") DeepSeek MoE架構(gòu)下的網(wǎng)絡(luò)負(fù)載如何優(yōu)化?解鎖90%網(wǎng)絡(luò)利用率的關(guān)鍵策略
DeepSeek MoE架構(gòu)下的網(wǎng)絡(luò)負(fù)載如何優(yōu)化?解鎖90%網(wǎng)絡(luò)利用率的關(guān)鍵策略
在人工智能技術(shù)快速發(fā)展的浪潮下,現(xiàn)代數(shù)據(jù)中心網(wǎng)絡(luò)正面臨著前所未有的挑戰(zhàn)。GPT大模型的參數(shù)量已突破萬(wàn)億級(jí)別,自動(dòng)駕駛訓(xùn)練需要處理PB級(jí)的場(chǎng)景數(shù)據(jù),這些都使得AI計(jì)算集群規(guī)模呈指數(shù)級(jí)增長(zhǎng)。
根據(jù)OpenAI披露的數(shù)據(jù),GPT-4訓(xùn)練使用的GPU數(shù)量已超過(guò)25,000個(gè),這種大規(guī)模并行計(jì)算架構(gòu)對(duì)網(wǎng)絡(luò)性能提出了嚴(yán)苛要求:網(wǎng)絡(luò)傳輸時(shí)延需要控制在微秒級(jí),帶寬利用率必須達(dá)到80%以上,任何網(wǎng)絡(luò)抖動(dòng)都會(huì)直接導(dǎo)致算力資源的閑置浪費(fèi)。
統(tǒng)計(jì)數(shù)據(jù)顯示,傳統(tǒng)以太網(wǎng)的平均利用率長(zhǎng)期徘徊在35%-40%,這意味著超過(guò)60%的網(wǎng)絡(luò)帶寬資源處于閑置狀態(tài)。這種低效不僅造成巨額硬件投資浪費(fèi),更成為制約AI訓(xùn)練效率的關(guān)鍵瓶頸。
傳統(tǒng)以太網(wǎng)的困境
網(wǎng)絡(luò)利用率作為衡量實(shí)際傳輸流量與理論帶寬比值的核心指標(biāo),在AI計(jì)算場(chǎng)景中直接決定模型訓(xùn)練周期。這種效率瓶頸源于多重技術(shù)桎梏:
- 流量復(fù)雜度倍增:現(xiàn)代數(shù)據(jù)中心混合承載著AI訓(xùn)練的長(zhǎng)流(Long Flow)、推理服務(wù)的短流(Short Flow)、存儲(chǔ)復(fù)制的大包(Jumbo Frame)以及管理信令的小包(Mouse Flow)。這種流量形態(tài)的多樣性導(dǎo)致網(wǎng)絡(luò)必須按"峰值突發(fā)量×安全冗余"的超配模式建設(shè),造成非峰值期大量帶寬閑置。
- 架構(gòu)性阻塞難題:經(jīng)典的接入-匯聚-核心三級(jí)架構(gòu)存在天然的收斂比限制。以典型4:1收斂比設(shè)計(jì)為例,當(dāng)接入層40G鏈路滿載時(shí),匯聚層100G鏈路的理論利用率僅能達(dá)到80%,若考慮流量潮汐效應(yīng),實(shí)際利用率常低于50%。
- 丟包引發(fā)的鏈?zhǔn)椒磻?yīng):傳統(tǒng)QoS機(jī)制采用尾丟棄(Tail Drop)或WRED隨機(jī)丟棄策略應(yīng)對(duì)擁塞,這種"先污染后治理"的方式觸發(fā)TCP超時(shí)重傳,導(dǎo)致有效帶寬被重傳數(shù)據(jù)重復(fù)占用。實(shí)測(cè)表明,1%的丟包率即可造成吞吐量下降40%。
- 流控機(jī)制鈍化:基于ECN的擁塞通知僅能傳遞1bit信息,終端設(shè)備需通過(guò)"探測(cè)-降速-恢復(fù)"的試探性調(diào)節(jié)適應(yīng)帶寬變化。這種開環(huán)控制方式在應(yīng)對(duì)AI訓(xùn)練中的All-Reduce等集合通信時(shí),調(diào)節(jié)延遲常超過(guò)100ms,造成帶寬利用的階段性塌陷。
- 路徑調(diào)度失衡:依賴五元組哈希的ECMP算法,在面對(duì)AI訓(xùn)練中持續(xù)時(shí)間長(zhǎng)達(dá)數(shù)小時(shí)、帶寬需求穩(wěn)定的"大象流"時(shí),極易引發(fā)路徑選擇的極化現(xiàn)象。某知名云廠商的故障案例顯示,40%的等價(jià)鏈路處于空載狀態(tài)時(shí),剩余60%鏈路卻持續(xù)過(guò)載丟包。
超級(jí)以太網(wǎng)的技術(shù)突圍
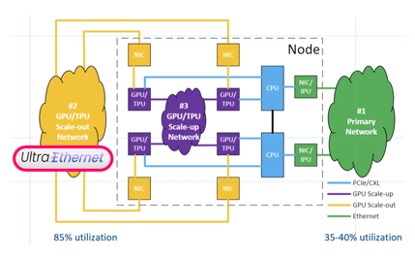
為突破85%網(wǎng)絡(luò)利用率的目標(biāo),超級(jí)以太網(wǎng)聯(lián)盟(UEC)提出系統(tǒng)性解決方案:
1、專用通道隔離:利用AI流量可預(yù)測(cè)特性構(gòu)建物理隔離的RoCEv2專用網(wǎng)絡(luò)。某頭部AI實(shí)驗(yàn)室的實(shí)踐表明,通過(guò)分離訓(xùn)練流量與存儲(chǔ)流量,網(wǎng)絡(luò)有效利用率提升27%,GPU空閑等待時(shí)間減少41%。
2、無(wú)阻塞拓?fù)洌何覀冃枰O(shè)計(jì)無(wú)阻塞的網(wǎng)絡(luò)結(jié)構(gòu),如CLOS、Dragonfly, Torus, MegaFly, SlimFly等。目前,CLOS是最流行的網(wǎng)絡(luò)結(jié)構(gòu) [3],在這個(gè)網(wǎng)絡(luò)結(jié)構(gòu)中,總接入帶寬與總匯聚帶寬相等,并容易在縱向和橫向上擴(kuò)展,在宏觀上實(shí)現(xiàn)了無(wú)阻塞。然而由于流量不均衡和微突發(fā)現(xiàn)象的存在,在局部鏈路上,擁塞仍然會(huì)存在。
3、精準(zhǔn)擁塞控制升級(jí):當(dāng)In-Cast擁塞產(chǎn)生后,目前主要通過(guò)端到端的流控機(jī)制來(lái)緩解這一問題。例如,基于ECN的DCQCN/DCTCP技術(shù)通過(guò)調(diào)節(jié)源端的發(fā)送流量速率,適應(yīng)網(wǎng)絡(luò)的可用帶寬。由于ECN攜帶的信息只有1個(gè)bit,這種調(diào)節(jié)方式不夠精確。為了解決這一問題,UEC傳輸層(UET,Ultra Ethernet Transport Layer)提出了以下改進(jìn)措施:
- 加速調(diào)整過(guò)程:UET通過(guò)測(cè)量端到端延遲來(lái)調(diào)節(jié)發(fā)送速率,并根據(jù)接收方的能力通知發(fā)送方調(diào)整速率,快速達(dá)到線速。
- 基于遙測(cè):來(lái)自網(wǎng)絡(luò)的擁塞信息可以通告擁塞的位置和原因,縮短擁塞信令路徑并向終端節(jié)點(diǎn)提供更多信息,從而實(shí)現(xiàn)更快的擁塞響應(yīng)。
4、包噴灑:突破傳統(tǒng)流級(jí)調(diào)度的"包噴灑"技術(shù),通過(guò)動(dòng)態(tài)路徑選擇算法將數(shù)據(jù)包離散分布在多條路徑,從而更充分地利用網(wǎng)絡(luò)帶寬。由于這種方式會(huì)導(dǎo)致目的地接收到的報(bào)文亂序,因此需要修改傳輸協(xié)議,允許包亂序到達(dá),并在目的地重新組裝為完整的消息。然而,重組過(guò)程帶來(lái)了額外的開銷,增加了整個(gè)流的延遲,且目的端需要等待該流的所有包傳輸完畢后才能處理整個(gè)消息,無(wú)法實(shí)現(xiàn)流水線操作。
實(shí)踐突破
作為UEC核心成員,星融元通過(guò)三大技術(shù)創(chuàng)新將網(wǎng)絡(luò)利用率推升至90%:
Flowlet
前面提到,基于流的ECMP容易造成負(fù)載不均衡,而包噴灑技術(shù)又帶來(lái)了額外的延遲。有沒有兩全其美的技術(shù)?flowlet應(yīng)運(yùn)而生。Flowlet是根據(jù)流中的“空閑”時(shí)間間隔將一個(gè)流劃分為若干片段。在一個(gè)flowlet內(nèi),數(shù)據(jù)包在時(shí)間上緊密連續(xù);而兩個(gè)flowlet之間,存在較大的時(shí)間間隔。這一間隔遠(yuǎn)大于同一流分片內(nèi)數(shù)據(jù)包之間的時(shí)間間隔,足以使兩個(gè)流分片通過(guò)不同的網(wǎng)絡(luò)路徑傳輸而不發(fā)生亂序。

并行計(jì)算過(guò)程中,計(jì)算和通信是交替進(jìn)行的。因而AI并行訓(xùn)練和推理產(chǎn)生的流量是典型的flowlet。
當(dāng)網(wǎng)絡(luò)發(fā)生擁塞時(shí),可將flowlet調(diào)度到較空閑的鏈路上以緩解壓力。在AI訓(xùn)練和推理網(wǎng)絡(luò)中,RDMA流通常較持久,訓(xùn)練流可能持續(xù)數(shù)分鐘至數(shù)小時(shí),推理流多為數(shù)秒至數(shù)分鐘,而flowlet則以微秒到毫秒級(jí)的短暫突發(fā)為主。這種基于flowlet的精細(xì)調(diào)度能有效優(yōu)化流量分配,顯著降低網(wǎng)絡(luò)擁塞,從而提高網(wǎng)絡(luò)利用率。
基于遙測(cè)的路由
將傳統(tǒng)OSPF的靜態(tài)度量升級(jí)為時(shí)延、丟包、利用率等多維度動(dòng)態(tài)權(quán)重。通過(guò)部署在Spine層的分布式?jīng)Q策單元,實(shí)現(xiàn)10ms級(jí)別的全網(wǎng)狀態(tài)同步與路徑重計(jì)算。某自動(dòng)駕駛公司的實(shí)測(cè)表明,突發(fā)流量下的路徑切換延遲從秒級(jí)降至毫秒級(jí)。
基于遙測(cè)的路由(Int-based Routing)技術(shù)結(jié)合OSPF、BGP和在網(wǎng)遙測(cè)(INT)技術(shù),為網(wǎng)絡(luò)中任意一對(duì)節(jié)點(diǎn)之間計(jì)算多條路徑,每個(gè)路徑的開銷是動(dòng)態(tài)測(cè)量的延遲,從而能夠根據(jù)實(shí)時(shí)的網(wǎng)絡(luò)負(fù)載進(jìn)行路由,從而充分利用每個(gè)路徑的帶寬。
WCMP
ECMP技術(shù)將包、flowlet或整個(gè)流均勻的分布到多個(gè)路徑上,忽略了不同路徑上的實(shí)際負(fù)載。為了進(jìn)一步提升網(wǎng)絡(luò)利用率。星融元采用加權(quán)代價(jià)多路徑(Weighted Cost Multiple Path)算法,基于遙測(cè)獲取的時(shí)延等信息,在時(shí)延更低的路徑上調(diào)度更多的流量,在時(shí)延更高的路徑上調(diào)度更少的流量,從而實(shí)現(xiàn)所有路徑的公平利用。在理想情況下,流量經(jīng)過(guò)不同路徑的總時(shí)延是相等的,可充分利用所有可用帶寬。
隨著AI大模型參數(shù)規(guī)模突破10萬(wàn)億,超級(jí)以太網(wǎng)正從技術(shù)概念演變?yōu)樗懔A(chǔ)設(shè)施的關(guān)鍵支柱。通過(guò)架構(gòu)革新與協(xié)議棧重構(gòu),網(wǎng)絡(luò)利用率突破90%已具備工程可行性。這不僅意味著數(shù)據(jù)中心OPEX的大幅降低,更將推動(dòng)AI訓(xùn)練效率進(jìn)入新的數(shù)量級(jí),加速通用人工智能時(shí)代的到來(lái)。
【參考文獻(xiàn)】
[1] Ultra Ethernet Consortium, “Ultra Ethernet Introduction” 15th October 2024.
[2] Asterfusion, “Unveiling AI Data Center Network Traffic” https://cloudswit.ch/blogs/ai-data-center-network-traffic/.
[3] Asterfusion, “What is Leaf-Spine Architecture and How to Build it?” https://cloudswit.ch/blogs/what-is-leaf-spine-architecture-and-how-to-build-it/.
-
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
7780瀏覽量
90465 -
負(fù)載均衡
+關(guān)注
關(guān)注
0文章
119瀏覽量
12542 -
DeepSeek
+關(guān)注
關(guān)注
1文章
783瀏覽量
1419
發(fā)布評(píng)論請(qǐng)先 登錄
【書籍評(píng)測(cè)活動(dòng)NO.62】一本書讀懂 DeepSeek 全家桶核心技術(shù):DeepSeek 核心技術(shù)揭秘
雙智網(wǎng)絡(luò)概述和關(guān)鍵技術(shù)

拼版怎么拼好,板廠經(jīng)常說(shuō)利用率太低,多收費(fèi)用?
mes工廠管理系統(tǒng):如何讓設(shè)備利用率提升50%?
DeepSeek推動(dòng)AI算力需求:800G光模塊的關(guān)鍵作用
MPLS網(wǎng)絡(luò)性能優(yōu)化技巧
了解DeepSeek-V3 和 DeepSeek-R1兩個(gè)大模型的不同定位和應(yīng)用選擇
DeepSeek對(duì)芯片算力的影響

解析DeepSeek MoE并行計(jì)算優(yōu)化策略
華納云:什么是負(fù)載均衡?優(yōu)化資源利用率的策略
交換機(jī)內(nèi)存利用率過(guò)高會(huì)是什么問題
HTTP海外訪問優(yōu)化:提升跨國(guó)網(wǎng)絡(luò)性能的秘訣
如何利用traceroute命令發(fā)現(xiàn)網(wǎng)絡(luò)中的負(fù)載均衡





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論