") AXI握手時序優(yōu)化—pipeline緩沖器
AXI握手時序優(yōu)化—pipeline緩沖器

skid buffer(pipeline緩沖器)介紹
??解決ready/valid兩路握手的時序困難,使路徑流水線化。
??只關(guān)心valid時序參考這篇寫得很好的博客鏈接:握手協(xié)議(pvld/prdy或者valid-ready或AXI)中Valid及data打拍技巧;只關(guān)心ready時序修復(fù)可以參考同作者這篇文章鏈接:(AXI)握手協(xié)議(pvld/prdy或者valid-ready)中ready打拍技巧
??一個skid buffer是最小的Pipeline FIFO Buffer,只有兩個入口。當(dāng)您需要在發(fā)送者和接收者之間為并發(fā)和/或定時流水線化路徑時,它很有用,但不能消除數(shù)據(jù)速率不匹配。它還只需要兩個數(shù)據(jù)寄存器,在這個規(guī)模上比LUT RAM或Block RAM小(取決于實現(xiàn)),并且具有更大的布局和布線自由度。
背景
??片上網(wǎng)絡(luò) (NoC) 和pipeline具有作為基本構(gòu)建塊的握手機制,其中鏈路的每一端都可以發(fā)出信號,如果它們有數(shù)據(jù)要發(fā)送(“valid”),或者它們是否能夠接收數(shù)據(jù)(“ready”)。當(dāng)兩端一致(有效且均為高電平)時,在該時鐘周期發(fā)生數(shù)據(jù)傳輸。
?? 但是,流水線握手更復(fù)雜:1.如果直接將valid、ready和data流水線寄存是可以工作的,但是每次傳輸需要兩個周期開始,兩個周期停止。如果每次握手只傳輸一個數(shù)據(jù)塊,這在帶寬利用方面還不錯。但是現(xiàn)在接收器必須知道它和發(fā)送器之間存在多少管道階段,才能有足夠的內(nèi)部緩沖數(shù)據(jù)(在它發(fā)出不再準(zhǔn)備好接收更多數(shù)據(jù)的信號后,吸收不斷到達(dá)的數(shù)據(jù),因為說了ready要過一拍才能傳上去)。
??這是基于信用的連接的基礎(chǔ)(不在這里討論),它可以最大化帶寬,但是如果只需要在兩端之間添加單個pipe階段,而無需修改master/slave,只是滿足時序或允許每一端發(fā)送一項數(shù)據(jù)而不必等待打拍的延遲響應(yīng)(因此重疊通信,這是可取的)。
需求與模塊定義
??為了開始設(shè)計一個pipeline緩沖器,讓我們想象一個可以執(zhí)行valid/ready握手并接收輸入數(shù)據(jù)的單元,輸出執(zhí)行相同的握手以輸出數(shù)據(jù)。

??理想情況下,輸入和輸出接口同時握手以獲得最大帶寬:即在相同的時鐘周期內(nèi),輸入接口接收到新的數(shù)據(jù)并將其放入內(nèi)部寄存器中;此時該寄存器同時在輸出接口被握手讀出。但是,如果輸出接口在給定周期內(nèi)沒有發(fā)送數(shù)據(jù),則輸入接口在該周期內(nèi)也不能輸入數(shù)據(jù),否則舊數(shù)據(jù)將被覆蓋。為避免此問題,上游輸入邊的ready接口應(yīng)該在下游輸出端ready未就緒的同一周期中聲明自己未就緒。但這形成了它們之間的直接組合連接,而不是流水線連接。
??為了解決這個矛盾,我們需要一個額外的緩沖buffer來保存數(shù)據(jù),此時輸入接口正在獲取數(shù)據(jù)但輸出接口沒有發(fā)送數(shù)據(jù)的情況,并且pipeline寄存器中已經(jīng)有數(shù)據(jù)。然后,在下一個周期,輸入接口可以發(fā)出信號它不再準(zhǔn)備好,并且沒有數(shù)據(jù)丟失。我們可以想象這個額外的緩沖buffer允許輸入接口“延遲一拍”停止,而不是立即停止(與ready打一拍同步了),解決了之前的問題。
下面展示一些內(nèi)聯(lián)代碼片。
`default_nettype none
module Pipeline_Skid_Buffer
#(
parameter WORD_WIDTH = 0
)
(
input wire clock,
input wire clear,
input wire input_valid,
output wire input_ready,
input wire [WORD_WIDTH-1:0] input_data,
output wire output_valid,
input wire output_ready,
output wire [WORD_WIDTH-1:0] output_data
);
localparam WORD_ZERO = {WORD_WIDTH{1'b0}};
數(shù)據(jù)路徑
??數(shù)據(jù)路徑的作用:在Buffer有數(shù)據(jù)時從buffer送數(shù)據(jù)給pipeline寄存器(輸出數(shù)據(jù)寄存器),沒有數(shù)據(jù)時從輸入數(shù)據(jù)寄存。
??注意到,我們選擇了將不同輸入數(shù)據(jù)到單個輸出寄存器(pipeline寄存器)的方案,而不是在兩個相同的輸出寄存器后加入MUX選通,從而避免新的單元和路徑延遲。單個輸出寄存器還能在下游繼續(xù)重定時優(yōu)化時序。
??選通的初始默認(rèn)值為選通輸入數(shù)據(jù)寄存,即認(rèn)為buffer的“空”狀態(tài)。因此默認(rèn)情況下,第一個到達(dá)的數(shù)據(jù)最終一定會直接給到pipeline寄存器。我們不必?fù)?dān)心此時選通信號的狀態(tài)。
reg data_buffer_wren = 1'b0; // EMPTY at start, so don't load.
wire [WORD_WIDTH-1:0] data_buffer_out;
Register
#(
.WORD_WIDTH (WORD_WIDTH),
.RESET_VALUE (WORD_ZERO)
)
data_buffer_reg
(
.clock (clock),
.clock_enable (data_buffer_wren),
.clear (clear),
.data_in (input_data),
.data_out (data_buffer_out)
);
reg data_out_wren = 1'b1; // EMPTY at start, so accept data.
reg use_buffered_data = 1'b0;
reg [WORD_WIDTH-1:0] selected_data = WORD_ZERO;
always @(*) begin
selected_data = (use_buffered_data == 1'b1) ? data_buffer_out : input_data;
end
Register
#(
.WORD_WIDTH (WORD_WIDTH),
.RESET_VALUE (WORD_ZERO)
)
data_out_reg
(
.clock (clock),
.clock_enable (data_out_wren),
.clear (clear),
.data_in (selected_data),
.data_out (output_data)
);
控制路徑
??我們將控制路徑模塊單獨出來,因此數(shù)據(jù)路徑模塊不必知道有關(guān)當(dāng)前狀態(tài)或其編碼的任何信息。
??控制路徑為一個狀態(tài)機,此FSM假定valid/ready握手信號的通常含義和行為——當(dāng)兩者都為高電平時,數(shù)據(jù)在時鐘周期結(jié)束時傳輸。當(dāng)無法接受數(shù)據(jù)時拉高ready或在無法發(fā)送數(shù)據(jù)時拉高valid都是錯誤的。這些協(xié)議層面的錯誤并不會被處理。
??要將使用我們的控制路徑模塊來操控數(shù)據(jù)路徑用作緩沖區(qū),我們需要了解我們希望允許它處于哪些狀態(tài),以及狀態(tài)怎么轉(zhuǎn)換。該pipeline緩沖器具有三種狀態(tài):
???? 1. Empty: Buffer和pipeline寄存器是空的。
???? 2. Busy: Pipeline寄存器滿,此時等待新的數(shù)據(jù)或完成數(shù)據(jù)傳送。
???? 3. Full: buffer和pipeline寄存器全滿,必須等待pipeline寄存器及buffer都清空(將buffer加載進(jìn)pipeline寄存器),否則“延遲一拍”將不再有效。
??在這些狀態(tài)轉(zhuǎn)換時的操作是:
????a. 將數(shù)據(jù)握手后送入數(shù)據(jù)路徑的輸入接口(+)
????b. 從數(shù)據(jù)路徑中刪除數(shù)據(jù)項的輸出接口 ( -)
????c. 兩個接口同時插入和移除 ( ±)
??我們還描述性地命名了狀態(tài)之間的每個轉(zhuǎn)換。這些名稱稍后會出現(xiàn)在代碼中。
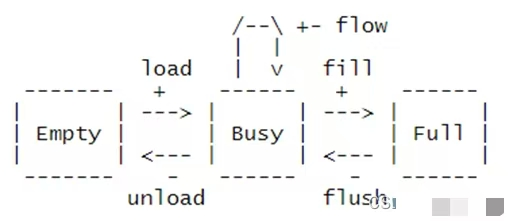
??從狀態(tài)圖轉(zhuǎn)移中我們可以看出,當(dāng)datapath為空時,只能支持寫入,而當(dāng)datapath滿時,只能支持讀出。這些限制將在以后變得非常重要。如果接口嘗試在 Empty 時讀出,或在 Full 時寫入,則數(shù)據(jù)將分別重復(fù)或丟失。
??這個簡單的 FSM 描述幫助我們澄清了問題,但它也掩蓋了實現(xiàn)時的潛在復(fù)雜性:3 個狀態(tài)中,總共兩對握手信號,每個狀態(tài)共有16個可能的組合轉(zhuǎn)換,即總共 48 種可能的狀態(tài)轉(zhuǎn)換。
??沒人會想手動枚舉所有轉(zhuǎn)換來合并等效的轉(zhuǎn)換并排除所有不可能的情況。相反,如果我們用邏輯表達(dá)我們從狀態(tài)圖中確定的刪除和插入的約束,以及數(shù)據(jù)路徑上可能的轉(zhuǎn)換,那么我們幾乎可以輕松獲得狀態(tài)轉(zhuǎn)換邏輯和數(shù)據(jù)路徑控制信號邏輯。
??讓我們描述數(shù)據(jù)路徑的可能狀態(tài),并對其進(jìn)行初始化。此代碼描述了二進(jìn)制狀態(tài)編碼,但CAD工具可以對狀態(tài)編碼進(jìn)行重新編碼和重新編號。
localparam STATE_BITS = 2;
localparam [STATE_BITS-1:0] EMPTY = 'd0; // Output and buffer registers empty
localparam [STATE_BITS-1:0] BUSY = 'd1; // Output register holds data
localparam [STATE_BITS-1:0] FULL = 'd2; // Both output and buffer registers hold data
// There is no case where only the buffer register would hold data.
// No handling of erroneous and unreachable state 3.
// We could check and raise an error flag.
wire [STATE_BITS-1:0] state;
reg [STATE_BITS-1:0] state_next = EMPTY;
??現(xiàn)在,讓我們表達(dá)我們從狀態(tài)圖中得出的約束:
???? 1. 輸入接口只能在數(shù)據(jù)路徑不處于FULL時接受數(shù)據(jù)。
???? 2. 只有當(dāng)數(shù)據(jù)路徑不為Empty時,輸出接口才能讀出數(shù)據(jù)。
??我們通過根據(jù)數(shù)據(jù)路徑FSM的狀態(tài)計算允許的讀出時的valid/ready握手信號。我們使用state_next所以我們可以有很好的寄存器輸出。這段代碼刪掉了大量無效的狀態(tài)轉(zhuǎn)換。
??這段代碼很關(guān)鍵,因為它還暗示了pipeline緩沖區(qū)的基本操作假設(shè):上游接口的當(dāng)前狀態(tài)不能依賴于下游接口的當(dāng)前狀態(tài),否則會有組合路徑也就起不到時序優(yōu)化。
??計算上游的ready信號(非滿不寫)。
Register
#(
.WORD_WIDTH (1),
.RESET_VALUE (1'b1) // EMPTY at start, so accept data
)
input_ready_reg
(
.clock (clock),
.clock_enable (1'b1),
.clear (clear),
.data_in (state_next != FULL),
.data_out (input_ready)
);
??計算下游的valid信號(非空可讀)。
Register
#(
.WORD_WIDTH (1),
.RESET_VALUE (1'b0)
)
output_valid_reg
(
.clock (clock),
.clock_enable (1'b1),
.clear (clear),
.data_in (state_next != EMPTY),
.data_out (output_valid)
);
??之后,讓我們描述實現(xiàn)我們在數(shù)據(jù)路徑模塊上的兩個基本操作的接口信號條件:讀入和讀出握手。這消除了許多可能的狀態(tài)轉(zhuǎn)換。
reg insert = 1'b0;
reg remove = 1'b0;
always @(*) begin
insert = (input_valid == 1'b1) && (input_ready == 1'b1);
remove = (output_valid == 1'b1) && (output_ready == 1'b1);
end
??現(xiàn)在我們有了數(shù)據(jù)路徑的狀態(tài)和操作,讓我們用它們來描述對數(shù)據(jù)路徑的可能轉(zhuǎn)換,以及它們可能發(fā)生的狀態(tài)。你會看到這些準(zhǔn)確地描述了狀態(tài)圖中的5條邊,并且由于我們修剪了不必要的邏輯,使用了最少的邏輯來描述它們。
reg load = 1'b0; // Empty datapath inserts data into output register.
reg flow = 1'b0; // New inserted data into output register as the old data is removed.
reg fill = 1'b0; // New inserted data into buffer register. Data not removed from output register.
reg flush = 1'b0; // Move data from buffer register into output register. Remove old data. No new data inserted.
reg unload = 1'b0; // Remove data from output register, leaving the datapath empty.
always @(*) begin
load = (state == EMPTY) && (insert == 1'b1) && (remove == 1'b0);
flow = (state == BUSY) && (insert == 1'b1) && (remove == 1'b1);
fill = (state == BUSY) && (insert == 1'b1) && (remove == 1'b0);
flush = (state == FULL) && (insert == 1'b0) && (remove == 1'b1);
unload = (state == BUSY) && (insert == 1'b0) && (remove == 1'b1);
end
??現(xiàn)在我們只需要計算每次數(shù)據(jù)路徑轉(zhuǎn)換后的下一個狀態(tài):
always @(*) begin
state_next = (load == 1'b1) ? BUSY : state;
state_next = (flow == 1'b1) ? BUSY : state_next;
state_next = (fill == 1'b1) ? FULL : state_next;
state_next = (flush == 1'b1) ? BUSY : state_next;
state_next = (unload == 1'b1) ? EMPTY : state_next;
end
Register
#(
.WORD_WIDTH (STATE_BITS),
.RESET_VALUE (EMPTY) // Initial state
)
state_reg
(
.clock (clock),
.clock_enable (1'b1),
.clear (clear),
.data_in (state_next),
.data_out (state)
);
??同樣,從控制FSM轉(zhuǎn)換中,我們可以計算數(shù)據(jù)路徑所需的所有控制信號。
always @(*) begin
data_out_wren = (load == 1'b1) || (flow == 1'b1) || (flush == 1'b1);
data_buffer_wren = (fill == 1'b1);
use_buffered_data = (flush == 1'b1);
end
endmodule
??對于64bit連接,生成的pipeline緩沖器使用128個寄存器,4到9個寄存器用于FSM和接口輸出,具體取決于CAD工具選擇的特定狀態(tài)編碼,并且很容易達(dá)到高運行速度。
-
寄存器
+關(guān)注
關(guān)注
31文章
5430瀏覽量
123987 -
緩沖器
+關(guān)注
關(guān)注
6文章
2039瀏覽量
46878 -
高電平
+關(guān)注
關(guān)注
6文章
199瀏覽量
21991 -
AXI
+關(guān)注
關(guān)注
1文章
136瀏覽量
17183
原文標(biāo)題:AXI握手時序優(yōu)化——pipeline緩沖器
文章出處:【微信號:gh_9d70b445f494,微信公眾號:FPGA設(shè)計論壇】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【芯片設(shè)計】握手協(xié)議的介紹與時序說明

請問如何擴展AXI VDMA幀緩沖器?
緩沖器,緩沖器是什么?
緩沖器,緩沖器基本原理是什么?
三態(tài)緩沖器介紹
緩沖器的作用是什么
液壓緩沖器的優(yōu)點
緩沖器的工作原理及它的作用
什么是時鐘緩沖器(Buffer)?時鐘緩沖器(Buffer)參數(shù)解析
液壓緩沖器怎么調(diào)節(jié)
AXI4協(xié)議五個不同通道的握手機制

封裝寄存器進(jìn)VO緩沖器的概念及其優(yōu)點簡析
緩沖器是干嘛的
時鐘緩沖器在現(xiàn)代化建設(shè)中的作用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論