 基于RDK X3的“校史通”機器人:SLAM導航+智能交互,讓校史館活起來!
基于RDK X3的“校史通”機器人:SLAM導航+智能交互,讓校史館活起來!
智慧校園:校史館也瘋狂
在科技狂飆的今天,連校史館都卷起來了!我們給校史館配了個“社牛”機器人:
- 主動迎賓:機器人通過視覺識別,主動上前打招呼,告別“自助式”參觀。
- 語音互動:邊帶路邊講解,校史知識隨問隨答,參觀體驗更生動。
- 智能導航:運用SLAM技術靈活避障,規劃最佳路線,確保游客不錯過任何亮點。
這一創新讓校史館從靜態展覽變身智能互動空間,有望能提升參觀體驗——跑得賊穩團隊
一、特色與創新
本項目通過前沿技術融合,打造了一款智能校史館向導機器人,具備以下核心創新點:
1.1 會聊天的歷史通
- 聽得清:采用六路環形麥克風+R818降噪板,在嘈雜環境中也能精準捕捉提問,像朋友聊天一樣自然。
- 答得妙:接入語音模塊和大語言模型,不僅能指路,還能化身"校史百事通",隨時解答"學校第一任校長是誰?"這類刁鉆問題。
- 主動撩:告別傳統屏幕"你問我答"模式,機器人會主動迎賓,邊走邊講解,讓參觀像逛博物館有私人導覽。
1.2 自帶導航老司機
- 認路準:通過激光雷達+深度相機融合SLAM技術,5分鐘就能"摸清"整個校史館布局,自動生成最佳參觀路線。
- 躲人穩:遇到突然出現的參觀人群,能像老司機般靈活繞行,絕不會"撞車"尬場。
- 解說忙:帶路時還會貼心地提醒:"左側展柜是1958年建校文物,要停下來看看嗎?"
1.3 高定版鋼鐵俠戰衣
- 為場景而生:自主設計的車體兼顧靈活性與穩定性,能在狹窄展區間自如轉身,底盤防撞設計避免磕碰文物。
- 模塊化升級:像樂高一樣可快速更換電池、傳感器等模塊,適應未來功能擴展需求。
二、功能設計
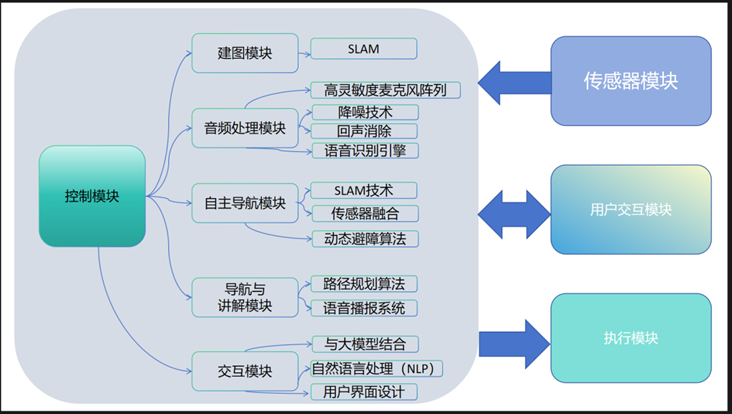
2.1 總體設計
為提升校史館的智能化服務,本項目設計了"小莫"智能導覽機器人,采用模塊化架構,實現精準交互與自主導航。
核心設計思路:
- 用戶友好交互:訪客通過語音或觸摸屏與機器人互動,指令傳遞至中央控制系統。
- 智能決策中樞:控制模塊整合SLAM定位、AI語音識別、環境感知數據,實時生成最優導覽方案。
- 精準執行反饋:導航模塊驅動機器人移動,語音系統同步講解,形成"問-答-導"閉環體驗。
技術亮點:
? 聽得懂:抗噪麥克風+AI語音模型,準確識別訪客需求
? 找得準:激光雷達SLAM實時建圖,動態規劃避障路徑
? 講得活:大語言模型賦能,校史講解媲美專業導游
2.2功能設計
2.21硬件升級:打造更靈敏的機器人
原廠配置的語音和視覺模塊存在明顯不足:
- 原有問題:麥克風拾音模糊、攝像頭成像質量差,僅支持4個基礎指令
- 改進方案:
- 聽覺系統:采用6路環形麥克風陣列配合R818專業降噪板,實現會議級降噪效果
- 視覺系統:升級為索尼IMX219傳感器,配備120°廣角鏡頭,支持高清拍攝
2.22模塊化系統架構
功能模塊 | 核心組件 | 主要功能 | 性能參數 |
感知系統 | 激光雷達+深度相機 | 環境探測與識別 | 10米探測范圍,±2cm精度 |
控制系統 | Jetson Nano+RDK X3 | 數據處理與決策 | 支持實時建圖與導航 |
驅動系統 | 精密伺服電機 | 運動控制 | 0.8m/s移動速度 |
交互系統 | 語音處理引擎 | 語音識別與合成 | 200ms響應時間 |
2.24智能工作流程
- 環境感知:通過多傳感器采集周圍環境數據
- 數據處理:Jetson Nano處理導航數據,RDK X3運行交互模型
- 任務執行:根據分析結果執行導覽或解答任務
2.25 系統接口設計
三、系統實現
3.1硬件實現
首先對語音模塊進行集成,通過PLA外殼和螺柱螺栓實現了穩固的固定。然后使用USB連接麥克風和免驅聲卡。
3.2軟件實現
3.2.1環境感知
機器人的環境感知傳感器為雷達與深度相機,下面介紹如何基于這兩個傳感器實現環境感知的。
傳感器包括雷達和深度相機。首先,關于雷達部分,可以通過克隆GitHub上的官方雷達ydlidar_ros_driver包來實現:
(git clone
https://github.com/YDLIDAR/ydlidar_ros_driver.git/ydlidar_ws/src/ydlidar_ros_driver)
接著cd到所在的目錄下,通過catkin_make構建ydlidar_ros_driver包,下一步配置包環境,使用如下指令添加永久工作區環境變量:
($echo
"source ~/ydlidar_ws/devel/setup.bash" >> ~/.bashrc)
($source ~/.bashrc)
最后,如圖4.1將lidar_view.launch文件中的lidar.launch改為X2.launch小莫使用的雷達型號為X2就完成配置了。

隨后打開rviz工具,查看雷達掃描效果,命令如下:
(roslaunch limo_bringup
lidar_rviz launch)
默認情況下,雷達的掃描范圍是360度,但可以根據需要在launch文件中修改參數以改變雷達的掃描范圍。對于小莫使用的X2雷達,在ROS內遵循右手定則,角度范圍為[-180, 180]。


至此,機器人已經完成了對兩個環境感知傳感器的適配,這意味著它現在能夠全面感知并理解周圍環境的情況。
3.2.2底盤驅動
在實現環境感知模塊之后,系統需要將感知到的環境信息用于實際的運動控制,因此底盤驅動模塊的設計與實現顯得尤為重要。接下來,我們將介紹底盤驅動模塊的具體實現方法。
移動底盤需要通過程序驅動才能實現移動機器人的運動,移動機器人的底盤驅動程序分為兩個版本,分別為C++版本和Python版本,兩個版本都可以控制移動機器人運動。
Python版本的代碼僅有三個?件組成驅動程序,init.py的作?為申明需要使用的?件limomsg.py的作?為驅動成所需要的消息,limo.py是主程序,它的作用是驅動移動機器人。
(函數名稱)() | (函數作)(?)() |
(EnableCommand()) | (控制使能)() |
(SetMotionCommand()) | (設置移動命令)() |
(GetLinearVelocity()) | (獲取線速度)() |
(GetAngularVelocity()) | (獲取)(?)(速度)() |
(GetSteeringAngle()) | (獲取內轉)(??)(度)() |
(GetLateralVelocity()) | (獲取橫移速度)() |
(GetControlMode()) | (獲取控制模式)() |
(GetBatteryVoltage()) | (獲取電池電量)() |
(GetErrorCode()) | (獲取錯誤代碼)() |
(GetRightWheelOdem()) | (獲取左輪)(?)(程計)() |
(GetLeftWheelOdem()) | (獲取右輪)(?)(程計)() |
(GetIMUAccelData()) | (獲取)(IMU)(的加速度)() |
(GetIMUGyroData()) | (獲取陀螺儀的數據)() |
(GetIMUYawData()) | (獲取)(IMU)(的航向)(?)() |
(GetIMUPichData()) | (獲取俯仰)(?)() |
(GetIMURollData()) | (獲取橫滾)(?)() |
3.2.3動態避障
底盤驅動為車輛提供了動力,而避障則是確保車輛在運動過程中能夠安全地避開障礙物,兩者需要密切合作,因此該機器人使用了兩種動態避障算法進行雷達避障。
首先用到的庫是teb_local_planner,由move_base包進行調用
(sudo
apt-get install ros-kinetic-teb-local-planner)
(sudo
apt-get install ros-kinetic-teb-local-planner-tutorials)
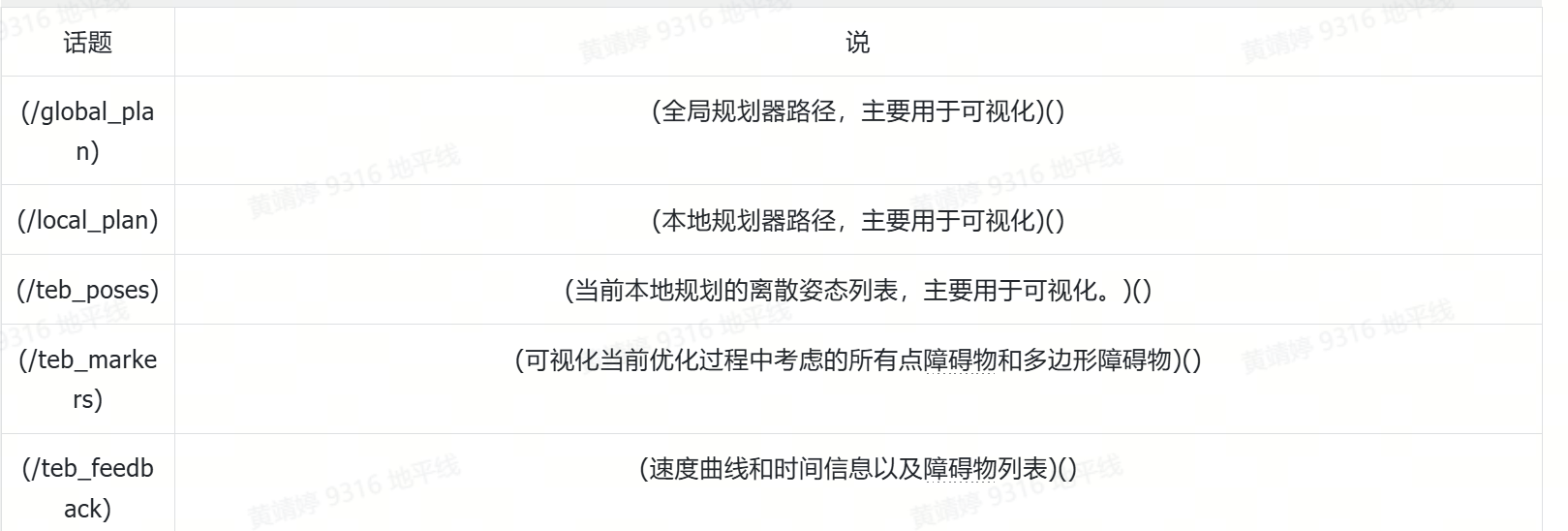
在實際使用中,避障能力受到參數調整的影響極大,稍有不慎便可能導致撞上障礙物。為此,我們總結了一套僅適用于小莫的TEB調參方法及適配于室內避障的范圍。
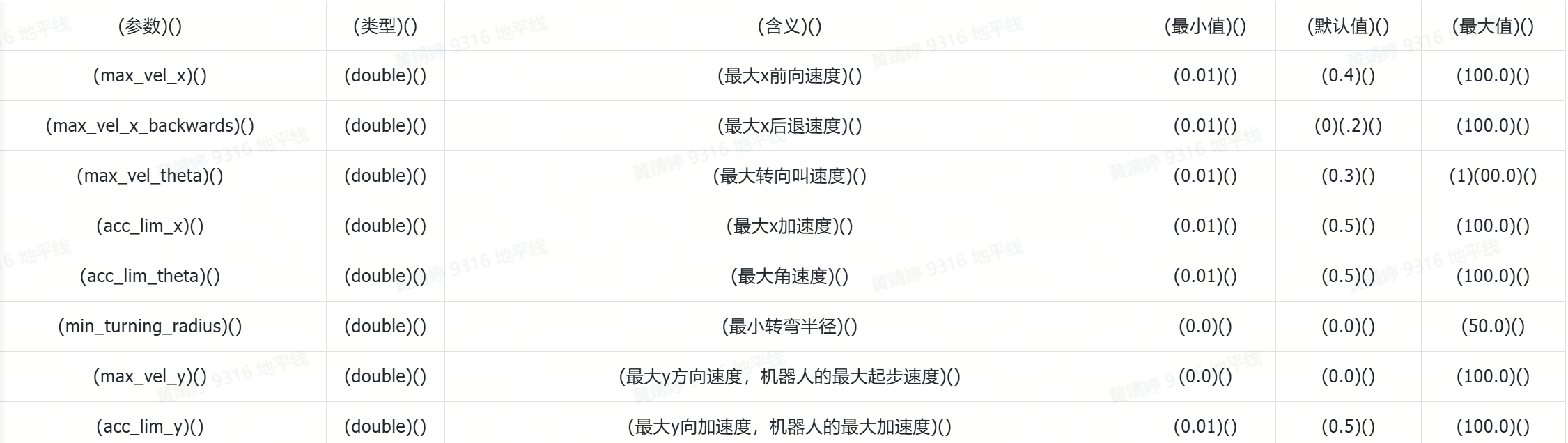
我們定義避障效果的好壞是通過同等障礙物距離下LIMO響應的快慢來直觀感受的,參數是在rqt_reconfigure界面里調整的。經過測試發現,關閉多路徑并行規劃和使用Costmap Converter可以顯著提升避障效果。降低迭代次數no_inner/outer_iterations和減小局部成本地圖的大小也能顯著改善性能。相較之下,降低max_lookahead_distance的效果較為一般,而增大規劃周期和控制周期則會影響整體效果。使用單點footprint并結合最小障礙物距離約束,對效果的提升不太顯著,并且可能影響整體性能。
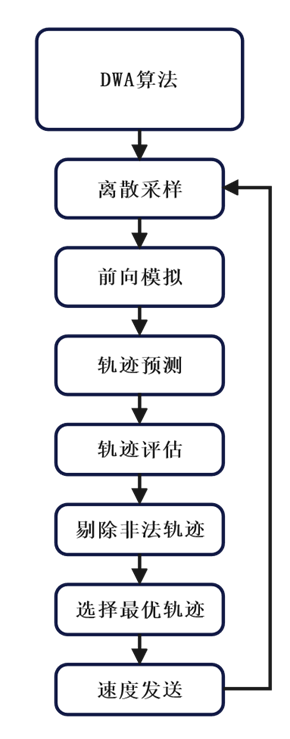
至此,TEB算法的配置已經完成,但由于TEB算法容易陷入局部最優問題,且在處理密集障礙物或狹窄空間時可能會產生不穩定的路徑規劃結果,因此需要引入第二個算法——DWA(動態窗口法)算法進行補充。通過這種方法,DWA算法能夠動態調整機器人的路徑規劃,避免局部最優問題,并在密集障礙物或狹窄空間中提供更穩定的路徑規劃結果,從而補足了TEB算法的不足。
3.2.4 地圖構建
在車輛在復雜環境中執行動態避障的過程中,實時感知到的障礙物信息不僅為安全行駛提供了保障,接下來就是建圖步驟。
SLAM建圖是小莫機器人進行地圖構建的核心原理,指的是即時定位和建圖,SLAM建圖主要是有以下三個過程:
一是預處理,對雷達點云數據進行處理,包括清除異常值,以確保數據質量。這個過程有助于提高雷達測量的準確性和可靠性。簡而言之,點云數據的優化是確保雷達捕獲的環境信息準確無誤的關鍵步驟。以激光作為信號源,由激光器發射出的脈沖激光,打到周圍障礙物上,引起散射。
一部分光波會反射到激光雷達的接收器上,再根據激光測距原理計算,就可以得到從激光雷達到目標點的距離。關于點云:通俗來說,激光雷達獲取的周圍環境信息,被稱為點云。它是能反映機器人所在環境中“眼睛”能看到的一個部分。雷達點云數據呈現了物體的精確位置,包括角度和距離,形成了分布式的空間信息集合。這些數據為機器人或系統提供了關于其周圍環境的詳細三維視圖。
二是匹配,在當前環境中,將點云數據與已有地圖進行對照,以定位相應位置。激光SLAM系統通過比較不同時間點的點云數據,來計算激光雷達的移動距離和方向變化,實現機器人的自我定位。
三是地圖更新,新一輪激光雷達數據會被整合進原始地圖,以此更新地圖。
SLAM的過程已經詳細闡釋,下面將通過三種算法實現SLAM建圖:
一是gmapping,通過以下命令將gmapping安裝在小莫上,創建相關launch文件即可使用。
sudo apt-get install ros-melodic-gmapping
sudo apt-get install ros-melodic-teleop_twist_keyboard
sudo apt install ros-melodic-map-server
在gmapping功能包中,slam_gmapping節點扮演著核心角色,它處理多種話題和服務來實現SLAM。具體來說,它訂閱tf話題以獲取雷達和里程計之間的坐標轉換信息,以及/scan話題來接收雷達掃描數據。此外,它發布map_metadata和map話題,分別提供地圖的元數據和柵格數據,這些數據通常在rviz中可視化展示。節點還發布~entropy話題,用于估計機器人姿態的不確定性。同時,它提供dynamic_map服務,以供請求地圖數據之用。
二是Cartographer,通過以下命令將Cartographe安裝在小莫上,創建相關launch文件即可使用:
sudo apt install ros-foxy-cartographer
sudo apt install ros-foxy-cartographer-ros
在Cartographer調參測試發現,概率通過公式離散化的uint8數值小于127時,空閑概率更大;數值大于127時,占用概率更大。
我們看到,層數越高,圖像變得越來越粗糙,黑色部分明顯膨脹,因此,我們選定滑動窗口為width=1作為參數。
同時,我們也為小莫的四種運動模態創建了兩個建圖launch文件,其中履帶模式、麥克拉姆輪模式都可以與差速模式共用一個launch文件。
至此,兩種建圖算法已經成功配置實現,除cartographer選定參數width=1外,其余參數經測試發現適用于小莫機器人,故均選用默認參數使用。
3.2.5自主導航
實時感知到的障礙物信息為安全行駛提供了保障,同時地圖構建也提供了重要的環境數據,為后續路徑規劃和導航奠定了堅實的基礎。
路徑規劃的前提是定位,定位功能是用來計算機器人在全局地圖上的具體位置。雖然SLAM技術包含了定位算法,但它主要用于在導航開始前構建全局地圖,而實時定位則是在導航過程中使用,我們選用的是AMCL蒙特卡洛定位系統,這一系統專門用于導航時的機器人定位,定位方法算法流程如下:

在小莫中,AMCL定位輸入以下命令安裝,配置如圖4.11的launch文件即可備用:
([1]) https://wiki.ros.org/move_base
([1]) amcl - ROS Wiki
sudo apt-get install ros-melodic-navigation
AMCL需要訂閱的服務是/scan激光雷達數據和/tf坐標變換消息,它發布的話題中,最重要的是/amcl_pose,這是機器人在地圖中的位姿估計。
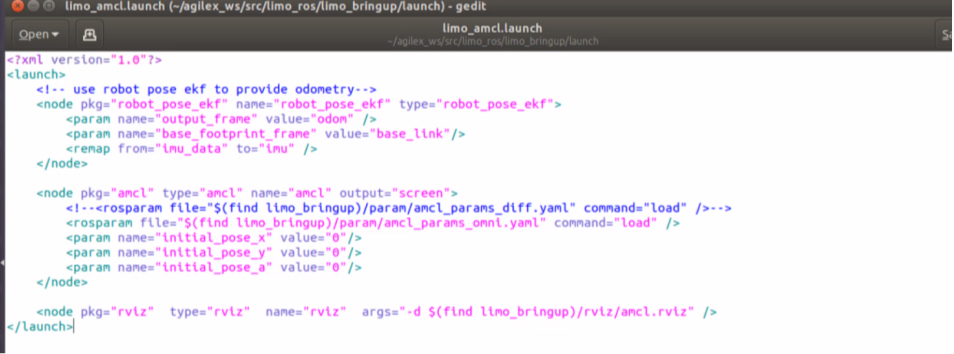
AMCL則負責機器人在環境中的定位,在導航過程中還需要能實現路徑規劃和避障的“地圖”,即代價地圖(Cost Map),它通過為地圖中的每個柵格分配一個“代價”值,來表示機器人在該位置的移動難度或風險。
Costmap2D 類維護了每個柵格的代價值。Layer 類是虛基類,它統一了各插件costmap層的接口。其中最主要的接口函數有:
initialize函數,它調用onInitialize函數,分別對各costmap 層進行初始化;matchSize函數,在StaticLayer 類和ObstacleLayer 類中,該函數調用了CostmapLayer類matchSize 函數,初始化各costmap 層的size,分辨率,原點和默認代價值,并保持與layered_costmap 一致。對于inflationLayer 類,根據膨脹半徑計算了隨距離變化的cost 表。后面就可以用距離來查詢膨脹柵格的cost 值。同時定義了seen_數組,該數組用于標記柵格是否已經被遍歷過。對于VoxelLayer 類,則初始化了體素方格的size;
updateBounds 函數,調整當前costmap 層需要更新的大小范圍。對于StaticLayer類,確定costmap 的更新范圍為靜態地圖的大小,注意:靜態層一般只用在全局costmap中。對于ObstacleLayer 類,遍歷clearing_observations 中的傳感器數據確定障礙物的邊界。
其中initialize 函數和matchSize 函數分別只執行一次。updateBounds 函數和updateCosts 函數則會周期執行,其執行頻率由map_update_frequency 決定。
CostmapLayer 類同時繼承了Layer 類和Costmap2D 類,并提供了幾個更新cost 值的操作方法。StaticLayer 類和ObstacleLayer 類需要保存實例化costmap 層的cost 值,所以都繼承了CostmapLayer 類。StaticLayer 類使用靜態柵格地圖數據更新自己的costmap。ObstacleLayer 類使用傳感器數據更新自己的costmap 。VoxelLayer 類相對于ObstacleLayer 類則多考慮了z軸的數據。效果的區別主要體現在障礙物的清除方面。一個是二維層面的清除,一個是三維里的清除。
代價地圖已經內嵌到下文提及的move_base的功能包中,無需單獨配置。
至此,萬事具備,導航準備工作已經完成,已經可以開始在小莫上實現自主導航了。
move_base功能包需要使用本節前文提及的所有模塊:深度相機提供的畫面會集成在導航操作界面中,供用戶實時了解機器人的位置和環境;雷達數據不僅用于避障,還參與SLAM建圖,為導航提供可靠的地圖信息和障礙物檢測;雷達避障的兩個局部規劃器分別負責不同的避障任務,與move_base中的全局規劃器配合,共同實現整體路徑規劃的優化和調整;AMCL包則持續反饋機器人在地圖中的位姿信息,確保導航時能夠依賴代價地圖(Cost Map)進行實時路徑規劃和調整。通過這些模塊的協同工作,小莫機器人能夠在復雜環境中實現精準的自主導航,確保安全和高效的路徑規劃。
通過以下指令便可以安裝move_base包:
sudo apt-get install ros-melodic-navigation
同時,我們也為小莫的四種運動模態創建了兩個導航launch文件,履帶模式、麥克拉姆輪模式都可以與差速模式共用一個launch文件。
至此,自主導航功能已經全部實現,為語音導航,自主建圖打下了基礎。
3.2.6語音交互
右鍵單擊“此電腦”點擊“管理”,在設備管理器中找到“CH340”字樣,獲取麥克風的端口號。
在串口選擇區選擇麥克風的串口,我們是連接的是COM3串口。
點擊串口選擇區的“打開串口”,看到如下所示頁面,即成功與PC建立連接。
在命令輸入區輸入“{"type":"version"}”,點擊“Send Raw”即可在顯示區看到麥克風的版本信息。
在命令輸入區輸入“{"type":"wakeup_keywords", "content":{"keyword": "xiao3 huan4 xiao3 huan4", "threshold": "900"}}”點擊“Send Raw”即可在顯示區看到麥克風的通信信息。(“content:”表示喚醒內容,“keyword:{}”表示關鍵字,xiao3為小的拼音+聲調,huan4為幻的拼音+聲調)。
在語音開放平臺申請kpi后將該文件導入,修改了appid后,添加啟動時也啟動hw_speaker文件。
3.2.7語言大模型
我們用大模型KIMI智能助手。KIMI API兼容Openai的接口規范,使用 openai 提供的 Python或NodeJS SDK 來調用和使用 Kimi 大模型,那么只需要將 base_url 和 api_key 替換成 Kimi 大模型的配置。

3.2.8目標檢測
RDK X3提供了基于MIPI攝像頭推理的Python代碼,實現了加載FCOS 圖像目標檢測算法模型基于COCO數據集訓練的80個類別的目標檢測,包括且不限于人、狗、貓等生活中常見的類、從MIPI攝像頭讀取視頻圖像,并進行推理、解析模型輸出并將結果渲染到原始視頻流、通過HDMI接口輸出渲染后的視頻流。
選用fcos作為推理模型是因為FCOS算法的設計復雜度,易于理解和操作;性能優于YOLO、SSD等檢測網絡;可以充分利用CPU,減少進程切換導致的資源浪費。
3.3各模塊協同實現
各個模塊實現后,需要通過集成手段實現各個模塊的協同配合,實現的詳細介紹如下。
用戶通過語音或界面喚醒麥克風,麥克風拾音之后對語音進行分析來判斷用戶是進行運動控制、下達指令還是進行提問從而進行下一步動作。若是對運動控制,則將信息發送到Jetson nano中進行解析執行;若是進行提問,則將內容送到大模型中,等待返回結果后進行文字轉語音,再播放語音。
3.3.1用戶界面實現
小莫的集成特性是本設計的創新點之一,各模塊協同配合的一種紐帶是靠PyQt所構建的菜單界面,如圖4.27所示,窗口由歡迎窗口、主界面窗口和各個子窗口構成。歡迎窗口可鍵入主窗口,主窗口點擊各功能按鈕進入子窗口。
啟動主窗口的同時也啟動 dabai_u3.launch攝像頭節點和limo_start.launch底盤節點,如圖4.28所示,各個功能模塊的啟動與關閉匯總在主窗口中,點擊即可分別開啟各個launch文件啟動節點,同時彈出提示框提示是否打開成功。
啟動建圖節點:使用subprocess.Popen數啟動了一個新的進程來運行建圖節點的launch文件,具體是limo_bringup limo_rtabmap_orbbec.launch,同時設置了localization:=true參數。這個參數表示要啟動定位功能,這在建圖的過程中很重要,因為定位可以讓機器人知道自己在地圖中的位置。
隨機移動建圖的邏輯:定義了一個random_move函數,其中包含了一個while循環,在循環中機器人會以隨機的方式移動,模擬在環境中探索的過程。
在循環中,首先會生成一個隨機的目標點,然后調用movebase_client函數來讓機器人移動到這個目標點。
同時還會生成一個隨機的方向,以便機器人移動時有一定的旋轉,增加探索的多樣性。
建圖過程的等待和結束:在識別到“自主建圖”命令后,會啟動隨機移動,并且等待一段時間,這段時間是模擬機器人在環境中探索的過程。
在等待時間結束后,會停止隨機移動,并且結束建圖節點的運行,同時播放“mapping_complete”提示音,表示建圖完成。
3.3.2語音控制實現
語音控制是小莫的創新點,機器人可以通過語音控制各個模塊,并實現功能。
錄音調用控制器:用于實現語音識別并控制相關設備。主要功能包括接收來自喚醒標志的信息,調用離線語音識別服務,處理識別結果并根據情況執行相應操作。該操作首先初始化ROS節點,并創建必要的節點句柄、服務客戶端和話題訂閱者。然后,在一個循環中,不斷地獲取離線語音識別的結果,并根據識別結果進行相應的處理。在識別結果的處理過程中,該操作首先判斷喚醒狀態,如果處于喚醒狀態,則調用離線語音識別服務獲取識別結果。根據識別結果的不同,可能執行以下操作:如果識別結果為“休眠”,則將喚醒標志置為0,使系統進入休眠狀態。如果識別結果為“ok”,表示識別成功,根據具體識別到的語音內容,執行相應操作,并將喚醒標志置為0,進入休眠狀態。如果識別結果為“fail”,表示識別失敗,記錄失敗次數,并根據失敗次數的不同,可能發出相應的警告信息,并在連續失敗達到一定次數后,將系統置為休眠狀態。如果調用離線語音識別服務失敗,則記錄錯誤信息并繼續下一次循環。通過以上邏輯,該操作實現了對語音指令的識別和處理,并可以根據識別結果執行相應的控制操作,從而實現了語音控制相關設備的功能。
離線語音識別服務識別聲音指令:頭文件引入和全局變量聲明:包括一些頭文件的引入以及全局變量的聲明,其中包括用于發布聲音識別結果的ROS發布者、離線識別開關、一些參數設置和一些外部聲明的變量。輔助函數定義:包括將字符串轉換為寬字符和將寬字符轉換為字符串的輔助函數,以及播放聲音的函數。業務數據處理函數(business_data):用于處理錄音數據,并將數據傳入語音識別引擎進行識別。顯示離線識別結果函數(show_result):用于解析離線識別結果字符串,提取有效關鍵字和置信度。獲取離線識別結果服務回調函數(Get_Offline_Recognise_Result):用于接收離線識別結果請求,并調用相應的處理函數進行離線識別,并返回識別結果。主函數(main):包括ROS節點初始化、參數設置、服務、發布者的創建和一些初始化操作,然后進入循環中不斷檢測初始化是否成功和是否完成錄音,并根據情況調用離線識別服務進行識別。
設置麥克風類型和喚醒詞并喚醒語音控制:實現了一個可以與環形麥克風陣列交互的 ROS 節點,可以通過 ROS 服務設置麥克風類型和喚醒詞,并通過 ROS 發布者發布喚醒標志和喚醒角度,主要功能包括:CircleMic 類:這個類實現了與環形麥克風陣列通信的方法。它包括了初始化串口、切換麥克風類型、獲取版本信息、設置喚醒詞等功能。AwakeNode 類:這個類是一個ROS節點,通過串口與環形麥克風陣列通信,提供了三個 ROS 服務:設置麥克風類型、獲取設置信息、設置喚醒詞。它還創建了兩個 ROS 發布者,用于發布喚醒標志和喚醒角度。主函數:在主函數中,首先初始化了 ROS 節點,然后根據參數設置了環形麥克風的類型、串口和喚醒詞。接著創建了一個AwakeNode 對象,初始化了 ROS 服務和發布者,并調用了環形麥克風的方法來獲取喚醒結果。
通過識別語音指令執行相應操作:它通過結合語音識別和導航功能,實現了對小車的語音指令控制,包括控制小車的移動、執行特定任務以及與用戶進行交互的功能。首先,操作中建立了與ROS通信的發布者和訂閱者。這些發布者和訂閱者用于與其他ROS節點進行數據交換,以便小車能夠接收語音指令并執行相應的動作。其次,該操作定義了多個函數來實現不同的功能。其中,amcl_pose_callback函數用于接收小車當前位置信息,這對于后續的導航任務至關重要;play函數用于播放特定名稱的語音提示,以便與用戶進行交互;pub_cmd_msg函數用于發布控制小車移動的指令,并可以設置持續時間,以實現精確的控制;movebase_client函數則用于向move_base節點發送導航目標點,并等待導航完成;add_mark_point函數用于向數據庫添加標記點信息,以便小車能夠在地圖中定位和導航;random_move函數實現了小車的隨機移動功能,這對于自主建圖過程中的地圖探索至關重要。在主循環中,該操作通過訂閱語音識別節點的話題來監聽語音指令。一旦接收到特定的指令,就會調用相應的處理函數執行相應的動作或任務。例如,當接收到前進、后退、左轉、右轉等移動指令時,該操作會調用相關的移動函數控制小車的運動;當接收到導航到特定地點的指令時,該操作會調用導航函數執行相應的任務。此外,該操作還實現了喚醒與休眠處理功能。當接收到喚醒指令時,該操作會播放喚醒成功提示,并根據當前小車的角度進行旋轉以調整朝向;當接收到休眠指令時,該操作會播放休眠提示,并暫停監聽語音指令,以節省系統資源。
接著詳細展開說明代碼中的關鍵函數:
首先是amcl_pose_callback(msg)函數。這個函數用于接收小車當前位置信息,并將其存儲在全局變量中供其他部分代碼使用。它訂閱了ROS話題/amcl_pose,該話題發布的消息包含小車在地圖中的位置信息。每當有新的位置信息到達時,該函數就會被調用,并將當前位置信息存儲在全局變量中。
接著是play(name)函數。這個函數用于播放特定名稱的語音提示,以便與用戶進行交互。它使用了一個名為voice_play的模塊,通過調用其中的函數實現語音播放功能。調用該函數時,將所需的語音提示的名稱作為參數傳遞給該函數,然后它會根據名稱播放相應的語音。
下一個函數是pub_cmd_msg(msg, duration)。這個函數用于發布控制小車移動的指令,并可以設置持續時間。它接受兩個參數:msg表示要發布的控制指令,duration表示指令持續的時間。在函數內部,它通過ROS發布者向話題/cmd_vel發布指令消息,控制小車的運動。同時,通過設置定時器,可以確保指令在指定的持續時間內持續執行,然后停止。
接下來是movebase_client(x, y, orientation)函數。這個函數用于向move_base節點發送導航目標點,并等待導航完成。它使用了ROS的行為庫中的SimpleActionClient來實現與move_base節點的通信。在函數內部,首先創建一個MoveBaseGoal對象,設置目標位置和姿態,然后向move_base節點發送這個目標,并等待導航任務完成。
然后是add_mark_point(name, x, y, orientation)函數。這個函數用于向數據庫添加標記點信息。它接受標記點的名稱、位置坐標和姿態作為參數,并將這些信息插入到SQLite數據庫中。在函數內部,它使用了SQLite數據庫連接和游標對象來執行插入操作,確保標記點信息被正確存儲。
最后是random_move()函數。這個函數實現了小車的隨機移動功能。它使用了Python的random模塊來生成隨機目標點和隨機方向。在函數內部,它周期性地生成隨機目標點,并調用movebase_client函數來讓小車移動到這些目標點,從而實現隨機移動和地圖探索。
指令處理函數 words_callback(msg) 在這個代碼中扮演著至關重要的角色。它是通過訂閱語音識別節點發布的話題/call_recognition/voice_words來監聽語音指令的。一旦接收到語音指令,該函數將被觸發,開始執行指令處理流程。
首先,函數會解析接收到的消息,將語音指令提取出來。這通常涉及將消息內容進行解碼,以確保正確地識別和理解用戶的指令。解析語音指令可能包括文本分詞、語義分析等步驟,以便準確識別用戶的意圖和要求。
接著,根據解析得到的指令內容,函數會進入相應的處理分支。這些分支通常是一系列的條件語句或者是使用字典等數據結構進行指令匹配的邏輯判斷。每個分支對應著一種或多種可能的指令,以及執行相應操作的代碼。
在處理指令的過程中,函數可能會調用其他函數來實現具體的操作。例如,如果接收到的是控制小車移動的指令,函數會調用控制小車移動的函數;如果接收到的是導航到特定地點的指令,函數會調用導航函數執行相應的導航任務。
除了執行相應操作外,指令處理函數還可能會向用戶提供反饋信息。這可以通過語音提示、控制臺輸出、圖形界面等形式來實現,以便用戶了解指令的執行情況和結果。
在處理完指令后,函數可能會繼續等待并監聽下一個語音指令,以保持對用戶的持續響應。整個指令處理函數的設計目的是使系統能夠實現對用戶語音指令的準確理解和及時響應,從而提高系統的交互性和用戶體驗。
以下是對每個分支進行詳細描述:
自主建圖指令分支:如果接收到的語音指令是"自主建圖",系統將啟動建圖功能。首先,系統會播放開始建圖的語音提示,然后啟動建圖節點和導航節點,讓小車開始在環境中進行地圖構建。在建圖過程中,系統可能會調用隨機移動函數,使小車在環境中探索,以獲取更多的地圖信息。建圖完成后,系統會播放建圖完成的語音提示,并關閉建圖節點,以便后續的導航任務。
移動控制指令分支:如果接收到的語音指令是移動控制指令,比如"前進"、"后退"、"向左轉"、"向右轉"等,系統會根據指令調整小車的移動方向和速度,以執行相應的動作。例如,如果接收到"前進"指令,系統會使小車向前移動;如果接收到"向左轉"指令,系統會使小車向左轉動。
導航指令分支:如果接收到的語音指令是導航指令,比如"導航到前臺"、"去王老師辦公室"等,系統會調用相應的導航函數,使小車導航到指定的目標位置。這些導航函數會計算小車到目標位置的路徑,并發送導航指令給導航節點,以實現自主導航功能。
標記點操作分支:如果接收到的語音指令是標記點操作指令,比如"設置A點",系統會獲取當前小車的位置信息,并將其作為一個標記點保存到數據庫中。這些標記點可以在后續的導航任務中使用,以便小車能夠到達預先設置的目標位置。
其他指令分支:如果接收到的語音指令不屬于以上任何一種情況,系統可能會播放無法識別的語音指令提示,或者不做任何響應。這種情況下,系統會保持等待狀態,繼續監聽新的語音指令。
([1]) ydlidar_ros_driver/details.md at master · YDLIDAR/ydlidar_ros_driver · GitHub
([2]) https://vcp.developer.orbbec.com.cn/documentation
([3]) teb_local_planner - ROS Wiki
([4]) teb_local_planner - ROS Wiki
([5]) teb_local_planner - ROS Wiki
([6]) dwa_local_planner - ROS Wiki
([8]) gmapping - ROS Wiki
([9]) cartographer - ROS Wiki
([10]) https://wiki.ros.org/move_base
([11]) amcl - ROS Wiki
([12]) amcl - ROS Wiki
([13]) move_base - ROS Wiki
-
機器人
+關注
關注
213文章
29568瀏覽量
211963 -
人工智能
+關注
關注
1805文章
48843瀏覽量
247449 -
RDK
+關注
關注
0文章
24瀏覽量
9191
發布評論請先 登錄
詳細介紹機場智能指路機器人的工作原理
RDK X3 帶飛的智能護理系統:讓機器人秒變貼心小棉襖

【「# ROS 2智能機器人開發實踐」閱讀體驗】視覺實現的基礎算法的應用
【「# ROS 2智能機器人開發實踐」閱讀體驗】+ROS2應用案例
【「# ROS 2智能機器人開發實踐」閱讀體驗】+內容初識
RDK X3新玩法:超沉浸下棋機器人開發日記

地瓜機器人RDK X5 規格書與地瓜機器人RDK X5原理圖
復合機器人是通過什么導航方式?
RDK X3暴改機器人:手搓能爬樓的AI快遞員會爬樓能嘮嗑

AGV機器人智能化無人倉儲,讓你的倉庫活起來!
手搓網球撿拾機器人:RDK X3帶你輕松解鎖球場黑科技


ROSCon China 2024 | RDK第一本教材來了!地瓜機器人與古月居發布新書《ROS 2智能機器人開發實踐》






 工商網監
工商網監
評論