 高通量測序常用名詞匯總
高通量測序常用名詞匯總
高通量測序技術是對傳統測序一次革命性的改變,一次對幾十萬到幾百萬條DNA分子進行序列測定,因此在有些文獻中稱其為下一代測序技術(next generation sequencing)足見其劃時代的改變,同時高通量測序使得對一個物種的轉錄組和基因組進行細致全貌的分析成為可能,所以又被稱為深度測序(deep sequencing)。
高通量測序技術的誕生可以說是基因組學研究領域一個具有里程碑意義的事件。該技術使得核酸測序的單堿基成本與第一代測序技術相比急劇下降, 以人類基因組測序為例, 上世紀末進行的人類基因組計劃花費 30 億美元解碼了人類生命密碼, 而第二代測序使得人類基因組測序已進入萬(美)元基因組時代。如此低廉的單堿基測序成本使得我們可以實施更多物種的基因組計劃從而解密更多生物物種的基因組遺傳密碼。同時在已完成基因組序列測定的物種中, 對該物種的其他品種進行大規模地全基因組重測序也成為了可能。
高通量測序領域常用名詞匯總及解釋
什么是高通量測序?
高通量測序技術(High-throughput sequencing,HTS)是對傳統Sanger測序(稱為一代測序技術)革命性的改變, 一次對幾十萬到幾百萬條核酸分子進行序列測定, 因此在有些文獻中稱其為下一代測序技術(next generation sequencing,NGS )足見其劃時代的改變, 同時高通量測序使得對一個物種的轉錄組和基因組進行細致全貌的分析成為可能, 所以又被稱為深度測序(Deep sequencing)。
什么是Sanger法測序(一代測序)
Sanger法測序利用一種DNA聚合酶來延伸結合在待定序列模板上的引物。直到摻入一種鏈終止核苷酸為止。每一次序列測定由一套四個單獨的反應構成,每個反應含有所有四種脫氧核苷酸三磷酸(dNTP),并混入限量的一種不同的雙脫氧核苷三磷酸(ddNTP)。由于ddNTP缺乏延伸所需要的3-OH基團,使延長的寡聚核苷酸選擇性地在G、A、T或C處終止。終止點由反應中相應的雙脫氧而定。每一種dNTPs和ddNTPs的相對濃度可以調整,使反應得到一組長幾百至幾千堿基的鏈終止產物。它們具有共同的起始點,但終止在不同的的核苷酸上,可通過高分辨率變性凝膠電泳分離大小不同的片段,凝膠處理后可用X-光膠片放射自顯影或非同位素標記進行檢測。
什么是基因組重測序(Genome Re-sequencing)
全基因組重測序是對基因組序列已知的個體進行基因組測序,并在個體或群體水平上進行差異性分析的方法。隨著基因組測序成本的不斷降低,人類疾病的致病突變研究由外顯子區域擴大到全基因組范圍。通過構建不同長度的插入片段文庫和短序列、雙末端測序相結合的策略進行高通量測序,實現在全基因組水平上檢測疾病關聯的常見、低頻、甚至是罕見的突變位點,以及結構變異等,具有重大的科研和產業價值。
什么是de novo測序
de novo測序也稱為從頭測序:其不需要任何現有的序列資料就可以對某個物種進行測序,利用生物信息學分析手段對序列進行拼接,組裝,從而獲得該物種的基因組圖譜。獲得一個物種的全基因組序列是加快對此物種了解的重要捷徑。隨著新一代測序技術的飛速發展,基因組測序所需的成本和時間較傳統技術都大大降低,大規模基因組測序漸入佳境,基因組學研究也迎來新的發展契機和革命性突破。利用新一代高通量、高效率測序技術以及強大的生物信息分析能力,可以高效、低成本地測定并分析所有生物的基因組序列。
什么是外顯子測序(whole exon sequencing)
外顯子組測序是指利用序列捕獲技術將全基因組外顯子區域DNA捕捉并富集后進行高通量測序的基因組分析方法。外顯子測序相對于基因組重測序成本較低,對研究已知基因的SNP、Indel等具有較大的優勢,但無法研究基因組結構變異如染色體斷裂重組等。
什么是mRNA測序 (RNA-seq)
轉錄組學(transcriptomics)是在基因組學后新興的一門學科,即研究特定細胞在某一功能狀態下所能轉錄出來的所有RNA(包括mRNA和非編碼RNA)的類型與拷貝數。Illumina提供的mRNA測序技術可在整個mRNA領域進行各種相關研究和新的發現。mRNA測序不對引物或探針進行設計,可自由提供關于轉錄的客觀和權威信息。研究人員僅需要一次試驗即可快速生成完整的poly-A尾的RNA完整序列信息,并分析基因表達、cSNP、全新的轉錄、全新異構體、剪接位點、等位基因特異性表達和罕見轉錄等最全面的轉錄組信息。簡單的樣品制備和數據分析軟件支持在所有物種中的mRNA測序研究。
什么是small RNA測序
Small RNA(micro RNAs、siRNAs和 pi RNAs)是生命活動重要的調控因子,在基因表達調控、生物個體發育、代謝及疾病的發生等生理過程中起著重要的作用。Illumina能夠對細胞或者組織中的全部Small RNA進行深度測序及定量分析等研究。實驗時首先將18-30 nt范圍的Small RNA從總RNA中分離出來,兩端分別加上特定接頭后體外反轉錄做成cDNA再做進一步處理后,利用測序儀對DNA片段進行單向末端直接測序。通過Illumina對Small RNA大規模測序分析,可以從中獲得物種全基因組水平的miRNA圖譜,實現包括新miRNA分子的挖掘,其作用靶基因的預測和鑒定、樣品間差異表達分析、miRNAs聚類和表達譜分析等科學應用。
什么是miRNA測序
成熟的microRNA(miRNA)是17~24nt的單鏈非編碼RNA分子,通過與mRNA相互作用影響目標mRNA的穩定性及翻譯,最終誘導基因沉默,調控著基因表達、細胞生長、發育等生物學過程。基于第二代測序技術的microRNA測序,可以一次性獲得數百萬條microRNA序列,能夠快速鑒定出不同組織、不同發育階段、不同疾病狀態下已知和未知的microRNA及其表達差異,為研究microRNA對細胞進程的作用及其生物學影響提供了有力工具。
什么是Chip-seq
染色質免疫共沉淀技術(ChromatinImmunoprecipitation,ChIP)也稱結合位點分析法,是研究體內蛋白質與DNA相互作用的有力工具,通常用于轉錄因子結合位點或組蛋白特異性修飾位點的研究。將ChIP與第二代測序技術相結合的ChIP-Seq技術,能夠高效地在全基因組范圍內檢測與組蛋白、轉錄因子等互作的DNA區段。
ChIP-Seq的原理是:首先通過染色質免疫共沉淀技術(ChIP)特異性地富集目的蛋白結合的DNA片段,并對其進行純化與文庫構建;然后對富集得到的DNA片段進行高通量測序。研究人員通過將獲得的數百萬條序列標簽精確定位到基因組上,從而獲得全基因組范圍內與組蛋白、轉錄因子等互作的DNA區段信息。
什么是CHIRP-Seq
CHIRP-Seq( Chromatin Isolation by RNA Purification )是一種檢測與RNA綁定的DNA和蛋白的高通量測序方法。方法是通過設計生物素或鏈霉親和素探針,把目標RNA拉下來以后,與其共同作用的DNA染色體片段就會附在到磁珠上,最后把染色體片段做高通量測序,這樣會得到該RNA能夠結合到在基因組的哪些區域,但由于蛋白測序技術不夠成熟,無法知道與該RNA結合的蛋白。
什么是RIP-seq
RNA Immunoprecipitation是研究細胞內RNA與蛋白結合情況的技術,是了解轉錄后調控網絡動態過程的有力工具,能幫助我們發現miRNA的調節靶點。這種技術運用針對目標蛋白的抗體把相應的RNA-蛋白復合物沉淀下來,然后經過分離純化就可以對結合在復合物上的RNA進行測序分析。
RIP可以看成是普遍使用的染色質免疫沉淀ChIP技術的類似應用,但由于研究對象是RNA-蛋白復合物而不是DNA-蛋白復合物,RIP實驗的優化條件與ChIP實驗不太相同(如復合物不需要固定,RIP反應體系中的試劑和抗體絕對不能含有RNA酶,抗體需經RIP實驗驗證等等)。RIP技術下游結合microarray技術被稱為RIP-Chip,幫助我們更高通量地了解癌癥以及其它疾病整體水平的RNA變化。
什么是CLIP-seq
CLIP-seq,又稱為HITS-CLIP,即紫外交聯免疫沉淀結合高通量測序(crosslinking-immunprecipitation and high-throughput sequencing), 是一項在全基因組水平揭示RNA分子與RNA結合蛋白相互作用的革命性技術。其主要原理是基于RNA分子與RNA結合蛋白在紫外照射下發生耦聯,以RNA結合蛋白的特異性抗體將RNA-蛋白質復合體沉淀之后,回收其中的RNA片段,經添加接頭、RT-PCR等步驟,對這些分子進行高通量測序,再經生物信息學的分析和處理、總結,挖掘出其特定規律,從而深入揭示RNA結合蛋白與RNA分子的調控作用及其對生命的意義。
什么是metagenomic(宏基因組):
Magenomics研究的對象是整個微生物群落。相對于傳統單個細菌研究來說,它具有眾多優勢,其中很重要的兩點:(1) 微生物通常是以群落方式共生于某一小生境中,它們的很多特性是基于整個群落環境及個體間的相互影響的,因此做Metagenomics研究比做單個個體的研究更能發現其特性;(2) Metagenomics研究無需分離單個細菌,可以研究那些不能被實驗室分離培養的微生物。
宏基因組是基因組學一個新興的科學研究方向。宏基因組學(又稱元基因組學,環境基因組學,生態基因組學等),是研究直接從環境樣本中提取的基因組遺傳物質的學科。傳統的微生物研究依賴于實驗室培養,元基因組的興起填補了無法在傳統實驗室中培養的微生物研究的空白。過去幾年中,DNA測序技術的進步以及測序通量和分析方法的改進使得人們得以一窺這一未知的基因組科學領域。
什么是SNP、SNV(單核苷酸位點變異)
單核苷酸多態性singlenucleotide polymorphism,SNP 或單核苷酸位點變異SNV。個體間基因組DNA序列同一位置單個核苷酸變異(替代、插入或缺失)所引起的多態性。不同物種、個體基因組DNA序列同一位置上的單個核苷酸存在差別的現象。有這種差別的基因座、DNA序列等可作為基因組作圖的標志。人基因組上平均約每1000個核苷酸即可能出現1個單核苷酸多態性的變化,其中有些單核苷酸多態性可能與疾病有關,但可能大多數與疾病無關。單核苷酸多態性是研究人類家族和動植物品系遺傳變異的重要依據。在研究癌癥基因組變異時,相對于正常組織,癌癥中特異的單核苷酸變異是一種體細胞突變(somatic mutation),稱做SNV。
什么是INDEL (基因組小片段插入)
基因組上小片段(》50bp)的插入或缺失,形同SNP/SNV。
什么是copy number variation (CNV):基因組拷貝數變異
基因組拷貝數變異是基因組變異的一種形式,通常使基因組中大片段的DNA形成非正常的拷貝數量。例如人類正常染色體拷貝數是2,有些染色體區域拷貝數變成1或3,這樣,該區域發生拷貝數缺失或增加,位于該區域內的基因表達量也會受到影響。如果把一條染色體分成A-B-C-D四個區域,則A-B-C-C-D/A-C-B-C-D/A-C-C-B-C-D/A-B-D分別發生了C區域的擴增及缺失,擴增的位置可以是連續擴增如A-B-C-C-D也可以是在其他位置的擴增,如A-C-B-C-D。
什么是structure variation (SV):基因組結構變異
染色體結構變異是指在染色體上發生了大片段的變異。主要包括染色體大片段的插入和缺失(引起CNV的變化),染色體內部的某塊區域發生翻轉顛換,兩條染色體之間發生重組(inter-chromosome trans-location)等。一般SV的展示利用Circos 軟件。
什么是Segment duplication
一般稱為SD區域,串聯重復是由序列相近的一些DNA片段串聯組成。串聯重復在人類基因多樣性的靈長類基因中發揮重要作用。在人類染色體Y和22號染色體上,有很大的SD序列。
什么是genotype and phenotype
既基因型與表型;一般指某些單核苷酸位點變異與表現形式間的關系。
什么是Read?
高通量測序平臺產生的序列標簽就稱為reads。
什么是soft-clipped reads
當基因組發生某一段的缺失,或轉錄組的剪接,在測序過程中,橫跨缺失位點及剪接位點的reads回帖到基因組時,一條reads被切成兩段,匹配到不同的區域,這樣的reads叫做soft-clipped reads,這些reads對于鑒定染色體結構變異及外源序列整合具有重要作用。
什么是multi-hits reads
由于大部分測序得到的reads較短,一個reads能夠匹配到基因組多個位置,無法區分其真實來源的位置。一些工具根據統計模型,如將這類reads分配給reads較多的區域。
什么是Contig?
拼接軟件基于reads之間的overlap區,拼接獲得的序列稱為Contig(重疊群)。
什么是Scaffold?
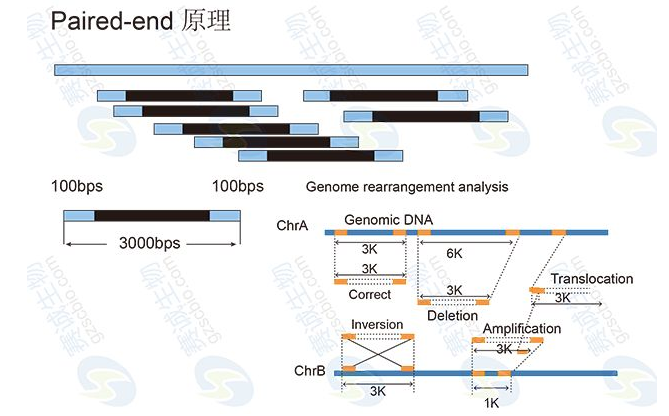
基因組de novo測序,通過reads拼接獲得Contigs后,往往還需要構建454 Paired-end庫或Illumina Mate-pair庫,以獲得一定大小片段(如3Kb、6Kb、10Kb、20Kb)兩端的序列。基于這些序列,可以確定一些Contig之間的順序關系,這些先后順序已知的Contigs組成Scaffold。
什么是Contig N50?
Reads拼接后會獲得一些不同長度的Contigs。將所有的Contig長度相加,能獲得一個Contig總長度。然后將所有的Contigs按照從長到短進行排序,如獲得Contig 1,Contig 2,Contig 3.。。………Contig 25。將Contig按照這個順序依次相加,當相加的長度達到Contig總長度的一半時,最后一個加上的Contig長度即為Contig N50。舉例:Contig 1+Contig 2+ Contig 3+Contig 4=Contig總長度*1/2時,Contig 4的長度即為Contig N50。Contig N50可以作為基因組拼接的結果好壞的一個判斷標準。
什么是Scaffold N50?
Scaffold N50與Contig N50的定義類似。Contigs拼接組裝獲得一些不同長度的Scaffolds。將所有的Scaffold長度相加,能獲得一個Scaffold總長度。然后將所有的Scaffolds按照從長到短進行排序,如獲得Scaffold 1,Scaffold 2,Scaffold 3.。。………Scaffold 25。將Scaffold按照這個順序依次相加,當相加的長度達到Scaffold總長度的一半時,最后一個加上的Scaffold長度即為Scaffold N50。舉例:Scaffold 1+Scaffold 2+ Scaffold 3 +Scaffold 4 +Scaffold 5=Scaffold總長度*1/2時,Scaffold 5的長度即為Scaffold N50。Scaffold N50可以作為基因組拼接的結果好壞的一個判斷標準。
什么是測序深度和覆蓋度?
測序深度是指測序得到的總堿基數與待測基因組大小的比值。假設一個基因大小為2M,測序深度為10X,那么獲得的總數據量為20M。覆蓋度是指測序獲得的序列占整個基因組的比例。由于基因組中的高GC、重復序列等復雜結構的存在,測序最終拼接組裝獲得的序列往往無法覆蓋有所的區域,這部分沒有獲得的區域就稱為Gap。例如一個細菌基因組測序,覆蓋度是98%,那么還有2%的序列區域是沒有通過測序獲得的。
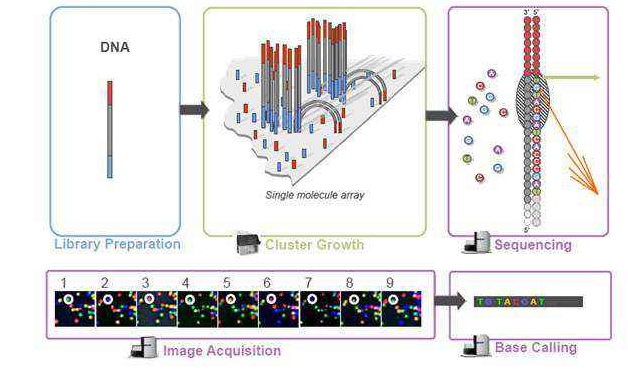
什么是RPKM、FPKM
RPKM,Reads Per Kilobase of exon model per Million mapped reads, is defined in thisway [Mortazavi etal., 2008]:
每1百萬個map上的reads中map到外顯子的每1K個堿基上的reads個數。
假如有1百萬個reads映射到了人的基因組上,那么具體到每個外顯子呢,有多少映射上了呢,而外顯子的長度不一,那么每1K個堿基上又有多少reads映射上了呢,這大概就是這個RPKM的直觀解釋。
如果對應特定基因的話,那么就是每1000000 mapped到該基因上的reads中每kb有多少是mapped到該基因上的exon的read
Total exon reads:This is the number in the column with header Total exonreads in the row for the gene. This is the number of reads that have beenmapped to a region in which an exon is annotated for the gene or across theboundaries of two exons or an intron and an exon for an annotated transcript ofthe gene. For eukaryotes, exons and their internal relationships are defined byannotations of type mRNA.映射到外顯子上總的reads個數。這個是映射到某個區域上的reads個數,這個區域或者是已知注釋的基因或者跨兩個外顯子的邊界或者是某個基因已經注釋的轉錄本的內含子、外顯子。對于真核生物來說,外顯子和它們自己內部的關系由某類型的mRNA來注釋。
Exonlength: This is the number in the column with the header Exon length inthe row for the gene, divided by 1000. This is calculated as the sum of thelengths of all exons annotated for the gene. Each exon is included only once inthis sum, even if it is present in more annotated transcripts for the gene.Partly overlapping exons will count with their full length, even though theyshare the same region.外顯子的長度。計算時,計算所有某個基因已注釋的所有外顯子長度的總和。即使某個基因以多種注釋的轉錄本呈現,這個外顯子在求和時只被包含一次。即使部分重疊的外顯子共享相同的區域,重疊的外顯子以其總長來計算。
Mapped reads: The sum of all the numbers in the column with header Totalgene reads. The Total gene reads for a gene is the total number ofreads that after mapping have been mapped to the region of the gene. Thus thisincludes all the reads uniquely mapped to the region of the gene as well asthose of the reads which match in more places (below the limit set in thedialog in figure18.110) that have been allocated tothis gene‘s region. A gene’s region is that comprised of the flanking regions(if it was specified in figure 18.110), the exons, the introns andacross exon-exon boundaries of all transcripts annotated for the gene. Thus,the sum of the total gene reads numbers is the number of mapped reads for thesample (you can find the number in the RNA-Seq report).map的reads總和。映射到某個基因上的所有reads總數。因此這包含所有的唯一映射到這個區域上的reads。
舉例:比如對應到該基因的read有1000個,總reads個數有100萬,而該基因的外顯子總長為5kb,那么它的RPKM為:10^9*1000(reads個數)/10^6(總reads個數)*5000(外顯子長度)=200或者:1000(reads個數)/1(百萬)*5(K)=200這個值反映基因的表達水平。
FPKM(fragments per kilobase of exon per million fragments mapped)。 FPKM與RPKM計算方法基本一致。不同點就是FPKM計算的是fragments,而RPKM計算的是reads。Fragment比read的含義更廣,因此FPKM包含的意義也更廣,可以是pair-end的一個fragment,也可以是一個read。
什么是轉錄本重構
用測序的數據組裝成轉錄本。有兩種組裝方式:1,de-novo構建; 2,有參考基因組重構。其中de-novo組裝是指在不依賴參考基因組的情況下,將有overlap的reads連接成一個更長的序列,經過不斷的延伸,拼成一個個的contig及scaffold。常用工具包括velvet,trans-ABYSS,Trinity等。有參考基因組重構,是指先將read貼回到基因組上,然后在基因組通過reads覆蓋度,junction位點的信息等得到轉錄本,常用工具包括scripture、cufflinks。
什么是genefusion
將基因組位置不同的兩個基因中的一部分或全部整合到一起,形成新的基因,稱作融合基因,或嵌合體基因。該基因有可能翻譯出融合或嵌合體蛋白。
什么是表達譜
基因表達譜(geneexpression profile):指通過構建處于某一特定狀態下的細胞或組織的非偏性cDNA文庫,大規模cDNA測序,收集cDNA序列片段、定性、定量分析其mRNA群體組成,從而描繪該特定細胞或組織在特定狀態下的基因表達種類和豐度信息,這樣編制成的數據表就稱為基因表達譜
什么是功能基因組學
功能基因組學(Functuionalgenomics)又往往被稱為后基因組學(Postgenomics),它利用結構基因組所提供的信息和產物,發展和應用新的實驗手段,通過在基因組或系統水平上全面分析基因的功能,使得生物學研究從對單一基因或蛋白質得研究轉向多個基因或蛋白質同時進行系統的研究。這是在基因組靜態的堿基序列弄清楚之后轉入對基因組動態的生物學功能學研究。研究內容包括基因功能發現、基因表達分析及突變檢測。基因的功能包括:生物學功能,如作為蛋白質激酶對特異蛋白質進行磷酸化修飾;細胞學功能,如參與細胞間和細胞內信號傳遞途徑;發育上功能,如參與形態建成等。采用的手段包括經典的減法雜交,差示篩選,cDNA代表差異分析以及mRNA差異顯示等,但這些技術不能對基因進行全面系統的分析,新的技術應運而生,包括基因表達的系統分析(serial analysis of gene expression,SAGE),cDNA微陣列(cDNA microarray),DNA 芯片(DNA chip)和序列標志片段顯示(sequence tagged fragmentsdisplay。
什么是比較基因組學
比較基因組學(ComparativeGenomics)是基于基因組圖譜和測序基礎上,對已知的基因和基因組結構進行比較,來了解基因的功能、表達機理和物種進化的學科。利用模式生物基因組與人類基因組之間編碼順序上和結構上的同源性,克隆人類疾病基因,揭示基因功能和疾病分子機制,闡明物種進化關系,及基因組的內在結構。
什么是表觀遺傳學
表觀遺傳學是研究基因的核苷酸序列不發生改變的情況下,基因表達了可遺傳的變化的一門遺傳學分支學科。表觀遺傳的現象很多,已知的有DNA甲基化(DNAmethylation),基因組印記(genomicimpriting),母體效應(maternaleffects),基因沉默(genesilencing),核仁顯性,休眠轉座子激活和RNA編輯(RNA editing)等。
什么是計算生物學
計算生物學是指開發和應用數據分析及理論的方法、數學建模、計算機仿真技術等。當前,生物學數據量和復雜性不斷增長,每14個月基因研究產生的數據就會翻一番,單單依靠觀察和實驗已難以應付。因此,必須依靠大規模計算模擬技術,從海量信息中提取最有用的數據。
什么是基因組印記
基因組印記(又稱遺傳印記)是指基因根據親代的不同而有不同的表達。印記基因的存在能導致細胞中兩個等位基因的一個表達而另一個不表達。基因組印記是一正常過程,此現象在一些低等動物和植物中已發現多年。印記的基因只占人類基因組中的少數,可能不超過5%,但在胎兒的生長和行為發育中起著至關重要的作用。基因組印記病主要表現為過度生長、生長遲緩、智力障礙、行為異常。目前在腫瘤的研究中認為印記缺失是引起腫瘤最常見的遺傳學因素之一。
什么是基因組學
基因組學(英文genomics),研究生物基因組和如何利用基因的一門學問。用于概括涉及基因作圖、測序和整個基因組功能分析的遺傳學分支。該學科提供基因組信息以及相關數據系統利用,試圖解決生物,醫學,和工業領域的重大問題。
什么是DNA甲基化
DNA甲基化是指在DNA甲基化轉移酶的作用下,在基因組CpG二核苷酸的胞嘧啶5‘碳位共價鍵結合一個甲基基團。正常情況下,人類基因組“垃圾”序列的CpG二核苷酸相對稀少,并且總是處于甲基化狀態,與之相反,人類基因組中大小為100—1000 bp左右且富含CpG二核苷酸的CpG島則總是處于未甲基化狀態,并且與56%的人類基因組編碼基因相關。人類基因組序列草圖分析結果表明,人類基因組CpG島約為28890個,大部分染色體每1 Mb就有5—15個CpG島,平均值為每Mb含10.5個CpG島,CpG島的數目與基因密度有良好的對應關系[9]。由于DNA甲基化與人類發育和腫瘤疾病的密切關系,特別是CpG島甲基化所致抑癌基因轉錄失活問題,DNA甲基化已經成為表觀遺傳學和表觀基因組學的重要研究內容。
什么是基因組注釋
基因組注釋(Genomeannotation) 是利用生物信息學方法和工具,對基因組所有基因的生物學功能進行高通量注釋,是當前功能基因組學研究的一個熱點。基因組注釋的研究內容包括基因識別和基因功能注釋兩個方面。基因識別的核心是確定全基因組序列中所有基因的確切位置。
發布評論請先 登錄
高通量測序數據分析:RNA-seq 精選資料分享
全基因組測序的優勢 精選資料分享
常用電工名詞的定義
研究首次實現高通量小RNA芯片非標記檢測
高通量測序技術及原理介紹
高通量測序技術及其應用
高通量測序生物信息學分析
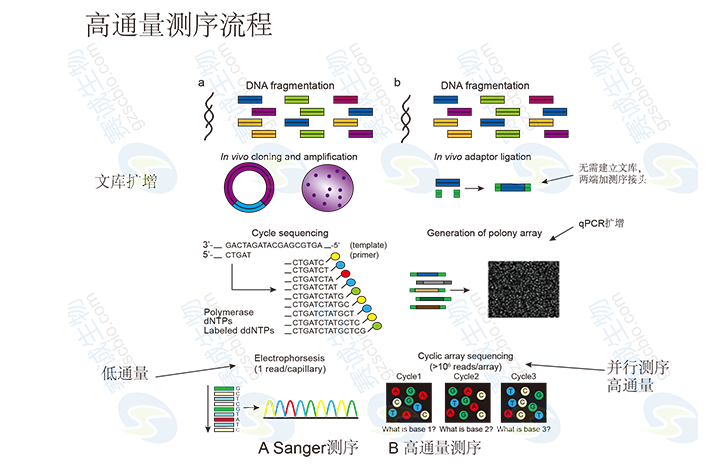
高通量測序面臨的5大挑戰





 工商網監
工商網監
評論