") 基于Achronix Speedster7t FPGA器件的AI基準(zhǔn)測(cè)試
基于Achronix Speedster7t FPGA器件的AI基準(zhǔn)測(cè)試
作者:Myrtle.ai的Aiken Cairncross、Basile Henry、Chris Chalmers、Douglas Reid,Jonny Shipton、Jon Fowler、Liz Corrigan、Mike Ash
摘要——在部署具有自回歸關(guān)鍵路徑或遞歸能力的機(jī)器學(xué)習(xí)網(wǎng)絡(luò)通常不能很好地利用AI加速器硬件。這類網(wǎng)絡(luò)就像自動(dòng)語音識(shí)別(Automatic Speech Recognition,簡(jiǎn)稱ASR)中使用的網(wǎng)絡(luò)一樣,必須以低延遲和確定性尾部延遲運(yùn)行,以適用于大規(guī)模實(shí)時(shí)應(yīng)用進(jìn)程。在本文中,我們提出了一種推理引擎的疊加架構(gòu),然后在Speedster7t FPGA上實(shí)現(xiàn)該架構(gòu)。Speedster7t系列FPGA芯片是Achronix半導(dǎo)體公司推出的為計(jì)算加速優(yōu)化的器件。我們展示了所考慮到的網(wǎng)絡(luò)類型的潛在高利用率。其特別之處在于,我們描述了一種雙時(shí)鐘方法,該方法采用的時(shí)鐘頻率為Speedster器件中嵌入的機(jī)器學(xué)習(xí)處理模塊(MLP)的額定頻率的74.7%。這一結(jié)果表明,該器件可以在一組標(biāo)準(zhǔn)的AI基準(zhǔn)測(cè)試中達(dá)到36.4TOPS的算力,并且可以在一系列場(chǎng)景中達(dá)到的器件總體效率大約為60%。然后,我們重點(diǎn)介紹該架構(gòu)對(duì)低延遲實(shí)時(shí)應(yīng)用進(jìn)程(如自動(dòng)語音識(shí)別)的優(yōu)勢(shì)。
I.簡(jiǎn)介
Achronix半導(dǎo)體公司推出了為AI優(yōu)化的Speedster7t系列FPGA芯片,該系列包含專門針對(duì)AI工作負(fù)載的強(qiáng)化計(jì)算引擎。隨著AI在各個(gè)領(lǐng)域變得普遍,在FPGA芯片上部署AI應(yīng)用的需求促使了架構(gòu)創(chuàng)新,關(guān)注點(diǎn)放在了在所有深度神經(jīng)網(wǎng)絡(luò)處理的核心中添加足夠的計(jì)算能力來支持核心完成矩陣乘法運(yùn)算,同時(shí)靈活使用FPGA的邏輯陣列來實(shí)現(xiàn)AI處理所需的各種其他運(yùn)算。
FPGA歷來都是被用于電信設(shè)備,工業(yè)系統(tǒng),汽車電子等嵌入式系統(tǒng)中。現(xiàn)在也被用于數(shù)據(jù)中心的大規(guī)模AI推理加速,如微軟的Project Brainwave[1]、SK Telecom [2]和快手[3]所證明的那樣。這些部署正在被用于低延遲實(shí)時(shí)部署,其中FPGA架構(gòu)支持小批量的高效處理,從而使AI能夠被用于那些因?yàn)檠舆t而影響用戶體驗(yàn)的地方,例如對(duì)話式 AI服務(wù)。在這些部署中使用FPGA作為AI推理ASIC經(jīng)濟(jì)有效的替代方案,同時(shí)保持了靈活的軟件可編程優(yōu)勢(shì),可以更好地跟進(jìn)快速發(fā)展的AI技術(shù)開發(fā)。
在本文中,我們討論了Achronix最新為AI優(yōu)化的Speedster7t FPGA器件的特性,以及如何將其高效地用于如自動(dòng)語音識(shí)別(ASR)等的實(shí)時(shí)應(yīng)用。我們描述了一種可以高效發(fā)揮FPGA作用的疊加架構(gòu),并且為核心計(jì)算指標(biāo)GEMV和機(jī)器學(xué)習(xí)處理模塊(MLP)的AI操作提供了一組基準(zhǔn)測(cè)試結(jié)果。最后,我們將實(shí)現(xiàn)的TOPS和內(nèi)存帶寬數(shù)據(jù)與器件的總體性能數(shù)據(jù)進(jìn)行了比較,以突出部署于AI工作負(fù)載時(shí)可實(shí)現(xiàn)的效率。
II.用于人工智能的Speedster7t器件的特性
當(dāng)考慮用于AI推理的FPGA器件時(shí),相關(guān)器件的關(guān)鍵特性是器件支持的數(shù)值精度、可提供的計(jì)算單元數(shù)量和高速存儲(chǔ)器接口的規(guī)格。這些因素共同影響目標(biāo)網(wǎng)絡(luò)可實(shí)現(xiàn)的整體質(zhì)量和性能。在本節(jié)中,我們介紹了用于AI推理的Speedster7t器件的功能,并且在本節(jié)的最后,我們討論了如何組合這些功來確定器件用于低延遲AI推理的能力。
A.機(jī)器學(xué)習(xí)處理模塊
Speedster7t 1500 FPGA器件在片上包含了2560個(gè)機(jī)器學(xué)習(xí)處理模塊。這些硬化的模塊運(yùn)行頻率高達(dá)750 MHz,在INT8整數(shù)格式下可以提供高達(dá)61.44 TOPS的總算力。該機(jī)器學(xué)習(xí)處理模塊集成了Block RAM和乘法累加電路。這些特性支持其實(shí)現(xiàn)最大的性能,因?yàn)樗械母邘挃?shù)據(jù)流都保持在機(jī)器學(xué)習(xí)處理模塊內(nèi),從而大大減少了將權(quán)重和激活移動(dòng)到器件計(jì)算組件中造成的FPGA 路由開銷。。機(jī)器學(xué)習(xí)處理模塊包含一條相鄰模塊之間的級(jí)聯(lián)路徑,用于共享內(nèi)存和數(shù)據(jù)權(quán)重或激活數(shù)據(jù),并實(shí)現(xiàn)有效的數(shù)據(jù)結(jié)構(gòu),如脈動(dòng)陣列架構(gòu)。
機(jī)器學(xué)習(xí)處理模塊的架構(gòu)如圖1所示。
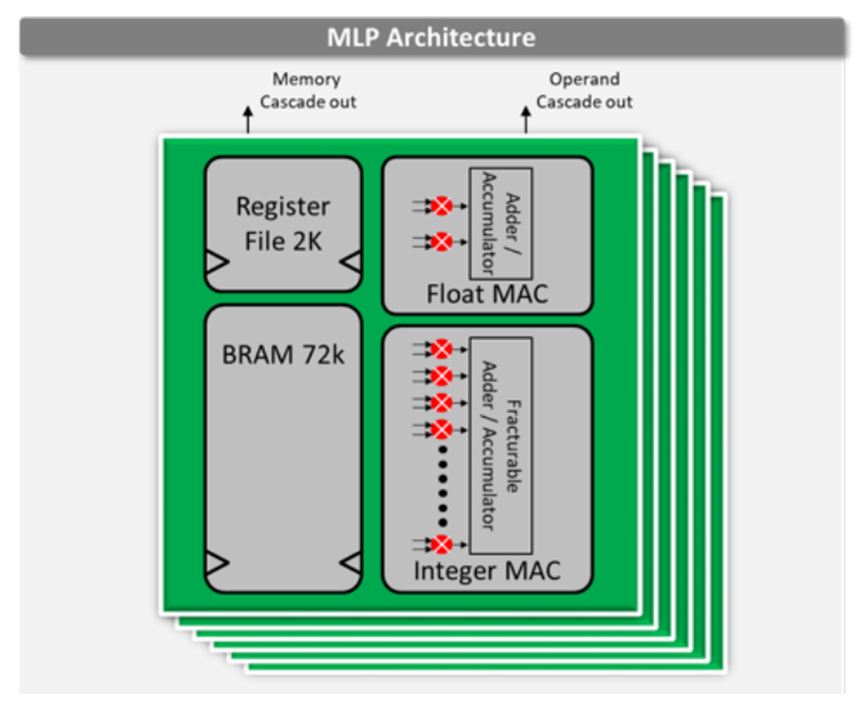
圖1. Achronix Speedster7t FPGA上的MLP架構(gòu)
B. Speedster7t的數(shù)值精度
用于推理的量化模型是一種廣泛使用的技術(shù),其中的計(jì)算操作以一種計(jì)算成本較低的格式運(yùn)行中。該方法已被廣泛應(yīng)用于各種模型,包括BERT[4]、ResNet和GNMT[5],并被廣泛認(rèn)可的機(jī)器學(xué)習(xí)基準(zhǔn)測(cè)試所采用[6]。
量化過程包括以下一項(xiàng)或兩項(xiàng):
1)減少數(shù)據(jù)類型的位數(shù)。例如,使用8位而不是32位。
2)使用成本較低的格式。例如,使用整數(shù)代替浮點(diǎn)數(shù)。
量化為整數(shù)是人工智能推理的常用選擇。以INTX(通常是INT8)整數(shù)格式運(yùn)行推理被廣泛用于部署,包括機(jī)器翻譯[7]、自動(dòng)語音識(shí)別[8]、計(jì)算機(jī)視覺[9]和嵌入式自然語言處理(NLP)[5]等領(lǐng)域的模型。
得益于硬件供應(yīng)商的支持,除了INTX和FP16之外的其他格式正變得越來越通用。例如,Google TPU和Intel Xeon CPU就支持BrainFloat16格式。最近,微軟也已展示了塊浮點(diǎn)格式[10]能夠利用訓(xùn)練后的量化流程使網(wǎng)絡(luò)保持精度,并且實(shí)現(xiàn)更高效的硬件計(jì)算。塊浮點(diǎn)格式可在一系列小數(shù)值部分(通常為8或16)上共享單個(gè)指數(shù)值。該方案比定點(diǎn)算法提供更好的動(dòng)態(tài)范圍,同時(shí)精度接近傳統(tǒng)的浮點(diǎn),但計(jì)算效率相當(dāng)于整數(shù)處理。圖2演示了塊浮點(diǎn)格式。
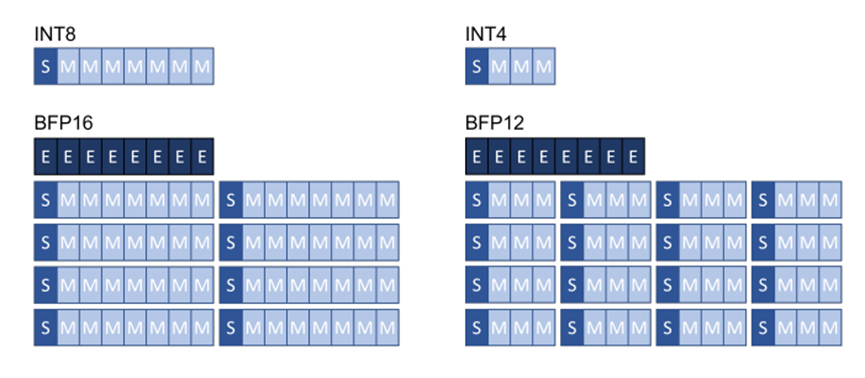
圖2. 塊浮點(diǎn)量化格式
Achronix Speedster7t FPGA器件可以支持一系列數(shù)值格式,因?yàn)樗贔PGA上的機(jī)器學(xué)習(xí)處理模塊中具有完全可拆分的整數(shù)MAC。該機(jī)器學(xué)習(xí)處理模塊支持INT16、INT8或INT4乘法運(yùn)算。浮點(diǎn)MAC的增加使器件能夠支持fp16, fp24和bf16浮點(diǎn)格式。通過組合兩個(gè)MAC,則可以支持使用任意塊大小的塊浮點(diǎn)格式,從而使器件能夠?qū)崿F(xiàn)BFP16和BFP12等格式。表1顯示了所支持的數(shù)值格式及其可實(shí)現(xiàn)的TOPS和相關(guān)的內(nèi)存壓縮系數(shù)。在本文中,我們使用塊大小為8的BFP16和塊大小為16的BFP12。
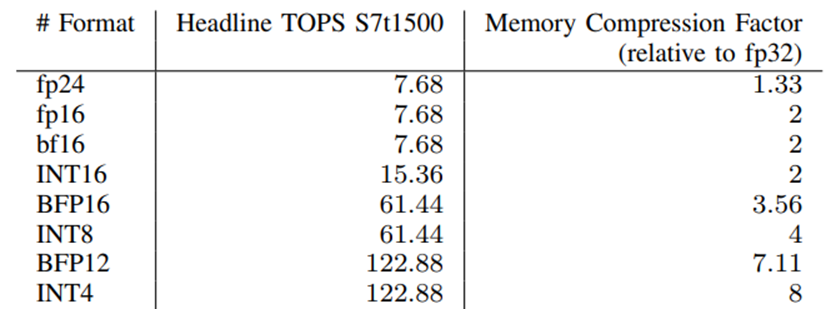
表1. Speedster7t1500在不同數(shù)值格式下的計(jì)算能力
除了提高計(jì)算效率外,精度更低的格式還降低了推理平臺(tái)的內(nèi)存帶寬要求,這對(duì)于受限于內(nèi)存的處理和低延遲應(yīng)用來說,可以帶來性能的線性提高。
C. GDDR6存儲(chǔ)器
Speedster7t的機(jī)器學(xué)習(xí)處理模塊中包含的BRAM提供了總計(jì)195Mbit的片上存儲(chǔ)資源,足以持久地容納精度為INT8的、規(guī)模在24Mbyte以下的AI模型。當(dāng)神經(jīng)網(wǎng)絡(luò)的大小超過這個(gè)閾值時(shí),模型參數(shù)就需要存儲(chǔ)在更大的外部存儲(chǔ)器中。就Speedster7t而言,該器件支持最大32GB的外部GDDR6存儲(chǔ)器。GDDR6存儲(chǔ)器接口如圖3所示。這樣就可以處理更大的模型,基于4Tb /s的帶寬將模型參數(shù)移動(dòng)到器件上,以支持低延遲處理。
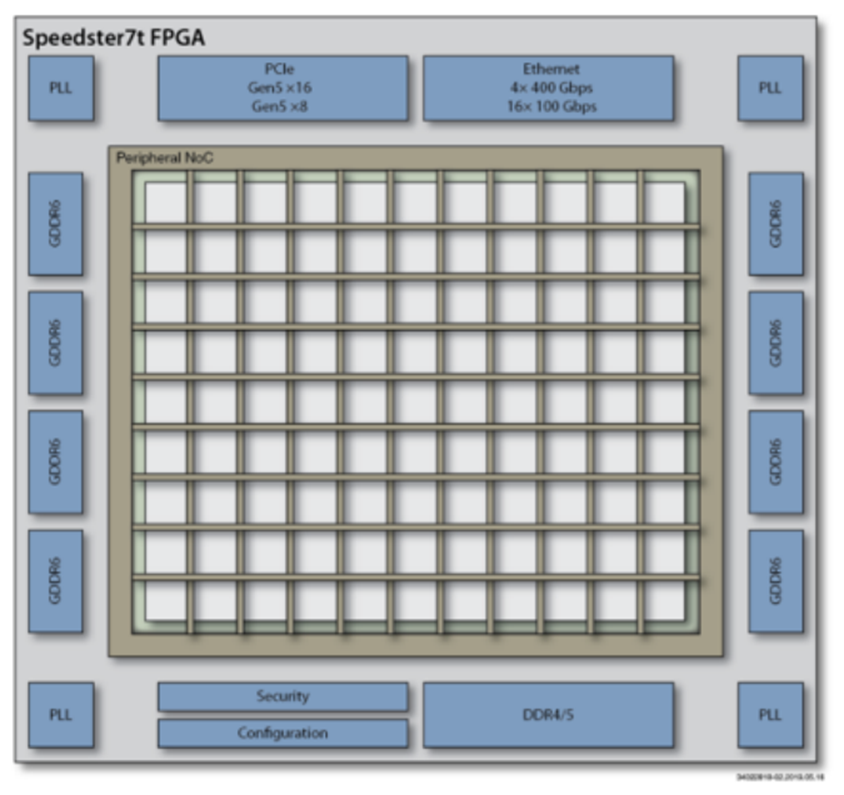
圖3. Achronix Speedster7t FPGA的外部接口
想要理解一款器件用于AI推理的性能,重要的是要同時(shí)綜合考慮計(jì)算性能和存儲(chǔ)性能;這對(duì)于理解低延遲部署或存儲(chǔ)密集型網(wǎng)絡(luò)情況下的性能限制尤為重要;我們可以看到實(shí)時(shí)數(shù)據(jù)流ASR和transformer模型架構(gòu)等方面的案例。卷積神經(jīng)網(wǎng)絡(luò)(CNN)通常要求低存儲(chǔ)帶寬,即使是在小批量的情況下也是如此,因此用于CNN的推理解決方案并沒有針對(duì)高帶寬存儲(chǔ)進(jìn)行優(yōu)化。
D.全硬件化的片上網(wǎng)絡(luò)
只有在模型參數(shù)能夠被移動(dòng)到器件上的計(jì)算引擎中同時(shí)不損失效率的情況下,擁有大的外部存儲(chǔ)帶寬才有用武之地。Speedster7t系列器件包含一個(gè)硬核的二維片上網(wǎng)絡(luò)(2D-NoC),在整個(gè)FPGA的總數(shù)據(jù)傳輸帶寬可以到20Tb/s。這使得數(shù)據(jù)可以方便地從外部存儲(chǔ)器移動(dòng)到器件的計(jì)算引擎中,并可實(shí)現(xiàn)跨FPGA邏輯陣列傳輸,從而不會(huì)受限于FPGA計(jì)算資源對(duì)外部存儲(chǔ)的訪問帶寬。此外,這種2D-NoC減少了為搬運(yùn)數(shù)據(jù)而造成邏輯資源的消耗,從而節(jié)省了FPGA邏輯中用于路由的資源,并實(shí)現(xiàn)更好的時(shí)序收斂效果。
2D-NoC的原理如圖4所示。
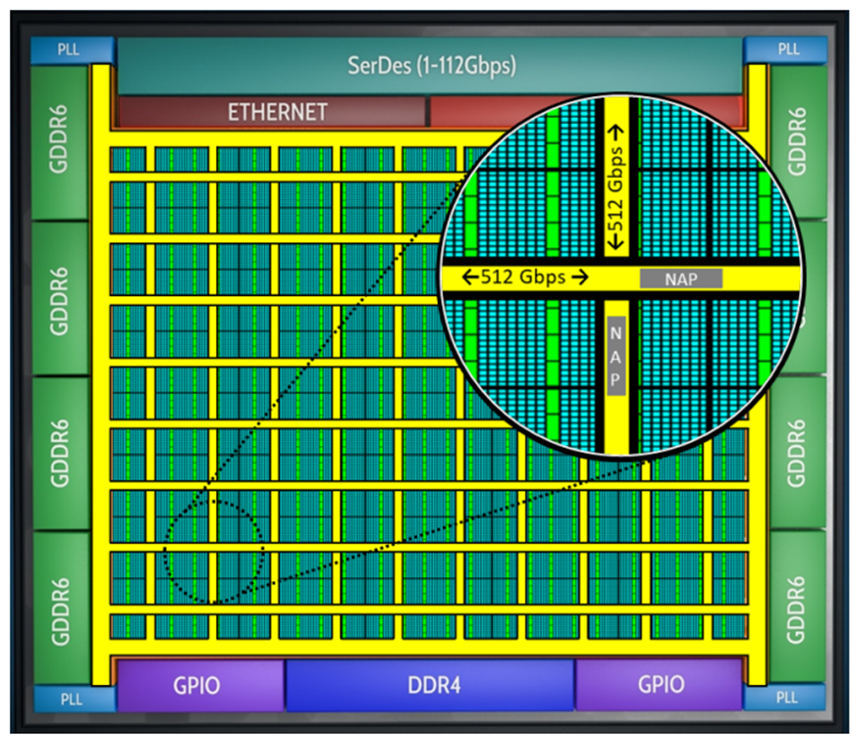
圖4. Achronix Speedster7t FPGA中帶有的二維片上網(wǎng)絡(luò)(2D-NoC)
III. 針對(duì)Speedster7t的一種AI疊加層架構(gòu)
為了對(duì)Speedster7t系列FPGA器件進(jìn)行基準(zhǔn)測(cè)試,我們給在Bittware S7t-VG6 VectorPath PCIe加速卡上的FPGA器件(Speedster7t1500)創(chuàng)建了一個(gè)AI推理疊加設(shè)計(jì)。疊加層采用Myrtle.ai可編程的MAU Accelerator架構(gòu)來構(gòu)建,MAU內(nèi)核是一個(gè)用于深度神經(jīng)網(wǎng)絡(luò)的可編程的處理引擎,它通過FPGA邏輯資源來構(gòu)建,以提供一個(gè)靈活的且運(yùn)行時(shí)可配置的推理引擎。我們將4個(gè)專門為Achronix FPGA器件(Speedster7t1500)進(jìn)行優(yōu)化的MAU內(nèi)核放置在其加速卡上的Achronix FPGA(Speedster7t1500)中去運(yùn)行,并演示可實(shí)現(xiàn)的利用率和時(shí)序結(jié)果。
該設(shè)計(jì)使用4個(gè)MAU 加速器內(nèi)核,每個(gè)內(nèi)核都包含512個(gè)機(jī)器學(xué)習(xí)處理模塊(MLP)模塊,以形成所有機(jī)器學(xué)習(xí)推理所需的核心點(diǎn)積電路。完整的設(shè)計(jì)使用了80%的MLP資源來實(shí)現(xiàn)點(diǎn)積計(jì)算,剩余的20%用于額外的計(jì)算操作和非線性運(yùn)算,或者僅作為塊RAM。
該設(shè)計(jì)使用BFP16格式實(shí)現(xiàn),如圖2所示。它使用8位尾數(shù)和8位指數(shù),模塊大小均為8。這樣可以得到較好的模型精度,可以應(yīng)用于訓(xùn)練后的模型,而不會(huì)損失網(wǎng)絡(luò)精度,同時(shí)簡(jiǎn)化了架構(gòu)疊加的用戶流程。
我們通過Achronix ACE軟件中對(duì)MAU Accelerator內(nèi)核進(jìn)行布局,以確保保持高時(shí)鐘頻率的同時(shí)可以實(shí)現(xiàn)高的邏輯資源利用率。
疊加架構(gòu)的總算力為36.4 TOPS,是FPGA邏輯陣列采用INT8格式時(shí)總計(jì)算能力的59.2%。這樣高的效率數(shù)字是通過使用雙時(shí)鐘方案來實(shí)現(xiàn)的,使MLP模塊能夠以560MHz運(yùn)行,是這些組件的750MHz額定Fmax的74.7%,同時(shí)可以在FPGA邏輯中以280MHz的頻率實(shí)現(xiàn)所有邏輯功能。
為MAU Accelerator內(nèi)核優(yōu)化的Achronix Speedster7t FPGA架構(gòu)如圖5所示。它具有面向GEMV和多層感知器(MLP)操作來實(shí)現(xiàn)AI基準(zhǔn)測(cè)試所需的所有功能。
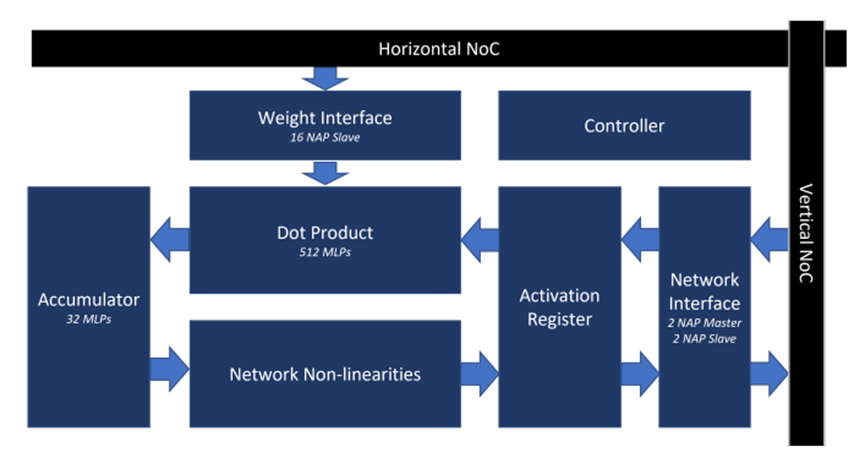
圖5. Achronix Speedstert FPGA上的MAU內(nèi)核架構(gòu)
A.針對(duì)機(jī)器學(xué)習(xí)處理模塊的一種雙時(shí)鐘方案
一種雙時(shí)鐘方案被用來為該FPGA中的機(jī)器學(xué)習(xí)處理模塊提供時(shí)鐘。這使得硬核化的芯片組件能夠以比邏輯陣列主頻更高的時(shí)鐘頻率運(yùn)行,從而使實(shí)際設(shè)計(jì)應(yīng)用可以接近這些模塊的設(shè)計(jì)規(guī)范的工作頻點(diǎn)。這是可能的,因?yàn)闄C(jī)器學(xué)習(xí)處理模塊內(nèi)的BRAM和MAC單元相互緊密耦合,從而使得高權(quán)重的數(shù)據(jù)通過模塊內(nèi)的專用線路傳輸?shù)組AC。BRAM和MAC之間用于在機(jī)器學(xué)習(xí)處理模塊中傳輸權(quán)重的專用線路可承載177 Tb/s的速率,是激活輸入的16倍。
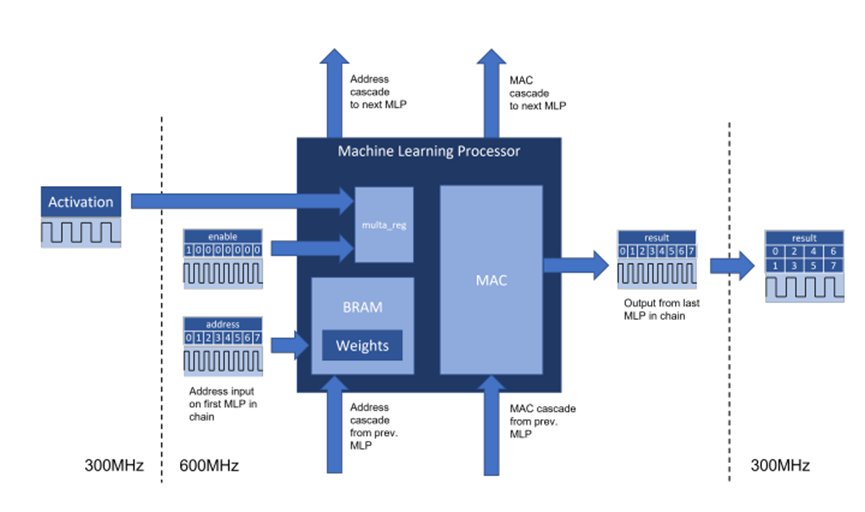
圖6. 在Achronix Speedster7t FPGA器件上用于MAU內(nèi)核架構(gòu)的雙時(shí)鐘方案
位于MAU Accelerator內(nèi)核中心的點(diǎn)積電路將256x256矩陣和256向量數(shù)據(jù)進(jìn)行相乘。矩陣通常用于權(quán)重,向量通常用于激活。激活向量在560MHz時(shí)鐘域上保持恒定超過8個(gè)周期,而權(quán)重則從與MAC緊密耦合的BRAM中讀取,并在每個(gè)周期進(jìn)行更改。機(jī)器學(xué)習(xí)處理模塊被排列成每列32個(gè)共16列,它們被級(jí)聯(lián)在一起以便每列都可計(jì)算兩個(gè)大小為256的BFP16點(diǎn)積。
激活向量通過激活扇出組件分發(fā)到機(jī)器學(xué)習(xí)處理模塊中,該組件還處理延遲激活,以與機(jī)器學(xué)習(xí)處理模塊之間的級(jí)聯(lián)傳遞的部分和相對(duì)齊。要從結(jié)果中讀取的權(quán)重索引在列的頂部輸出。輸出在560MHz域上,相鄰時(shí)鐘周期的值則通過一個(gè)邏輯反序列化器連接并傳輸?shù)?80MHz域上。機(jī)器學(xué)習(xí)處理模塊在每個(gè)內(nèi)核中都被布置為兩個(gè)外部列,并保留中央列以供其他設(shè)計(jì)單元和網(wǎng)絡(luò)特定操作使用。這可以在圖7的布局中看到。
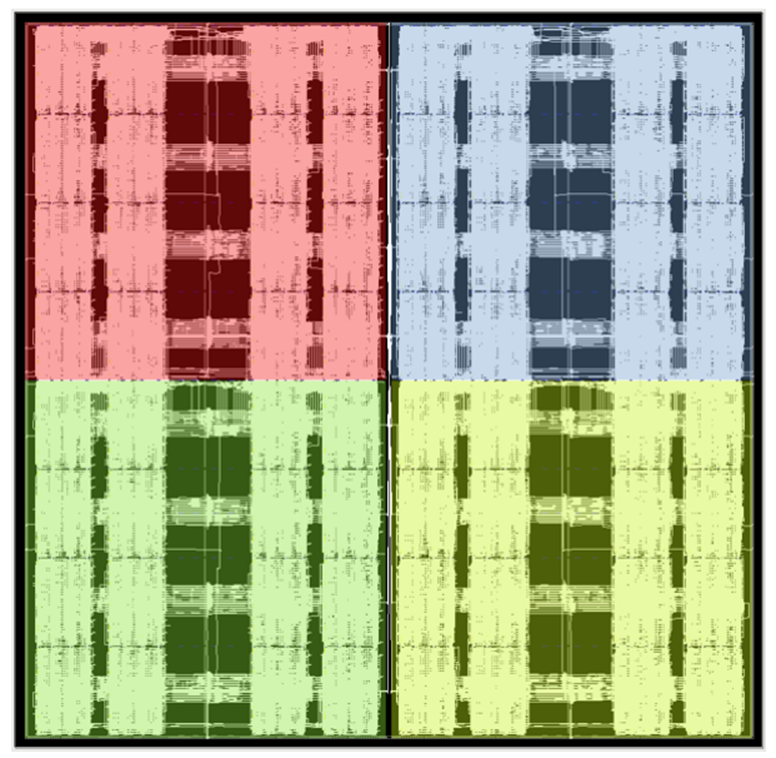
圖7. Achronix Speedster7t FPGA上點(diǎn)積電路的平面布置圖
B.二維片上網(wǎng)絡(luò)(2D-NoC)的使用
二維片上網(wǎng)絡(luò)(2D-NoC)被用于在整個(gè)設(shè)計(jì)中傳輸數(shù)據(jù),降低了將邏輯陣列資源用于數(shù)據(jù)傳輸?shù)男枨蟆?D-NoC用于通過PCIe接口在CPU和FPGA之間傳輸推理數(shù)據(jù);于運(yùn)行時(shí)在GDDR6和MAU Accelerator加速器內(nèi)核之間傳輸權(quán)重?cái)?shù)據(jù),從而使大型網(wǎng)絡(luò)能夠保存在片外存儲(chǔ)器中;并可以用于在芯片上的MAU Accelerator加速器內(nèi)核之間傳輸推理數(shù)據(jù),從而使數(shù)據(jù)能夠在實(shí)現(xiàn)不同層操作的內(nèi)核之間傳遞,或跨內(nèi)核拆分矩陣操作。
每個(gè)內(nèi)核都有16個(gè)網(wǎng)絡(luò)接入點(diǎn)(NAP),用于從GDDR6加載權(quán)重;這些接入點(diǎn)NAP在280MHz主頻時(shí)提供高達(dá)1.12 Tb/s的帶寬,這大于每個(gè)內(nèi)核分配到的1Tb/s可用內(nèi)存帶寬。這可以確保在受限于內(nèi)存的網(wǎng)絡(luò)和低延遲操作場(chǎng)景中去實(shí)現(xiàn)最高性能。每個(gè)內(nèi)核所具有的16個(gè)NAP Slave的從連接分布在4個(gè)hNoC行上。
對(duì)于主機(jī)到內(nèi)核和內(nèi)核到內(nèi)核的數(shù)據(jù)傳輸,該設(shè)計(jì)中每個(gè)內(nèi)核都具有2個(gè)NAP Master主連接和2個(gè)NAP Slave從連接。內(nèi)核間的數(shù)據(jù)帶寬為143.36 Gbps。除了非常小的矩陣計(jì)算外,這對(duì)于在內(nèi)核之間傳輸?shù)拇蠖鄶?shù)操作來說已經(jīng)足夠了。
C.器件利用率
該器件用于加速器疊加架構(gòu)時(shí)的資源利用率如表II所示。這表明,用于實(shí)現(xiàn)高性能AI計(jì)算的機(jī)器學(xué)習(xí)處理模塊和BRAM的利用率都非常高,同時(shí)只有LUT和DFF在邏輯陣列中具有低資源利用率。這為在邏輯陣列中實(shí)現(xiàn)其他功能提供了空間,并減少了邏輯陣列中的路由擁塞,從而在FPGA中獲得更高的時(shí)鐘頻率。
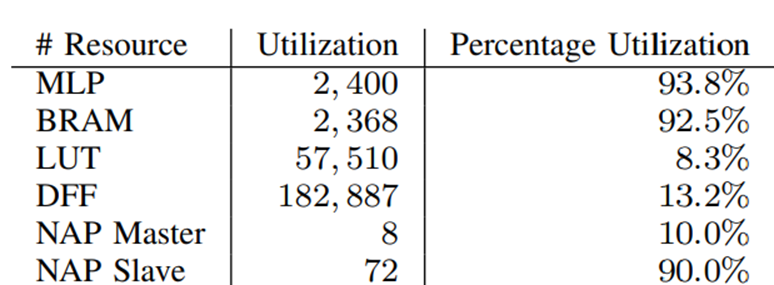
表2. MAU Accelerator加速器內(nèi)核疊加架構(gòu)的資源利用率
IV. AI基準(zhǔn)測(cè)試結(jié)果
A.測(cè)試方法
我們?cè)赟peedster7t上對(duì)兩種簡(jiǎn)單的操作進(jìn)行基準(zhǔn)測(cè)試,以說明AI網(wǎng)絡(luò)可以達(dá)到的性能。我們執(zhí)行了GEMV基準(zhǔn)測(cè)試和多層感知器(MLP)基準(zhǔn)測(cè)試。GEMV測(cè)試展示了所有AI基準(zhǔn)測(cè)試的核心操作的性能。
GEMV-N基準(zhǔn)測(cè)試計(jì)算Ax + y,其中A是維數(shù)為N的方陣,x和y為N的向量。MLP-N基準(zhǔn)測(cè)試計(jì)算一個(gè)5層的多層感知器,每層都被定義為layeri(xi) = Wixi+bi,其中Wi為N × N方陣。每一層的輸入如下,xi+1 = layeri(xi), x0是輸入。
我們使用硬件周期計(jì)數(shù)器來測(cè)量計(jì)算一個(gè)特定基準(zhǔn)測(cè)試所需的時(shí)間,并從穩(wěn)態(tài)測(cè)量中推斷吞吐量。我們沒有對(duì)CPU和FPGA之間的數(shù)據(jù)傳輸進(jìn)行計(jì)時(shí),因?yàn)檫@只會(huì)支配這些非常小的基準(zhǔn)測(cè)試操作的處理時(shí)間。在最初從外部GDDR6存儲(chǔ)器加載之后,所有的基準(zhǔn)測(cè)試都使用存儲(chǔ)于BRAM中的常量。
B,計(jì)算性能
圖8顯示了GEMV和MLP在不同大小的矩陣上所展示的高性能。基準(zhǔn)測(cè)試在四個(gè)內(nèi)核上并行進(jìn)行,因此Batch 4意味著在每個(gè)內(nèi)核上獨(dú)立運(yùn)行一個(gè)推理。對(duì)于Batch 20的結(jié)果,每個(gè)內(nèi)核就要運(yùn)行5個(gè)流水線推理。疊加架構(gòu)被用作GEMV基準(zhǔn)測(cè)試,效率為100%,其中矩陣可被512整除。
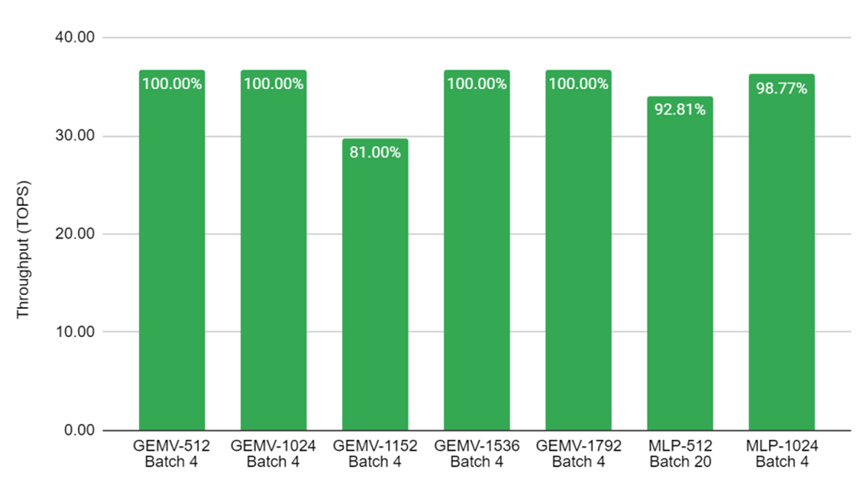
圖8.在Achronix S7t-VG6 VectorPath加速卡上進(jìn)行關(guān)鍵AI基準(zhǔn)測(cè)試的吞吐量數(shù)值。結(jié)果是在C2速度等級(jí)的器件上以560MHz運(yùn)行來測(cè)量的。坐標(biāo)標(biāo)簽顯示了利用率占MAU Accelerator總性能的百分比。
C.可實(shí)現(xiàn)最高性能
考慮到用于低延遲和實(shí)時(shí)應(yīng)用的加速平臺(tái),圖9顯示了Achronix Speedster7t1500器件實(shí)現(xiàn)的最高性能曲線。在該器件上可以36.4 TOPS的算力實(shí)現(xiàn)算術(shù)強(qiáng)度超過70個(gè)運(yùn)算/字節(jié)的網(wǎng)絡(luò)以 RNN-T 操作點(diǎn)為例,突出顯示加速器在流式部署中以批處理大小為 8 和 80ms 塊大小的 MLPerf RNN-T 參考模型的處理需求。
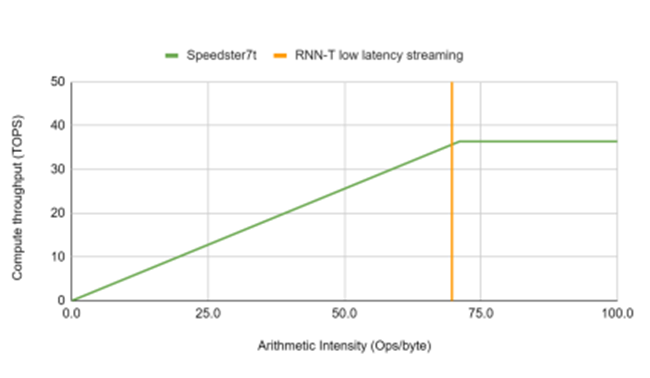
圖9. 通過使用總內(nèi)存帶寬,Achronix器件實(shí)現(xiàn)的最高性能曲線和RNN-T工作點(diǎn)
V.結(jié)論
本文展示了由Achronix提供的全新專為AI優(yōu)化的FPGA器件——Speedster7t1500系列,當(dāng)被應(yīng)用于關(guān)鍵AI基準(zhǔn)測(cè)試時(shí),能夠?qū)崿F(xiàn)59.2%的效率和36.4 TOPS的算力。其專為AI優(yōu)化的架構(gòu)支持高時(shí)鐘頻率計(jì)算,且高外部?jī)?nèi)存帶寬使該器件非常適合用于低延遲工作負(fù)載。
-
FPGA
+關(guān)注
關(guān)注
1643文章
21983瀏覽量
614653 -
半導(dǎo)體
+關(guān)注
關(guān)注
335文章
28669瀏覽量
233468 -
AI
+關(guān)注
關(guān)注
88文章
34421瀏覽量
275771 -
Achronix
+關(guān)注
關(guān)注
1文章
76瀏覽量
22723
原文標(biāo)題:基于Achronix Speedster?7t FPGA器件的AI基準(zhǔn)測(cè)試
文章出處:【微信號(hào):Achronix,微信公眾號(hào):Achronix】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Achronix Speedster7t FPGA如何運(yùn)用GDDR6滿足網(wǎng)絡(luò)產(chǎn)品的高帶寬需求
利用片上高速網(wǎng)絡(luò)(2D NoC)創(chuàng)新地實(shí)現(xiàn)FPGA內(nèi)部超高帶寬邏輯互連
中高端FPGA如何選擇
Achronix推出Speedster7tFPGA系列產(chǎn)品 簡(jiǎn)化設(shè)計(jì)FPGA靈活性

Achronix推全新7nm FPGA 首度支持GDDR6高帶寬存儲(chǔ)

BittWare和Achronix合作推出采用7納米的Speedster7t FPGA
2D NoC可實(shí)現(xiàn)FPGA內(nèi)部超高帶寬的邏輯互連
Achronix展示Speedster7t高性能接口 貿(mào)澤備貨Molex電路板連接器
Achronix Speedster7t FPGA芯片中2D NoC的設(shè)計(jì)細(xì)節(jié)
Speedster7t FPGA中可編程邏輯的架構(gòu)
Achronix將在SC22上展示全系列基于FPGA的硬件數(shù)據(jù)處理加速器
Achronix的FPGA有哪方面的優(yōu)勢(shì)?

采用創(chuàng)新的FPGA 器件來實(shí)現(xiàn)更經(jīng)濟(jì)且更高能效的大模型推理解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論