") GPU 性能原理拆解
GPU 性能原理拆解

「迷思」是指經(jīng)由人們口口相傳,但又難以證明證偽的現(xiàn)象。由于 GPU 硬件實(shí)現(xiàn)、驅(qū)動(dòng)實(shí)現(xiàn)是一個(gè)黑盒,我們只能通過(guò)廠商提供的 API、經(jīng)過(guò)抽象的架構(gòu)來(lái)了解并猜測(cè)其原理。因此坊間流傳著各種關(guān)于與 GPU 打交道時(shí)的性能迷思。比如「移動(dòng)端的瓶頸是帶寬」、「移動(dòng)端不需要太在意 Overdraw」、「植被需要做 PrePass」等等。這些優(yōu)化手段,有時(shí)候我們對(duì)后面的原理一知半解,有時(shí)候又會(huì)隨著硬件的發(fā)展而逐漸變得不適用,逐漸會(huì)變成一種神秘主義。
作者:mobiuschen
我希望可以結(jié)合一些現(xiàn)有資料,對(duì)這些「迷思」做定性的分析,避免一不小心變成了負(fù)優(yōu)化。有條件時(shí),甚至希望可以做一些定量分析的實(shí)驗(yàn)。
移動(dòng)端架構(gòu)
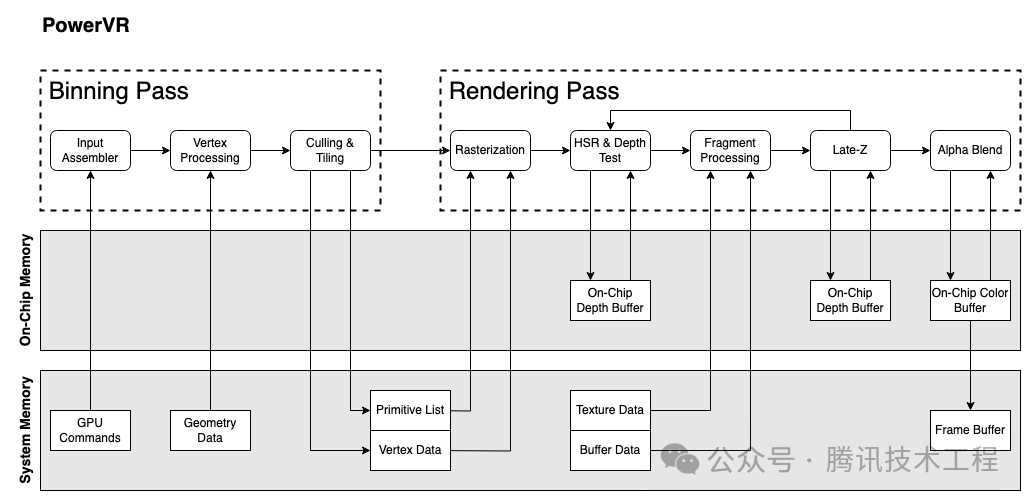
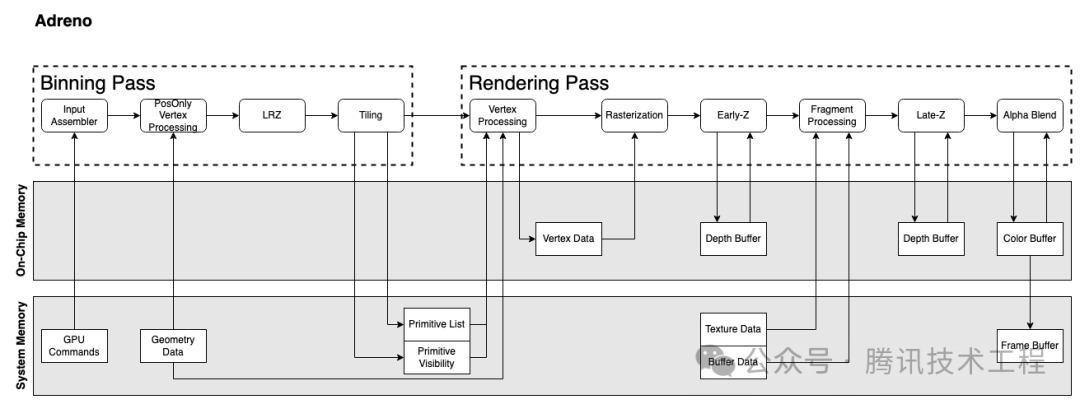
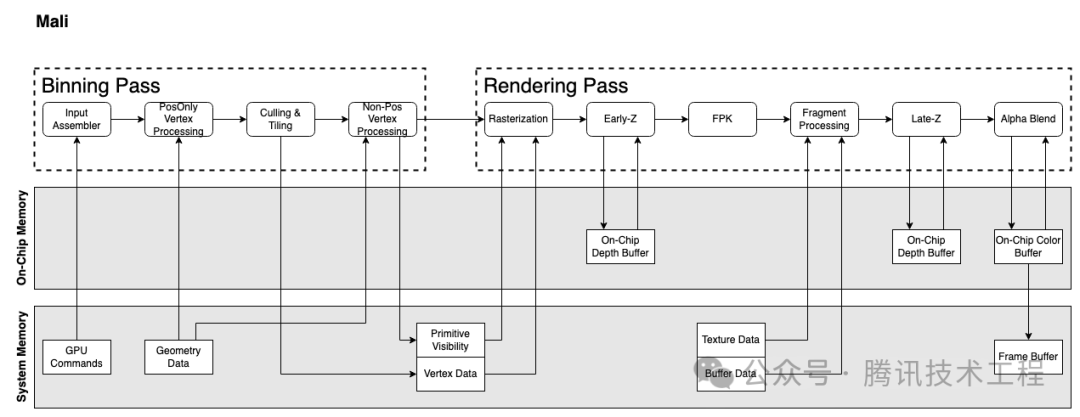
我們先簡(jiǎn)單過(guò)一下幾個(gè)廠商的 GPU 架構(gòu)。蘋果的 GPU 架構(gòu)查不到任何文檔,只能姑且以多年前 PowerVR 的架構(gòu)文檔來(lái)替代。移動(dòng)端的 GPU 現(xiàn)在都是 TBDR 架構(gòu),分為兩個(gè) Pass:Binning Pass 和 Rendering Pass。Binning Pass 將各個(gè) Primitive 分到各個(gè) Tile,Rendering pass 再在對(duì)這些 tile 進(jìn)行渲染。
講 GPU 結(jié)構(gòu)的資料還是比較多,這里不再贅述。我們只著重講幾點(diǎn)不同架構(gòu)上有差異、與后面「迷思」相關(guān)的功能點(diǎn)。
隱面剔除
「隱面剔除」技術(shù)這一術(shù)語(yǔ)來(lái)自于 PowerVR 的 HSR (Hidden Surface Removal),通常用來(lái)指代 GPU 對(duì)最終被遮擋的 Primitive/Fragment 做剔除,避免執(zhí)行其 PS,以達(dá)到減少 Overdraw 的效果。
Adreno/Mali/PowerVR 三家在處理隱面剔除除的方式是不一樣的。
PowerVR 的 HSR 原理是生成一個(gè) visibility buffer,記錄了每一個(gè) pixel 的深度,用于對(duì) fragment 做像素級(jí)的剔除。因?yàn)槭侵鹣袼丶?jí)的剔除,因此需要放到 Rasterization 之后,也就是說(shuō)每個(gè)三角形都需要做 Rasterization。根據(jù) visibility buffer 來(lái)決定每一個(gè)像素執(zhí)行哪個(gè) fragment 的 ps。也因此,PowerVR 將自己 TBR (Tile Based Rendering) 稱為 TBDR (Tile Based Deferred Rendering)。而且特別提到了一點(diǎn),如果當(dāng)出現(xiàn)一個(gè) fragment 的深度無(wú)法在 vs 階段就確定,那么就會(huì)等到 fragment 的 ps 執(zhí)行完,確定了深度,再來(lái)填充對(duì)應(yīng)的 visibility buffer。也就是說(shuō)這個(gè) fragment 會(huì)阻塞了 visibility buffer 的生成。這個(gè)架構(gòu)來(lái)自于 PowerVR 2015年左右的文檔,后續(xù) Apple 繼承了其架構(gòu),但是后面是否有做更進(jìn)一步的架構(gòu)優(yōu)化不得而知。
Adreno 實(shí)現(xiàn)隱面剔除技術(shù)的流程稱為 LRZ (Low Resolution Depth),其剔除的顆粒度是 Primitive 而不是 Fragment。在 Binning pass 階段執(zhí)行 Position-Only VS 時(shí)的會(huì)生成一張 LRZ buffer (低分辨率的 z buffer),將三角形的最小深度與 z buffer 做對(duì)比,以此判斷三角形的可見(jiàn)性。Binning pass 之后,將可見(jiàn)的 triangle list 存入 SYSMEM,在 render pass 中再根據(jù) triangle list 來(lái)繪制。相比于 PowerVR 的 HSR,LRZ 由于是 binning pass 做的,可以減少 Rasterization 的開(kāi)銷。并且在 render pass 中,也會(huì)有 early-z stage 來(lái)做 fragment 級(jí)別的剔除。對(duì)于那種需要在 ps 階段才能決定深度的 fragment,就會(huì)跳過(guò) LRZ,但是并不會(huì)阻塞管線。
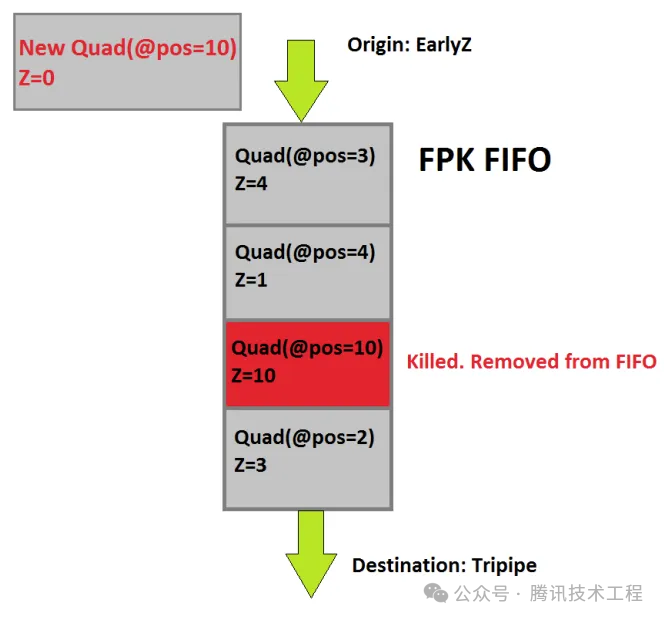
Mali 實(shí)現(xiàn)隱面剔除的技術(shù)稱為 FPK (Forward Pixel Killing)。其原理是所有經(jīng)過(guò) Early-Z 之后的 Quad,都會(huì)放入一個(gè) FIFO 隊(duì)列中,記錄其位置與深度,等待執(zhí)行。如果在執(zhí)行完之前,隊(duì)列中新進(jìn)來(lái)一個(gè) Quad A,位置與現(xiàn)隊(duì)列中的某個(gè) Quad B 相同,但是 A 深度更小,那么隊(duì)列中的 B 就會(huì)被 kill 掉,不再執(zhí)行。Early-Z 只可以根據(jù)歷史數(shù)據(jù),剔除掉當(dāng)前的 Quad。而 FPK 可以使用當(dāng)前的 Quad,在一定程度上剔除掉老的 Quad。FPK 與 HSR 類似,但是區(qū)別是 HSR 是阻塞性的,只有只有完全生成 visibility buffer 之后,才會(huì)執(zhí)行 PS。但 FPK 不會(huì)阻塞,只會(huì)kill 掉還沒(méi)來(lái)得及執(zhí)行或者執(zhí)行到一半的 PS。
Vertex Shader 的執(zhí)行
PowerVR 下,VS 是在 Binning Pass 階段執(zhí)行的,只會(huì)執(zhí)行一次。
Adreno 和 Mali 都是會(huì)執(zhí)行兩次 VS。第一次都是 "PosOnly Vertex Processing",就是只執(zhí)行 VS 中產(chǎn)出 position 相關(guān)的指令,只算出 Position 信息給 Binning 階段使用。
第二次 VS 的執(zhí)行,Mali 是在 binning 階段,稱為 "Varying Shading",只執(zhí)行非 Position 的那部分邏輯。而 Adreno 的第二次 VS 的執(zhí)行會(huì)放到 rendering 階段,并且是執(zhí)行全量的 VS。
為什么有這個(gè)區(qū)別呢?下個(gè)點(diǎn) "VS Output" 會(huì)講到。
VS Output
VS 階段產(chǎn)出的數(shù)據(jù)稱為 VS Output,或者稱為 Post-VS Attributes。對(duì)這些數(shù)據(jù)的處理,不同架構(gòu)也不大一樣。
PowerVR,Binning Pass 階段就已經(jīng)執(zhí)行了全量的 VS,然后會(huì)將 VS Output 寫到 system memory。在 Rendering Pass 再重新讀回來(lái)。
Adreno 架構(gòu)下,Binning Pass 之后只產(chǎn)出兩種數(shù)據(jù)并會(huì)將其寫到 system memory:Primitive List 和 Primitive Visibility。在 Rendering Pass 會(huì)重新執(zhí)行一遍 VS,產(chǎn)出 VS Output。這些數(shù)據(jù)不回寫回 system memory,而是存在 On-Chip Memory (LocalBuffer),PS 階段直接可以從 Local Buffer 讀取。
這樣就節(jié)省了很多的帶寬消耗。
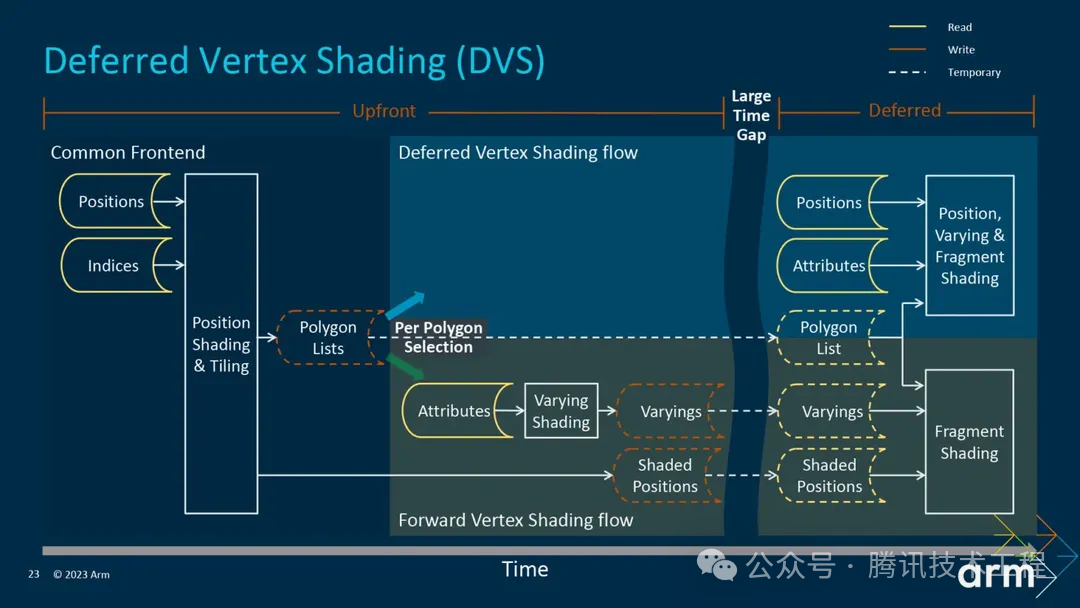
Mali 在第五代 GPU 架構(gòu) Immortalis 之前,第二遍 VS 會(huì)在 Binning Pass 執(zhí)行完,并且把 VS Output 都寫入 system memory,在 rendering pass 重新讀出來(lái)。這樣就會(huì)有帶寬的消耗。于是第五代架構(gòu)推出了 Deferred Vertex Shading (DVS),就是將 Varying Shading 延遲到 rendering 階段再執(zhí)行,這樣就直接可以把數(shù)據(jù)存到 On-Chip Memory 給后面的 PS 使用,達(dá)到節(jié)省帶寬的目的。
號(hào)稱可以節(jié)省 20% -40% 的帶寬。
移動(dòng)端帶寬是瓶頸
帶寬就是單位時(shí)間內(nèi)數(shù)據(jù)的傳輸量,其量化標(biāo)準(zhǔn)為「位寬 (bit wide) * 頻率」。在位寬確定的情況下,只能通過(guò)增加工作頻率來(lái)提高帶寬。更高的頻率意味著需要更高的電壓,進(jìn)而造成更高的功耗。功率 (P) 與電壓 (V) 的關(guān)系 ,也就是說(shuō)功耗與電壓平方成正比。
「在移動(dòng)端帶寬是瓶頸」,源自于兩方面:
- 帶寬的發(fā)展與算力的發(fā)展不匹配
- 帶寬的增加帶來(lái)了大功耗
下面這張圖對(duì)比了算力、內(nèi)存帶寬、內(nèi)部帶寬的發(fā)展,可以看到 20 年間,硬件算力提升了 60000 倍,內(nèi)存帶寬提升了 100 倍,而內(nèi)部帶寬只提升了 30 倍。公路寬度提升了幾十倍,車流量卻變成了幾萬(wàn)倍,當(dāng)然公路的寬度就變成了瓶頸了。
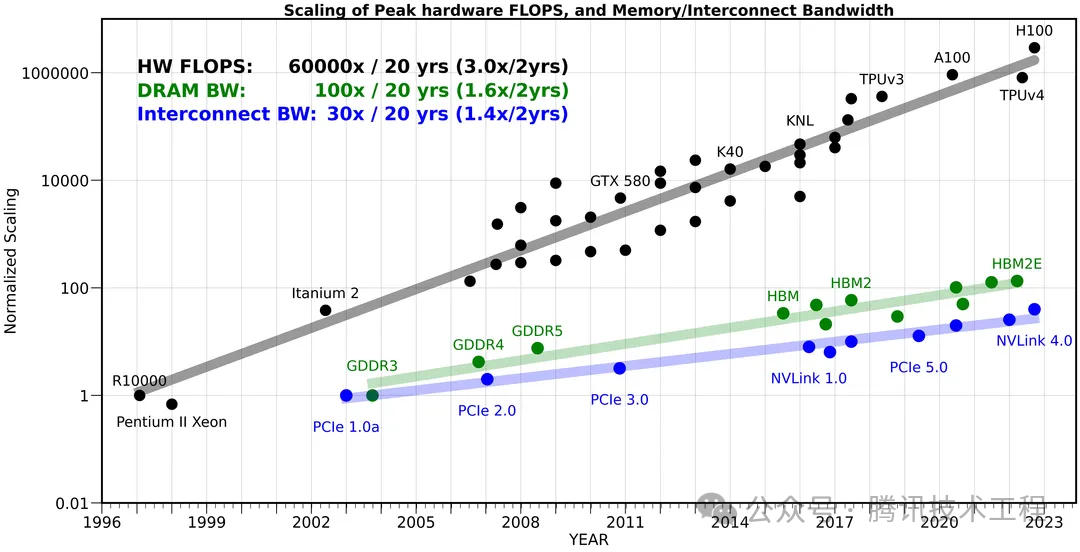
這個(gè)問(wèn)題在移動(dòng)端變得更加嚴(yán)重。因?yàn)樵谝苿?dòng)端,芯片面積有限,位寬無(wú)法做得很大。在手機(jī)上,內(nèi)存位寬一般是 64-bit wide 或者 128-bit wide;而桌面端可以是 1024-bit wide,甚至搭配了 HBM (High Bandwidth Memory) 的顯卡可以到 4096-bit wide。更高的位寬意味更高的面積和成本。因此,手機(jī)上只能通過(guò)提高電壓來(lái)增加帶寬。按照前面的公式,功率 (P) 與電壓 (V) 的平方成正比。電壓的增加指數(shù)級(jí)地增加了手機(jī)的功耗。所以我們經(jīng)常說(shuō)「手機(jī)功耗的大頭就是帶寬」。
不要在 Shader 中使用分支
這是一個(gè)經(jīng)典的迷思:「不要在 Shader 中使用分支,使用了之后相當(dāng)于 Shader 需要在分支兩邊各執(zhí)行一遍」。
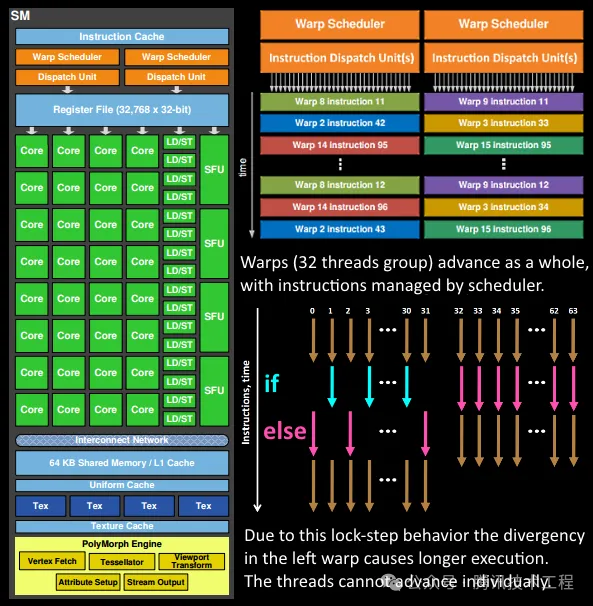
這個(gè)說(shuō)法是基于 GPU SP 并行執(zhí)行的原理。SP 在執(zhí)行時(shí),是使用 lockstep 的方式執(zhí)行同一個(gè) wave (或者 warp) 中的所有 fiber (或者 thread)的。也就是說(shuō),使用 SIMD 的指令,在一個(gè) cycle 內(nèi)同時(shí)執(zhí)行所有的 fiber 相同指令。每一個(gè) fiber 都是同時(shí)往前步進(jìn)的。SP 有個(gè) Mask 的功能,可以在執(zhí)行時(shí)屏蔽某些 fiber。這個(gè)功能就是用來(lái)處理分支的。當(dāng)遇到分支時(shí),先 mask 掉應(yīng)該走 false 的 fiber,執(zhí)行 true 的分支;再 mask 掉應(yīng)該走 true 的 fiber,執(zhí)行 false 的分支。這也就是前面說(shuō)到的,需要 shader 在分支兩邊各執(zhí)行一遍。
這個(gè)功能稱為 "Divergency",不止用在了處理邏輯分支,還用于處理很多其他功能。比如后面會(huì)說(shuō)到的 quad overdraw。
但是,分支條件分為幾種情況:
- 常量條件:這種在編譯時(shí)就會(huì)被優(yōu)化掉,是不會(huì)產(chǎn)生分支的。
- Uniform 作為條件:如果同個(gè) wave 中的所有 fiber 都是走同一個(gè)條件分支,理應(yīng)也是不會(huì)產(chǎn)生分支的。
- 運(yùn)行時(shí)的變量決定:這種產(chǎn)生對(duì)于性能的影響是最大的
第二點(diǎn)是容易被忽略的
另外,不同的 GPU 架構(gòu)對(duì)于 divergency 的性能敏感程度是不同的。從原理上我們可以猜到,每個(gè) wave 中的 fiber 數(shù)量越多,divergency 的代價(jià)就越大。Adreno 中每個(gè) wave 中 fiber 數(shù)量較多,因此收 Divergency 影響會(huì)更大。
在 Snapdragon Profiler 中,通過(guò)這兩個(gè)指標(biāo)來(lái)觀察 Divergency 的情況:% Shader ALU Capacity Utilized 、 % Time ALUs Working。
下面是這倆指標(biāo)的含義:
% Shader ALU Capacity Utilized:重要指標(biāo)。當(dāng)存在 Divergence 時(shí),此 Metrics 會(huì)小于 "% Time ALUs Working". 比如 % Time ALUs Working" 為 50%, "% Shader ALU Capacity Utilized" 為 25%,那么意味著一半的 fibers 不工作 (masked due to divergence, or triangle coverage)。
% Time ALUs Working. SP busy 的 Cycles 里,多少比例的 Cycle ALU Engine is Working。一個(gè) Wave 即使只有一個(gè) fiber active,這個(gè) Metrics 也加一。這點(diǎn)與 Fragment ALU Instructions Full/Half 不同。
也就是說(shuō),Divergence 的比例 = % Time ALUs Working - % Shader ALU Capacity Utilized
移動(dòng)端不需要太關(guān)注 Overdraw
"Overdraw" 字面意思就是「畫多了」,做多了不必要的工作。通常我們說(shuō)的 overdraw 是指多個(gè)三角形重疊,先畫遠(yuǎn)處再畫近處,遠(yuǎn)的像素就會(huì)被拋棄掉,那么遠(yuǎn)的像素這部分的 PS 就被浪費(fèi)了。
在目前的 TBDR 架構(gòu)中,在 binning 階段之后,由于通過(guò) vs 有了深度信息,可以利用這個(gè)深度信息來(lái)剔除遠(yuǎn)處的三角形(或像素)的繪制,減少后面 ps 的 overdraw。這個(gè)機(jī)制,Adreno GPU 稱為 LRZ (Low Resolution Depth),PowerVR GPU 稱為 HSR (Hidden Surface Removal),Mali 稱為 FPK (Forward Pixel Killing)。因此,在這個(gè)層面上,這個(gè)迷思是正確的。
但是有另外一種 overdraw 原理完全不同,稱為 "Quad Overdraw"。SP 在做 PS 繪制時(shí),并不是以 pixel 為單位,而是以 quad 為單位的,每個(gè) quad 是 4 個(gè)像素。如下圖
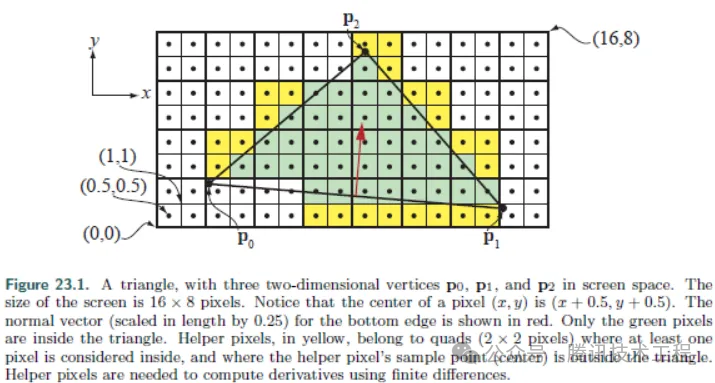
一個(gè) quad 中畫多了的那些 pixel,就是 quad overdraw。一個(gè)三角形的面積越大,quad overdraw 的比例就會(huì)越小。極端情況下,如果三角形只占據(jù)了 1 pixel,那么就會(huì)有 3 pixel 的繪制是浪費(fèi)的,75% 的 quad overdraw。
Quad overdraw 在 GPU 的實(shí)現(xiàn)邏輯,就是 Divergency。因此,在 Adreno 這種對(duì)于 divergency 更敏感的架構(gòu)中,這個(gè)問(wèn)題會(huì)變得更嚴(yán)重。Adreno 架構(gòu)一個(gè) wave 最多只能處理 4 個(gè)三角形,但卻有 128 個(gè) fiber。極端情況下,每個(gè)三角形只占據(jù) 1 個(gè)像素,那么 128 fiber 只畫了 4 個(gè)有效像素,浪費(fèi)了 96.9% 的算力。
因此,我們需要盡量減少微小的三角形的出現(xiàn),最直接的辦法就是使用合適的 LOD。這不僅會(huì)讓繪制的三角數(shù)量更少,減少帶寬使用,還會(huì)讓繪制效率更高。Arm 對(duì)此的建議是,建議每個(gè)三角形至少覆蓋 10-20 個(gè) fragment。
- Use models that create at least 10-20 fragments per primitive.
驗(yàn)證 Quad Overdraw,一樣還是用 % Shader ALU Capacity Utilized、% Time ALUs Working 這倆指標(biāo)。Divergency 比例 = % Time ALUs Working - % Shader ALU Capacity Utilized
為了排除 shader 分支造成的 divergency 的干擾,可以將 shader 都替換為沒(méi)有任何分支的簡(jiǎn)單 shader。
Shader 復(fù)雜度
當(dāng)我們?cè)谡f(shuō)「shader 復(fù)雜度」的時(shí)候,我們是在說(shuō):
- Shader 靜態(tài)指令數(shù)
- Shader 動(dòng)態(tài)指令數(shù)
- Shader 使用的寄存器數(shù)量
分別討論一下這幾個(gè)指標(biāo)過(guò)多過(guò)大之后的問(wèn)題
指令數(shù)量
「指令數(shù)量」分為:靜態(tài)指令數(shù)(static instruction count)和動(dòng)態(tài)指令數(shù)(dynamic instruction count)。靜態(tài)指令數(shù)是指編譯后的 shader 程序里的指令數(shù)量;動(dòng)態(tài)指令數(shù)則是被執(zhí)行的指令數(shù)量。比如,使用 [unroll] 展開(kāi) for 循環(huán),那么編譯出來(lái)的程序的靜態(tài)指令數(shù)就會(huì)比沒(méi)有展開(kāi)的多。但無(wú)論是否展開(kāi),運(yùn)行兩個(gè)程序的動(dòng)態(tài)指令數(shù)應(yīng)該是一樣的。
Offline compiler 統(tǒng)計(jì)出來(lái)的都是靜態(tài)指令數(shù),但是可能會(huì)也會(huì)統(tǒng)計(jì)出的最短執(zhí)行路徑的動(dòng)態(tài)指令數(shù)。
當(dāng)靜態(tài)指令數(shù)量過(guò)多時(shí),cache 就會(huì)裝不下。Snapdragon Profiler 中有對(duì)應(yīng)的指標(biāo):
% Instruction Cache Miss: 不要讓 Shader (編譯后機(jī)器)指令超過(guò) 2000 條(VS+PS),用 SDP 的 Offline Compiler 可以看到指令數(shù)
寄存器數(shù)量
Shader Processor (SP) 中使用寄存器來(lái)保存 shader 的上下文。如果 shader 的寄存器使用過(guò)多,當(dāng)需要通過(guò)切換執(zhí)行的 shader 來(lái) hide latency 時(shí),寄存器數(shù)量不足而無(wú)法切換,進(jìn)而導(dǎo)致執(zhí)行效率下降。
什么是 "Hide Latency" 呢?就是當(dāng) SP 當(dāng)前執(zhí)行的 shader 發(fā)生 long latency 時(shí)(比如貼圖采樣),為了提高利用率,SP 會(huì)切換到另一個(gè) shader 來(lái)執(zhí)行而不是干等。這就稱為 "Hide Latency"。是否可以切換成功的條件是,寄存器在保留原 shader 上下文的基礎(chǔ)上,是否足以可以容納新 shader 的上下文。如果某個(gè) shader 需要多寄存器較多,當(dāng)前的寄存器已經(jīng)放不下了,就會(huì)導(dǎo)致切換失敗。
貼圖采樣、Storage Buffer 訪問(wèn)都會(huì)造成 latency,寄存器使用的數(shù)量會(huì)影響 hide latency 的效率。因此,我們要避免同時(shí)貼圖采樣數(shù)量多而又計(jì)算過(guò)程復(fù)雜(寄存器使用數(shù)量多)的 shader。
當(dāng)占用寄存器數(shù)量繼續(xù)增大,大于 on-chip memory 的尺寸時(shí),會(huì)出現(xiàn) "Register Spilling"。也就是寄存器存不下來(lái),只能放到 system memory 里了,那么性能就會(huì)出現(xiàn)斷崖式下降。
寄存器數(shù)量是移動(dòng)端 GPU 和桌面端一個(gè)大的差異點(diǎn)。驍龍888 是 64KB 每 64 ALU,而 nVidia/AMD 是 256KB 每 64 ALU。這直接決定了兩端 shader 的復(fù)雜程度。桌面端的 shader 拿到移動(dòng)端來(lái)跑,性能的下降并不是和指令數(shù)量不是成線性關(guān)系,而會(huì)因?yàn)榧拇嫫魅萘坎蛔悖瑢?dǎo)致 shader 無(wú)法充分地切換、甚至出現(xiàn) spilling 而執(zhí)行效率非常低下。
使用 Offline Compiler 中的: register footprint per shader instance 來(lái)看 shader 寄存器的使用數(shù)量。
在 Snapdragon Profiler 中可以通過(guò) % Shader Stalled 來(lái)判斷 shader 的執(zhí)行效率。當(dāng) SP 無(wú)法切換到其他 shader 去執(zhí)行時(shí),就會(huì)出現(xiàn) stall。
% Shader Stalled: 指沒(méi)有任何 execution units (主要是指 alu, texture & load/store) 在工作的 cycles 占總 Cycle 數(shù)的比例。Memory fetch stalled 不一定意味著 Shader Stalled,因?yàn)槿绻?shader 還能找個(gè)某個(gè) wave 執(zhí)行 ALU,那么不算 stall。% Shader Stalled 意味著 IPC (instruction per cycle) 下降。
移動(dòng)端 Vertex Shader 是性能敏感的
移動(dòng)端,vertex shader 性能敏感有幾層原因:
首先,在 TBR 架構(gòu)中,跨 tile 的三角形在每個(gè) tile 中都會(huì)被執(zhí)行。如果開(kāi)啟了 MSAA,那么 tile size 就會(huì)變小,那么跨 tile 的三角形數(shù)量就會(huì)變多,vs 壓力會(huì)變得更大。
其次,就是前面架構(gòu)部分說(shuō)到的,在 Adreno/Mali 架構(gòu)中,VS 都會(huì)被執(zhí)行 2 次。在 iOS 中只在 binning pass 階段執(zhí)行一次 VS,render pass 只執(zhí)行 PS。
Adreno/Mali 在 binning pass 中,并不是執(zhí)行全量的 VS,而是只執(zhí)行與 position 相關(guān)的指令。一般里說(shuō),position 的計(jì)算只需要做座標(biāo)系轉(zhuǎn)換。但如果涉及復(fù)雜計(jì)算或者貼圖采樣,那么這部分開(kāi)銷就被放大。比如,在地形繪制時(shí)通過(guò)采樣高度圖來(lái)計(jì)算頂點(diǎn)位置。
第三,Vertex Output 也會(huì)影響管線執(zhí)行效率。這是跟硬件實(shí)現(xiàn)相關(guān)的。
在 Adreno 架構(gòu)中,vertex output 是不需要 resolve 到 SYSMEM 的。每個(gè) SP 中的 Local Buffer 里有一小塊區(qū)域是用來(lái)存 vs output 的,可以在 ps 階段使用。但是這部分的區(qū)域是有限的,在 8Gen2 中只有 8KB。如果 SP 中這塊區(qū)域滿了,就會(huì)出現(xiàn) vs stall。如果一個(gè) vs output 是 12 個(gè) float4 attribute,那么 8KB 可以裝 64 個(gè) fragment。
在 Mali 的第五代 GPU 架構(gòu) Immortalis 之前,在 render pass 中執(zhí)行的 vs 產(chǎn)生的 vs output 是會(huì) resolve 到 SYSMEM,在 ps 中再 load 回來(lái)。這樣就產(chǎn)生了帶寬開(kāi)銷。第五代 GPU 架構(gòu)引入了 Deferred vertex shading (DVS) pipeline,可以省去 vs output resolve/unresolve 的過(guò)程,對(duì)帶寬有較大的改善。官方的說(shuō)法是 20% - 40% 的帶寬。但可以想象,這部分肯定也是有存儲(chǔ)上限的。
總結(jié)來(lái)說(shuō),就是
- 啟用 MSAA 會(huì)加重 VS 的壓力
- VS 中 position 計(jì)算部分不要用過(guò)重的邏輯,尤其不要使用 data fetch、貼圖采樣。
- 要控制 VS Output 的數(shù)據(jù)量,數(shù)據(jù)量過(guò)大,可能會(huì)造成 vs stall;對(duì)于 mali 舊機(jī)型、iOS,會(huì)增加帶寬使用。
是否要做 PrePass
這個(gè)問(wèn)題會(huì)比較復(fù)雜。
我們重新看看前面 Adreno 的架構(gòu)圖:在 Binning pass 階段會(huì)做 LRZ (Low Resolution Z,也就是低分辨率的深度圖) 剔除。接著在 Rendering pass 階段會(huì)做 early-z 和 late-z。LRZ Test 是做低分辨率、primitive 顆粒度的深度剔除;Early-Z、Late-Z 是做全分辨率、quad 顆粒度的深度剔除。
對(duì)于 Opaque 物體,在 LRZ/Early-Z 階段,會(huì)去做不同顆粒度的 Test & Write;在 Late-Z 就無(wú)需再做測(cè)試了。
對(duì)于 Translucent (Alpha Blend) 物體,不可以 Write。但是因?yàn)橛锌赡軙?huì)被更近的深度剔除掉,所以可以 Test。
對(duì)于 Mask (Alpha Test) 物體,深度其實(shí)在 VS 階段就可以確定了,但是因?yàn)榭赡茉?ps 階段被 discard 掉,所以在 LRZ、Early-Z 階段都只能 Test 不能 Write,需要到 Late-Z 才能 Write。
對(duì)于 Custom Depth (oDepth) 的物體,只會(huì)在 Late-Z 寫深度,且不會(huì)被深度剔除。oDepth 是 pixel shader output depth register,專門指 ps 階段寫深度的寄存器。
| LRZ | Early-Z | Late-Z | |
|---|---|---|---|
| Opaque | Test & Write | Test & Write | Off |
| Translucent (Alpha Blend) | Test | Test | Off |
| Masked (Alpha Test) | Test | Test | Write |
| Custom Depth (oDepth) | Off | Off | Write |
有了上面的梳理,我們?cè)賮?lái)看看這個(gè)迷思。
PrePass,在桌面端的傳統(tǒng)做法,是針對(duì) Opaque 先跑一遍 PositionOnly 的較為簡(jiǎn)單的 Shader,生成深度圖給后面的 BasePass 使用。以達(dá)到減少 overdraw 的目的。但是對(duì)于移動(dòng)端來(lái)說(shuō),由于 binning pass 的 LRZ 已經(jīng)做了類似的事情,因此移動(dòng)端的 Opaque 物體是沒(méi)必要做這個(gè)事情的。
對(duì)于「移動(dòng)端是否要做 PrePass」的討論,一般主要集中在 Mask 物體。Mask 物體無(wú)法在 LRZ/Early-Z 階段寫深度,那么對(duì)于大面積的 Mask 物體就會(huì)造成 overdraw。如果大量的 mask 物體穿插在一起(比如植被),開(kāi)銷就跟畫一堆透明物體一樣。
并且對(duì)于不同的架構(gòu),Mask 的沖擊是不一樣的。
對(duì)于 PowerVR 的架構(gòu)下,"Overdraw Reducing" 是使用了 HSR (Hidden Surface Removal)。這是一個(gè) Fragment 顆粒度的可見(jiàn)性剔除,在 binning pass 階段會(huì)輸出一張全分辨率的 visibility map,在 render pass 中只需要執(zhí)行 ps 而無(wú)需再執(zhí)行 vs。因此可以無(wú)視 drawcall 提交順序。
With PowerVR TBDR, Hidden Surface Removal (HSR) will completely remove overdraw regardless of draw call submission order.
但如果遇到 alpha test,那就很難受了。需要等到 ps 執(zhí)行完得到真實(shí)深度了,再 feedback 到 HSR。這個(gè) feedback 是否會(huì) stall 后面的 drawcall 呢?資料中沒(méi)有明確地提及。由于需要根據(jù) HSR 產(chǎn)生的 visibility map 去做 render pass,所以可以猜測(cè)就算不會(huì) stall 后面的 drawcall,也會(huì) stall 整個(gè) HSR。
對(duì)于 Adreno/Mali 架構(gòu),雖然 Mask 不會(huì)造成管線 stall,但是混雜了 Opaque 和 Mask 的渲染 pass,對(duì)管線的執(zhí)行效率也是有影響。因此也是建議將 Opaque/Mask 作為兩個(gè) pass 來(lái)渲染。
默認(rèn)的處理方案,是將 Opaque 和 Mask 分成兩個(gè) pass 來(lái)渲染,避免 Mask 對(duì)渲染管線的阻塞。
在默認(rèn)方案之上,可以考慮針使用專門的簡(jiǎn)化的 vs/ps 對(duì) Mask 物體先做一遍 PrePass,然后在 BasePass 階段 Mask 物體就無(wú)需標(biāo)記為 Alpha Test 了,只需要將 Depth Test 設(shè)成 Equal。因?yàn)?Mask 物體需要執(zhí)行 ps 才能得到深度,因此需要一個(gè)簡(jiǎn)化到只做采樣 alpha 的專門 ps。
總結(jié)來(lái)說(shuō),Mask 的 PrePass 的意義在于用一批簡(jiǎn)單的 drawcall 來(lái)?yè)Q取 BasePass 的管線執(zhí)行效率、減少 overdraw。
PowerVR 架構(gòu)下,不會(huì)讓 alpha test 的 late-z 成為 HSR 的瓶頸;Adreno/Mali 架構(gòu)下,不存在 stall pass 的問(wèn)題,PrePass 更大的意義在于可以參與去剔除 BasePass 中的物體,無(wú)論是 Opaque/Translucent/Masked。
但這批「簡(jiǎn)單的 drawcall」當(dāng)然也有開(kāi)銷,PrePass 是否一個(gè)正優(yōu)化,需要根據(jù)場(chǎng)景類型、機(jī)型來(lái)做 perf tuning。
運(yùn)行 CS 可以更高效地利用 GPU
現(xiàn)在都 Shader Processor (SP) 都是 unified design,一個(gè) SP 可以執(zhí)行 VS/PS/CS,不會(huì)有專門用于跑 CS 的 SP。因此單獨(dú)地跑 raster pipeline 并不會(huì)造成硬件利用率不高。并且在 SP 工作在 VS/PS 下,和工作在 CS 下是兩種不同「工作模式」。切換成本根據(jù)硬件而有所不同。
如果在 VS/PS 和 CS 可以「同時(shí)」跑在同一個(gè) SP 上,這個(gè)功能稱為 Async Compute。這個(gè)「同時(shí)」是打引號(hào)的,是指 SP 上可以有 graphics wave 和 compute wave 互相切換,用來(lái) hide latency。在這個(gè)層面上講,確實(shí)是可以更高效地利用 GPU。
但是對(duì)于結(jié)對(duì)同時(shí)運(yùn)行的 graphics 和 compute 最好在資源使用上最好是匹配互補(bǔ)的。比如,好的匹配:
- Graphics: Shadow Rendering (Geometry limited)
- Compute: Light Culling (ALU Heavy)
壞的匹配:
- Graphics: G-Buffer (Bandwidth limited)
- Compute: SSAO (Bandwidth limited)
目前 iOS 是移動(dòng)端支持 Async Compute 支持最好的。Mali 也是支持的,但更多的細(xì)節(jié)需要測(cè)試。但 Adreno 到目前為止還是不支持的。
GPU Driven 在移動(dòng)端的技術(shù)限制
GPU Driven 是在桌面端一種非常細(xì)顆粒度的三角面剔除 + 合批方案,但是在移動(dòng)端鮮有應(yīng)用。雖然其目的是「GPU 性能換取 CPU 性能」,但在移動(dòng)端對(duì)于 GPU 的性能沖擊跟 CPU 的性能優(yōu)化是不匹配的。
究其原因,主要有兩個(gè):
- 低效的 Storage Buffer 隨機(jī)訪問(wèn)
- 大量的 small drawcall,以及 instanceCount=0 的 invalid drawcall
GPU Driven 中,"PerInstance" 的 vertex stream 里存放的是指向各個(gè) storage buffer 的 index。這些 storage buffer 存的是 Instance Transform、Material Data、Primitive Data 等信息。在 VS 中通過(guò) index 索引這些 storage buffer 獲取有效數(shù)據(jù)。原先這些數(shù)據(jù)都是通過(guò) instance buffer (vertx stream) 或者 uniform buffer 來(lái)獲取的,在 on-chip memory 上就可以很快的獲取到。改為 storage buffer 之后,這些 buffer 一般都比較大,on-chip memory 和 L1/L2 都是存不住的,大概率都要到 SYSMEM 去拿數(shù)據(jù),因此效率很低。
尤其是 instance transform,是會(huì)參與 vs 的 position 計(jì)算的。在移動(dòng)端就會(huì)導(dǎo)致這部分計(jì)算要跑兩遍。
地道的 GPU Driven 會(huì)做 cluster 級(jí)別的剔除,一個(gè) cluster 可能是 64/128 個(gè)三角形。每個(gè) cluster 作為一個(gè) indirect drawcall 的 sub-drawcall 來(lái)繪制。如果這個(gè) cluster 被剔除,那么這個(gè) sub-drawcall 的 instance count 就會(huì)被寫為 0。這種處理方式,一方面產(chǎn)生非常多的 small drawcall,另一方面產(chǎn)生了很多的 instanceCount=0 的 invalid drawcall
GPU 有專門的用來(lái)生成 wave 的組件,Adreno 的叫 HLSQ (High Level Sequencer),Mali 的叫 Warp Manager。這些組件會(huì)預(yù)讀取若干個(gè) drawcall 來(lái)生成 wave,以便可以互相切換。但移動(dòng)端這塊能預(yù)讀取的數(shù)量是比較有限的,比如 Adreno 8Gen1 的 HLSQ 就只能預(yù)讀取 4 個(gè) drawcall。如果這些是 small drawcall 或者 invalid drawcall,那就導(dǎo)致喂不飽后端的管線。
最后
破除迷思的辦法,就是摒棄神秘主義,知其然知其所以然。希望這些可以為我們后面的優(yōu)化帶來(lái)更清晰的思路和方法,而不是盲人摸象。
貫徹費(fèi)曼學(xué)習(xí)法,這也算是我自己個(gè)人在這方面所了解的東西的一個(gè)總結(jié)。
但作為應(yīng)用層,終究只能在廠商構(gòu)筑的黑盒之外摸索和猜測(cè)。所以難免會(huì)有很多不正確、不詳盡、過(guò)時(shí)的東西。望見(jiàn)諒。
-
gpu
+關(guān)注
關(guān)注
28文章
4944瀏覽量
131220 -
蘋果
+關(guān)注
關(guān)注
61文章
24545瀏覽量
203934 -
硬件
+關(guān)注
關(guān)注
11文章
3483瀏覽量
67487
發(fā)布評(píng)論請(qǐng)先 登錄
手機(jī)散熱器拆解
【電子拆解無(wú)極限】華為超薄旗艦Ascend P1真機(jī)拆解
GPU
NVIDIA火熱招聘GPU高性能計(jì)算架構(gòu)師
GPU加速XenApp/Windows 2016/Office/IE性能會(huì)提高嗎
如何在vGPU環(huán)境中優(yōu)化GPU性能
big.LITTLE和GPU相結(jié)合可以實(shí)現(xiàn)性能和功耗的最佳匹配
GPU爆炸式發(fā)展背后的深層原因?
如何使用iMX8mmini提高GPU性能?
Mali GPU性能分析工具
選擇GPU服務(wù)器需要考慮哪些情況如何才能提升GPU存儲(chǔ)性能
GPU高性能服務(wù)器配置
如何提高GPU性能
?為什么GPU性能效率比峰值性能更關(guān)鍵






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論