") GPU將失寵,ASIC 才是AI 前景所在
GPU將失寵,ASIC 才是AI 前景所在

GPU 在人工智能(AI)運(yùn)算大放異彩,激勵(lì)兩家GPU 大廠Nvidia、超微(AMD)股價(jià)狂飆。但是分析師警告,明年GPU 在AI 的地位,也許會(huì)遭「特殊應(yīng)用集成電路」(ASIC)取代。
12 日Nvidia 下跌1.96%,13 日續(xù)跌2.44% 收在186.18 美元。12 日超微下跌2.56%,13 日反彈2.12% 收在10.11 美元。
MarketWatch、Smarter Analyst報(bào)導(dǎo),Susquehanna分析師Christopher Rolland 12日報(bào)告稱,2017年AI GPU當(dāng)?shù)溃?018年可能換成ASIC發(fā)威。AI運(yùn)用深度學(xué)習(xí)解決真實(shí)世界問題,也使用在語音和影像辨識(shí)、自動(dòng)駕駛、醫(yī)療等,Nvidia是AI工作量大增的受惠者,股價(jià)暴沖。不過,Susquehanna和多位業(yè)界領(lǐng)袖討論,判斷ASIC可能會(huì)取代GPU。
Rolland 以虛擬貨幣挖礦為例,解釋此一變化。早期礦工挖掘虛幣時(shí),多用GPU,不過隨著挖礦難度不斷提高,礦工逐漸改用ASIC。現(xiàn)在比特幣礦工多半采用ASIC,以太幣礦工也會(huì)在今年改用ASIC。市面上更出現(xiàn)以太幣專用ASIC,效能遠(yuǎn)勝GPU。
報(bào)告稱,Nvidia 有ASIC 相關(guān)部門,未來仍會(huì)在AI 扮演重要角色。但是市場將有更多競爭者,有望受惠的ASIC 業(yè)者,包括協(xié)助谷歌研發(fā)AI 芯片的博通、Cavium、Marvell、Microsemi 等。
另外,現(xiàn)場可程式化閘陣列(Field-Programmable Gate Array,FPGA)也可能從AI 熱潮沾光,賽靈思(Xilinx)的FPGA 就用于亞馬遜云端服務(wù)。
芯片商Cerebras 正在研發(fā)AI 專用的ASIC,該公司執(zhí)行長Andrew Feldman 強(qiáng)調(diào),GPU 并非最適合AI 運(yùn)算的芯片。GPU 原本是為了電玩開發(fā),如今卻碰巧適用于另一個(gè)毫不相干的新市場。這種幸運(yùn)的巧合不會(huì)發(fā)生,最可能的解釋是,GPU 只是當(dāng)前最佳的解決方案,讓業(yè)界能繼續(xù)往前,暗示ASIC 才是AI 前景所在。
Barron's.com 8 月23 日報(bào)導(dǎo),摩根士丹利(Morgan Stanley,通稱大摩)發(fā)表研究報(bào)告指出,現(xiàn)場可程式化閘陣列在機(jī)器學(xué)習(xí)進(jìn)行「推論」(inference)時(shí)扮演的角色,可能比市場想像還要大,Xilinx 有望受惠。
GPU、FPGA、ASIC,誰更適合人工智能?
圍繞著人工智能的計(jì)算,有上述三種方案,我們來看一下哪一種會(huì)是AI首選。
GPU主要擅長做類似圖像處理的并行計(jì)算,所謂的“粗粒度并行(coarse-grain parallelism)”。圖形處理計(jì)算的特征表現(xiàn)為高密度的計(jì)算而計(jì)算需要的數(shù)據(jù)之間較少存在相關(guān)性,GPU 提供大量的計(jì)算單元(多達(dá)幾千個(gè)計(jì)算單元)和大量的高速內(nèi)存,可以同時(shí)對很多像素進(jìn)行并行處理。
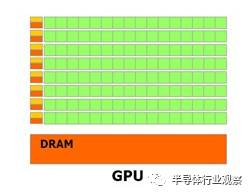
GPU中一個(gè)邏輯控制單元對應(yīng)多個(gè)計(jì)算單元,同時(shí)要想計(jì)算單元充分并行起來,邏輯控制必然不會(huì)太復(fù)雜,太復(fù)雜的邏輯控制無法發(fā)揮計(jì)算單元的并行度,例如過多的if…else if…else if… 分支計(jì)算就無法提高計(jì)算單元的并行度,所以在GPU中邏輯控制單元也就不需要能夠快速處理復(fù)雜控制。
這里GPU計(jì)算能力用Nvidia的Tesla K40進(jìn)行分析,K40包含2880個(gè)流處理器(Stream Processor),流處理器就是GPU的計(jì)算單元。每個(gè)流處理器包含一個(gè)32bit單精度浮點(diǎn)乘和加單元,即每個(gè)時(shí)鐘周期可以做2個(gè)單精度浮點(diǎn)計(jì)算。GPU峰值浮點(diǎn)計(jì)算性能 = 流處理器個(gè)數(shù) GPU頻率 每周期執(zhí)行的浮點(diǎn)操作數(shù)。以K40為例,K40峰值浮點(diǎn)計(jì)算性能= 2880(流處理器) 745MHz 2(乘和加) = 4.29T FLOPs/s即每秒4.29T峰值浮點(diǎn)計(jì)算能力。
GPU芯片結(jié)構(gòu)是否可以充分發(fā)揮浮點(diǎn)計(jì)算能力?GPU同CPU一樣也是指令執(zhí)行過程:取指令 ->指令譯碼 ->指令執(zhí)行,只有在指令執(zhí)行的時(shí)候,計(jì)算單元才發(fā)揮作用。GPU的邏輯控制單元相比CPU簡單,所以要想做到指令流水處理,提高指令執(zhí)行效率,必然要求處理的算法本身復(fù)雜度低,處理的數(shù)據(jù)之間相互獨(dú)立,所以算法本身的串行處理會(huì)導(dǎo)致GPU浮點(diǎn)計(jì)算能力的顯著降低。
上圖是GPU的設(shè)計(jì)結(jié)構(gòu)。GPU的設(shè)計(jì)出發(fā)點(diǎn)在于GPU更適用于計(jì)算強(qiáng)度高、多并行的計(jì)算。因此,GPU把晶體管更多用于計(jì)算單元,而不像CPU用于數(shù)據(jù)Cache和流程控制器。這樣的設(shè)計(jì)是因?yàn)椴⑿杏?jì)算時(shí)每個(gè)數(shù)據(jù)單元執(zhí)行相同程序,不需要繁瑣的流程控制而更需要高計(jì)算能力,因此也不需要大的cache容量。
FPGA作為一種高性能、低功耗的可編程芯片,可以根據(jù)客戶定制來做針對性的算法設(shè)計(jì)。所以在處理海量數(shù)據(jù)的時(shí)候,F(xiàn)PGA 相比于CPU 和GPU,優(yōu)勢在于:FPGA計(jì)算效率更高,F(xiàn)PGA更接近IO。
FPGA不采用指令和軟件,是軟硬件合一的器件。對FPGA進(jìn)行編程要使用硬件描述語言,硬件描述語言描述的邏輯可以直接被編譯為晶體管電路的組合。所以FPGA實(shí)際上直接用晶體管電路實(shí)現(xiàn)用戶的算法,沒有通過指令系統(tǒng)的翻譯。
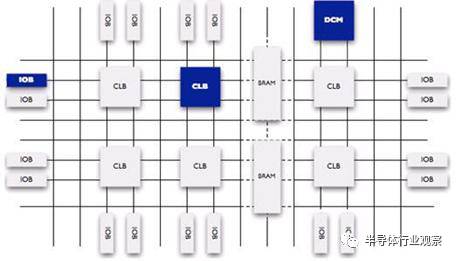
FPGA的英文縮寫名翻譯過來,全稱是現(xiàn)場可編程邏輯門陣列,這個(gè)名稱已經(jīng)揭示了FPGA的功能,它就是一堆邏輯門電路的組合,可以編程,還可以重復(fù)編程。上圖展示了可編程FPGA的內(nèi)部原理圖。
里FPGA計(jì)算能力用Xilinx的V7-690T進(jìn)行分析,V7-690T包含3600個(gè)DSP(Digital Signal Processing),DSP就是FPGA的計(jì)算單元。每個(gè)DSP可以在每個(gè)時(shí)鐘周期可以做2個(gè)單精度浮點(diǎn)計(jì)算(乘和加)。FPGA峰值浮點(diǎn)計(jì)算性能 = DSP個(gè)數(shù) FPGA頻率 每周期執(zhí)行的浮點(diǎn)操作數(shù)。V7-690T運(yùn)行頻率已250MHz來計(jì)算,V7-690T峰值浮點(diǎn)計(jì)算性能 = 3600(DSP個(gè)數(shù)) 250MHz 2(乘和加)=1.8T FLOPs/s即每秒1.8T峰值浮點(diǎn)計(jì)算能力。
FPGA芯片結(jié)構(gòu)是否可以充分發(fā)揮浮點(diǎn)計(jì)算能力?FPGA由于算法是定制的,所以沒有CPU和GPU的取指令和指令譯碼過程,數(shù)據(jù)流直接根據(jù)定制的算法進(jìn)行固定操作,計(jì)算單元在每個(gè)時(shí)鐘周期上都可以執(zhí)行,所以可以充分發(fā)揮浮點(diǎn)計(jì)算能力,計(jì)算效率高于CPU和GPU。
ASIC是一種專用芯片,與傳統(tǒng)的通用芯片有一定的差異。是為了某種特定的需求而專門定制的芯片。ASIC芯片的計(jì)算能力和計(jì)算效率都可以根據(jù)算法需要進(jìn)行定制,所以ASIC與通用芯片相比,具有以下幾個(gè)方面的優(yōu)越性:體積小、功耗低、計(jì)算性能高、計(jì)算效率高、芯片出貨量越大成本越低。但是缺點(diǎn)也很明顯:算法是固定的,一旦算法變化就可能無法使用。目前人工智能屬于大爆發(fā)時(shí)期,大量的算法不斷涌出,遠(yuǎn)沒有到算法平穩(wěn)期,ASIC專用芯片如何做到適應(yīng)各種算法是個(gè)最大的問題,如果以目前CPU和GPU架構(gòu)來適應(yīng)各種算法,那ASIC專用芯片就變成了同CPU、GPU一樣的通用芯片,在性能和功耗上就沒有優(yōu)勢了。
我們來看看FPGA 和 ASIC 的區(qū)別。FPGA基本原理是在芯片內(nèi)集成大量的數(shù)字電路基本門電路以及存儲(chǔ)器,而用戶可以通過燒入 FPGA 配置文件來來定義這些門電路以及存儲(chǔ)器之間的連線。這種燒入不是一次性的,即用戶今天可以把 FPGA 配置成一個(gè)微控制器 MCU,明天可以編輯配置文件把同一個(gè) FPGA 配置成一個(gè)音頻編解碼器。ASIC 則是專用集成電路,一旦設(shè)計(jì)制造完成后電路就固定了,無法再改變。
比較 FPGA 和 ASIC 就像比較樂高積木和模型。舉例來說,如果你發(fā)現(xiàn)最近星球大戰(zhàn)里面 Yoda 大師很火,想要做一個(gè) Yoda 大師的玩具賣,你要怎么辦呢?
有兩種辦法,一種是用樂高積木搭,還有一種是找工廠開模定制。用樂高積木搭的話,只要設(shè)計(jì)完玩具外形后去買一套樂高積木即可。而找工廠開模的話在設(shè)計(jì)完玩具外形外你還需要做很多事情,比如玩具的材質(zhì)是否會(huì)散發(fā)氣味,玩具在高溫下是否會(huì)融化等等,所以用樂高積木來做玩具需要的前期工作比起找工廠開模制作來說要少得多,從設(shè)計(jì)完成到能夠上市所需要的時(shí)間用樂高也要快很多。
FPGA 和 ASIC 也是一樣,使用 FPGA 只要寫完 Verilog 代碼就可以用 FPGA 廠商提供的工具實(shí)現(xiàn)硬件加速器了,而要設(shè)計(jì) ASIC 則還需要做很多驗(yàn)證和物理設(shè)計(jì) (ESD,Package 等等),需要更多的時(shí)間。如果要針對特殊場合(如軍事和工業(yè)等對于可靠性要求很高的應(yīng)用),ASIC 則需要更多時(shí)間進(jìn)行特別設(shè)計(jì)以滿足需求,但是用 FPGA 的話可以直接買軍工級的高穩(wěn)定性 FPGA 完全不影響開發(fā)時(shí)間。但是,雖然設(shè)計(jì)時(shí)間比較短,但是樂高積木做出來的玩具比起工廠定制的玩具要粗糙(性能差)一些(下圖),畢竟工廠開模是量身定制。
另外,如果出貨量大的話,工廠大規(guī)模生產(chǎn)玩具的成本會(huì)比用樂高積木做便宜許多。FPGA 和 ASIC 也是如此,在同一時(shí)間點(diǎn)上用最好的工藝實(shí)現(xiàn)的 ASIC 的加速器的速度會(huì)比用同樣工藝 FPGA 做的加速器速度快 5-10 倍,而且一旦量產(chǎn)后 ASIC 的成本會(huì)遠(yuǎn)遠(yuǎn)低于 FPGA 方案。
FPGA 上市速度快, ASIC 上市速度慢,需要大量時(shí)間開發(fā),而且一次性成本(光刻掩模制作成本)遠(yuǎn)高于 FPGA,但是性能高于 FPGA 且量產(chǎn)后平均成本低于 FPGA。目標(biāo)市場方面,F(xiàn)PGA 成本較高,所以適合對價(jià)格不是很敏感的地方,比如企業(yè)應(yīng)用,軍事和工業(yè)電子等等(在這些領(lǐng)域可重配置真的需要)。而 ASIC 由于低成本則適合消費(fèi)電子類應(yīng)用,而且在消費(fèi)電子中可配置是否是一個(gè)偽需求還有待商榷。
我們看到的市場現(xiàn)狀也是如此:使用 FPGA 做深度學(xué)習(xí)加速的多是企業(yè)用戶,百度、微軟、IBM 等公司都有專門做 FPGA 的團(tuán)隊(duì)為服務(wù)器加速,而做 FPGA 方案的初創(chuàng)公司 Teradeep 的目標(biāo)市場也是服務(wù)器。而 ASIC 則主要瞄準(zhǔn)消費(fèi)電子,如 Movidius。由于移動(dòng)終端屬于消費(fèi)電子領(lǐng)域,所以未來使用的方案應(yīng)當(dāng)是以 ASIC 為主。
由于不同的芯片生產(chǎn)工藝,對芯片的功耗和性能都有影響,這里用相同工藝或者接近工藝下進(jìn)行對比,ASIC芯片還沒有商用的芯片出現(xiàn),Google的TPU也只是自己使用沒有對外提供信息,這里ASIC芯片用在學(xué)術(shù)論文發(fā)表的《DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning》作為代表。
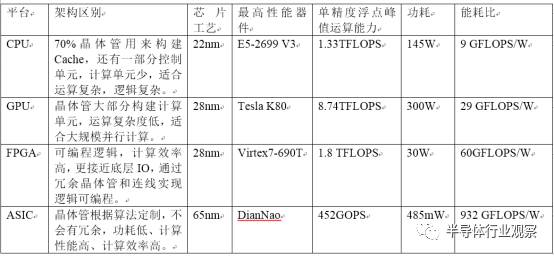
從上面的對比來看,能耗比方面:ASIC > FPGA > GPU > CPU,產(chǎn)生這樣結(jié)果的根本原因:對于計(jì)算密集型算法,數(shù)據(jù)的搬移和運(yùn)算效率越高的能耗比就越高。ASIC和FPGA都是更接近底層IO,所以計(jì)算效率高和數(shù)據(jù)搬移高,但是FPGA有冗余晶體管和連線,運(yùn)行頻率低,所以沒有ASIC能耗比高。GPU和CPU都是屬于通用處理器,都需要進(jìn)行取指令、指令譯碼、指令執(zhí)行的過程,通過這種方式屏蔽了底層IO的處理,使得軟硬件解耦,但帶來數(shù)據(jù)的搬移和運(yùn)算無法達(dá)到更高效率,所以沒有ASIC、FPGA能耗比高。GPU和CPU之間的能耗比的差距,主要在于CPU中晶體管有大部分用在cache和控制邏輯單元,所以CPU相比GPU來說,對于計(jì)算密集同時(shí)計(jì)算復(fù)雜度低的算法,有冗余的晶體管無法發(fā)揮作用,能耗比上CPU低于GPU。
-
FPGA
+關(guān)注
關(guān)注
1645文章
22050瀏覽量
618423 -
asic
+關(guān)注
關(guān)注
34文章
1246瀏覽量
122392 -
gpu
+關(guān)注
關(guān)注
28文章
4946瀏覽量
131235 -
AI
+關(guān)注
關(guān)注
88文章
35145瀏覽量
279828
原文標(biāo)題:GPU將失寵,明年的AI市場看ASIC
文章出處:【微信號:icbank,微信公眾號:icbank】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
智算加速卡是什么東西?它真能在AI戰(zhàn)場上干掉GPU和TPU!

Imagination與澎峰科技攜手推動(dòng)GPU+AI解決方案,共拓計(jì)算生態(tài)
FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測......
AI推理帶火的ASIC,開發(fā)成敗在此一舉!

ASIC和GPU的原理和優(yōu)勢
NVIDIA和GeForce RTX GPU專為AI時(shí)代打造
英偉達(dá)組建ASIC團(tuán)隊(duì),挖掘臺(tái)灣設(shè)計(jì)服務(wù)人才
GPU是如何訓(xùn)練AI大模型的
ASIC爆火!大廠AI訓(xùn)練推理拋棄GPU;博通的護(hù)城河有多深?
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
ASIC集成電路如何提高系統(tǒng)效率
GPU服務(wù)器AI網(wǎng)絡(luò)架構(gòu)設(shè)計(jì)

FPGA和ASIC在大模型推理加速中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論