉驗(yàn)證等方法來確定最佳的Dropout比例。
3.4 正則化與模型優(yōu)化的結(jié)合
正則化不僅僅是防止過擬合的一種手段,還可以與模型優(yōu)化算法相結(jié)合,進(jìn)一步提高模型的性能。例如,在訓(xùn)練深度學(xué)習(xí)模型時(shí),通常會(huì)采用梯度下降(Gradient Descent)或其變種(如Adam、RMSprop等)作為優(yōu)化算法。這些算法通過不斷迭代更新模型的參數(shù)來最小化損失函數(shù)。在這個(gè)過程中,正則化項(xiàng)可以被視為損失函數(shù)的一部分,通過調(diào)整正則化項(xiàng)的權(quán)重來平衡模型在訓(xùn)練集上的表現(xiàn)和在測試集上的泛化能力。因此,正則化與模型優(yōu)化的結(jié)合是深度學(xué)習(xí)模型訓(xùn)練過程中不可或缺的一部分。
四、過擬合與正則化的挑戰(zhàn)與未來展望
4.1 挑戰(zhàn)
盡管正則化技術(shù)在防止過擬合方面取得了顯著成效,但在實(shí)際應(yīng)用中仍面臨一些挑戰(zhàn)。首先,正則化方法的選擇和參數(shù)設(shè)置需要依賴大量的實(shí)驗(yàn)和經(jīng)驗(yàn)積累,缺乏統(tǒng)一的標(biāo)準(zhǔn)和理論指導(dǎo)。其次,隨著深度學(xué)習(xí)模型的復(fù)雜度和規(guī)模的不斷增加,正則化方法的效果可能會(huì)受到限制。例如,在極大規(guī)模的神經(jīng)網(wǎng)絡(luò)中,簡單的L2正則化或Dropout可能無法有效防止過擬合。此外,正則化方法的選擇和參數(shù)設(shè)置也可能受到計(jì)算資源和時(shí)間成本的限制。
4.2 未來展望
為了應(yīng)對(duì)這些挑戰(zhàn)并進(jìn)一步提高深度學(xué)習(xí)模型的性能,研究者們正在不斷探索新的正則化方法和策略。一方面,研究者們致力于開發(fā)更加高效、自適應(yīng)的正則化方法,以更好地適應(yīng)不同場景和任務(wù)的需求。例如,一些研究者提出了自適應(yīng)Dropout(Adaptive Dropout)等方法,可以根據(jù)模型訓(xùn)練過程中的表現(xiàn)動(dòng)態(tài)調(diào)整Dropout的比例。另一方面,研究者們也在探索將正則化方法與深度學(xué)習(xí)模型的其他方面相結(jié)合的新途徑。例如,將正則化方法與深度學(xué)習(xí)模型的架構(gòu)搜索(Architecture Search)相結(jié)合,通過自動(dòng)化地搜索最優(yōu)的模型架構(gòu)和正則化策略來進(jìn)一步提高模型的性能。
五、結(jié)論
過擬合是深度學(xué)習(xí)中一個(gè)常見且重要的問題,它限制了模型在實(shí)際應(yīng)用中的泛化能力。正則化作為防止過擬合的一種有效手段,在深度學(xué)習(xí)模型的訓(xùn)練過程中發(fā)揮著重要作用。通過合理選擇和調(diào)整正則化方法及其參數(shù)設(shè)置,可以顯著降低模型的過擬合風(fēng)險(xiǎn)并提高其泛化能力。然而,正則化方法的選擇和參數(shù)設(shè)置仍面臨一些挑戰(zhàn)和限制。未來隨著深度學(xué)習(xí)技術(shù)的不斷發(fā)展和完善,我們期待看到更多高效、自適應(yīng)的正則化方法和策略的出現(xiàn),以進(jìn)一步推動(dòng)深度學(xué)習(xí)技術(shù)的發(fā)展和應(yīng)用。
-
模型
+關(guān)注
關(guān)注
1文章
3500瀏覽量
50101 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5557瀏覽量
122565
發(fā)布評(píng)論請(qǐng)先 登錄
神經(jīng)網(wǎng)絡(luò)中避免過擬合5種方法介紹
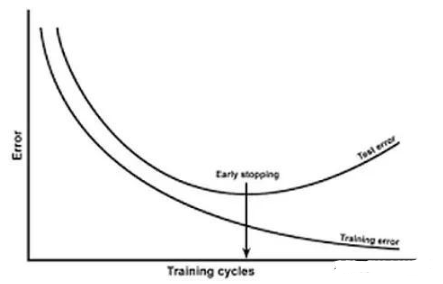
深層神經(jīng)網(wǎng)絡(luò)模型的訓(xùn)練:過擬合優(yōu)化
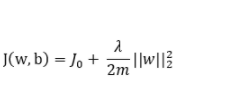
機(jī)器學(xué)習(xí)基礎(chǔ)知識(shí) 包括評(píng)估問題,理解過擬合、欠擬合以及解決問題的技巧
深度學(xué)習(xí)中過擬合/欠擬合的問題及解決方案
深度學(xué)習(xí)模型是如何創(chuàng)建的?
dropout正則化技術(shù)介紹
過擬合的概念和用幾種用于解決過擬合問題的正則化方法

【連載】深度學(xué)習(xí)筆記4:深度神經(jīng)網(wǎng)絡(luò)的正則化
深度學(xué)習(xí)筆記5:正則化與dropout
欠擬合和過擬合是什么?解決方法總結(jié)
詳解機(jī)器學(xué)習(xí)和深度學(xué)習(xí)常見的正則化
深度學(xué)習(xí)中過擬合、欠擬合問題及解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論