 在英特爾酷睿Ultra AI PC上用NPU部署YOLOv11與YOLOv12
在英特爾酷睿Ultra AI PC上用NPU部署YOLOv11與YOLOv12

作者:
顏國進 英特爾邊緣計算創新大使
最新的英特爾 酷睿 Ultra 處理器(第二代)讓我們能夠在臺式機、移動設備和邊緣中實現大多數 AI 體驗,將 AI 加速提升到新水平,在 AI 時代為邊緣計算提供動力。英特爾 酷睿 Ultra 處理器提供了一套全面的專為 AI 定制的集成計算引擎,包括 CPU、GPU 和 NPU,提供高達 99 總平臺 TOPS。近期,YOLO系列模型發布了YOLOv12, 對 YOLO 框架進行了全面增強,特別注重集成注意力機制,同時又不犧牲 YOLO 模型所期望的實時處理能力,是 YOLO 系列的一次進化,突破了人工視覺的極限。
本文中,我們將使用英特爾 酷睿 Ultra 處理器AI PC設備,結合OpenVINO C# API 使用最新發布的OpenVINO 2025.0 部署YOLOv11 和 YOLOv12 目標檢測模型,并在AIPC設備上,進行速度測試:
OpenVINO C# API項目鏈接:
https://github.com/guojin-yan/OpenVINO-CSharp-API.git
本文使用的項目源碼鏈接為:
https://github.com/guojin-yan/YoloDeployCsharp/blob/yolov1/demo/yolo_openvino_demo/
1前言
1.1 英特爾 酷睿 Ultra 處理器(第二代)
全新英特爾 酷睿 Ultra 200V系列處理器對比上代 Ultra 100,升級了模塊化結構、封裝工藝,采用全新性能核與能效核、英特爾硬件線程調度器、Xe2微架構銳炫GPU、第四代NPU…由此也帶來了CPU性能提升18%,GPU性能提升30%,整體功耗降低50%,以及120TOPS平臺AI算力。
酷睿Ultra 200V系列處理器共有9款SKU,包括1款酷睿Ultra 9、4款酷睿Ultra 7以及4款酷睿Ultra 5,全系8核心8線程(4個性能核與4個能效核),具體規格如下:
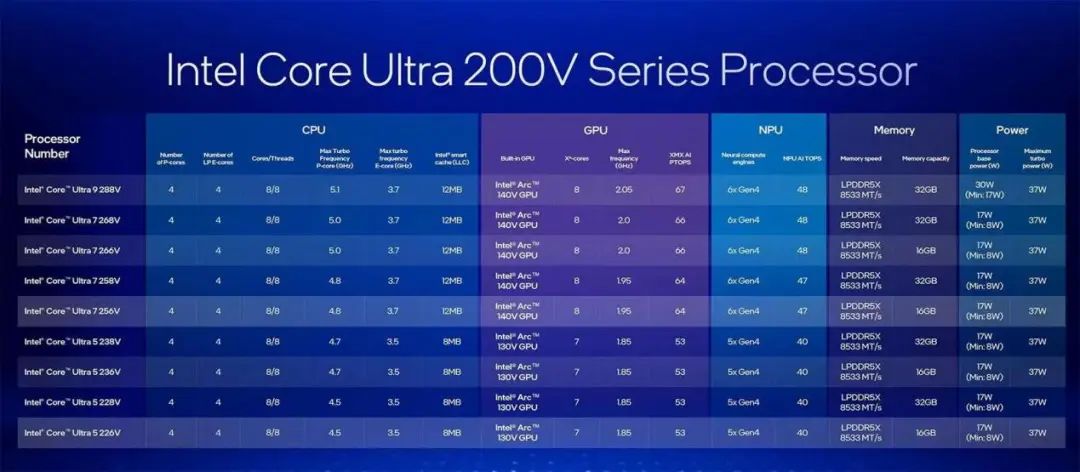
作為新一代旗艦,酷睿Ultra 9 288V性能核頻率最高5.1GHz、能效核頻率最高3.7GHz,擁有12MB三級緩存。GPU方面,集成銳炫140V顯卡,擁有8個全新Xe2核心、8個光線追蹤單元,頻率最高2.05GHz,可以實現67TOPSAI算力。而NPU集成6個第四代神經計算引擎,AI算力提升至48TOPS。
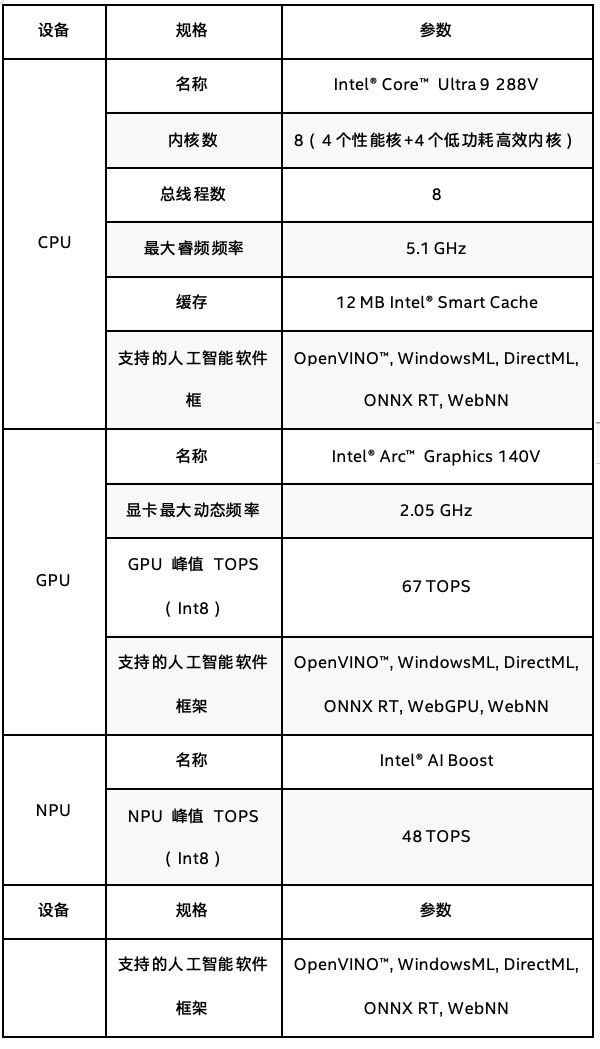
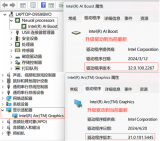
在當前項目測試,使用的是英特爾 酷睿 Ultra 9 288V設備,處理器信息如下表所示:
1.2 OpenVINO C# API
英特爾發行版 OpenVINO 工具套件基于 oneAPI 而開發,可以加快高性能計算機視覺和深度學習視覺應用開發速度工具套件,適用于從邊緣到云的各種英特爾平臺上,幫助用戶更快地將更準確的真實世界結果部署到生產系統中。通過簡化的開發工作流程,OpenVINO 可賦能開發者在現實世界中部署高性能應用程序和算法。
OpenVINO 2025.0版本在生成式AI和硬件支持方面實現了多項重大突破。生成式AI推理速度大幅提升,特別是Whisper語音模型和圖像修復技術的加速,讓AI應用的實時性和效率得到顯著改善。同時,新增支持Qwen 2.5和DeepSeek-R1等中文大模型,優化了長文本處理和7B模型的推理吞吐量。在硬件方面,新一代酷睿Ultra和Xeon處理器帶來了更強的FP16推理能力,同時OpenVINO還推出了全球首個支持torch.compile的NPU后端,提升了異構計算能力。GPU優化和Windows Server原生支持也讓硬件性能得到更大釋放,邊緣計算領域的優化使IoT設備能效大幅提高。
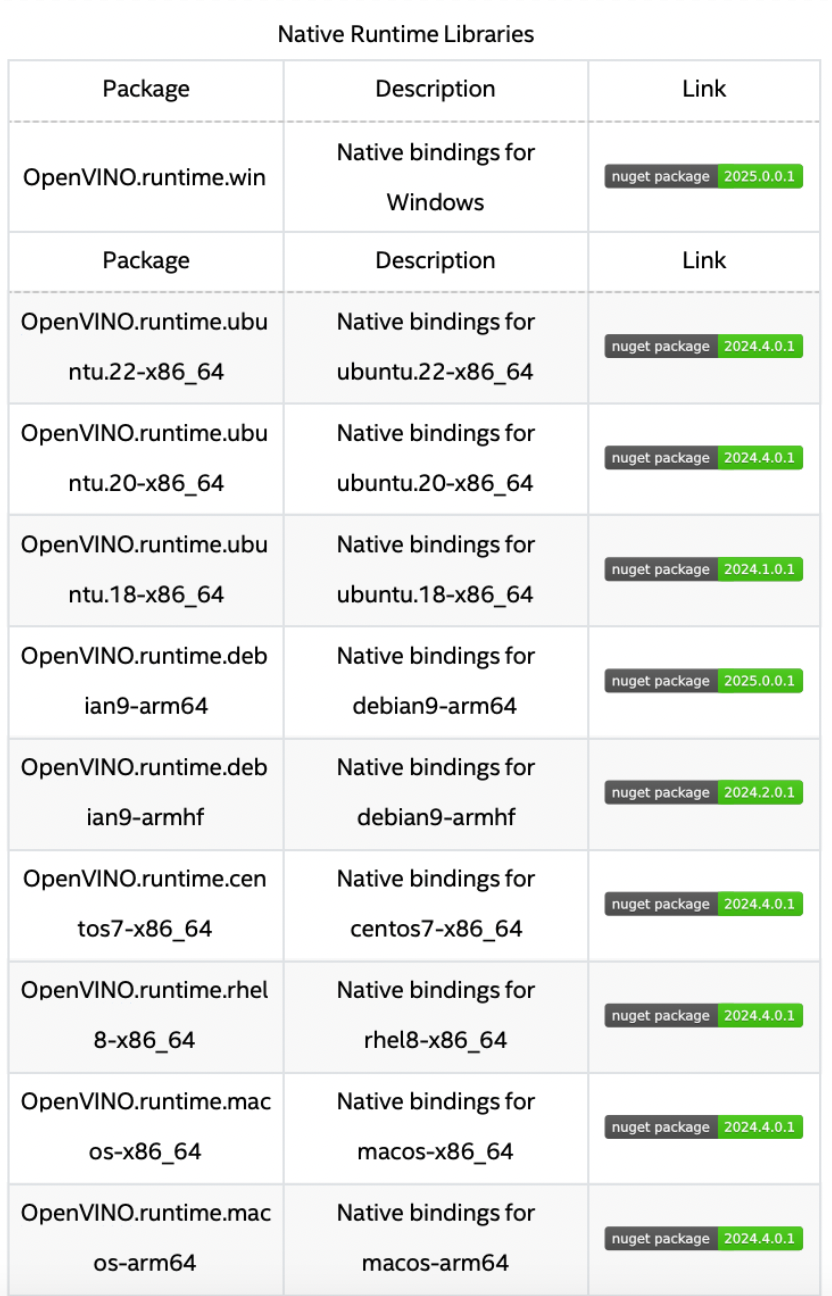
OpenVINO C# API 是一個 OpenVINO 的 .Net wrapper,應用最新的 OpenVINO 庫開發,通過 OpenVINO C API 實現 .Net 對 OpenVINO Runtime 調用,使用習慣與 OpenVINO C++ API 一致。OpenVINO C# API 由于是基于 OpenVINO 開發,所支持的平臺與 OpenVINO 完全一致,具體信息可以參考 OpenVINO。通過使用 OpenVINO C# API,可以在 .NET、.NET Framework等框架下使用 C# 語言實現深度學習模型在指定平臺推理加速。
下表為當前發布的 OpenVINO C# API NuGet Package,支持多個目標平臺,可以通過NuGet一鍵安裝所有依賴。

1.3 YOLOv11與YOLOv12
YOLO系列目標檢測模型自2016年提出以來,始終以"實時檢測"為核心優勢,通過端到端架構和網格化預測思想,在目標檢測領域持續引領技術革新。從YOLOv1的7x7網格基礎框架,到YOLOv8的骨干網絡優化,再到YOLOv10的C3K2模塊創新,該系列通過特征提取增強、后處理優化和計算效率提升,不斷突破速度與精度的平衡極限。
YOLOv11特色由Ultralytics公司開發,通過改進CSPNet主干網絡和頸部架構,實現參數精簡與精度提升的雙重突破。其核心創新在于:
增強型特征提取:采用跨階段特征融合技術,在復雜場景中捕捉細微目標特征
動態計算優化:通過自適應計算分配策略,在保持45ms推理速度的同時,mAP提升3.2%
輕量化設計:相比YOLOv8減少18%參數量,更適合邊緣設備部署
YOLOv12的開發人員通過其最新模型在開創性版本中樹立了計算機視覺領域的新標準。YOLOv12 以其無與倫比的速度、準確性和多功能性而聞名,是 YOLO 系列的一次進化,突破了人工視覺的極限。YOLOv12 對 YOLO 框架進行了全面增強,特別注重集成注意力機制,同時又不犧牲 YOLO 模型所期望的實時處理能力。
以注意力為中心的設計:YOLOv12 具有區域注意力模塊,該模塊通過分割特征圖來保持效率,將計算復雜度降低一半,同時使用 FlashAttention 來緩解實時檢測的內存帶寬限制。
分層結構:該模型采用殘差高效層聚合網絡(R-ELAN)來優化特征集成并減少梯度阻塞,并簡化了最后階段以實現更輕、更快的架構。
架構增強:通過用 7x7 可分離卷積取代傳統位置編碼,YOLOv12 有效地保留了位置信息。自適應 MLP 比率可以更好地分配計算資源,在實時約束下支持多樣化數據集。
訓練和優化:該模型使用 SGD 和自定義學習計劃訓練了 600 多個時期,實現了高精度。它采用 Mosaic 和 Mixup 等數據增強技術來提高泛化能力,從而提升了 YOLOv12 快速、準確檢測物體的能力。
兩代模型分別代表了YOLO系列在傳統架構優化與新型注意力機制融合兩個方向的最新突破,其中YOLOv12更開創性地將Transformer優勢融入實時檢測框架,標志著該系列進入"注意力增強"新階段。
2模型獲取
2.1 配置環境
安裝模型下載以及轉換環境,此處使用Anaconda進行程序集管理,輸入以下指令創建一個yolo環境:
conda create -n yolo python=3.10 conda activate yolo pip install ultralytics
2.2 下載并轉換ONNX模型
首先導出目標識別模型,此處以官方預訓練模型為例,目前ultralytics已經集成了,依次輸入以下指令即可:
yolo export model=yolo11s.pt format=onnx
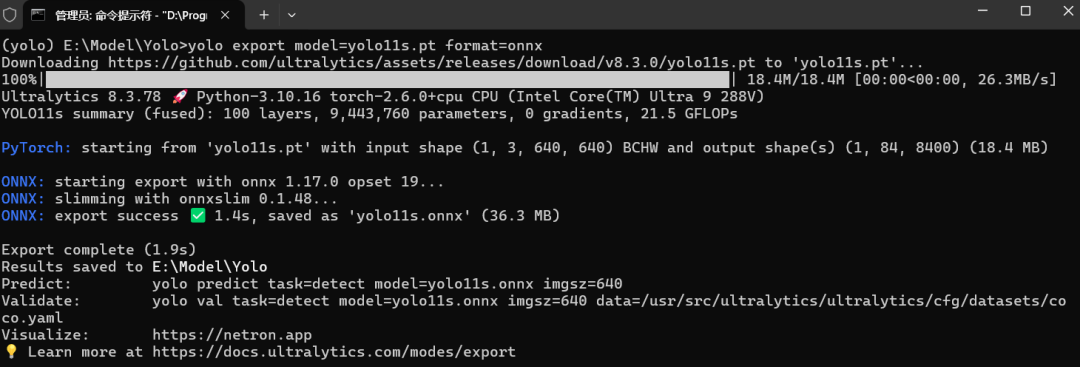
目前OpenVINO支持直接調用ONNX模型,因此此處只導出ONNX模型即可,如需要導出OpenVINO格式的模型,可以參考OpenVINO官方文檔。
3Yolo 項目配置
3.1 項目創建與環境配置
在Windows平臺開發者可以使用Visual Studio平臺開發程序,但無法跨平臺實現,為了實現跨平臺,此處采用dotnet指令進行項目的創建和配置。
首先使用dotnet創建一個測試項目,在終端中輸入一下指令:
dotnet new console --framework net8.0 --use-program-main -o yolo_sample
此處以Windows平臺為例安裝項目依賴,首先是安裝OpenVINO C# API項目依賴,在命令行中輸入以下指令即可:
dotnet add package OpenVINO.CSharp.API dotnet add package OpenVINO.runtime.win dotnet add package OpenVINO.CSharp.API.Extensions dotnet add package OpenVINO.CSharp.API.Extensions.OpenCvSharp
關于在不同平臺上搭建 OpenVINO C# API 開發環境請參考以下文章:
在Windows上搭建OpenVINOC#開發環境
https://github.com/guojin-yan/OpenVINO-CSharp-API/blob/csharp3.1/docs/inatall/Install_OpenVINO_CSharp_Windows_cn.md
在Linux上搭建OpenVINOC#開發環境
https://github.com/guojin-yan/OpenVINO-CSharp-API/blob/csharp3.1/docs/inatall/Install_OpenVINO_CSharp_Linux_cn.md
在MacOS上搭建OpenVINOC#開發環境
https://github.com/guojin-yan/OpenVINO-CSharp-API/blob/csharp3.1/docs/inatall/Install_OpenVINO_CSharp_MacOS_cn.md
接下來安裝使用到的圖像處理庫 OpenCvSharp,在命令行中輸入以下指令即可:
dotnet add package OpenCvSharp4 dotnet add package OpenCvSharp4.Extensions dotnet add package OpenCvSharp4.runtime.win
關于在其他平臺上搭建 OpenCvSharp 開發環境請參考以下文章:
【OpenCV】在Linux上使用OpenCvSharp
https://mp.weixin.qq.com/s/z6ahGWlkaQs3pUtN15Lzpg
【OpenCV】在MacOS上使用OpenCvSharp
https://mp.weixin.qq.com/s/8njRodtg7lRMggBfpZDHgw
添加完成項目依賴后,項目的配置文件如下所示:
Exe net8.0 enable enable
3.2 定義模型預測方法
使用 OpenVINO C# API 部署模型主要包括以下幾個步驟:
初始化 OpenVINO Runtime Core
讀取本地模型(將圖片數據預處理方式編譯到模型)
將模型編譯到指定設備
創建推理通道
處理圖像輸入數據
設置推理輸入數據
模獲取推理結果
處理結果數據
按照 OpenVINO C# API 部署深度學習模型的步驟,編寫YOLOv10模型部署流程,在之前的項目里,我們已經部署了YOLOv5~9等一系列模型,其部署流程是基本一致的,YOLOv10模型部署代碼如下所示:
internal class YoloDet
{
public static void predict(string model_path, string image_path, string device)
{
DateTime start = DateTime.Now;
// -------- Step 1. Initialize OpenVINO Runtime Core --------
Core core = new Core();
DateTime end = DateTime.Now;
Console.WriteLine("1. Initialize OpenVINO Runtime Core success, time spend: " + (end - start).TotalMilliseconds + "ms.");
// -------- Step 2. Read inference model --------
start = DateTime.Now;
Model model = core.read_model(model_path);
end = DateTime.Now;
Console.WriteLine("2. Read inference model success, time spend: " + (end - start).TotalMilliseconds + "ms.");
// -------- Step 3. Loading a model to the device --------
start = DateTime.Now;
CompiledModel compiled_model = core.compile_model(model, device);
end = DateTime.Now;
Console.WriteLine("3. Loading a model to the device success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 4. Create an infer request --------
start = DateTime.Now;
InferRequest infer_request = compiled_model.create_infer_request();
end = DateTime.Now;
Console.WriteLine("4. Create an infer request success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 5. Process input images --------
start = DateTime.Now;
Mat image = new Mat(image_path); // Read image by opencvsharp
int max_image_length = image.Cols > image.Rows ? image.Cols : image.Rows;
Mat max_image = Mat.Zeros(new OpenCvSharp.Size(max_image_length, max_image_length), MatType.CV_8UC3);
Rect roi = new Rect(0, 0, image.Cols, image.Rows);
image.CopyTo(new Mat(max_image, roi));
float factor = (float)(max_image_length / 640.0);
end = DateTime.Now;
Console.WriteLine("5. Process input images success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 6. Set up input data --------
start = DateTime.Now;
Tensor input_tensor = infer_request.get_input_tensor();
Shape input_shape = input_tensor.get_shape();
Mat input_mat = CvDnn.BlobFromImage(max_image, 1.0 / 255.0, new OpenCvSharp.Size(input_shape[2], input_shape[3]), new Scalar(), true, false);
float[] input_data = new float[input_shape[1] * input_shape[2] * input_shape[3]];
Marshal.Copy(input_mat.Ptr(0), input_data, 0, input_data.Length);
input_tensor.set_data(input_data);
end = DateTime.Now;
Console.WriteLine("6. Set up input data success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 7. Do inference synchronously --------
infer_request.infer();
start = DateTime.Now;
infer_request.infer();
end = DateTime.Now;
Console.WriteLine("7. Do inference synchronously success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 8. Get infer result data --------
start = DateTime.Now;
Tensor output_tensor = infer_request.get_output_tensor();
int output_length = (int)output_tensor.get_size();
float[] output_data = output_tensor.get_data(output_length);
end = DateTime.Now;
Console.WriteLine("8. Get infer result data success, time spend:" + (end - start).TotalMilliseconds + "ms.");
// -------- Step 9. Process reault --------
start = DateTime.Now;
// Storage results list
List position_boxes = new List();
List class_ids = new List();
List confidences = new List();
// Preprocessing output results
for (int i = 0; i < 8400; i++)
? ? ? ?{
? ? ? ? ? ?for (int j = 4; j < 84; j++)
? ? ? ? ? ?{
? ? ? ? ? ? ? ?float conf = output_data[8400 * j + i];
? ? ? ? ? ? ? ?int label = j - 4;
? ? ? ? ? ? ? ?if (conf > 0.2)
{
float cx = output_data[8400 * 0 + i];
float cy = output_data[8400 * 1 + i];
float ow = output_data[8400 * 2 + i];
float oh = output_data[8400 * 3 + i];
int x = (int)((cx - 0.5 * ow) * factor);
int y = (int)((cy - 0.5 * oh) * factor);
int width = (int)(ow * factor);
int height = (int)(oh * factor);
Rect box = new Rect(x, y, width, height);
position_boxes.Add(box);
class_ids.Add(label);
confidences.Add(conf);
}
}
}
// NMS non maximum suppression
int[] indexes = new int[position_boxes.Count];
CvDnn.NMSBoxes(position_boxes, confidences, 0.5f, 0.5f, out indexes);
end = DateTime.Now;
Console.WriteLine("9. Process reault success, time spend:" + (end - start).TotalMilliseconds + "ms.");
for (int i = 0; i < indexes.Length; i++)
? ? ? ?{
? ? ? ? ? ?int index = indexes[i];
? ? ? ? ? ?Cv2.Rectangle(image, position_boxes[index], new Scalar(0, 0, 255), 2, LineTypes.Link8);
? ? ? ? ? ?Cv2.Rectangle(image, new OpenCvSharp.Point(position_boxes[index].TopLeft.X, position_boxes[index].TopLeft.Y + 30),
? ? ? ? ? ? ? ?new OpenCvSharp.Point(position_boxes[index].BottomRight.X, position_boxes[index].TopLeft.Y), new Scalar(0, 255, 255), -1);
? ? ? ? ? ?Cv2.PutText(image, class_ids[index] + "-" + confidences[index].ToString("0.00"),
? ? ? ? ? ? ? ?new OpenCvSharp.Point(position_boxes[index].X, position_boxes[index].Y + 25),
? ? ? ? ? ? ? ?HersheyFonts.HersheySimplex, 0.8, new Scalar(0, 0, 0), 2);
? ? ? ?}
? ? ? ?string output_path = Path.Combine(Path.GetDirectoryName(Path.GetFullPath(image_path)),
? ? ? ? ? ?Path.GetFileNameWithoutExtension(image_path) + "_result.jpg");
? ? ? ?Cv2.ImWrite(output_path, image);
? ? ? ?Console.WriteLine("The result save to " + output_path);
? ? ? ?Cv2.ImShow("Result", image);
? ? ? ?Cv2.WaitKey(0);
? ?}
}
接下來就是在C#static void Main(string[] args)方法里調用該方法,調用代碼如下所示:
YoloDet.predict("E:/Model/Yolo/yolo11x.onnx", "./demo_2.jpg", "NPU");
YoloDet.predict("E:/Model/Yolo/yolo12x.onnx", "./demo_2.jpg", "CPU");
4項目編譯和運行
4.1 項目編譯和運行
接下來輸入項目編譯指令進行項目編譯,輸入以下指令即可:
dotnet build
接下來運行編譯后的程序文件,在CMD中輸入以下指令,運行編譯后的項目文件:
dotnet run --no-build
4.2 模型推理效果
下面分別使用x格式的模型演示YOLOv11和YOLOv12模型運行結果:
首先是YOLOv11x模型推理效果,如下圖所示
下面是YOLOv12x模型推理效果,如下圖所示:
5YOLO系列模型推理性能表現
下面四個表格通過對YOLOv8、YOLOv11和YOLOv12系列模型在英特爾 酷睿 Ultra 9 288V處理器上推理速度的對比分析,我們可以看到它們在CPU、NPU和GPU平臺上的表現差異。下面將詳細描述每個系列在不同硬件平臺上的推理速度,并對比其性能。
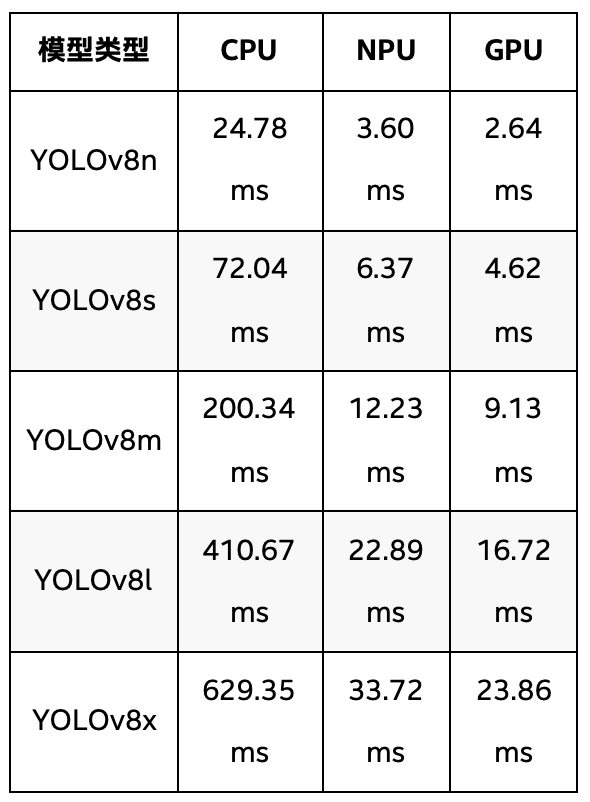
表 1 YOLOv8全系模型在英特爾 酷睿 Ultra 9 288V 處理器上推理速度
表1列出了YOLOv8全系模型的推理時間,在YOLOv8系列中,隨著模型復雜度的增加,推理時間也隨之增長。在CPU上,YOLOv8n(最小模型)需要24.78ms,YOLOv8x(最大模型)則達到629.35ms,推理時間大幅增加。在NPU上,YOLOv8n的推理時間為3.60ms,YOLOv8x則為33.72ms。GPU上,YOLOv8n的推理時間最短,僅為2.64ms,而YOLOv8x則為23.86ms。可以看出,YOLOv8系列在NPU和GPU加速下的表現非常優越,特別是YOLOv8n和YOLOv8s,它們在GPU上的推理時間僅為2.64ms和4.62ms,顯示了YOLOv8系列在加速硬件上的高效性。
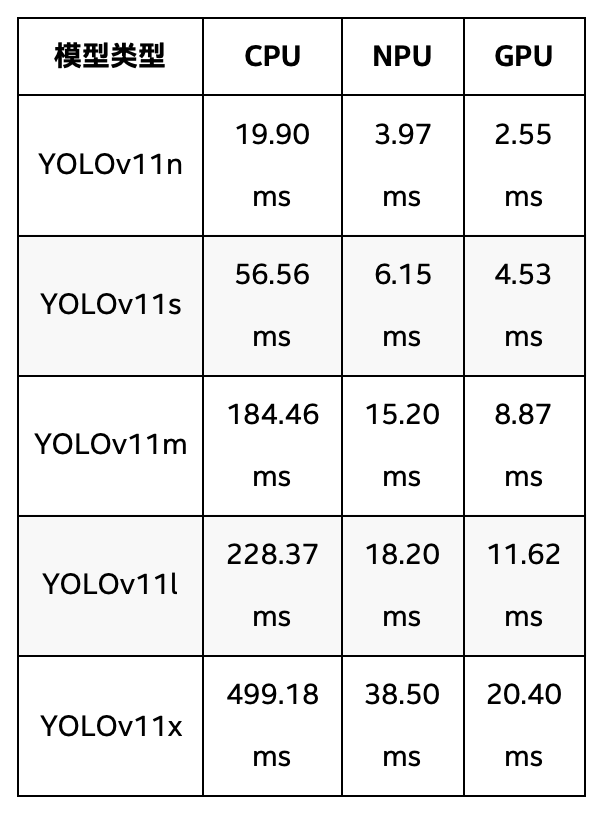
表 2 YOLOv11全系模型在英特爾 酷睿 Ultra 9 288V 處理器上推理速度
表2介紹了YOLOv11系列,YOLOv11系列的推理時間相較于YOLOv8系列較長,尤其是在CPU上。YOLOv11n在CPU上的推理時間為19.90ms,相比YOLOv8n的24.78ms稍快;但隨著模型復雜度增加,YOLOv11x的CPU推理時間為499.18ms,依然長于YOLOv8x的629.35ms。NPU加速方面,YOLOv11n的推理時間為3.97ms,YOLOv11x為38.50ms,雖然NPU加速顯著提升了推理速度,但整體表現遜色于YOLOv8系列。GPU方面,YOLOv11n在GPU上為2.55ms,YOLOv11x為20.40ms,也表現得相對較慢。
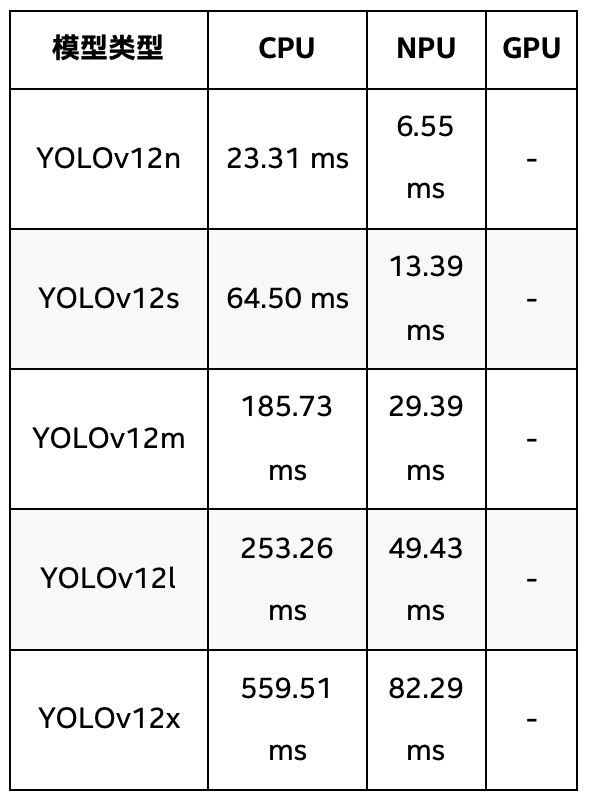
表 3 YOLOv12全系模型在英特爾 酷睿 Ultra 9 288V 處理器上推理速度
YOLOv12系列的推理時間在所有系列中表現較慢,尤其是在CPU上。YOLOv12n的推理時間為23.31ms,相比YOLOv8n和YOLOv11n都略長,而YOLOv12x的推理時間為559.51ms,明顯比其他系列的最大模型更慢。在NPU上,YOLOv12n的推理時間為6.55ms,YOLOv12x為82.29ms,雖然在NPU加速下,推理速度有所提升,但相對其他系列仍然較慢。YOLOv12系列在推理速度方面的表現整體較為遜色,特別是在沒有GPU加速的情況下。
從推理速度的整體表現來看,YOLOv8系列無疑是表現最好的。YOLOv8在NPU和GPU加速下的推理速度非常高效,尤其是在YOLOv8n和YOLOv8s這兩個小型模型上,其推理時間明顯優于YOLOv11和YOLOv12系列,且在GPU和NPU加速下依然保持較短的推理時間。相比之下,YOLOv11系列的表現略遜,雖然NPU加速有助于提升推理速度,但整體推理時間仍然較長。
YOLOv12系列則在推理時間上表現最差,尤其是在沒有GPU加速的情況下,其推理時間遠高于YOLOv8和YOLOv11系列。
6總結
英特爾 酷睿 Ultra 處理器憑借其出色的性能和高效的能耗管理,內置的高算力顯卡及神經計算單元(功耗約2W),是深度學習和計算機視覺應用的理想選擇。通過結合OpenVINO 工具套件和YOLOv11、YOLOv12等先進模型,我們可以顯著提升推理性能,并確保在不同計算單元上高效運行。
本文介紹了如何配置開發環境、使用C# API進行模型部署,以及如何利用處理器的優勢優化應用程序性能。隨著AI技術的不斷發展,英特爾的硬件和軟件工具將繼續為開發者提供更強大的支持,推動人工智能在各個領域的應用與創新。希望通過本文的學習,讀者能夠在實際項目中靈活運用這些技術,實現更高效、更智能的解決方案。
-
處理器
+關注
關注
68文章
19896瀏覽量
235244 -
英特爾
+關注
關注
61文章
10196瀏覽量
174690 -
PC
+關注
關注
9文章
2152瀏覽量
156550 -
酷睿
+關注
關注
2文章
437瀏覽量
36875
原文標題:開發者實戰|在英特爾? 酷睿? Ultra AI PC上用NPU部署YOLOv11與YOLOv12
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
開啟AI PC新紀元!英特爾酷睿Ultra重磅發布,勝任200億參數大語言模型

為什么在Ubuntu20.04上使用YOLOv3比Yocto操作系統上的推理快?
yolov7 onnx模型在NPU上太慢了怎么解決?
在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

在英特爾酷睿Ultra處理器上優化和部署YOLOv8模型
如何將Llama3.1模型部署在英特爾酷睿Ultra處理器

在英特爾AIPC上利用LabVIEW與YOLOv11實現目標檢測
在英特爾酷睿Ultra AI PC上部署多種圖像生成模型






 工商網監
工商網監
評論