") 谷歌新一代 TPU 芯片 Ironwood:助力大規(guī)模思考與推理的 AI 模型新引擎?
谷歌新一代 TPU 芯片 Ironwood:助力大規(guī)模思考與推理的 AI 模型新引擎?
電子發(fā)燒友網(wǎng)報道(文 / 李彎彎)日前,谷歌在 Cloud Next 大會上,隆重推出了最新一代 TPU AI 加速芯片 ——Ironwood。據(jù)悉,該芯片預(yù)計于今年晚些時候面向 Google Cloud 客戶開放,將提供 256 芯片集群以及 9,216 芯片集群兩種配置選項。
在核心亮點層面,Ironwood 堪稱谷歌首款專門為 AI 推理精心設(shè)計的 TPU 芯片,能夠有力支持大規(guī)模思考與推理 AI 模型。谷歌方面表示,它代表著 AI 發(fā)展從 “響應(yīng)式” 向 “主動式” 的范式轉(zhuǎn)變,未來 AI 代理將能夠主動檢索并生成數(shù)據(jù),進而提供深度見解,而非僅僅輸出原始數(shù)據(jù)。
在性能與能效表現(xiàn)上,Ironwood 取得了重大突破。其每瓦性能達到上一代 TPU Trillium 的兩倍,能效近乎首款云 TPU 的 30 倍。單芯片配備 192GB 高帶寬內(nèi)存(HBM),容量為 Trillium 的 6 倍;HBM 帶寬高達 7.2TB/s,是 Trillium 的 4.5 倍。芯片間互連(ICI)帶寬提升至 1.2TB/s,為 Trillium 的 1.5 倍,這一提升有力地支持了大規(guī)模分布式訓(xùn)練與推理任務(wù)。
此外,Ironwood 還是谷歌首款支持 FP8 浮點格式的 TPU 芯片。在此之前,TPU 僅支持 INT8(用于推理)和 BF16(用于訓(xùn)練)。采用 FP8 計算可使 AI 訓(xùn)練吞吐量翻倍,性能相較于 BF16 提升 10 倍。
Ironwood 還配備了增強版 SparseCore 專用加速器,可用于處理高級排名和推薦任務(wù)中常見的超大嵌入。憑借這一增強版 SparseCore,其能夠加速更多領(lǐng)域的任務(wù),應(yīng)用范圍從傳統(tǒng)的 AI 任務(wù)拓展至金融和科學(xué)等領(lǐng)域。
在系統(tǒng)架構(gòu)與擴展性方面,Ironwood 可擴展至 9216 個液冷芯片,借助突破性的 ICI 網(wǎng)絡(luò)進行連接,功率接近 10 兆瓦。它提供 256 芯片和 9216 芯片兩種 Pod 配置,其中 9216 芯片的 Pod 配置整體 AI 算力可達 42.5 Exaflops。谷歌先進的液冷解決方案能夠確保芯片在持續(xù)繁重的 AI 工作負(fù)載下依然保持高性能。
谷歌的 TPU 作為專為機器學(xué)習(xí)設(shè)計的定制化加速芯片,自 2015 年首次亮相以來,已成為 AI 硬件領(lǐng)域的重要力量。TPU 主要應(yīng)用于訓(xùn)練和推理大規(guī)模 AI 模型(如 AlphaGo、PaLM、Gemini 等),并深度融入 Google Cloud 以及谷歌內(nèi)部 AI 服務(wù)之中。
截至目前,TPU 已歷經(jīng)多次版本迭代:TPU v1 支持 INT8 精度,主要用于谷歌內(nèi)部項目(如 AlphaGo、RankBrain);TPU v2/v3 面向訓(xùn)練與推理場景,支持浮點運算,v3 進一步增加了內(nèi)存和互連帶寬;TPU v4 的算力達到 TPU v3 的 2.7 倍,采用液冷技術(shù),支持 4096 芯片互聯(lián)的 Pod 集群,適用于超大規(guī)模模型(如 PaLM)。
由此可見,谷歌 TPU 憑借其專用化設(shè)計、高能效比以及與 TensorFlow 的深度集成等優(yōu)勢,成為大規(guī)模 AI 模型訓(xùn)練與推理的核心硬件支撐。如今,Ironwood 的推出不僅將進一步鞏固谷歌在 AI 硬件領(lǐng)域的領(lǐng)先地位,也勢必為生成式 AI 的下一階段發(fā)展提供強大的計算動力。?
-
谷歌
+關(guān)注
關(guān)注
27文章
6228瀏覽量
107755 -
TPU
+關(guān)注
關(guān)注
0文章
152瀏覽量
21124
發(fā)布評論請先 登錄
谷歌新一代生成式AI媒體模型登陸Vertex AI平臺
Google推出第七代TPU芯片Ironwood
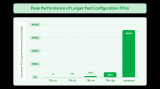
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命

適用于數(shù)據(jù)中心和AI時代的800G網(wǎng)絡(luò)
讓大模型訓(xùn)練更高效,奇異摩爾用互聯(lián)創(chuàng)新方案定義下一代AI計算





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論