 Cortex R52內核Cache的相關概念(2)
Cortex R52內核Cache的相關概念(2)
Cache相關概念
3Outer&Inner R/W allocate
表示分配方式為外部和內部都是讀寫分配。
讀/寫分配是一種內存訪問策略,用于確定處理器在訪問內存時是否需要將數據加載到高速緩存中。具體來說:
讀分配:當處理器需要從內存中讀取數據時,如果該數據不在高速緩存中,則會將相應的數據塊加載到高速緩存中,以便處理器能夠更快地訪問和處理數據。
寫分配:當處理器需要向內存寫入數據時,如果寫入的數據不在高速緩存中,則會先將相應的數據塊加載到高速緩存中,并在高速緩存中進行寫操作,然后再將更新后的數據寫入到內存中。讀/寫分配可以影響系統的性能表現,合理選擇讀/寫分配策略可以提高數據訪問的效率和速度。
如果外部和內部都是讀/寫分配,表示處理器在與外部存儲器和內部緩存之間的數據交互時,都采用讀/寫分配的方式來管理數據的加載和寫入操作。這樣的設置可以根據具體場景提高數據訪問的效率和性能。
4Write-Back,Write-Through
Write-back寫回,和Write-Through寫透是兩種不同的緩存策略,它們在處理器訪問數據時的行為有所不同:在寫回策略下,當處理器要寫入數據時,數據首先被寫入到緩存中,而不是直接寫入到內存中。只有在緩存行被替換出去時,才會將被修改的數據寫回到內存中。這樣可以減少對內存的頻繁寫入操作,提高緩存的利用率和性能。
在寫透策略下,當處理器要寫入數據時,數據會同時被寫入到緩存和內存中。每次寫操作都會導致數據被同步寫入到內存,確保內存和緩存中的數據一致性。雖然可以保證數據的一致性,但可能會增加寫操作的延遲。
效率上來說,寫回策略通常比寫透策略效率更高。這是因為寫回策略減少了對內存的頻繁寫入,利用了緩存的特性來減少內存訪問次數,提高了系統整體的性能。然而,寫回策略需要額外的控制邏輯來管理緩存中數據與內存之間的一致性,因此需要更多的硬件支持。選擇哪種策略取決于系統的設計需求和性能優化目標。
5Outer&Inner non-allocate
外部和內部都是非分配的意味著在存儲器屬性中指定了不進行分配(non-allocate)的方式。這意味著處理器在訪問這種類型的內存時,不會將數據加載到高速緩存中進行緩存,而是直接在內存中讀取或寫入數據。
當外部和內部都是非分配時,處理器在訪問這段內存時不會將其內容緩存起來,而是每次都直接從內存讀取或寫入數據。這種方式可能會增加內存訪問的延遲,但可以確保處理器訪問的數據是最新的,適用于對數據實時性要求較高的場景。
6Outer&Inner non-cacheable
表示外部和內部都不開緩存
7Non-transient可以理解為非瞬態
"transient" 通常用來描述一種短暫存在或暫時性的狀態或屬性。而 "non-transient" 則表示相反的情況,即不是短暫的或不是暫時的。
在代碼中提到的 "non-transient" 和 "transient" 可能用來描述內存訪問屬性的持久性或持續性。例如,如果一個內存區域被標記為 "non-transient",可能意味著該區域的屬性在一段時間內保持不變,而不是臨時性的或隨機變化的。

點擊可查看大圖
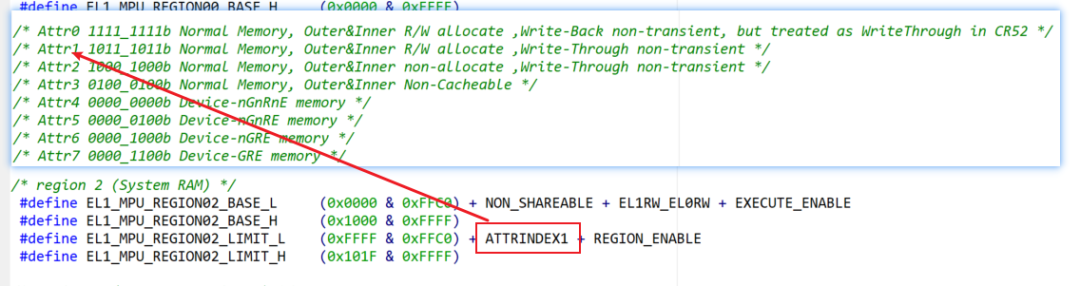
這里要注意的一點是:如上圖紅框所示CortexR52的內核的write-back被當成是write-through來對待。
System ram的MPU配置說明

點擊可查看大圖
這里的ATTRINDEX1對應的就是Attr1的配置,其它的序號也是一一對應的。
點擊可查看大圖
Attr1可以看出他的配置是正常存儲設備,內外部讀寫分配,并且是寫透的cache策略,這面要注意的是,打開cache一定要是non_shareable。
我們再看一下下圖中System RAM mirror:的MPU配置策略與system ram正好相反,ATTRINDEX3對應的Attr3是沒有使能cache,卻是“outer_shareable”的狀態。這個也好理解,因為開cache,又開共享的話會影響數據一致性的。

點擊可查看大圖
下個章節將介紹Cortex R52具體的緩存操作的實踐和性能測試。
-
處理器
+關注
關注
68文章
19409瀏覽量
231190 -
內核
+關注
關注
3文章
1382瀏覽量
40427 -
Cortex
+關注
關注
2文章
203瀏覽量
46603
原文標題:解密Cortex R52內核Cache:操作實踐、性能測試與深度解析(2)
文章出處:【微信號:瑞薩MCU小百科,微信公眾號:瑞薩MCU小百科】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
實際項目開發中為何選擇ARM? Cortex?-M4 內核的HK32MCU?
解析Arm Neoverse N2 PMU事件L2D_CACHE_WR

Arm Cortex-R82AE賦能高性能區域控制器設計
RM57L843基于ARM? Cortex?-R內核的Hercules?微控制器數據表

TMS570LC4357基于ARM Cortex?-R內核的Hercules?微控制器數據表
RT-Thread 率先支持RZ/T2M高性能、多功能 MPU!

Cortex R52內核Cache的具體操作(2)

Cortex R52內核Cache的相關概念(1)
CortexR52內核Cache的具體操作

摩芯半導體與安謀科技達成合作
普冉半導體推出一款基于32位ARM Cortex-M0+內核的微控制器
RZ/T2M直流伺服電機解決方案

兆易創新推出GD32F5系列Cortex-M33內核MCU
Cortex-M85內核單片機如何快速上手






 工商網監
工商網監
評論