 十大鮮為人知卻功能強大的機器學習模型
十大鮮為人知卻功能強大的機器學習模型

本文轉自:QuantML
當我們談論機器學習時,線性回歸、決策樹和神經網絡這些常見的算法往往占據了主導地位。然而,除了這些眾所周知的模型之外,還存在一些鮮為人知但功能強大的算法,它們能夠以驚人的效率解決獨特的挑戰。在本文中,我們將探索一些最被低估但極具實用價值的機器學習算法,這些算法絕對值得你將其納入工具箱。
1. 變分自編碼器(Variational Autoencoder, VAE)
變分自編碼器(VAE)是一種生成深度學習模型,旨在學習輸入數據的潛在表示,并生成與訓練數據相似的新數據樣本。與標準自編碼器不同,VAEs引入了隨機性,通過學習一個概率潛在空間,其中編碼器輸出均值(μ)和方差(σ)而不是固定表示。
在訓練過程中,從這些分布中隨機抽取潛在向量,通過解碼器生成多樣化的輸出。這使得VAEs在圖像生成、數據增強、異常檢測和潛在空間探索等任務中非常有效。
2. 隔離森林(Isolation Forest, iForest)
隔離森林是一種基于樹的異常檢測算法,它比傳統的聚類或基于密度的方法(如DBSCAN或單類SVM)更快地隔離異常值。它不是對正常數據進行建模,而是基于一個點在隨機分割的空間中突出程度來主動隔離異常值。
該算法適用于高維數據,并且不需要標記數據,使其適用于無監督學習。
示例代碼:
importnumpyasnp
importmatplotlib.pyplotasplt
fromsklearn.ensembleimportIsolationForest
# 生成合成數據(正常數據)
rng = np.random.RandomState(42)
X =0.3* rng.randn(100,2)
# 添加一些異常值(異常點)
X_outliers = rng.uniform(low=-4, high=4, size=(10,2))
# 合并正常數據和異常值
X = np.vstack([X, X_outliers])
iso_forest = IsolationForest(n_estimators=100, contamination=0.1, random_state=42)
y_pred = iso_forest.fit_predict(X)
plt.scatter(X[:,0], X[:,1], c=y_pred, cmap='coolwarm', edgecolors='k')
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.title("隔離森林異常檢測")
plt.show()
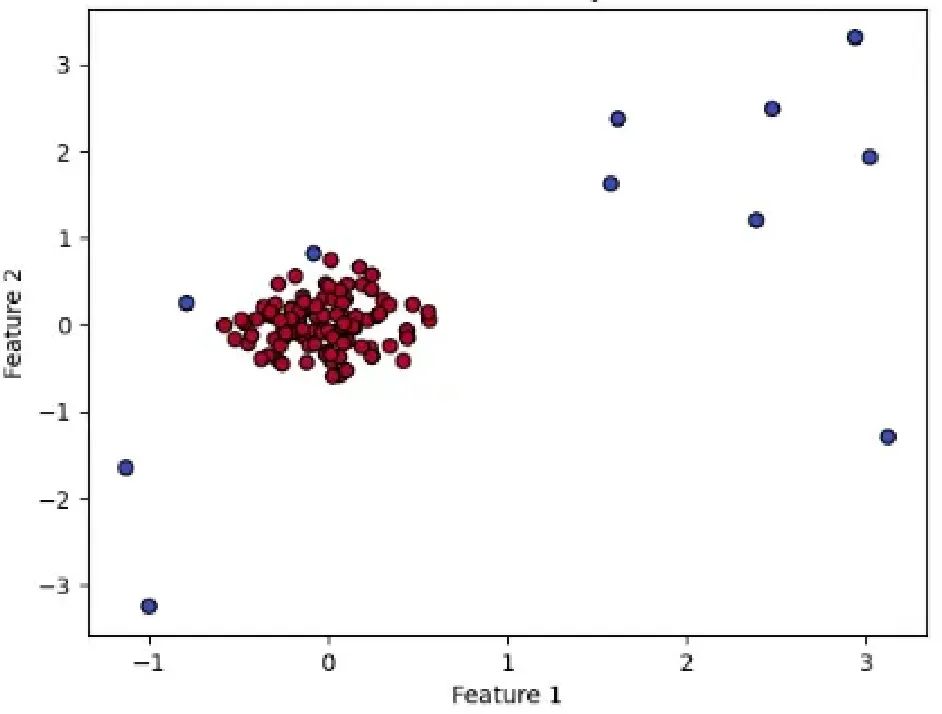 隔離森林異常檢測
隔離森林異常檢測
應用場景:
- 識別信用卡欺詐交易。
- 檢測網絡入侵或惡意軟件活動。
- 在質量控制中識別缺陷產品。
- 在健康數據中檢測罕見疾病或異常情況。
- 標記異常股票市場活動以檢測內幕交易。
3. Tsetlin機器(Tsetlin Machine, TM)
Tsetlin機器(TM)算法由Granmo在2018年首次提出,基于Tsetlin自動機(TA)。與傳統模型不同,它利用命題邏輯來檢測復雜的模式,通過獎勵和懲罰機制進行學習,從而改進其決策過程。
Tsetlin機器的一個關鍵優勢是其低內存占用和高學習速度,使其在提供具有競爭力的預測性能的同時,效率極高。此外,它們的簡單性使其能夠無縫地實現在低功耗硬件上,使其成為節能AI應用的理想選擇。
主要特點:
- 計算需求顯著低于深度學習模型。
- 易于解釋,因為它生成的是人類可讀的規則,而不是復雜的方程式。
- 最適合構建小型AI系統。
有關此算法的詳細信息,請訪問其GitHub存儲庫并查閱相關研究論文。
4. Random Kitchen Sinks, RKS
像支持向量機(SVM)和高斯過程這樣的核方法功能強大,但由于昂貴的核計算,它們在處理大型數據集時面臨挑戰。隨機廚房水槽(RKS)是一種巧妙的方法,它有效地近似核函數,使這些方法具有可擴展性。
RKS不是顯式地計算核函數(這在計算上可能非常昂貴),而是使用隨機傅里葉特征將數據投影到更高維度的特征空間。這允許模型在不進行大量計算的情況下近似非線性決策邊界。
示例代碼:
importnumpyasnp
importmatplotlib.pyplotasplt
fromsklearn.ensembleimportIsolationForest
# 生成合成數據(正常數據)
rng = np.random.RandomState(42)
X =0.3* rng.randn(100,2)
# 添加一些異常值(異常點)
X_outliers = rng.uniform(low=-4, high=4, size=(10,2))
# 合并正常數據和異常值
X = np.vstack([X, X_outliers])
iso_forest = IsolationForest(n_estimators=100, contamination=0.1, random_state=42)
y_pred = iso_forest.fit_predict(X)
plt.scatter(X[:,0], X[:,1], c=y_pred, cmap='coolwarm', edgecolors='k')
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.title("隔離森林異常檢測")
plt.show()
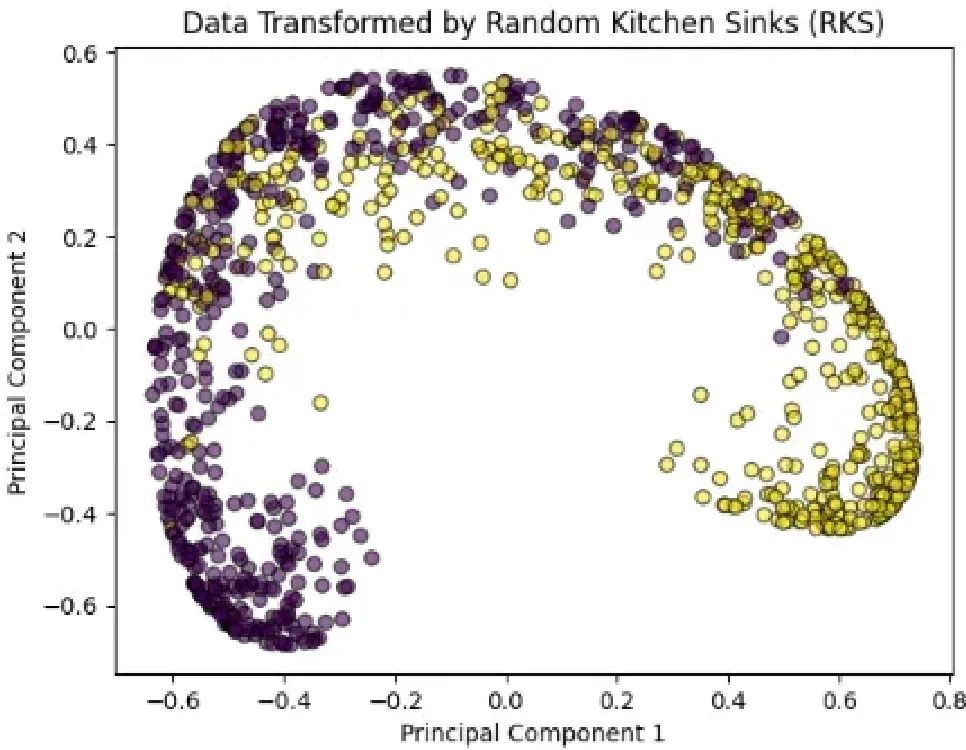 數據通過隨機廚房水槽(RKS)轉換
數據通過隨機廚房水槽(RKS)轉換
應用場景:
- 加速大型數據集上的SVM和核回歸。
- 有效地近似RBF(徑向基函數)核以實現可擴展的學習。
- 減少非線性模型的內存和計算成本。
5. 貝葉斯優化(Bayesian Optimization)
貝葉斯優化是一種順序的、概率性的方法,用于優化昂貴的函數,例如深度學習或機器學習模型中的超參數調整。
與盲目地測試不同的參數值(如網格搜索或隨機搜索)不同,貝葉斯優化使用概率模型(如高斯過程)對目標函數進行建模,并智能地選擇最有希望的參數值。
應用場景:
- 超參數調整:比網格搜索/隨機搜索更高效。
- A/B測試:無需浪費資源即可找到最佳變體。
- 自動化機器學習(AutoML):為Google的AutoML等工具提供支持。
示例代碼:
importnumpyasnp
frombayes_optimportBayesianOptimization
# 定義目標函數(例如,優化 x^2 * sin(x))
defobjective_function(x):
return-(x**2* np.sin(x))
# 定義參數邊界
param_bounds = {'x': (-5,5)}
# 初始化貝葉斯優化器
optimizer = BayesianOptimization(
f=objective_function,
pbounds=param_bounds,
random_state=42
)
# 運行優化
optimizer.maximize(init_points=5, n_iter=20)
# 找到的最佳參數
print("最佳參數:", optimizer.max)
輸出示例:
最佳參數: {'target': -23.97290882,'params': {'x': 4.9999284238296606}}
6. 霍普菲爾德網絡(Hopfield Networks)
霍普菲爾德網絡是一種遞歸神經網絡(RNN),它通過在內存中存儲二進制模式,專門從事模式識別和錯誤校正。當給定一個新輸入時,它會識別并檢索最接近的存儲模式,即使輸入不完整或有噪聲。這種能力稱為自聯想,使網絡能夠從部分或損壞的輸入中重建完整模式。例如,如果對圖像進行訓練,它可以識別并恢復它們,即使某些部分缺失或扭曲。
應用場景:
- 記憶回憶系統:它有助于恢復損壞的圖像或填補缺失的數據。
- 錯誤校正:用于電信中糾正傳輸錯誤。
- 神經科學模擬:模擬人類記憶過程。
7. 自組織映射(Self-Organizing Maps, SOMs)
自組織映射(SoM)是一種神經網絡,它使用無監督學習在低維(通常是2D)網格中組織和可視化高維數據。與依賴誤差校正(如反向傳播)的傳統神經網絡不同,SoMs使用競爭學習——神經元競爭以表示輸入模式。
SOMs的一個關鍵特性是它們的鄰域函數,它有助于保持數據中原始的結構和關系。這使得它們特別適用于聚類、模式識別和數據探索。
應用場景:
- 市場細分:識別不同的客戶群體。
- 醫學診斷:對患者癥狀進行聚類以檢測疾病。
- 異常檢測:檢測制造中的欺詐或缺陷。
8. 場感知因子分解機(Field-Aware Factorization Machines, FFMs)
場感知因子分解機(FFMs)是因子分解機(FMs)的一種擴展,專門設計用于高維、稀疏數據——通常出現在推薦系統和在線廣告(CTR預測)中。
在標準的因子分解機(FMs)中,每個特征都有一個單一的潛在向量用于與所有其他特征進行交互。在FFMs中,每個特征有多個潛在向量,每個字段(特征組)一個。這種場感知性使FFMs能夠更好地對不同特征組之間的交互進行建模。
應用場景:
9. 條件隨機場(Conditional Random Fields, CRFs)
條件隨機場(CRFs)是一種用于結構化預測的概率模型。與傳統的分類器不同,CRFs會考慮上下文,這使得它們適用于序列數據。
應用場景:
10. 極限學習機(Extreme Learning Machines, ELMs)
極限學習機(ELMs)是一種前饋神經網絡,它通過隨機初始化隱藏層權重并僅學習輸出權重來訓練得極快。與傳統的神經網絡不同,ELMs不使用反向傳播,這使得它們在訓練速度上顯著更快。
應用場景:
- 需要快速訓練速度時(與深度學習相比)。
- 對于大型數據集的分類和回歸任務。
- 當淺層模型(單隱藏層)足夠時。
- 當不需要對隱藏層權重進行微調時。
-
編碼器
+關注
關注
45文章
3788瀏覽量
137786 -
AI
+關注
關注
88文章
34918瀏覽量
278150 -
機器學習
+關注
關注
66文章
8500瀏覽量
134449
發布評論請先 登錄
仿真軟件ABAQUS:功能強大的有限元軟件
軟通動力入選2025十大DeepSeek部署典型案例
分享一款功能強大的QuarkXPress桌面排版軟件

機器學習模型市場前景如何
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
聚焦離子束技術的歷史發展

【開源項目】你準備好DIY一款功能強大的機器人了嗎?
商湯科技入選2024年CCF十大技術公益優秀案例
AI大模型與深度學習的關系
AI大模型與傳統機器學習的區別
功能強大的網絡通訊工具,支持各類TCP、UDP、HTTP的通訊協議
中國信通院發布“2024云計算十大關鍵詞”






 工商網監
工商網監
評論