") 如何描述機(jī)器學(xué)習(xí)中的一些綜合能力
如何描述機(jī)器學(xué)習(xí)中的一些綜合能力

當(dāng)我在閱讀機(jī)器學(xué)習(xí)相關(guān)文獻(xiàn)的時(shí)候, 我經(jīng)常思考這項(xiàng)工作是否:
提高了模型的表達(dá)能力;
使模型更易于訓(xùn)練;
提高了模型的泛化性能。
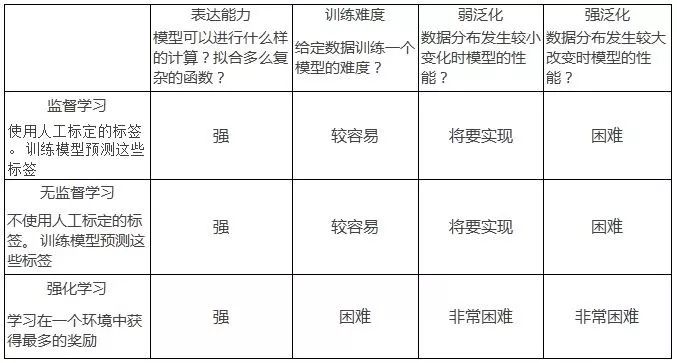
在這篇博文中, 我們討論當(dāng)前的機(jī)器學(xué)習(xí)研究:監(jiān)督學(xué)習(xí), 無(wú)監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)在這些方面的表現(xiàn)。談到模型的泛化性能的時(shí)候, 我把它分為兩類:「弱泛化」和「強(qiáng)泛化」。我將會(huì)在后面分別討論它們。 下表總結(jié)了我眼中的研究現(xiàn)狀:
這篇博文涵蓋了相當(dāng)寬泛的研究領(lǐng)域,僅表達(dá)我個(gè)人對(duì)相關(guān)研究的看法,不反映我的同事和公司的觀點(diǎn)。歡迎讀者進(jìn)行討論以及給出修改的建議, 請(qǐng)?jiān)谠u(píng)論中提供反饋或發(fā)送電子郵件給我。
表達(dá)能力 expressivity
模型可以進(jìn)行什么樣的計(jì)算, 擬合多么復(fù)雜的函數(shù)?
模型的表達(dá)能力用來(lái)衡量參數(shù)化模型如神經(jīng)網(wǎng)絡(luò)的可以擬合的函數(shù)的復(fù)雜程度。深度神經(jīng)網(wǎng)絡(luò)的表達(dá)能力隨著它的深度指數(shù)上升, 這意味著中等規(guī)模的神經(jīng)網(wǎng)絡(luò)就擁有表達(dá)監(jiān)督、 半監(jiān)督、強(qiáng)化學(xué)習(xí)任務(wù)的能力[2]。 深度神經(jīng)網(wǎng)絡(luò)可以記住非常大的數(shù)據(jù)集就是一個(gè)很好的佐證。
最近在產(chǎn)生式模型研究上的突破證明了神經(jīng)網(wǎng)絡(luò)強(qiáng)大的表達(dá)能力:神經(jīng)網(wǎng)絡(luò)可以找到幾乎與真實(shí)數(shù)據(jù)難以分辨的極為復(fù)雜的數(shù)據(jù)流形(如音頻, 圖像數(shù)據(jù)的流形)。下面是NVIDIA研究人員提出的新的基于產(chǎn)生式對(duì)抗神經(jīng)網(wǎng)絡(luò)的模型的生成結(jié)果:
產(chǎn)生的圖像仍然不是很完美(注意不自然的背景),但是已經(jīng)非常好了。同樣的, 在音頻合成中,最新的 WaveNet 模型產(chǎn)生的音頻也已經(jīng)非常像人類了。
在強(qiáng)化學(xué)習(xí)中神經(jīng)網(wǎng)絡(luò)看起來(lái)也有足夠的表達(dá)能力。 很小的網(wǎng)絡(luò)(2個(gè)卷積層2個(gè)全連接層)就足夠解決Atari 和 MuJoCo 控制問(wèn)題了(雖然它們的訓(xùn)練還是一個(gè)問(wèn)題,我們將在下一個(gè)部分討論)。
模型的表達(dá)能力問(wèn)題是最容易的(增加一些層即可), 但同時(shí)也是最神秘的:我們無(wú)法找到一個(gè)很好的方法來(lái)度量對(duì)于一個(gè)給定的任務(wù)我們需要多強(qiáng)的(或什么類型的)表達(dá)能力。
什么樣的問(wèn)題會(huì)需要比我們現(xiàn)在用的神經(jīng)網(wǎng)絡(luò)大得多的網(wǎng)絡(luò)?為什么這些任務(wù)需要這么大量的計(jì)算?我們現(xiàn)有的神經(jīng)網(wǎng)絡(luò)是否有足夠的表達(dá)能力來(lái)表現(xiàn)像人類一樣的智能?要解決更加困難的問(wèn)題的泛化問(wèn)題會(huì)需要表達(dá)能力超級(jí)強(qiáng)的模型嗎?
人的大腦有比我們現(xiàn)在的大網(wǎng)絡(luò)(Inception-ResNet-V2 有大概 25e6 ReLU結(jié)點(diǎn))多很多數(shù)量級(jí)的「神經(jīng)節(jié)點(diǎn)」(1e11)。 這個(gè)結(jié)點(diǎn)數(shù)量上的差距已經(jīng)很巨大了, 更別提 ReLU 單元根本無(wú)法比擬生物神經(jīng)元。
訓(xùn)練難度 trainability
給定一個(gè)有足夠表達(dá)能力的模型結(jié)構(gòu), 我能夠訓(xùn)練出一個(gè)好的模型嗎(找到好的參數(shù))
任何一個(gè)從數(shù)據(jù)中學(xué)習(xí)到一定功能的計(jì)算機(jī)程序都可以被稱為機(jī)器學(xué)習(xí)模型。在「學(xué)習(xí)」過(guò)程中, 我們?cè)冢赡芎艽蟮模┠P涂臻g內(nèi)搜索一個(gè)比較好的, 利用數(shù)據(jù)中的知識(shí)學(xué)到的模型來(lái)做決策。 搜索的過(guò)程常常被構(gòu)造成一個(gè)在模型空間上的優(yōu)化問(wèn)題。

優(yōu)化的不同類型
一個(gè)具體的例子:最小化平均交叉熵是訓(xùn)練神經(jīng)網(wǎng)絡(luò)分類圖像的標(biāo)準(zhǔn)方法。我們希望模型在訓(xùn)練集上的交叉熵?fù)p失達(dá)到最小時(shí), 模型在測(cè)試數(shù)據(jù)上可以以一定精度或召回來(lái)正確分類圖像。
搜索好的模型(訓(xùn)練)最終會(huì)變?yōu)橐粋€(gè)優(yōu)化問(wèn)題——沒(méi)有別的途徑! 但是有時(shí)候我們很難去定義優(yōu)化目標(biāo)。 在監(jiān)督學(xué)習(xí)中的一個(gè)經(jīng)典的例子就是圖像下采樣:我們無(wú)法定義一個(gè)標(biāo)量可以準(zhǔn)確反映出我們?nèi)搜鄹惺艿降南虏蓸釉斐傻摹敢曈X(jué)損失」。
同樣地, 超分辨率圖像和圖像合成也非常困難,因?yàn)槲覀兒茈y把效果的好壞寫成一個(gè)標(biāo)量的最大化目標(biāo):想象一下, 如何設(shè)計(jì)一個(gè)函數(shù)來(lái)判斷一張圖片有多像一張真實(shí)的照片?事實(shí)上關(guān)于如何去評(píng)價(jià)一個(gè)產(chǎn)生式模型的好壞一直爭(zhēng)論到現(xiàn)在。
近年來(lái)最受歡迎的的方法是 「協(xié)同適應(yīng)」(co-adaptation)方法:它把優(yōu)化問(wèn)題構(gòu)造成求解兩個(gè)相互作用演化的非平穩(wěn)分布的平衡點(diǎn)求解問(wèn)題[3]。這種方法比較「自然」, 我們可以將它類比為捕食者和被捕食者之間的生態(tài)進(jìn)化過(guò)程。
捕食者會(huì)逐漸變得聰明, 這樣它可以更有效地捕獲獵物。然后被捕食者也逐漸變得更聰明以避免被捕食。兩種物種相互促進(jìn)進(jìn)化, 最終它們都會(huì)變得更加聰明。
演化策略通常把優(yōu)化看作是仿真。用戶對(duì)模型群體指定一些動(dòng)力系統(tǒng), 在仿真過(guò)程中的每個(gè)時(shí)間步上, 根據(jù)動(dòng)力系統(tǒng)的運(yùn)行規(guī)則來(lái)更新模型群體。 這些模型可能會(huì)相互作用也可能不會(huì)。 隨著時(shí)間的演變, 系統(tǒng)的動(dòng)態(tài)特性可能會(huì)使模型群體最終收斂到好的模型上面。
David Ha所著的 《A Visual Guide to Evolution Strategies》 是一部非常好的演化策略在強(qiáng)化學(xué)習(xí)中應(yīng)用的教材(其中的「參考文獻(xiàn)和延伸閱讀」部分非常棒!)
研究現(xiàn)狀
監(jiān)督學(xué)習(xí)中前饋神經(jīng)網(wǎng)絡(luò)和有顯式目標(biāo)函數(shù)的問(wèn)題已經(jīng)基本解決了(經(jīng)驗(yàn)之談, 沒(méi)有理論保障)。2015年發(fā)表的一些重要的突破(批歸一化 Batch Norm,殘差網(wǎng)絡(luò) Resnets,良好初始化 Good Init)現(xiàn)在被廣泛使用, 這使得前饋神經(jīng)網(wǎng)絡(luò)的訓(xùn)練變得非常容易。
事實(shí)上, 數(shù)百層的深度網(wǎng)絡(luò)已經(jīng)可以把大的分類數(shù)據(jù)集的訓(xùn)練損失減小到零。關(guān)于現(xiàn)代深度神經(jīng)網(wǎng)絡(luò)的硬件和算法基礎(chǔ)結(jié)構(gòu),參考 https://arxiv.org/abs/1703.09039。
有證據(jù)表明很多 RNN 結(jié)構(gòu)有相同的表達(dá)能力, 模型最終效果的差異僅僅是由于一些結(jié)構(gòu)比另一些更加易于訓(xùn)練[4]。
無(wú)監(jiān)督學(xué)習(xí)的模型輸出常常大很多(并不是總是),比如,1024 x 1024 像素的圖片, 很長(zhǎng)的語(yǔ)音和文本序列。很不幸, 這導(dǎo)致模型更加難以訓(xùn)練。
最近 NVIDA 的工作改進(jìn)了Wasserstein GAN 使之對(duì)很多超參, 比如 BN 的參數(shù)、網(wǎng)絡(luò)結(jié)構(gòu)等不再敏感。模型的穩(wěn)定性在實(shí)踐和工業(yè)應(yīng)用中非常重要:穩(wěn)定性讓我們相信它會(huì)和我們未來(lái)的研究思路和應(yīng)用相兼容。
總的來(lái)講, 這些成果令人振奮, 因?yàn)檫@證明了我們的產(chǎn)生網(wǎng)絡(luò)有足夠的表達(dá)能力來(lái)產(chǎn)生正確的圖像, 效果的瓶頸在于訓(xùn)練的問(wèn)題——不幸的是對(duì)于神經(jīng)網(wǎng)絡(luò)來(lái)講我們很難辯別一個(gè)模型表現(xiàn)較差僅僅是因?yàn)樗谋磉_(dá)能力不夠還是我們沒(méi)有訓(xùn)練到位。
不幸的是, 即使在僅僅考慮可訓(xùn)練性,不考慮泛化的情況下, 強(qiáng)化學(xué)習(xí)也遠(yuǎn)遠(yuǎn)地落在了后面。在有多于一個(gè)時(shí)間步的環(huán)境中, 我們實(shí)際是在首先搜索一個(gè)模型, 這個(gè)模型在推理階段會(huì)最大化獲得的獎(jiǎng)勵(lì)。
強(qiáng)化學(xué)習(xí)比較困難,因?yàn)槲覀円靡粋€(gè)外部的(outer loop)、僅僅依賴角色(agent)見(jiàn)過(guò)的數(shù)據(jù)的優(yōu)化過(guò)程來(lái)找到最優(yōu)的模型, 同時(shí)用一個(gè)內(nèi)部的(inner loop)、模型引導(dǎo)的最優(yōu)控制(optimal control)過(guò)程來(lái)最大化獲得的獎(jiǎng)勵(lì)。
不同環(huán)境下,實(shí)現(xiàn)同樣的算法我們經(jīng)常得到不同的結(jié)果, 因此強(qiáng)化學(xué)習(xí)文章中報(bào)告的結(jié)果我們也不能輕易完全相信。
如果我們把強(qiáng)化學(xué)習(xí)看作一個(gè)單純的優(yōu)化問(wèn)題(先不考慮模型的泛化和復(fù)雜的任務(wù)), 這個(gè)問(wèn)題同樣非常棘手。假設(shè)現(xiàn)在有一個(gè)環(huán)境, 只有在一個(gè)場(chǎng)景結(jié)束時(shí)才會(huì)有非常稀疏的獎(jiǎng)勵(lì)(例如:保姆照看孩子, 只有在父母回家時(shí)她才會(huì)得到酬勞)。
因此, 要想估計(jì)模型優(yōu)化過(guò)程中任意一處的策略梯度, 我們都要采樣指數(shù)增長(zhǎng)的動(dòng)作空間(action space)中的樣本來(lái)獲得一些對(duì)學(xué)習(xí)有用的信號(hào)。這就像是我們想要使用蒙特卡洛方法關(guān)于一個(gè)分布計(jì)算期望(在所有動(dòng)作序列上), 而這個(gè)分布集中于一個(gè)狄拉克函數(shù)(dirac delta distribution)(密度函數(shù)見(jiàn)下圖)。
在建議分布(proposal distribution)和獎(jiǎng)勵(lì)分布(reward distribution)之間幾乎沒(méi)有重疊時(shí), 基于有限樣本的蒙特卡洛估計(jì)會(huì)失效,不管你采了多少樣本。

此外, 如果數(shù)據(jù)布不是平穩(wěn)的(比如我們采用帶有重放緩存 replay buffer 的離策略 off-policy 算法), 數(shù)據(jù)中的「壞點(diǎn)」會(huì)給外部的優(yōu)化過(guò)程(outer loop)提供不穩(wěn)定的反饋。
不從蒙特卡洛估計(jì)的角度, 而從優(yōu)化的角度來(lái)看的話:在沒(méi)有關(guān)于狀態(tài)空間的任何先驗(yàn)的情況下(比如對(duì)于世界環(huán)境的理解或者顯式地給角色 agent 一些明確的指示), 優(yōu)化目標(biāo)函數(shù)的形狀(optimization landscape)看起來(lái)就像「瑞士芝士」——一個(gè)個(gè)凸的極值(看作小孔)周圍都是大面積的平地,這樣平坦的「地形」上策略梯度信息幾乎沒(méi)用。這意味著整個(gè)模型空間幾乎不包含信息(非零的區(qū)域幾乎沒(méi)有,學(xué)習(xí)的信號(hào)在整個(gè)模型空間里是均勻的)。
如果沒(méi)有更好的表示方法,我們可能就僅僅是在隨機(jī)種子附近游走,隨機(jī)采樣一些策略,直到我們幸運(yùn)地找到一個(gè)恰好落在「芝士的洞里」的模型。事實(shí)上,這樣訓(xùn)練出的模型效果其實(shí)很好。這說(shuō)明強(qiáng)化學(xué)習(xí)的優(yōu)化目標(biāo)函數(shù)形狀很有可能就是這樣子的。
我相信像 Atari 和 MuJoCo 這樣的強(qiáng)化學(xué)習(xí)基準(zhǔn)模型并沒(méi)有真正提高機(jī)器學(xué)習(xí)的能力極限, 雖然從一個(gè)單純優(yōu)化問(wèn)題來(lái)看它們很有趣。這些模型還只是在一個(gè)相對(duì)簡(jiǎn)單的環(huán)境中去尋找單一的策略來(lái)使模型表現(xiàn)得更好, 沒(méi)有任何的選擇性機(jī)制讓他們可以泛化。 也就是說(shuō), 它們還僅僅是單純的優(yōu)化問(wèn)題, 而不是一個(gè)復(fù)雜的機(jī)器學(xué)習(xí)問(wèn)題。
要想解決更高維,更復(fù)雜的強(qiáng)化學(xué)習(xí)問(wèn)題, 在解決數(shù)值優(yōu)化問(wèn)題之前,我們必須先考慮模型的泛化和一般的感性認(rèn)知能力。反之就會(huì)愚蠢地浪費(fèi)計(jì)算力和數(shù)據(jù)(當(dāng)然這可能會(huì)讓我們明白僅僅通過(guò)暴力計(jì)算我們可以做得多好)。
我們要讓每個(gè)數(shù)據(jù)點(diǎn)都給強(qiáng)化學(xué)習(xí)提供訓(xùn)練信息,也需要能夠在不用指數(shù)增長(zhǎng)的數(shù)據(jù)時(shí)就能通過(guò)重要性采樣(importance sampling)獲得非常復(fù)雜的問(wèn)題的梯度。只有在這樣的情況下, 我們才能確保通過(guò)暴力計(jì)算我們可以獲得這個(gè)問(wèn)題的解。
最后做一個(gè)總結(jié):監(jiān)督學(xué)習(xí)的訓(xùn)練比較容易。 無(wú)監(jiān)督學(xué)習(xí)的訓(xùn)練相對(duì)困難但是已經(jīng)取得了很大的進(jìn)展。但是對(duì)于強(qiáng)化學(xué)習(xí),訓(xùn)練還是一個(gè)很大的問(wèn)題。
泛化性能
在這三個(gè)問(wèn)題中, 泛化性能是最深刻的,也是機(jī)器學(xué)習(xí)的核心問(wèn)題。簡(jiǎn)單來(lái)講, 泛化性能用來(lái)衡量一個(gè)在訓(xùn)練集上訓(xùn)練好的模型在測(cè)試集上的表現(xiàn)。
泛化問(wèn)題主要可以分為兩大類:
1) 訓(xùn)練數(shù)據(jù)與測(cè)試數(shù)據(jù)來(lái)自于同一個(gè)分布(我們使用訓(xùn)練集來(lái)學(xué)習(xí)這個(gè)分布)。
2)訓(xùn)練數(shù)據(jù)與測(cè)試數(shù)據(jù)來(lái)自不同的分布(我們要讓在訓(xùn)練集上學(xué)習(xí)的模型在測(cè)試集上也表現(xiàn)良好)。
通常我們把(1)稱為「弱泛化」,把(2)稱為「強(qiáng)泛化」。我們也可以把它們理解為「內(nèi)插(interpolation)」和「外推(extrapolation)」,或「魯棒性(robustness)」與「理解(understanding)」。
弱泛化:考慮訓(xùn)練集與測(cè)試集數(shù)據(jù)服從兩個(gè)類似的分布
如果數(shù)據(jù)的分布發(fā)生了較小的擾動(dòng), 模型還能表現(xiàn)得多好?
在「弱泛化」中,我們通常假設(shè)訓(xùn)練集和數(shù)據(jù)集的數(shù)據(jù)分布是相同的。但是在實(shí)際問(wèn)題中,即使是「大樣本」(large sample limit)情況下,二者的分布也總會(huì)有些許差異。
這些差異有可能來(lái)源于傳感器噪聲、物體的磨損、周圍光照條件的變化(可能攝影者收集測(cè)試集數(shù)據(jù)時(shí)恰好是陰天)。對(duì)抗樣本的出現(xiàn)也可能導(dǎo)致一些不同,對(duì)抗的擾動(dòng)很難被人眼分辨,因此我們可以認(rèn)為對(duì)抗樣本也是從相同的分布里采出來(lái)的。
因此,實(shí)踐中把「弱泛化」看作是評(píng)估模型在「擾動(dòng)」的訓(xùn)練集分布上的表現(xiàn)是有用的。

數(shù)據(jù)分布的擾動(dòng)也會(huì)導(dǎo)致優(yōu)化目標(biāo)函數(shù)(optimization landscape)的擾動(dòng)。
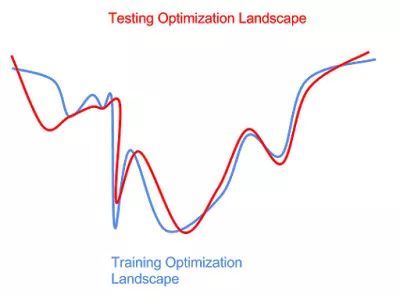
不能事先知道測(cè)試數(shù)據(jù)的分布為我們優(yōu)化帶來(lái)了一些困難。如果我們?cè)谟?xùn)練集上優(yōu)化得過(guò)于充分(上圖藍(lán)色曲線左邊的最低的局部極小點(diǎn)), 我們會(huì)得到一個(gè)在測(cè)試集上并不是最好的模型(紅色曲線左邊的局部極小點(diǎn))。 這時(shí), 我們就在訓(xùn)練集上過(guò)擬合(overfitting)了, 模型在測(cè)試集上沒(méi)有很好地泛化。
「正則化」包含一切我們用來(lái)防止過(guò)擬合的手段。我們一點(diǎn)都不知道測(cè)試集分布的擾動(dòng)是什么,所以我們只能在訓(xùn)練集或訓(xùn)練過(guò)程中加入噪聲,希望這些引入的噪聲中會(huì)包含測(cè)試集上的擾動(dòng)。隨機(jī)梯度下降、隨機(jī)剪結(jié)點(diǎn)(dropout)、權(quán)值噪聲(weight noise)、 激活噪聲(activation noise)、 數(shù)據(jù)增強(qiáng)等都是深度學(xué)習(xí)中常用的正則化技術(shù)。在強(qiáng)化學(xué)習(xí)中,隨機(jī)仿真參數(shù)(randomizing simulation parameters)會(huì)讓訓(xùn)練變得更加魯棒。張馳原在 ICLR2017 的報(bào)告中認(rèn)為正則化是所有的可能「增加訓(xùn)練難度」的方法(而不是傳統(tǒng)上認(rèn)為的「限制模型容量」)。總的來(lái)講,讓優(yōu)化變得困難一些有助于模型的泛化。
對(duì)于弱泛化最大的挑戰(zhàn)可能就是對(duì)抗攻擊了。 對(duì)抗方法會(huì)產(chǎn)生對(duì)模型最糟糕的的干擾,在這些擾動(dòng)下模型會(huì)表現(xiàn)得非常差。 我們現(xiàn)在還沒(méi)有對(duì)對(duì)抗樣本魯棒的深度學(xué)習(xí)方法, 但是我感覺(jué)這個(gè)問(wèn)題最終會(huì)得到解決[5]。
現(xiàn)在有一些利用信息論的工作表明在訓(xùn)練過(guò)程中神經(jīng)網(wǎng)絡(luò)會(huì)明顯地經(jīng)歷一個(gè)由「記住」數(shù)據(jù)到」壓縮」數(shù)據(jù)的轉(zhuǎn)換。這種理論正在興起,雖然仍然有關(guān)于這種理論是不是真的有效的討論。請(qǐng)關(guān)注這個(gè)理論,這個(gè)關(guān)于「記憶」和」壓縮」的直覺(jué)是令人信服的。
強(qiáng)泛化:自然流形
在強(qiáng)泛化范疇,模型是在完全不同的數(shù)據(jù)分布上進(jìn)行評(píng)估的, 但是數(shù)據(jù)來(lái)自于同一個(gè)流形(或數(shù)據(jù)產(chǎn)生過(guò)程)
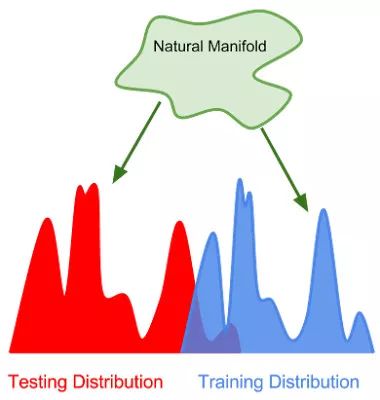
如果測(cè)試數(shù)據(jù)分布于訓(xùn)練數(shù)據(jù)分布「完全不同」,我們?nèi)绾蝸?lái)訓(xùn)練一個(gè)好的模型呢?實(shí)際上這些數(shù)據(jù)都來(lái)自同一個(gè)「自然數(shù)據(jù)流形」(natural data manifold)。只要來(lái)源于同一個(gè)數(shù)據(jù)產(chǎn)生過(guò)程,訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)仍然含有很多的信息交疊。
強(qiáng)泛化可以看作是模型可以多好地學(xué)到這個(gè)「超級(jí)流形」,訓(xùn)練這個(gè)模型只使用了流形上的很小一部分樣本。一個(gè)圖像分類器不需要去發(fā)現(xiàn)麥克斯韋方程組——它只需要理解與流形上的數(shù)據(jù)點(diǎn)相一致的事實(shí)。
在 ImageNet 上訓(xùn)練的現(xiàn)代分類器已經(jīng)基本上可以做到強(qiáng)泛化了。模型已經(jīng)可以理解基礎(chǔ)的元素比如邊緣、輪廓以及實(shí)體。這也是為什么常常會(huì)把這些分類器的權(quán)值遷移到其它數(shù)據(jù)集上來(lái)進(jìn)行少樣本學(xué)習(xí)(few shot learning)和度量學(xué)習(xí)(metric learning)。
和弱泛化一樣,我們可以對(duì)抗地采樣測(cè)試集來(lái)讓它的數(shù)據(jù)分布與訓(xùn)練集盡量不同。AlphaGo Zero 是我最喜歡的例子:在測(cè)試階段,它看到的是與它在訓(xùn)練階段完全不一樣的, 來(lái)自人類選手的數(shù)據(jù)。
遺憾的是, 強(qiáng)化學(xué)習(xí)的研究忽略了強(qiáng)泛化問(wèn)題。 大部分的基準(zhǔn)都基于靜態(tài)的環(huán)境, 沒(méi)有多少認(rèn)知的內(nèi)容(比如人型機(jī)器人只知道一些關(guān)節(jié)的位置可能會(huì)帶來(lái)獎(jiǎng)勵(lì), 而不知道它的它的世界和它的身體是什么樣子的)。
我相信解決強(qiáng)化學(xué)習(xí)可訓(xùn)練性問(wèn)題的關(guān)鍵在于解決泛化性。我們的學(xué)習(xí)系統(tǒng)對(duì)世界的理解越多,它就更容易獲得學(xué)習(xí)的信號(hào)可能需要更少的樣本。這也是為什么說(shuō)少樣本學(xué)習(xí)(few shot learning)、模仿學(xué)習(xí)(imitation learning)、學(xué)習(xí)如何學(xué)習(xí)(learning to learn)重要的原因了:它們將使我們擺脫采用方差大而有用信息少的暴力求解方式。
我相信要達(dá)到更強(qiáng)的泛化,我們要做到兩件事:
首先我們需要模型可以從觀察和實(shí)驗(yàn)中積極推理世界基本規(guī)律。符號(hào)推理(symbolic reasoning)和因果推理(causal inference)看起來(lái)已經(jīng)是成熟的研究了, 但是對(duì)任何一種無(wú)監(jiān)督學(xué)習(xí)可能都有幫助。
我們的基于模型的機(jī)器學(xué)習(xí)方法(試圖去「預(yù)測(cè)」環(huán)境的模型)現(xiàn)在正處于哥白尼革命之前的時(shí)期:它們僅僅是膚淺地基于一些統(tǒng)計(jì)原理進(jìn)行內(nèi)插,而不是提出深刻的,一般性的原理來(lái)解釋和推斷可能在數(shù)百萬(wàn)光年以外或很久遠(yuǎn)的未來(lái)的事情。
注意人類不需要對(duì)概率論有很好的掌握就能推導(dǎo)出確定性的天體力學(xué),這就產(chǎn)生了一個(gè)問(wèn)題:是否有可能在沒(méi)有明確的統(tǒng)計(jì)框架下進(jìn)行機(jī)器學(xué)習(xí)和因果推理?
讓我們的學(xué)習(xí)系統(tǒng)更具適應(yīng)性可以大大降低復(fù)雜性。我們需要訓(xùn)練可以在線實(shí)時(shí)地思考、記憶、學(xué)習(xí)的模型,而不僅僅是只能靜態(tài)地預(yù)測(cè)和行動(dòng)的模型。
其次, 我們需要把足夠多樣的數(shù)據(jù)送給模型來(lái)促使它學(xué)到更為抽象的表示。
沒(méi)有這些限制的話,學(xué)習(xí)本身就是欠定義的,我們能夠恰好找到一個(gè)好的解的可能性也非常小。 也許如果人類不能站起來(lái)看到天空,就不會(huì)想要知道為什么星星會(huì)以這樣奇怪的橢圓形軌跡運(yùn)行,也就不會(huì)獲得智慧。
-
AI
+關(guān)注
關(guān)注
88文章
35093瀏覽量
279526 -
人工智能
+關(guān)注
關(guān)注
1806文章
49008瀏覽量
249305 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8501瀏覽量
134579
原文標(biāo)題:如何理解和評(píng)價(jià)機(jī)器學(xué)習(xí)中的表達(dá)能力、訓(xùn)練難度和泛化性能
文章出處:【微信號(hào):AItists,微信公眾號(hào):人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Debian和Ubuntu哪個(gè)好一些?
嵌入式AI技術(shù)之深度學(xué)習(xí):數(shù)據(jù)樣本預(yù)處理過(guò)程中使用合適的特征變換對(duì)深度學(xué)習(xí)的意義
獨(dú)立服務(wù)器和云服務(wù)器哪個(gè)快一些?
zeta在機(jī)器學(xué)習(xí)中的應(yīng)用 zeta的優(yōu)缺點(diǎn)分析
【面試題】人工智能工程師高頻面試題匯總:機(jī)器學(xué)習(xí)深化篇(題目+答案)
傅立葉變換在機(jī)器學(xué)習(xí)中的應(yīng)用 常見(jiàn)傅立葉變換的誤區(qū)解析
人工智能工程師高頻面試題匯總——機(jī)器學(xué)習(xí)篇

一些常見(jiàn)的動(dòng)態(tài)電路

什么是機(jī)器學(xué)習(xí)?通過(guò)機(jī)器學(xué)習(xí)方法能解決哪些問(wèn)題?

eda在機(jī)器學(xué)習(xí)中的應(yīng)用
分享一些常見(jiàn)的電路
具身智能與機(jī)器學(xué)習(xí)的關(guān)系
LED驅(qū)動(dòng)器應(yīng)用的一些指南和技巧






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論