") 墨芯S40計(jì)算卡實(shí)現(xiàn)DeepSeek大模型部署
墨芯S40計(jì)算卡實(shí)現(xiàn)DeepSeek大模型部署
近期,“國(guó)產(chǎn)之光”DeepSeek系列大模型發(fā)展迅猛,領(lǐng)跑開(kāi)源大模型技術(shù)與生態(tài),為中國(guó)人工智能行業(yè)帶來(lái)了前所未有的變革動(dòng)力,對(duì)全球科技競(jìng)爭(zhēng)格局產(chǎn)生積極影響。
1稀疏計(jì)算
助力DeepSeek R1模型高效部署
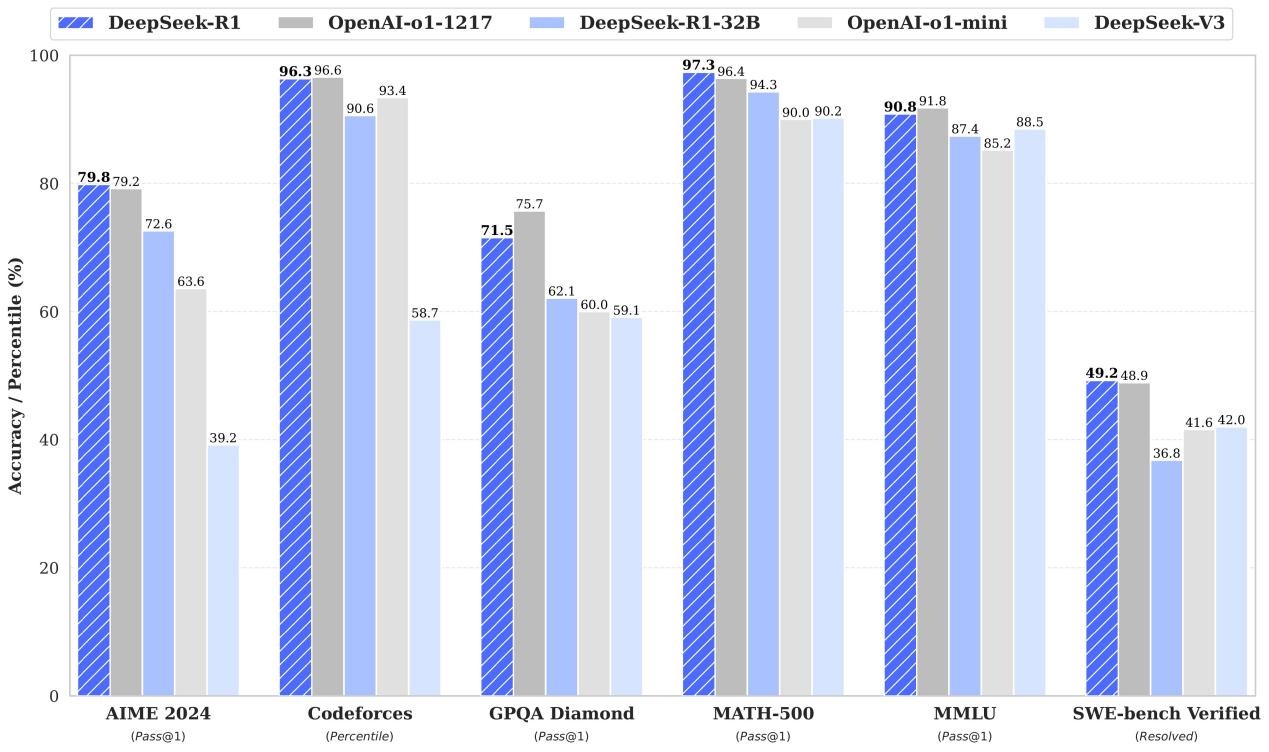
日前,墨芯人工智能(Moffett AI)已完成與DeepSeek R1全系列蒸餾模型的推理部署。憑借自研的雙稀疏算法技術(shù),墨芯S40計(jì)算卡性能得到充分釋放,為DeepSeek R1的高效部署提供了強(qiáng)勁的算力后盾,并在較短時(shí)間內(nèi)完成DeepSeek-R1-70B* 和DeepSeek-R1-32B* 等中、大模型部署,且成功實(shí)現(xiàn)單卡支持DeepSeek-R1-32B*部署。
墨芯S40計(jì)算卡支持DeepSeek R1-70B和DeepSeek R1-32B推理部署
2軟硬件協(xié)同
提升DeepSeek R1模型推理效率
DeepSeek-R1蒸餾模型是DeepSeek在模型壓縮與優(yōu)化領(lǐng)域的重要?jiǎng)?chuàng)新,通過(guò)蒸餾技術(shù)實(shí)現(xiàn)了高效、低成本的AI推理,適合企業(yè)內(nèi)部實(shí)施部署,實(shí)現(xiàn)降本增效。
DeepSeek-R1-70B* 和DeepSeek-R1-32B*是DeepSeek-R1蒸餾模型的中大規(guī)模和大規(guī)模模型。DeepSeek-R1-32B*推理速度較快,實(shí)時(shí)性要求高的場(chǎng)景,擅長(zhǎng)處理日常對(duì)話(huà)、文檔生成和基礎(chǔ)代碼輔助;DeepSeek-R1-70B*側(cè)重復(fù)雜邏輯推理、科研分析、高質(zhì)量?jī)?nèi)容創(chuàng)作。
墨芯的稀疏計(jì)算技術(shù)則是通過(guò)算法與硬件的協(xié)同設(shè)計(jì),有效地減少蒸餾模型部署所需的資源,其中稀疏化技術(shù)將模型中的稠密張量轉(zhuǎn)換為等效的稀疏張量,使張量中產(chǎn)生大量的零元素,通過(guò)剪枝,有效消減模型冗余,以顯著加快計(jì)算速度,實(shí)現(xiàn)了大模型的高效稀疏化,顯著提升DeepSeek-R1系列蒸餾模型的推理速度并降低能耗。
此外,相較于傳統(tǒng)推理平臺(tái),墨芯S40算力卡能夠?qū)崿F(xiàn)“單卡推理大模型”,簡(jiǎn)化了多卡分布式處理大模型的復(fù)雜部署流程,降低了時(shí)間、功耗和成本。這一優(yōu)勢(shì)在DeepSeek-R1蒸餾模型的部署中得到了充分體現(xiàn),墨芯的S40計(jì)算卡滿(mǎn)足了高算力需求,降低了總擁有成本(TCO),為 AI大模型在各行業(yè)的應(yīng)用提供了支持。
墨芯人工智能與DeepSeek-R1蒸餾模型的成功部署,實(shí)現(xiàn)了國(guó)產(chǎn)AI算力基座和國(guó)產(chǎn)大模型在應(yīng)用層面的“雙向奔赴”,展示了稀疏計(jì)算技術(shù)在大模型領(lǐng)域的實(shí)踐成果,也為企業(yè)部署“高性能”且“用得起”的大模型提供新思路。
備注:
DeepSeek-R1-70B*:指DeepSeek-R1-Distill-Llama-70B模型
DeepSeek-R1-32B*:指DeepSeek-R1-Distill-Qwen-32B模型
關(guān)于墨芯人工智能
墨芯人工智能是稀疏計(jì)算引領(lǐng)者,致力于提供云端和終端AI計(jì)算平臺(tái)和服務(wù)。通過(guò)全球領(lǐng)先的稀疏計(jì)算技術(shù)優(yōu)勢(shì),打造軟硬協(xié)同的新一代智能計(jì)算平臺(tái)。產(chǎn)品性能位居行業(yè)領(lǐng)先,相較行業(yè)主流產(chǎn)品,在算力、能效比與成本等方面均實(shí)現(xiàn)數(shù)量級(jí)優(yōu)化。面向互聯(lián)網(wǎng)、運(yùn)營(yíng)商、金融、制造、醫(yī)療、交通、能源、生命科學(xué)、自動(dòng)駕駛等眾多行業(yè)與場(chǎng)景,提供高算力、低功耗、高性?xún)r(jià)比的AI算力服務(wù),賦能前沿科技的進(jìn)步與社會(huì)的智能化升級(jí)。
-
墨芯
+關(guān)注
關(guān)注
0文章
11瀏覽量
1143 -
大模型
+關(guān)注
關(guān)注
2文章
3046瀏覽量
3869 -
DeepSeek
+關(guān)注
關(guān)注
1文章
783瀏覽量
1435
原文標(biāo)題:墨芯S40計(jì)算卡完成DeepSeek大模型部署, 支持單卡推理大模型
文章出處:【微信號(hào):墨芯人工智能,微信公眾號(hào):墨芯人工智能】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【幸狐Omni3576邊緣計(jì)算套件試用體驗(yàn)】CPU部署DeekSeek-R1模型(1B和7B)
DeepSeek在昇騰上的模型部署的常見(jiàn)問(wèn)題及解決方案
【幸狐Omni3576邊緣計(jì)算套件試用體驗(yàn)】DeepSeek 部署及測(cè)試
RK3588開(kāi)發(fā)板上部署DeepSeek-R1大模型的完整指南
兆芯全面部署DeepSeek R1大模型
行芯完成DeepSeek-R1大模型本地化部署
摩爾線(xiàn)程圖形顯卡MTT S80實(shí)現(xiàn)DeepSeek模型部署
紹興數(shù)據(jù)局率先實(shí)現(xiàn)政務(wù)環(huán)境下的DeepSeek模型部署

研華發(fā)布昇騰AI Box及Deepseek R1模型部署流程
添越智創(chuàng)基于 RK3588 開(kāi)發(fā)板部署測(cè)試 DeepSeek 模型全攻略
研華邊緣AI Box MIC-ATL3S部署Deepseek R1模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論