") DeepSeek的開源之路:一文讀懂從V1-R1的技術(shù)發(fā)展,見證從開源新秀到推理革命的領(lǐng)跑者
DeepSeek的開源之路:一文讀懂從V1-R1的技術(shù)發(fā)展,見證從開源新秀到推理革命的領(lǐng)跑者
作者:京東科技 蔡欣彤
一、引言:AI時(shí)代的挑戰(zhàn)與DeepSeek的崛起
在大模型時(shí)代,AI技術(shù)的飛速發(fā)展帶來了前所未有的機(jī)遇,但也伴隨著巨大的挑戰(zhàn)。隨著模型規(guī)模的不斷擴(kuò)大,算力需求呈指數(shù)級增長,訓(xùn)練成本飆升,而性能提升的邊際收益卻逐漸遞減,形成了所謂的“Scaling Law”瓶頸。與此同時(shí),OpenAI、谷歌等巨頭通過閉源策略壟斷技術(shù),限制了中小企業(yè)和研究機(jī)構(gòu)的參與空間。在這樣的背景下,DeepSeek應(yīng)運(yùn)而生,以“低成本+高性能+開源”為核心理念,致力于打破行業(yè)壁壘,為AI普惠化開辟了新的可能性。
但每一個(gè)大模型爆火的背后都是需要經(jīng)歷一代代的技術(shù)積累和演進(jìn),所以文本介紹一下 DeepSeek 系列主要模型的發(fā)布?xì)v史及每一代模型的技術(shù)突破。
二、DeepSeek的發(fā)展歷程
1.DeepSeek-V1
DeepSeek V1是2024年1月份發(fā)布的第一版DeepSeek模型,論文地址: https://github.com/deepseek-ai/deepseek-LLM
DeepSeek-V1 有 7B 和 67B 兩個(gè)版本,并且每個(gè)版本分別有基礎(chǔ)和聊天的模型,它支持多種編程語言,具有強(qiáng)大的編碼能力,適合程序開發(fā)人員和技術(shù)研究人員使用。
1.1 技術(shù)分析
?數(shù)據(jù)層面:通過包括去重、過濾、混合3個(gè)步驟構(gòu)建一個(gè)多樣性強(qiáng)、純凈的高質(zhì)量預(yù)訓(xùn)練數(shù)據(jù)
?模型結(jié)構(gòu)方面: 模型的主體結(jié)構(gòu)基本沿用LLaMA的體系結(jié)構(gòu), 在注意力機(jī)制方面, 7B模型使用 多頭注意力Multi-Head attention (MHA),而67B模型使用Grouped-Query Attention (GQA)替代MHA用來降低成本
1.2 成果解讀
第一代的模型在我看來更多的還是復(fù)現(xiàn)LLaMA,雖然采用了更優(yōu)質(zhì)的訓(xùn)練集提升了性能,但就像DeepSeek論文中提到,也存在潛在缺點(diǎn):過渡依賴培訓(xùn)數(shù)據(jù)容易產(chǎn)生偏見;幻覺問題沒有處理很好;在其生成的響應(yīng)中表現(xiàn)出重復(fù)回答等問題.
2.DeepSeek-V2
2024年5月左右發(fā)布了DeepSeek-V2,論文地址: https://github.com/deepseek-ai/DeepSeek-V2 .
這個(gè)版本的發(fā)布也讓deepSeek正式引起了大模型領(lǐng)域的關(guān)注.
2.1 技術(shù)分析
DeepSeek V2最核心的點(diǎn)都在改動(dòng)模型結(jié)構(gòu)上.分別為 多頭潛在注意力機(jī)制(Multi-head Latent Attention,MLA) 和 DeepSeekMoE架構(gòu), 這兩點(diǎn)也為后面的R1版本奠定了基礎(chǔ).
整體結(jié)構(gòu)如下圖:在注意力機(jī)制部分采用MLA,在前饋網(wǎng)絡(luò)(FFN)部分采用DeepSeekMoE的結(jié)構(gòu).
??
??
2.1.1 MLA
在標(biāo)準(zhǔn)的 Transformer 模型中,多頭注意力機(jī)制(MHA)通過并行計(jì)算多個(gè)注意力頭來捕捉輸入序列中的不同特征,每個(gè)注意力頭都有自己的Q,K,V. 這樣在處理長序列時(shí),鍵值緩存(KV Cache)的內(nèi)存開銷會(huì)隨著序列長度線性增長,這成為大模型推理效率的主要瓶頸之一.
MLA利用低秩鍵值聯(lián)合壓縮來消除推理時(shí)間鍵值緩存的瓶頸,從而支持有效的推理.MLA的具體實(shí)現(xiàn)包括以下關(guān)鍵技術(shù):
?低秩鍵值聯(lián)合壓縮(low-rank key-value joint compression):MLA通過將鍵和值矩陣壓縮到低維空間,減少了KV Cache的內(nèi)存占用。
?多頭潛在注意力:MLA在傳統(tǒng)多頭注意力的基礎(chǔ)上,引入了潛在注意力機(jī)制,通過動(dòng)態(tài)調(diào)整注意力頭的計(jì)算方式,進(jìn)一步優(yōu)化了長序列處理的效率。
?稀疏注意力:MLA通過稀疏化注意力權(quán)重,減少了計(jì)算復(fù)雜度,同時(shí)保持了模型的性能。
2.1.2 DeepSeekMoE
DeepSeekMoE對比傳統(tǒng)的混合專家模型(Mixture of Experts, MoE),多了2個(gè)核心優(yōu)化:
?細(xì)粒度專家劃分:如圖(b)Fine-grained Expert,DeepSeekMoE 將專家數(shù)量大幅增加,每個(gè)專家負(fù)責(zé)更小的輸入空間。這種細(xì)粒度劃分使專家能夠更專注于特定任務(wù),從而提高模型的表達(dá)能力和泛化性能
?共享專家隔離:如圖(c)Shared Expert DeepSeekMoE 引入共享專家機(jī)制,用于捕獲跨任務(wù)的通用知識.這樣的設(shè)計(jì)減少了路由專家之間的冗余,提高了參數(shù)效率,還改善了負(fù)載均衡問題,避免了某些專家被過度激活的情況.(簡單點(diǎn)來說,就是共享專家干通用的活,其他專家干自己更專業(yè)的活)
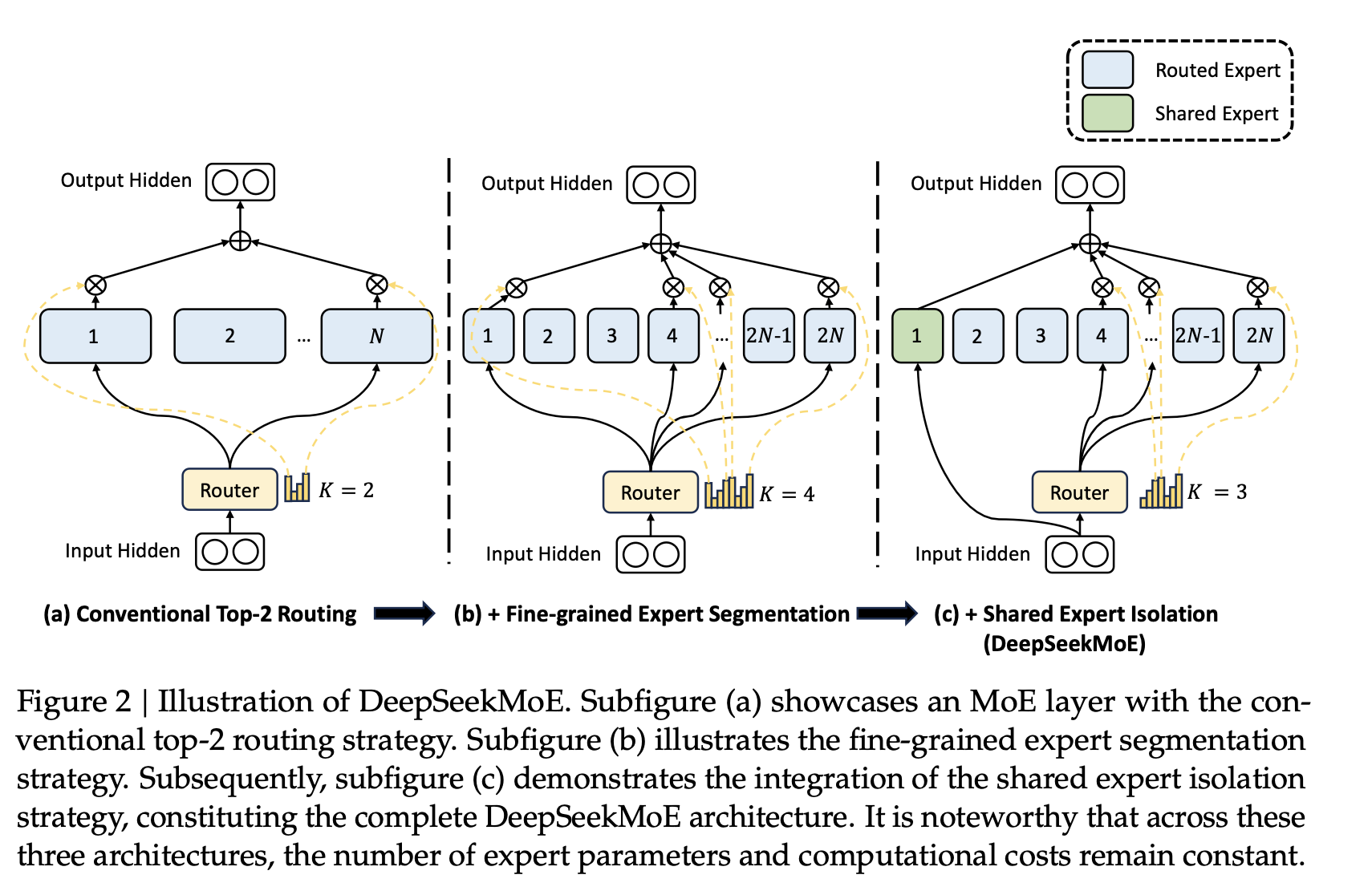
??
此外,DeepSeekMoE還做了負(fù)載均衡策略,
?負(fù)載均衡策略:論文中為Load Balance Consideration
?Expert-Level Balance Loss:創(chuàng)新性地避免了傳統(tǒng)負(fù)載均衡方法對模型性能的負(fù)面影響,通過靈活的批量負(fù)載均衡策略,允許專家在不同領(lǐng)域中更好地專業(yè)化
?Device-Level Balance Loss:在分布式訓(xùn)練和推理中,DeepSeekMoE 通過設(shè)備受限的路由機(jī)制,將專家分配到不同的設(shè)備上,并限制每個(gè)設(shè)備只能訪問本地專家。這減少了跨設(shè)備通信的開銷,顯著提升了訓(xùn)練和推理效率
2.2 成果解讀
高效的性能與低成本:通過上面的結(jié)構(gòu)優(yōu)化,降低了計(jì)算開銷,訓(xùn)練成本的降低大幅降低了開發(fā)門檻,適合科研和商業(yè)化應(yīng)用

??
3.DeepSeek-V3
DeepSeek-V3 是在2024年12月26正式發(fā)布. 論文地址: DeepSeekV3 Technical Report
DeepSeek-V3是該系列中的一個(gè)里程碑版本,專注于知識類任務(wù)和數(shù)學(xué)推理,性能大幅度提升,這個(gè)版本的發(fā)布也讓DeepSeek走進(jìn)了大眾視野.
整體來說,V3版本繼續(xù)沿用了V2版本的MLA和DeepSeekMoE結(jié)構(gòu),總使用了671B參數(shù),完成整個(gè)訓(xùn)練時(shí)間也減少很多.
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training.
3.1 技術(shù)分析
DeepSeekV3在模型結(jié)構(gòu)上的核心優(yōu)化有兩點(diǎn):
1.對DeepSeekMoE中的多專家負(fù)載均衡問題,提出了無輔助損失負(fù)載均衡策略(auxiliary-loss-free strategy),相比使用輔助loss提升了模型性能;
2.引入多Token預(yù)測(Multi-Token Prediction,MTP)技術(shù),相比原來每次只能預(yù)測一個(gè)token,顯著提升了infer的速度。
3.1.1 auxiliary-loss-free strategy
無輔助損失策略旨在解決傳統(tǒng) MoE 模型中因負(fù)載不均衡導(dǎo)致的計(jì)算效率下降和性能損失問題.
傳統(tǒng)的 MoE 模型中,專家負(fù)載不均衡是一個(gè)常見問題。某些專家可能會(huì)被過度激活,而其他專家則處于閑置狀態(tài),這不僅降低了計(jì)算效率,還可能導(dǎo)致路由崩潰(routing collapse),從而影響模型性能.為了解決這一問題,傳統(tǒng)方法通常依賴于輔助損失(Auxiliary Loss),通過額外的損失函數(shù)來強(qiáng)制均衡專家的負(fù)載。然而,輔助損失可能會(huì)對模型性能產(chǎn)生負(fù)面影響,尤其是在損失權(quán)重設(shè)置不當(dāng)?shù)那闆r下.
而無輔助損失負(fù)載均衡策略則是通過動(dòng)態(tài)調(diào)整專家路由的偏差項(xiàng)(bias term)來實(shí)現(xiàn)負(fù)載均衡,而無需引入額外的輔助損失函數(shù).具體來說:
? 偏差項(xiàng)調(diào)整:在訓(xùn)練過程中,系統(tǒng)會(huì)監(jiān)控每個(gè)專家的負(fù)載情況。如果某個(gè)專家過載,則減少其偏差項(xiàng);如果某個(gè)專家欠載,則增加其偏差項(xiàng)。這種動(dòng)態(tài)調(diào)整確保了專家負(fù)載的均衡,同時(shí)避免了輔助損失對模型性能的干擾
? 路由機(jī)制:在計(jì)算專家親和度分?jǐn)?shù)(affinity score)時(shí),偏差項(xiàng)被添加到親和度分?jǐn)?shù)中,以確定每個(gè) token 應(yīng)該路由到哪些專家。門控值(gating value)仍然基于原始的親和度分?jǐn)?shù)計(jì)算,從而保持了模型的路由靈活性
采用這種方法,無需引入額外的損失函數(shù),從而在保持模型性能的同時(shí)提高了訓(xùn)練穩(wěn)定性
3.1.2 MTP
傳統(tǒng)的模型通常采用單Token預(yù)測目標(biāo),即每次將當(dāng)前預(yù)測結(jié)果作為最新的一個(gè)輸入,再次預(yù)測下一個(gè)。而MTP則擴(kuò)展了這一目標(biāo),要求模型在每個(gè)時(shí)間同時(shí)預(yù)測多個(gè)未來的Token(例如2個(gè)、3個(gè)或更多)。
使用MTP, 一方面每次預(yù)測多個(gè)Token,可使訓(xùn)練信號更密集,提高數(shù)據(jù)利用效率和訓(xùn)練速度,另一方面也可以讓模型在生成后續(xù)token的時(shí)候有一個(gè)全局性,從而生成更連貫和語義準(zhǔn)確的文本.
大致做法:模型除了有一個(gè)主模型,還有幾個(gè)并行的MTP模塊.這些MTP模塊的Embedding層和Output Head和主模型共享.在主模型預(yù)測了next token后,將這個(gè)預(yù)測token的表征和之前token的Embedding拼接到一起,生成一個(gè)新的輸入(超出長度的更久遠(yuǎn)的token被才減掉)。這個(gè)拼接好的Embedding輸入到第一個(gè)MTP中預(yù)測next next token。以此類推..
文中引入Multi-Token Prediction主要為了提升訓(xùn)練效果,推理階段可以直接去掉這些MTP模塊,主模型可以獨(dú)立運(yùn)行,確保模型的正常工作.
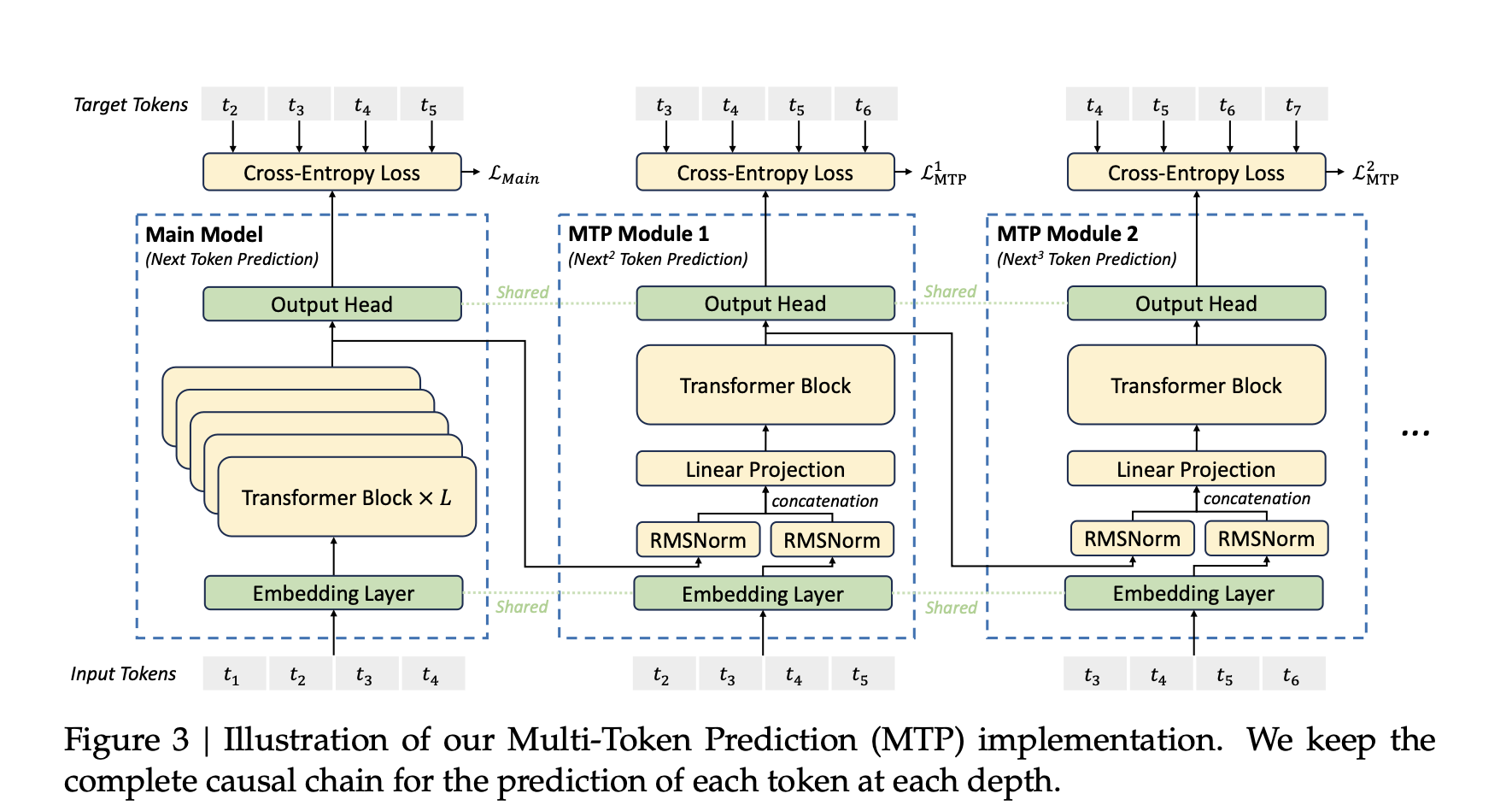
??
3.2 成果
DeepSeek-V3 多項(xiàng)評測成績超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他開源模型,并在性能上和世界頂尖的閉源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
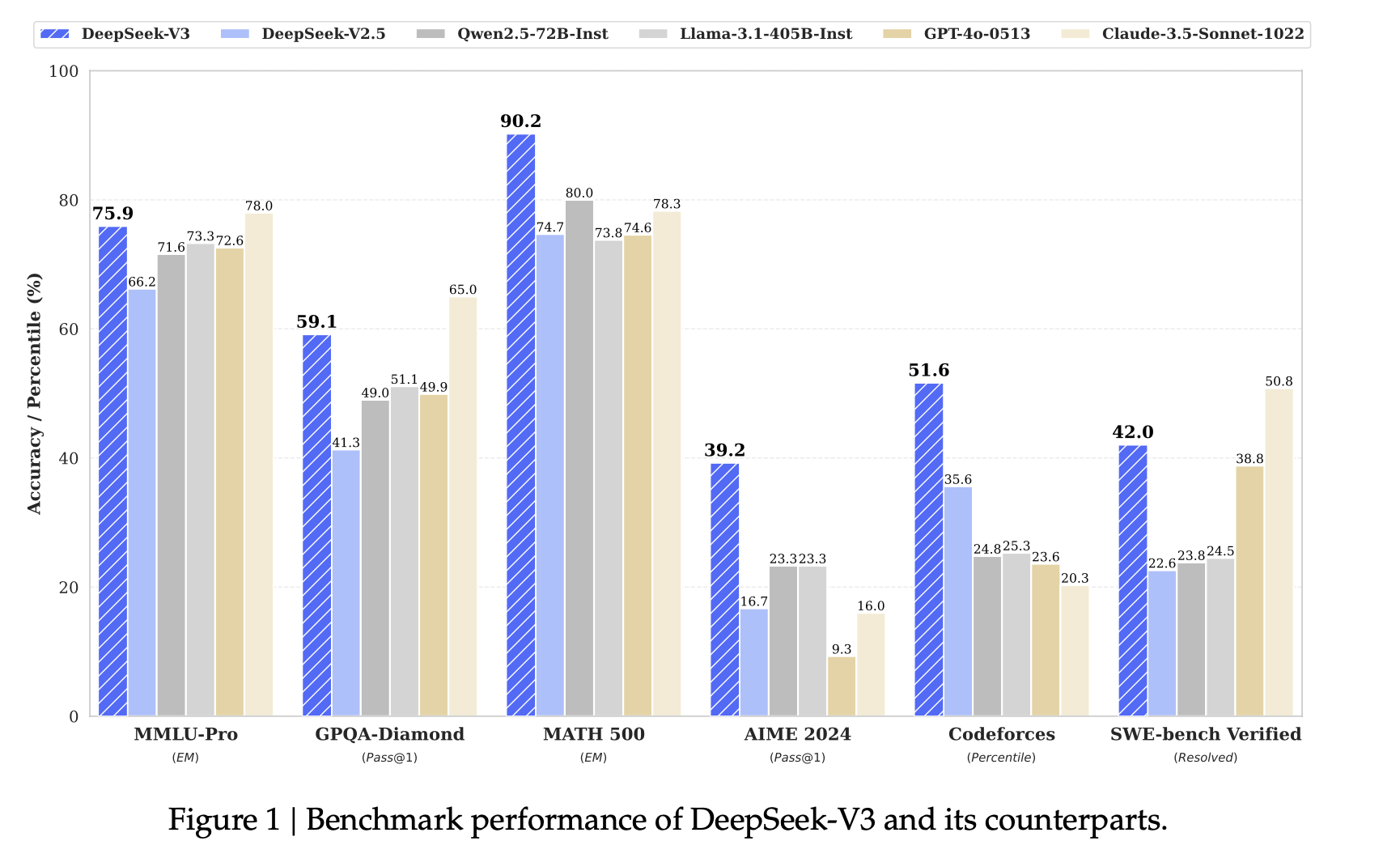
??
?
4.DeepSeek-R1-Zero和DeepSeek-R1
接著就來到了重頭戲,在2025年1月20日發(fā)布的DeepSeek-R1模型, 論文地址: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
他的發(fā)布,帶來了世界的震撼,也讓2025年初所有人都開始談?wù)?
4.1 技術(shù)分析
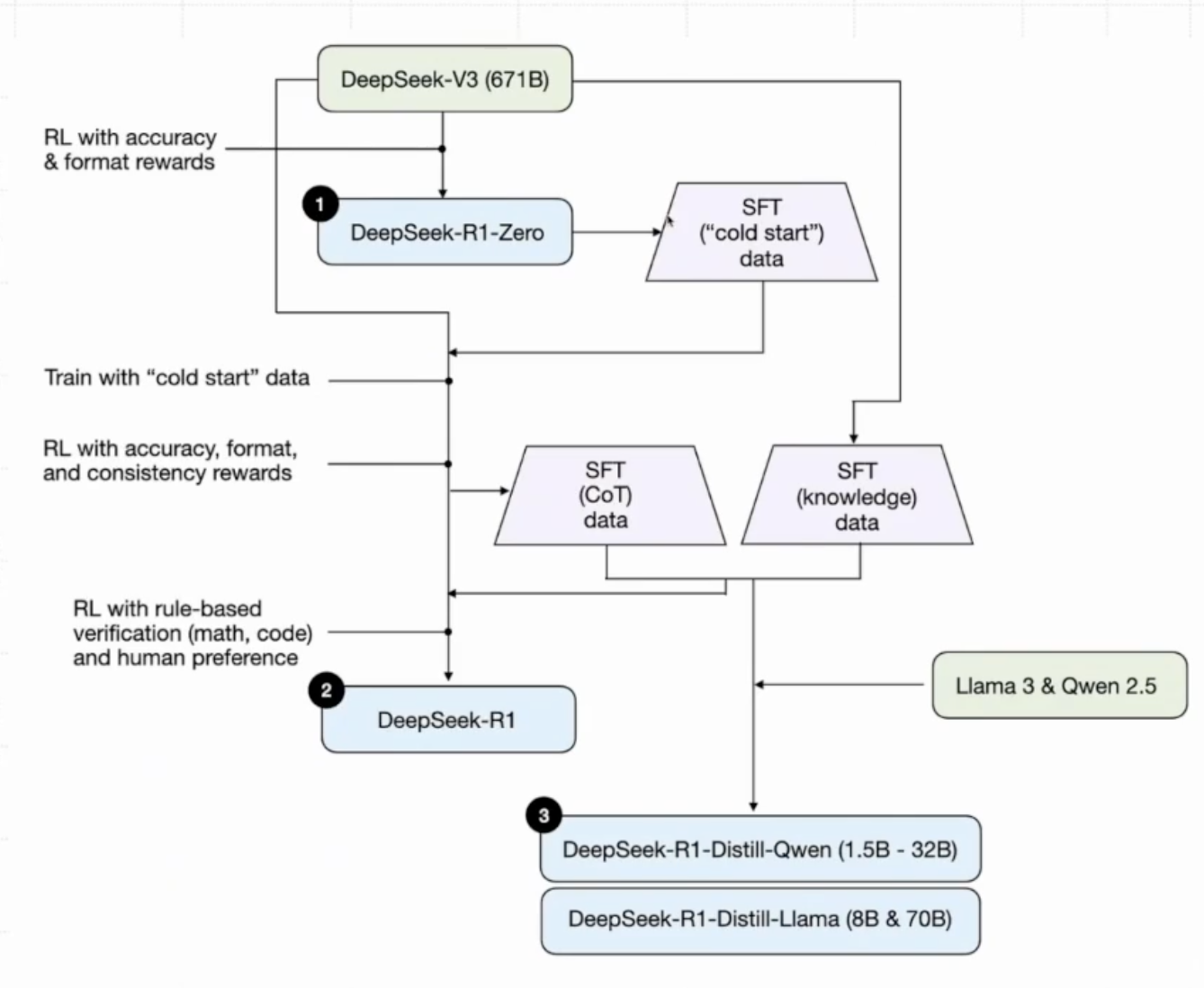
其實(shí)這個(gè)DeepSeek-R1先有一個(gè)DeepSeek-R1-Zero的版本,只通過強(qiáng)化學(xué)習(xí)(RL)進(jìn)行訓(xùn)練,沒有用監(jiān)督微調(diào) (SFT) 作為預(yù)備步驟,但是它遇到了諸如可讀性差和語言混合等問題,接著引入了 DeepSeek-R1,它在 RL 之前結(jié)合了多階段訓(xùn)練和冷啟動(dòng)數(shù)據(jù).
DeepSeek-R1的技術(shù)主要有以下幾點(diǎn):
?采用GROP(Group Relative Policy Optimization)算法
?Reward Modeling :一種基于規(guī)則的獎(jiǎng)勵(lì)系統(tǒng)和語言一致性獎(jiǎng)勵(lì)系統(tǒng)
?Cold Start:使用數(shù)千條冷啟動(dòng)數(shù)據(jù)
4.1.1 GROP算法
LLM 中主流 RLHF 方向分為兩大路線:
?以 [PPO] 為代表的 On Policy 路線 (但目前最常用的還是PPO)每次訓(xùn)練都基于自己的生成模型(Actor),通過教練(Critic)反饋獎(jiǎng)勵(lì);優(yōu)勢是效率高,沒有模型自生成自然效率高,問題是訓(xùn)練后模型能力可能不夠;
?以 [DPO] 為代表的 Off Policy 路線 基于現(xiàn)有標(biāo)注的情況進(jìn)行分析,存在訓(xùn)練樣本可能與模型不匹配的問題;優(yōu)勢是更有可能達(dá)到模型能力的上限,問題是效率較低。
從PPO的優(yōu)化過程分析,其存在如下缺點(diǎn):1.需要訓(xùn)練一個(gè)與策略模型大小相當(dāng)?shù)膬r(jià)值模型(Value Model),這帶來了巨大的內(nèi)存和計(jì)算負(fù)擔(dān); 2.LLM 通常只有最后一個(gè) token 會(huì)被獎(jiǎng)勵(lì)模型打分,訓(xùn)練在每個(gè) token 上都準(zhǔn)確價(jià)值函數(shù)難;
而GROP避免了像 PPO 那樣使用額外的 Value Model ,而是使用同一問題下多個(gè)采樣輸出的平均獎(jiǎng)勵(lì)作為基線,好處:
?無需額外的價(jià)值函數(shù):GRPO 使用組內(nèi)平均獎(jiǎng)勵(lì)作為基線,避免了訓(xùn)練額外的價(jià)值函數(shù),從而減少了內(nèi)存和計(jì)算負(fù)擔(dān)。
?與獎(jiǎng)勵(lì)模型的比較性質(zhì)對齊:GRPO 使用組內(nèi)相對獎(jiǎng)勵(lì)計(jì)算優(yōu)勢函數(shù),這與獎(jiǎng)勵(lì)模型通常在同一問題的不同輸出之間進(jìn)行比較的性質(zhì)相符。
?KL懲罰在損失函數(shù)中:GRPO 直接將訓(xùn)練策略 πθ 和參考策略 πref 之間的 KL 散度添加到損失中,而不是像 PPO 那樣在獎(jiǎng)勵(lì)中添加 KL 懲罰項(xiàng),從而避免了復(fù)雜化 A^i,t 的計(jì)算。
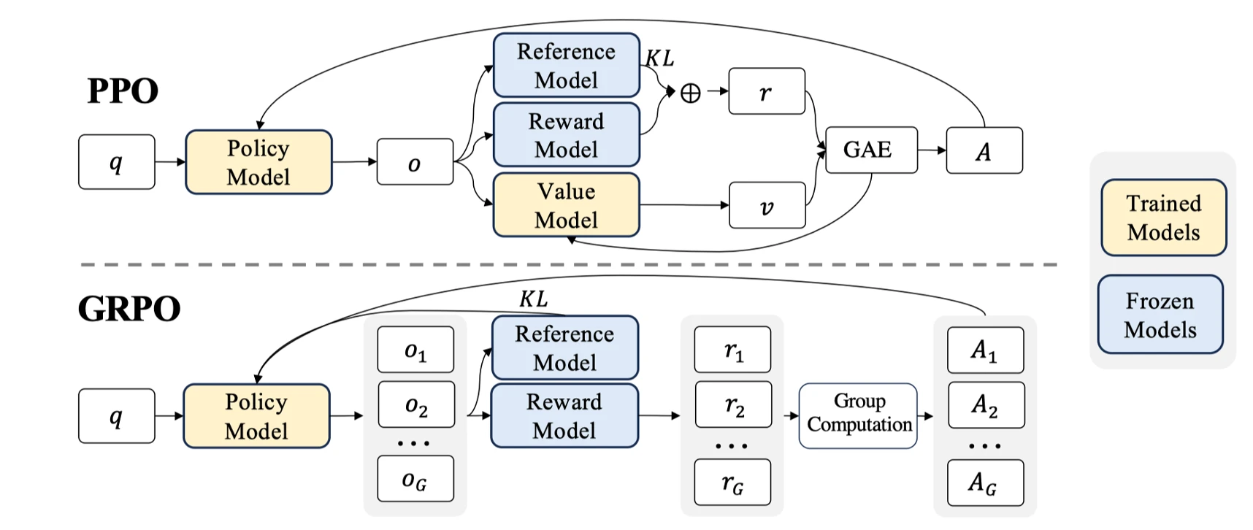
??
4.1.2 Reward Modeling
為了訓(xùn)練DeepSeek-R1-Zero,采用了一種基于規(guī)則的獎(jiǎng)勵(lì)系統(tǒng),該系統(tǒng)主要由兩種類型的獎(jiǎng)勵(lì)組成:
?準(zhǔn)確性獎(jiǎng)勵(lì):準(zhǔn)確性獎(jiǎng)勵(lì)模型評估響應(yīng)是否正確。例如,在具有確定性結(jié)果的數(shù)學(xué)問題中,模型需要以指定格式(例如,在框內(nèi))提供最終答案,從而實(shí)現(xiàn)基于規(guī)則的可靠正確性驗(yàn)證。類似地,對于 LeetCode 問題,可以使用編譯器根據(jù)預(yù)定義的測試用例生成反饋。
?格式獎(jiǎng)勵(lì):強(qiáng)制模型將其思考過程置于 ‘’ 和 ‘’ 標(biāo)簽之間。
注意, DeepSeek-R1-Zero 時(shí)沒有使用結(jié)果或過程神經(jīng)獎(jiǎng)勵(lì)模型,因?yàn)榘l(fā)現(xiàn)神經(jīng)獎(jiǎng)勵(lì)模型在大型強(qiáng)化學(xué)習(xí)過程中可能會(huì)遭受獎(jiǎng)勵(lì)黑客(reward hacking ),并且重新訓(xùn)練獎(jiǎng)勵(lì)模型需要額外的訓(xùn)練資源,這會(huì)使整個(gè)訓(xùn)練流程變得復(fù)雜。
在訓(xùn)練DeepSeek-R1階段,為了解決DeepSeek-R1-Zero中存在的語言混合問題,在RL中中引入了語言一致性獎(jiǎng)勵(lì)(language consistency reward ),該獎(jiǎng)勵(lì)計(jì)算為CoT中目標(biāo)語言詞的比例.
最后,通過將推理任務(wù)的準(zhǔn)確性和語言一致性獎(jiǎng)勵(lì)相加來形成最終獎(jiǎng)勵(lì).
4.1.3 Cold Start
與 DeepSeek-R1-Zero 不同,為了解決 RL 訓(xùn)練從基礎(chǔ)模型開始的早期不穩(wěn)定冷啟動(dòng)階段,對于 DeepSeek-R1,構(gòu)建并收集少量長 CoT 數(shù)據(jù)。為了收集此類數(shù)據(jù),用了幾種方法:使用少量樣本提示,以長 CoT 作為示例;直接提示模型生成帶有反思和驗(yàn)證的詳細(xì)答案;以可讀格式收集 DeepSeek-R1-Zero 輸出;以及通過人工標(biāo)注者進(jìn)行后處理來細(xì)化結(jié)果。
4.1.4 DeepSeek-R1訓(xùn)練的整體流程
首先對DeepSek-V3進(jìn)行RL訓(xùn)練,并采用基于規(guī)則的獎(jiǎng)勵(lì)系統(tǒng),產(chǎn)生DeepSeek-R1-Zero模型.通過提示指引DeepSeek-R1-Zero模型帶有反思和驗(yàn)證的詳細(xì)答案等Code Start數(shù)據(jù),然后將收集到的數(shù)千條冷啟動(dòng)數(shù)據(jù)重新微調(diào) DeepSeek-V3-Base 模型.接著執(zhí)行類似 DeepSeek-R1-Zero 的面向推理的強(qiáng)化學(xué)習(xí)。在強(qiáng)化學(xué)習(xí)過程接近收斂時(shí),我們通過對強(qiáng)化學(xué)習(xí)檢查點(diǎn)進(jìn)行拒絕采樣,并結(jié)合來自 DeepSeek-V3 在寫作、事實(shí)問答和自我認(rèn)知等領(lǐng)域中的監(jiān)督數(shù)據(jù),創(chuàng)建新的 SFT 數(shù)據(jù),然后再次重新訓(xùn)練 DeepSeek-V3-Base 模型,在使用新數(shù)據(jù)進(jìn)行微調(diào)后,檢查點(diǎn)會(huì)進(jìn)行額外的強(qiáng)化學(xué)習(xí)過程.(ps:二次訓(xùn)練 DeepSeek-V3是因?yàn)檫@次使用的新數(shù)據(jù)是更加優(yōu)質(zhì)的CoT數(shù)據(jù),使得訓(xùn)練完之后的模型推理性能再度提升,在這一步我真的感慨這種想法,就是一種藝術(shù)~~).經(jīng)過這些步驟,獲得了名為 DeepSeek-R1 的模型,其性能與 OpenAI-o1-1217 相當(dāng)。
??
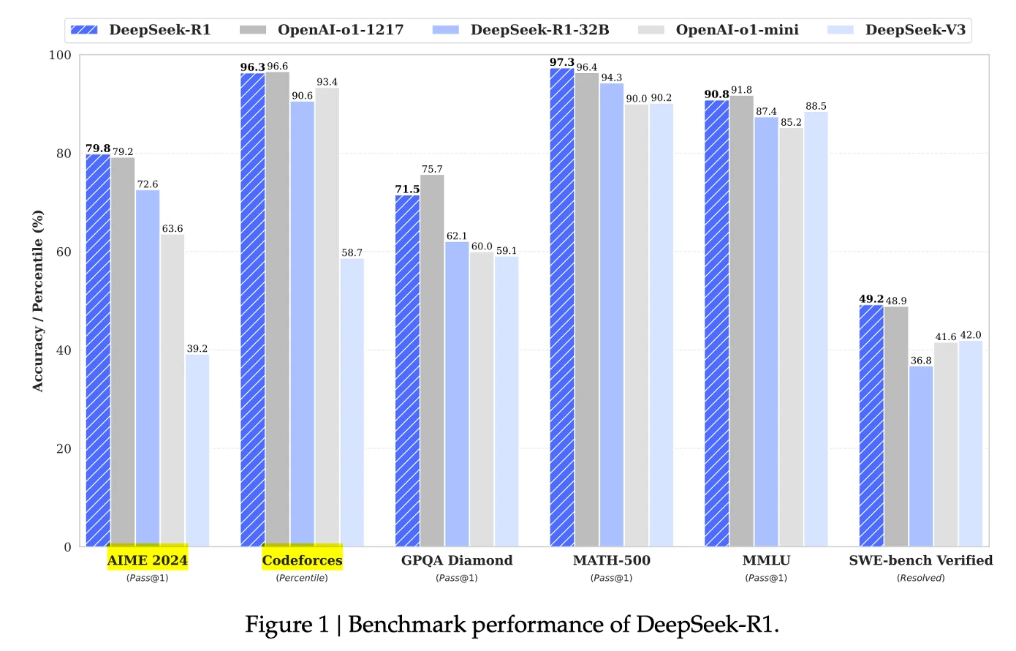
4.2 成果解讀
DeepSeek-R1 在后訓(xùn)練階段大規(guī)模使用了強(qiáng)化學(xué)習(xí)技術(shù),在僅有極少標(biāo)注數(shù)據(jù)的情況下,極大提升了模型推理能力。在數(shù)學(xué)、代碼、自然語言推理等任務(wù)上,性能比肩 OpenAI o1 正式版。
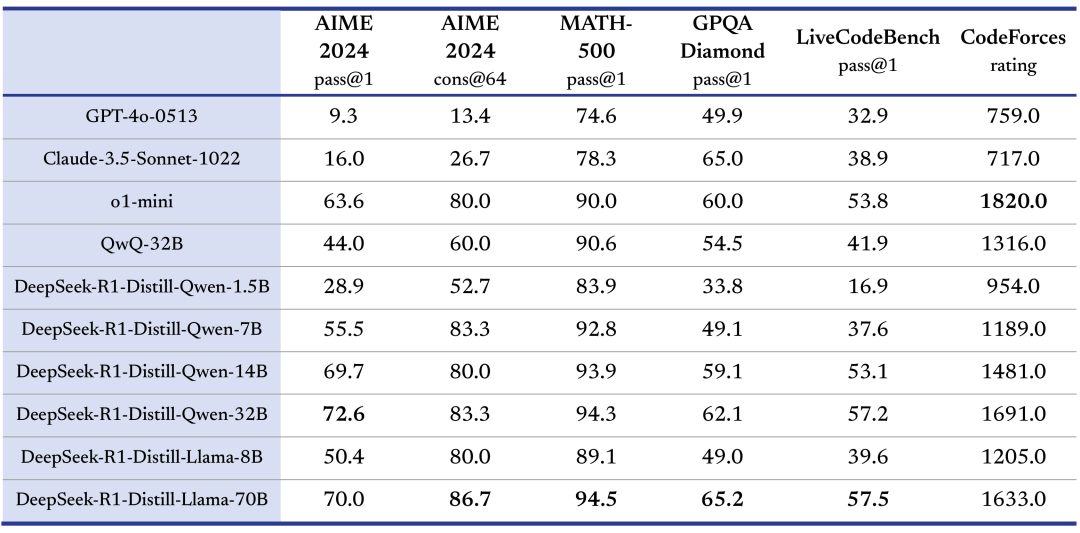
??
通過 DeepSeek-R1 的輸出,蒸餾了 6 個(gè)小模型開源給社區(qū),其中 32B 和 70B 模型在多項(xiàng)能力上實(shí)現(xiàn)了對標(biāo) OpenAI o1-mini 的效果。
??
四.結(jié)語:從大模型引發(fā)的思考
我對大模型時(shí)代的看法,我覺得我們已經(jīng)拉開了新的一幕,如果說第一幕是知識驅(qū)動(dòng)模型,卷參數(shù)量,拼算力,那么DeepSeek-R1的出現(xiàn)帶我進(jìn)入第二幕-推理驅(qū)動(dòng).在這一幕,讓模型學(xué)會(huì)自我思考,自我推理更為重要.而且更優(yōu)秀的算法來提高參數(shù)效率,降低訓(xùn)練成本也成為了關(guān)鍵所在.
最后,碼字不易,喜歡這篇文章的,請給作者點(diǎn)個(gè)贊吧,做個(gè)小小鼓勵(lì)~~
五.參考文獻(xiàn)
1. DeepSeek
2. DeepSeek中用到的Grouped-Query Attention技術(shù)是什么來頭
3. 10分鐘速通DeepSeekV1~V3核心技術(shù)點(diǎn)
4. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
5. Multi-Head Latent Attention (MLA) 詳細(xì)介紹
6. 一文通透DeepSeek V2——通俗理解多頭潛在注意力MLA:改進(jìn)MHA,從而壓縮KV緩存,提高推理速度
7. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
8. DeepSeekV3 Technical Report
審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
88文章
34406瀏覽量
275680 -
開源
+關(guān)注
關(guān)注
3文章
3623瀏覽量
43527 -
大模型
+關(guān)注
關(guān)注
2文章
3045瀏覽量
3857 -
DeepSeek
+關(guān)注
關(guān)注
1文章
782瀏覽量
1412
發(fā)布評論請先 登錄
如何使用OpenVINO運(yùn)行DeepSeek-R1蒸餾模型

了解DeepSeek-V3 和 DeepSeek-R1兩個(gè)大模型的不同定位和應(yīng)用選擇
RK3588開發(fā)板上部署DeepSeek-R1大模型的完整指南
【書籍評測活動(dòng)NO.62】一本書讀懂 DeepSeek 全家桶核心技術(shù):DeepSeek 核心技術(shù)揭秘
解讀“領(lǐng)跑者”認(rèn)證計(jì)劃
LED筒燈怎么申請GB30255-2019能效領(lǐng)跑者標(biāo)識?
【開源硬件黃金時(shí)代】開源運(yùn)動(dòng)浪潮:從軟件到硬件(文中課件可下載)
對標(biāo)OpenAI o1,DeepSeek-R1發(fā)布
AIBOX 全系產(chǎn)品已適配 DeepSeek-R1

DeepSeek V3/R1架構(gòu)解讀:探討其是否具有國運(yùn)級創(chuàng)新

OpenAI O3與DeepSeek R1:推理模型性能深度分析
開源大模型DeepSeek的開放內(nèi)容詳析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論