 云電腦:快速部署無限制、可聯網、帶專屬知識庫的私人 DeepSeek 大數據模型
云電腦:快速部署無限制、可聯網、帶專屬知識庫的私人 DeepSeek 大數據模型

在當下的科技領域,DeepSeek 無疑是一顆耀眼的明星,近期關于它的話題熱度持續飆升,引發了無數技術愛好者和行業從業者的熱烈討論。大家紛紛被其強大的大數據處理能力和廣泛的應用前景所吸引,急切地想要深入探索和使用這一先進的模型。然而,當人們滿懷期待地訪問 DeepSeek 官網時,卻遭遇了令人頭疼的問題 —— 官網響應極其緩慢,常常讓等待的時間變得漫長而煎熬,嚴重影響了大家獲取信息和使用服務的效率。
不過,現在有一個絕佳的解決方案擺在我們面前。今天,就讓我們一同深入學習如何巧妙利用京東云電腦,快速部署一個功能強大的私人 DeepSeek 大數據模型。這個模型不僅無使用限制,還能自由聯網,更可自定義自己的專屬知識庫,能夠滿足你多樣化的使用需求,為你帶來前所未有的便捷體驗。
為什么要部署私人大數據模型?
或許你會心生疑惑,既然有眾多便捷的云端 AI 服務可供選擇,為何還要大費周章地進行私人部署呢?實際上,本地部署私人 DeepSeek 大數據模型有著諸多不可替代的獨特優勢。
1.免費使用,降低成本:在當今的 AI 服務領域,許多云端服務都需要按使用量付費,對于頻繁使用 AI 模型的用戶來說,這無疑會帶來一筆不菲的開支。而本地部署,一旦完成初始的環境搭建與模型下載,便無需再支付額外的使用費用,就像擁有了一臺專屬的 AI 超級助手,隨時待命,卻不會產生任何后續的經濟負擔。
2.數據隱私保護:當我們使用云端 AI 服務時,數據會被上傳至第三方服務器,這意味著我們的隱私數據可能面臨泄露的風險。而本地部署將數據完全存儲在本地,就如同將珍貴的寶藏鎖在自己的保險柜里,只有自己擁有鑰匙,極大地保障了數據的安全性和隱私性,讓我們可以毫無顧慮地處理敏感信息。
3.無網絡依賴,隨時隨地使用:云端服務對網絡的依賴性極高,一旦網絡出現波動或中斷,服務便無法正常使用。而本地部署的 AI 模型則擺脫了這種束縛,無論身處網絡信號良好的繁華都市,還是網絡覆蓋薄弱的偏遠地區,只要設備正常運行,就能隨時隨地調用模型,享受高效穩定的 AI 服務,就像擁有了一個隨叫隨到的私人智能秘書。
4.靈活定制,滿足個性化需求:不同的用戶在使用 AI 模型時,往往有著不同的需求和偏好。本地部署賦予了我們充分的自主控制權,我們可以根據自己的實際需求,自由調整模型的參數和配置,添加個性化的功能,打造專屬于自己的獨一無二的 AI 模型,使其更貼合我們的工作和生活場景。
5.性能與效率優勢:本地部署能夠充分利用本地設備的硬件資源,避免了云端服務中可能出現的網絡延遲和資源競爭問題,從而實現更快的響應速度和更高的運行效率。在處理復雜任務時,本地部署的模型能夠迅速給出結果,大大提升了工作效率,讓我們在與時間賽跑的競爭中搶占先機。
6.無額外限制:一些云端 AI 服務可能會對使用時長、請求次數、生成內容等設置限制,這在一定程度上束縛了我們的使用體驗。而本地部署的模型則沒有這些限制,我們可以盡情發揮創意,自由探索 AI 的無限可能,充分滿足我們對技術的好奇心和探索欲。
DeepSeek 各版本示意
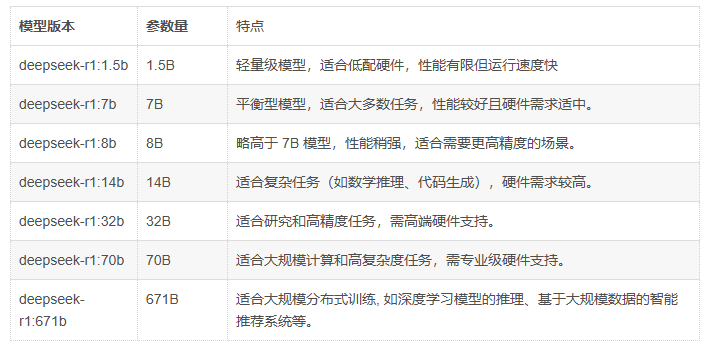
在深入探討部署過程之前,我們先來了解一下 DeepSeek 模型的不同版本及其特點,這將有助于我們更好地選擇適合本地部署的模型。DeepSeek 模型主要有滿血版和蒸餾版兩個版本,它們在多個方面存在明顯差異。
?滿血版指的是 DeepSeek 的完整版本,通常具有非常大的參數量。例如,DeepSeek-R1 的滿血版擁有 6710 億個參數。這種版本的模型性能非常強大,但對硬件資源的要求極高,通常需要專業的服務器支持。例如,部署滿血版的 DeepSeek-R1 至少需要 1T 內存和雙 H100 80G 的推理服務器。
?蒸餾版本是通過知識蒸餾技術從滿血版模型中提取關鍵知識并轉移到更小的模型中,從而在保持較高性能的同時,顯著降低計算資源需求。蒸餾版本的參數量從 1.5B 到 70B 不等,比如以下幾種變體:
?DeepSeek-R1-Distill-Qwen-1.5B
?DeepSeek-R1-Distill-Qwen-7B
?DeepSeek-R1-Distill-Qwen-14B
?DeepSeek-R1-Distill-Qwen-32B
?DeepSeek-R1-Distill-Llama-8B
?DeepSeek-R1-Distill-Llama-70B
DeepSeek-R1 是主模型的名字;Distill 的中文含義是 “蒸餾”,代表這是一個蒸餾后的版本;而后面跟的名字是從哪個模型蒸餾來的版本,例如 DeepSeek-R1-Distill-Qwen-32B 代表是基于千問(Qwen)蒸餾而來;最后的參數量(如 671B、32B、1.5B):表示模型中可訓練參數的數量( “B” 代表 “Billion” ,即十億。因此,671B、32B、1.5B 分別表示模型的參數量為 6710億、320億和15億。),參數量越大,模型的表達能力和復雜度越高,但對硬件資源的需求也越高。
1.對于本地部署而言,蒸餾版是更為合適的選擇。一方面,它對硬件的要求相對較低,不需要昂貴的多 GPU 服務器,普通用戶使用配備合適顯卡的電腦即可完成部署,降低了硬件成本和技術門檻。另一方面,雖然蒸餾版在性能上相較于滿血版有所降低,但在很多實際應用場景中,其性能表現依然能夠滿足需求,性價比極高。
購買和登錄云電腦
訪問京東云官網(https://www.jdcloud.com/),使用京東APP掃碼進入管理控制臺,購買云電腦。
當前官網有試用活動,可以在首頁進入試用中心(https://www.jdcloud.com/cn/pages/free_center),找到4核8G云電腦9.9元7天使用活動,下單。
下單完成后,按照指導登錄云電腦。
搭建 Ollama 服務
在本地部署 DeepSeek 大數據模型的過程中,Ollama 扮演著至關重要的角色,它是一個開源的 LLM(Large Language Model,大型語言模型)服務工具,就像是一位貼心的助手,專門用于簡化和降低大語言模型在本地的部署和使用門檻 ,讓我們能夠更加輕松地在本地環境部署和管理 LLM 運行環境,快速搭建起屬于自己的 AI 模型服務。
接下來,我們將以在 Windows Server 2016 系統環境中部署 Ollama 為例,詳細介紹其安裝和部署步驟。
首先,我們需要下載 Ollama 的安裝文件。

?
Ollama 官方為 Windows、Linux 以及 MacOS 等多種主流系統都提供了對應的安裝文件,我們可以直接從 Ollama 官網的下載頁面(https://ollama.com/download )獲取。在下載頁面中,找到 Windows 系統對應的安裝包,點擊 “Download for Windows ” 進行下載。
下載完成后,我們只需一路點擊 “install” 進行安裝即可。安裝過程就像安裝普通的軟件一樣簡單,按照安裝向導的提示逐步操作,很快就能完成安裝。
安裝完成之后,我們需要驗證 Ollama 是否安裝成功。首先檢查任務欄中是否有Ollama的圖標。
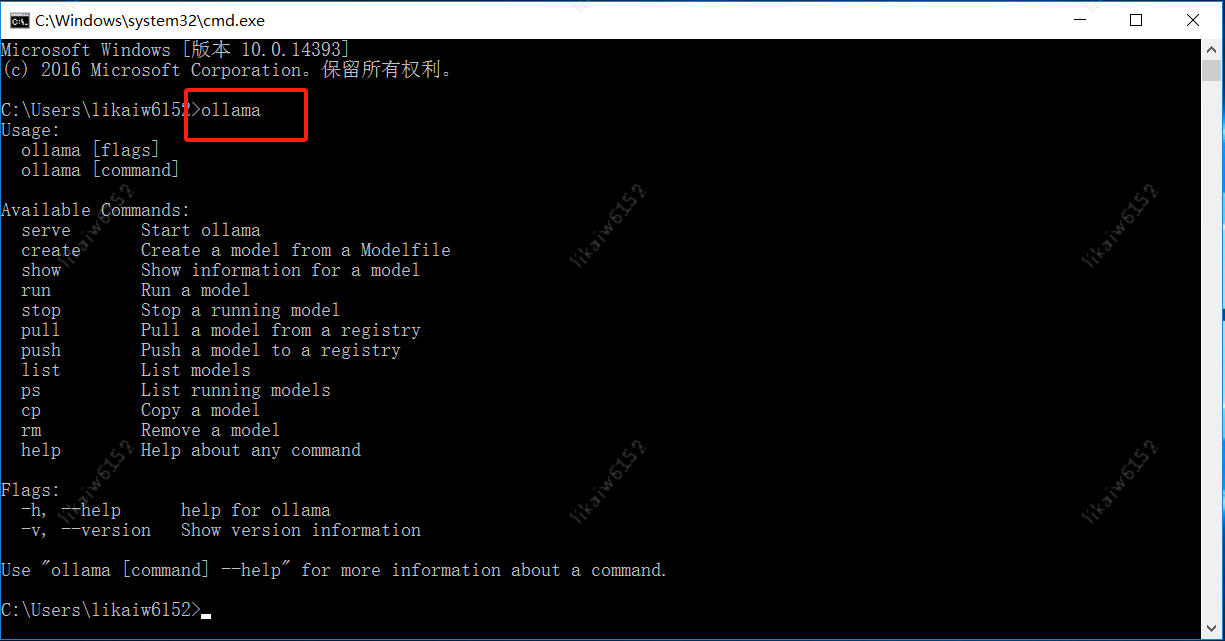
然后打開一個 cmd 命令窗口,輸入 “ollama” 命令,如果顯示 ollama 相關的信息,那就證明安裝已經成功了。這就好比我們安裝完一款游戲后,打開游戲能夠正常顯示游戲界面,就說明游戲安裝成功了一樣。
為了讓 Ollama 在系統啟動時自動運行,我們還需要將其添加為啟動服務。在 Windows 系統中,我們可以通過以下步驟來實現:
1.打開 “服務” 窗口。我們可以通過在 “運行” 對話框中輸入 “services.msc” 并回車來快速打開。
2.在 “服務” 窗口中,找到 “Ollama” 服務(如果沒有找到,可以先在 cmd 命令窗口中輸入 “ollama serve” 啟動 Ollama 服務)。
3.右鍵點擊 “Ollama” 服務,選擇 “屬性”。
4.在 “屬性” 窗口中,將 “啟動類型” 設置為 “自動”,然后點擊 “確定” 保存設置。
這樣,當我們的系統下次啟動時,Ollama 服務就會自動啟動,隨時準備為我們提供服務,就像我們設置了鬧鐘,每天早上鬧鐘會自動響起,提醒我們新的一天開始了一樣。
運行 DeepSeek 模型
當 Ollama 服務成功搭建并順利啟動后,我們就可以著手使用它來運行 DeepSeek 模型了。打開模型的官網地址:https://ollama.com/library/deepseek-r1。
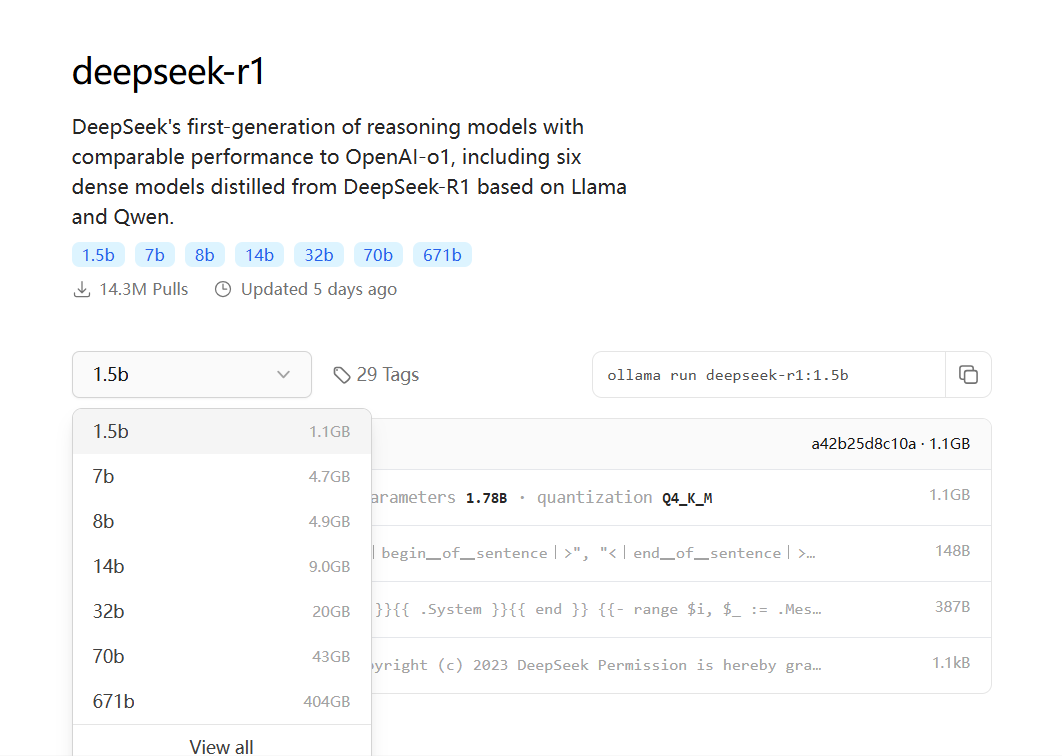
這里我們選擇1.5b的模型,復制后面的內容。
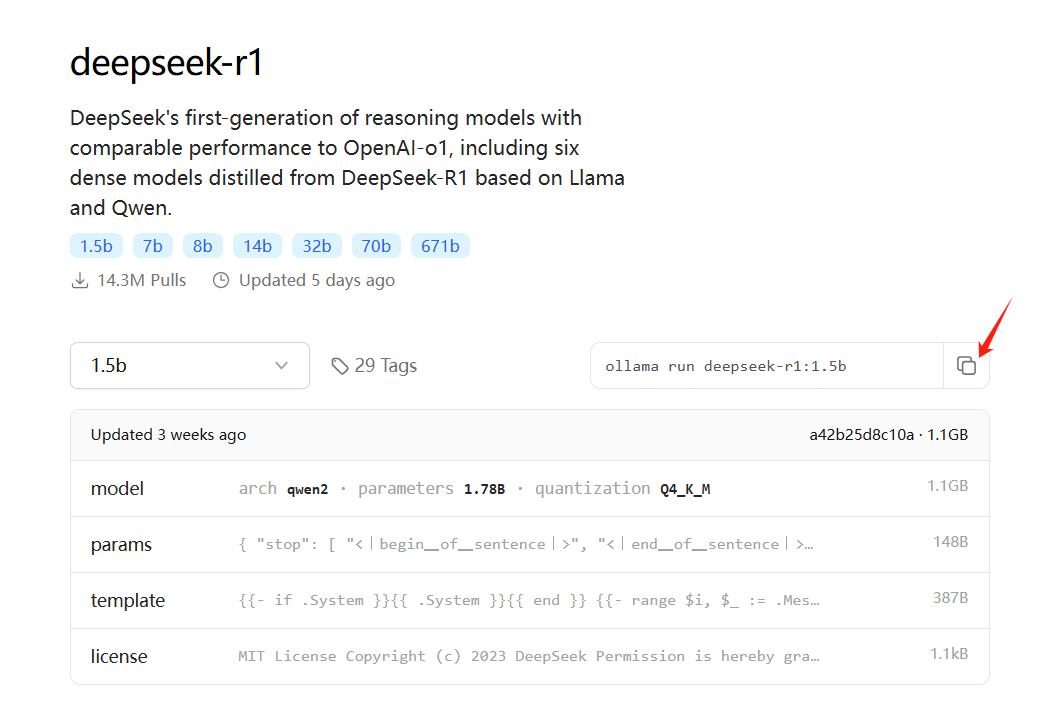
各模型版本說明
| 模型版本 | 所需空余空間 | 部署命令 | 配置說明 |
| 1.5b | 1.1GB | ollama run deepseek-r1:1.5b | 適用于內存為4G的電腦,參數規模較小,適合輕量級任務。 |
| 7b | 4.7GB | ollama run deepseek-r1:7b | 適用于內存為16G的電腦,參數規模適中,適合中等復雜度的任務。 |
| 8b | 4.9GB | ollama run deepseek-r1:8b | 適用于內存為16G的電腦,參數規模適中,適合中等復雜度的任務。 |
| 14b | 9GB | ollama run deepseek-r1:14b | 適用于內存為16G的電腦,參數規模較大,適合較高復雜度的任務。 |
| 32b | 20GB | ollama run deepseek-r1:32b | 適用于內存較大的電腦,參數規模大,適合高復雜度任務和高準確性要求。 |
| 70b | 43GB | ollama run deepseek-r1:70b | 適用于內存較大的電腦,參數規模極大,適合極高復雜度任務和高準確性要求。 |
| 671b | 404GB | ollama run deepseek-r1:671b | 基礎大模型,參數數量最多,模型容量極大,適合處理海量知識和復雜語言模式的任務。 |
?
在命令行中,我們輸入 “ollama run deepseek-r1: 版本號”,由于我們上面復制了,直接鼠標右鍵就可以粘貼成功。
回車后,開始下載
耐心等待后,見如下提示success表示下載成功。

可以問他一些問題,如下:
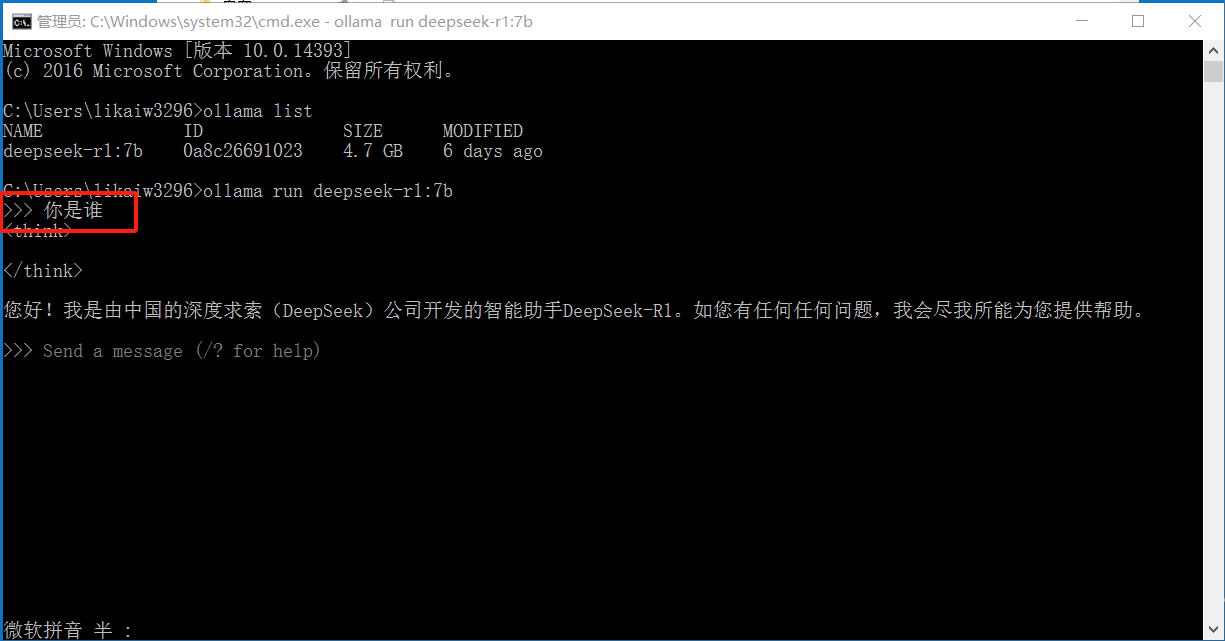
?
圖形客戶端配置本地知識庫
利用 CherryStudio 搭建知識寶庫
Cherry Studio 是一款強大的聚合主流大語言模型服務的桌面工具,為我們搭建本地知識庫提供了便捷的途徑,宛如一位貼心的知識管家,幫助我們高效地管理和利用知識。
1.下載與安裝:打開 Cherry 官網(https://cherry-ai.com/download ),根據自己的操作系統選擇適配的版本進行下載。下載完成后,按照默認設置進行安裝即可。
2.選擇 DeepSeek R1 模型:啟動 Cherry Studio 后,首先需要配置模型服務。我們把在硅基流動中申請的 API 密鑰添加進去,這就像是給模型服務配了一把鑰匙,讓它能夠順利開啟。如果還沒有申請過密鑰,可以在 API 秘鑰下方點擊 “這里獲取密鑰”,進入硅基流動官網,點擊創建 API 密鑰即可。完成密鑰添加后,在下方添加 DeepSeek R1 模型,具體路徑為 deepseek-ai/DeepSeek-R1 ,也可以點擊下方管理按鈕找到 DeepSeek 模型直接添加。添加完成后,點擊檢查按鈕進行測試,當看到檢查按鈕變成綠色對鉤,就表示測試通過,我們已經成功與 DeepSeek R1 模型建立了聯系。
3.搭建本地知識庫:點擊管理按鈕,選擇嵌入模型,這里我們可以把常用的幾個嵌入模型都添加進去,為后續的知識處理做好準備。確認添加后,就能看到之前添加的嵌入式模型了。接著,點擊左側知識庫按鈕,添加本地文檔。在彈出的窗口中,填寫知識庫名稱,選擇合適的嵌入模型,然后上傳本地文件。Cherry Studio 支持多種類型的知識上傳,包括文件、目錄、網址、筆記等等,非常方便。比如我們上傳了一個《三體》全集,當出現對鉤時,就表示文件處理完成,已經成功加入到我們的知識庫中了。
4.使用知識庫:在聊天窗口選擇知識庫圖標,選中之前創建的知識庫,如我們創建的 “test” 知識庫。現在,就可以在聊天區域詢問有關知識庫的問題了。比如我們詢問 “《三體》中三體人的科技特點是什么?”,DeepSeek R1 模型就會結合知識庫中的《三體》內容,給出準確而詳細的回答,讓我們輕松獲取所需的知識。
Page Assist 實現本地模型聯網
Page Assist 是一款開源瀏覽器擴展程序,它就像是一座橋梁,為本地 AI 模型與網絡之間搭建起了溝通的渠道,讓我們的本地 DeepSeek 模型能夠實現聯網搜索,獲取更廣泛的信息。
1.安裝 Page Assist 插件:打開我們常用的瀏覽器(建議使用 Chrome 或 Edge),在瀏覽器的擴展商店中搜索 “Page Assist”,找到對應的插件后點擊安裝。安裝完成后,插件會在瀏覽器的插件欄中顯示。
2.配置 Page Assist:安裝完成后,在瀏覽器的插件列表中點擊打開 Page Assist。在 Page Assist 的 Web UI 界面中,首先選擇剛剛下載的 DeepSeek 模型,確保模型與插件正確連接。接著,在 “RAG 設置” 中,確保選擇了深度求索模型,為聯網搜索做好準備。
3.使用聯網功能:回到主界面,此時界面已經是中文版,使用起來更加方便。點擊 “Page Assist” 插件,點擊上方的下拉菜單,選擇已經安裝的模型。然后將聊天框的聯網按鈕開關打開,就可以進行聯網搜索了。比如我們詢問 “最近的科技新聞有哪些?”,模型就會通過聯網獲取最新的科技資訊,并給出回答,讓我們及時了解行業動態。為了更好地利用知識,我們還可以添加嵌入模型,通過 “ollama pull nomic-embed-text” 命令下載嵌入模型,然后在插件里 RAG 設置中選擇嵌入模型。具體操作是點擊右上角齒輪【設置】——》【RAG 設置】——》選擇文本嵌入模型 ——》點擊【保存】按鈕即可。這樣,模型在處理問題時能夠更好地理解文本的語義和關聯,提供更準確的回答。
Anything LLM 打通本地知識庫以及聯網設置
Anything LLM 專注于文檔知識庫與問答場景,自帶向量檢索管理,就像是一個智能的知識搜索引擎,能夠實現多文檔整合,為我們打造一個強大的本地知識庫問答系統,同時它也支持聯網設置,讓知識獲取更加全面。
1.下載與安裝:打開 Anything LLM 的官網(https://anythingllm.com/desktop ),根據自己的系統選擇下載對應的版本。下載完成后,按照默認路徑安裝或者根據自己的需求修改安裝路徑都可以。安裝完成后,點擊完成按鈕,會自動跳轉到 Anything LLM 界面。
2.配置模型:在 Anything LLM 界面中,首先選擇 Ollama 作為模型管理器,因為我們之前已經通過 Ollama 運行了 DeepSeek 模型,這樣可以實現兩者的無縫對接。Anything LLM 會自動檢測本地部署的模型,前提是確保 Ollama 本地部署的模型正常運行。在模型配置中,“LLM Selection(大語言模型選擇)” 選擇名為 Ollama 的模型,這意味著我們的模型和聊天記錄僅在運行 Ollama 模型的機器上可訪問,保障了數據的安全性和隱私性;“Embedding Preference(嵌入偏好)” 使用名為 AnythingLLM Embedder 的嵌入工具,說明文檔文本是在 Anything LLM 的實例上私密嵌入的,不會泄露給第三方;“Vector Database(向量數據庫)” 使用 LanceDB 作為向量數據庫,保證向量和文檔文本都存儲在這個 Anything LLM 實例上,進一步強調了數據的私密性。
3.搭建本地知識庫:在左側工作區找到上傳按鈕,點擊上傳按鈕后,可以選擇上傳本地文件或者鏈接。比如我們上傳了一個包含公司項目資料的文件,選中上傳的文件,點擊 “Move to Workspace”,然后點擊 “Save and Embed”,系統會對文檔進行切分和詞向量化處理,將文檔轉化為模型能夠理解和處理的格式。完成后,點擊圖釘按鈕,將這篇文檔設置為當前對話的背景文檔,這樣在提問時,模型就會優先參考這篇文檔的內容。
4.深度調整:為了讓模型更好地回答問題,我們可以進行一些深度調整。點開設置,將聊天模式改成查詢模式,這樣 AI 會更基于它查詢出來的數據進行回答;將向量數據庫的最大上下文片段改成 6,意味著每次查詢時,模型會去數據庫里取出 6 個和問題相關的片段,以便更全面地理解問題;將文檔相似性閾值改成中,用來控制查詢到的數據和問題相關程度的閾值,確保獲取到的信息與問題高度相關。
5.聯網設置:雖然 Anything LLM 主要用于本地知識庫的搭建,但它也支持聯網設置。在一些高級設置中,我們可以配置網絡訪問權限,讓模型在需要時能夠聯網獲取更廣泛的信息。比如當本地知識庫中沒有相關信息時,模型可以通過聯網搜索來補充知識,提供更準確的回答。不過在使用聯網功能時,需要注意網絡安全和隱私保護,確保數據的安全傳輸。
審核編輯 黃宇
-
模型
+關注
關注
1文章
3516瀏覽量
50365 -
大數據
+關注
關注
64文章
8959瀏覽量
140112 -
DeepSeek
+關注
關注
1文章
795瀏覽量
1704
發布評論請先 登錄
【幸狐Omni3576邊緣計算套件試用體驗】DeepSeek 部署及測試
《AI Agent 應用與項目實戰》閱讀心得3——RAG架構與部署本地知識庫
技術融合實戰!Ollama攜手Deepseek搭建知識庫,Continue入駐VScode
RK3588開發板上部署DeepSeek-R1大模型的完整指南

DeepSeek從入門到精通(2):0成本用DeepSeek(滿血版)搭建本地知識庫

紹興數據局率先實現政務環境下的DeepSeek模型部署

標普云DeepSeek一體機發布:零門檻部署企業DeepSeek
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
Deepseek R1大模型離線部署教程

“輕松上手!5分鐘學會用京東云打造你自己的專屬DeepSeek”
騰訊云率先上線DeepSeek模型API接口,支持聯網搜索
基于華為云 Flexus 云服務器 X 搭建部署——AI 知識庫問答系統(使用 1panel 面板安裝)






 工商網監
工商網監
評論