") 蘋芯科技 N300 存算一體 NPU,開啟端側(cè) AI 新征程
蘋芯科技 N300 存算一體 NPU,開啟端側(cè) AI 新征程
文章轉(zhuǎn)自:愛集微
作者:陳炳欣
隨著端側(cè)人工智能技術(shù)的爆發(fā)式增長,智能設(shè)備對本地算力與能效的需求日益提高。而傳統(tǒng)馮·諾依曼架構(gòu)在數(shù)據(jù)處理效率上存在瓶頸,“內(nèi)存墻”問題成為制約端側(cè)AI性能突破的關(guān)鍵掣肘。在這一背景下,存算一體芯片憑借低功耗、高帶寬,以及相對的通用性能,正在成為賦能智能終端、物聯(lián)網(wǎng)設(shè)備以及邊緣計算場景的核心動力。
科技創(chuàng)新企業(yè)蘋芯科技深耕存算一體技術(shù),推出N300存算一體NPU,在不改變傳統(tǒng)MCU形態(tài)的同時為傳統(tǒng)MCU芯片賦予AI能力,突破傳統(tǒng)MCU的算力瓶頸,為端側(cè)設(shè)備加載AI提供了革命性的解決方案。蘋芯科技在接受集微網(wǎng)采訪時表示,目前存算一體技術(shù)在國內(nèi)外企業(yè)的不懈努力下已經(jīng)實現(xiàn)商業(yè)化應(yīng)用,存算一體芯片也即將全面進入千行百業(yè),為人工智能的大規(guī)模應(yīng)用提供不竭的算力支撐。
架構(gòu)創(chuàng)新,存算技術(shù)釋放數(shù)十倍能效比提升
存算一體并非最新提出的概念,發(fā)展歷程可以追溯到上個世紀。1969年,斯坦福研究所的Kautz等人首次提出了存算一體計算機的概念,旨在將計算單元與存儲單元融合,實現(xiàn)數(shù)據(jù)存儲與計算的同步進行。此后,多倫多大學(1992年)和伯克利實驗室(1997年)都相繼嘗試以邏輯電路的形式拉近存儲與計算的距離。
2000年以后,隨著大數(shù)據(jù)以及人工智能技術(shù)的發(fā)展,人們對于并行計算的需求日益增長,存算一體技術(shù)受到更多關(guān)注。特別是Transformer架構(gòu)的流行,生成式模型已經(jīng)出現(xiàn)上千億,甚至更高參數(shù)量的需求,對存儲的要求也越來越高、帶寬越來越大。傳統(tǒng)馮·諾依曼架構(gòu)的數(shù)據(jù)搬運模式很難滿足AI芯片的計算效率,這就給存算技術(shù)帶來了新的商業(yè)化空間。
根據(jù)蘋芯介紹,傳統(tǒng)芯片是先把數(shù)據(jù)從存儲系統(tǒng)中讀取出來,放到計算單元當中進行運算,然后再把計算結(jié)果傳回到存儲系統(tǒng)當中。這種大規(guī)模的數(shù)據(jù)遷移導(dǎo)致了帶寬的瓶頸和功耗的浪費。存算一體的核心創(chuàng)新在于“計算發(fā)生在數(shù)據(jù)存儲的位置”。它從根本上避免了上述情況的發(fā)生,同時帶來一系列的性能優(yōu)勢。以蘋芯科技開發(fā)的SRAM存算單元為例,它直接在存儲器內(nèi)部完成乘累加運算,徹底消除了數(shù)據(jù)搬運需求。測試數(shù)據(jù)顯示,這一技術(shù)可將數(shù)據(jù)遷移能耗降低90%以上,同時將能效比提升至27.38 TOPS/W,較傳統(tǒng)架構(gòu)提升數(shù)十倍(該成果已入選ISSCC 2022)。
目前,存算一體技術(shù)的商業(yè)化進程已處于成熟落地應(yīng)用階段,大規(guī)模應(yīng)用即將全面鋪開。比如搭載了存算一體NPU的MCU芯片,已用于智能監(jiān)控攝像頭等設(shè)備中,實現(xiàn)人臉識別、行為分析、目標檢測等視頻圖像的實時分析和處理;在智能手表、智能手環(huán)等設(shè)備中,進行心率監(jiān)測、運動姿態(tài)識別等時實數(shù)據(jù)監(jiān)測和分析。
聚焦終端側(cè),規(guī)模商業(yè)化突破的現(xiàn)實選擇
通常,工業(yè)界在評價一個架構(gòu)的商業(yè)化前景時,除了關(guān)注技術(shù)層面的發(fā)展?jié)摿σ酝猓€要考慮通用性、快速迭代能力,以及成本等核心指標。此外,相比馮·諾依曼架構(gòu)來說,存算一體架構(gòu)的專用性更強。由于從設(shè)計上是將計算單元與存儲單元融合在一起,在進行技術(shù)迭代時也會面臨更多的挑戰(zhàn)。這些都是業(yè)界探索存算一體技術(shù)應(yīng)用落地時,需要考慮的要點。因此,蘋芯指出,相對于云端高度復(fù)雜的生態(tài)、技術(shù)挑戰(zhàn),率先從終端側(cè)尋求突破是更加現(xiàn)實的選擇。
首先,云端計算往往被定位成一個平臺,因而更加強調(diào)泛化能力,也就是計算的通用性。這對更傾向于專用計算的存算一體芯片來說,設(shè)計上更具挑戰(zhàn)性。但是在終端側(cè)和邊緣側(cè)的MCU芯片進行的更多是一項或者幾項指定功能,比如人臉檢測、語音識別等。這就意味著,終端側(cè)的芯片并不需要那么強的平臺化能力,它的應(yīng)用是相對固定的,因而算法也相對固定,與之相匹配的計算和存儲的能力也就相對固定。這就讓存算一體芯片有了更多用武之地。
其次,很多終端側(cè)的應(yīng)用場景對芯片的能效比有著極高的要求,一方面要求產(chǎn)品具有輕量化、便攜化的趨勢,需要考慮無法插電源工作的情況;另一方面又有著從非AI轉(zhuǎn)向AI類產(chǎn)品的升級需求。這就需要有高能效比的技術(shù)來支撐,在這方面存算一體芯片更具優(yōu)勢。
此外,終端側(cè)的市場空間同樣足夠廣闊。機構(gòu)預(yù)測,2025年可穿戴類產(chǎn)品的市場規(guī)模將超過1000億元。今年CES大展上,AI眼鏡和AI玩具成為最火爆的兩類新品。預(yù)計2025年全年AI眼鏡出貨量可達幾百萬臺,WellsennXR預(yù)測到2029年全球AI眼鏡銷量或?qū)⑼黄?500萬副,滲透率將提升至3.48%,市場規(guī)模更是有望突破825億元。人工智能向端側(cè)市場的大規(guī)模滲透已經(jīng)開始。
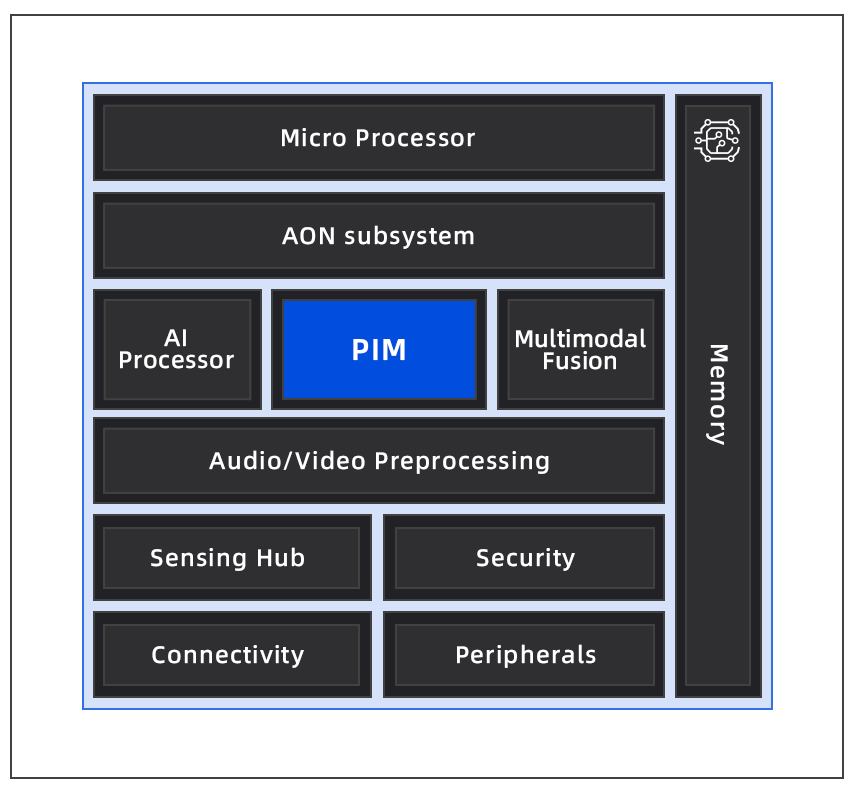
正是基于這樣的判斷,蘋芯科技面向終端側(cè)模型,推出了基于SRAM的存算一體NPU——N300。這是一款可集成于SoC芯片當中的IP核,可用于執(zhí)行神經(jīng)網(wǎng)絡(luò)的加速任務(wù)。NPU可以提升神經(jīng)網(wǎng)絡(luò)效率,涵蓋矩陣加速、非線性加速等功能。用戶基于NPU可以打造端側(cè)SoC、MCU等產(chǎn)品。蘋芯表示:“蘋芯科技的比較優(yōu)勢在于產(chǎn)品的快速迭代能力,強調(diào)以小成本的迭代方式,小步快跑、快速驗證,為實現(xiàn)存算一體技術(shù)的大規(guī)模商業(yè)化提供了必要條件。”
此外,N300 在架構(gòu)設(shè)計、性能指標(如算力、功耗、帶寬等)方面還有許多創(chuàng)新之處,比如存算融合陣列:256KB SRAM中嵌入計算單元,面積效率達0.26TOPS/mm2;動態(tài)精度引擎:支持4-16bit混合精度,語音模型量化后精度損失<3‰;多核彈性擴展:單核0.5TOPS,十六核集群可達8TOPS,工業(yè)質(zhì)檢場景吞吐量提升273%。
這些技術(shù)指標與性能集于一體,使N300具備了成為終端側(cè)優(yōu)秀AI解決方案的潛在實力。

生態(tài)與模式,N300在實際應(yīng)用中的優(yōu)勢所在目前,有越來越多MCU廠商開始將AI功能深度嵌入到芯片設(shè)計之中,包括ST、瑞薩、恩智浦以及眾多國內(nèi)企業(yè)。它們大多采用集成NPU的方案,讓芯片得以在端側(cè)直接執(zhí)行圖像識別、語音識別、預(yù)測分析等AI任務(wù),減少對數(shù)據(jù)回傳云端的依賴。為了滿足用戶的需求,蘋芯科技也在不斷調(diào)整自身的商業(yè)模式。首先,蘋芯科技不僅推出N300 存算一體IP核,還同時開發(fā)了一款SoC芯片——S300,在神經(jīng)網(wǎng)絡(luò)加速部分集成了基于28nm工藝的N300內(nèi)核,主打多模態(tài)和環(huán)境感知功能。這一方面使蘋芯科技具備了向系統(tǒng)廠商提供芯片級解決方案的能力,也意味著N300 作為一款I(lǐng)P核是已經(jīng)得到驗證的產(chǎn)品,芯片級用戶在采用它的時候,無需擔心產(chǎn)品的可靠性。
其次,在生態(tài)方面,N300 支持開源編譯器TFLM。AI加速芯片并不像存儲芯片那樣是一個標準化的產(chǎn)品,可能100家NPU公司,就有100種解決方案。不過目前很多MCU公司已經(jīng)支持開源框架。而N300支持TFLM,意味著與多數(shù)MCU公司采用了同一框架,這樣在軟件上就與MCU是統(tǒng)一的。芯片用戶可以直接使用N300方案進行訓(xùn)練,實現(xiàn)一鍵部署。
第三,N300是一款多模態(tài)融合感知NPU,對于語音、圖像,以及其他傳感數(shù)據(jù)都能給予支持。也就是說,在終端側(cè)的有限應(yīng)用中,它是可以做到相對通用,與其他面向終端側(cè)專用解決方案相比,具有更強的泛化優(yōu)勢,確保了客戶的易用性。
再加上存算一體芯片天然具有的能效比優(yōu)勢、帶寬優(yōu)勢,N300完全具備成為一款面向終端側(cè)AI市場優(yōu)秀解決方案的產(chǎn)品素質(zhì)。事實上,N300已經(jīng)在市場小范圍推廣,并取得不少成功的商業(yè)化案例。
以TWS耳機降噪案例為例,近年來TWS耳機市場火熱,很多廠商采用AI方案實現(xiàn)本地化語音增強與環(huán)境降噪。N300可被集成在22nm工藝的芯片當中,實現(xiàn)36 GOPS@64MHz的算力,支持DCCRN網(wǎng)絡(luò)(含LSTM)的實時推理。適配了微型化的終端設(shè)計;同時發(fā)揮極強的功耗控制效能,平均工作功耗<1mW,比傳統(tǒng)的DSP方案降低70%,延長耳機續(xù)航30%以上。
繼續(xù)深耕,蘋芯科技為邊緣未來布局展望終端與邊緣側(cè)AI市場發(fā)展趨勢,“存算一體”技術(shù)完全有能力成為該領(lǐng)域的主流芯片架構(gòu)之一。蘋芯表示,未來的計算架構(gòu)大致有三條發(fā)展路徑:一是存算一體。其將計算單元與存儲單元融合,在實現(xiàn)數(shù)據(jù)存儲的同時直接進行計算,以消除數(shù)據(jù)搬移帶來的開銷。二是3D堆疊。這種架構(gòu)出于對存儲帶寬的極致追求,因此是天然是反對存算一體的。第三條路徑則是在前兩種方案之間做平衡,也即近存計算。它希望在不改變計算單元,也不改變存儲單元的情況下,盡量縮短存儲與處理器中間的距離,以此改善芯片的性能。在這三條路徑中,如果計算和存儲功能相對明確,那么存算一體方案就更具優(yōu)勢,可以更加充分發(fā)揮架構(gòu)帶來的優(yōu)勢。當然,目前的存算一體要想實現(xiàn)大規(guī)模商用仍有很多技術(shù)瓶頸需要突破,包括工藝兼容性的改善,比如eNVM存儲器的穩(wěn)定量產(chǎn);提高設(shè)計工具鏈的成熟度,實現(xiàn)自動化EDA工具與跨平臺編譯器的支持,加強代工廠標準IP庫的建設(shè)與優(yōu)化多場景下的制造成本,以便提高產(chǎn)業(yè)鏈的整體協(xié)同能力。同時還需要構(gòu)建開源生態(tài),以解決開發(fā)門檻高、改善算法適配碎片化等問題。這樣才能將存算一體從技術(shù)優(yōu)勢轉(zhuǎn)化為規(guī)模化落地的能力。而蘋芯科技的優(yōu)勢在于能夠在較短時間內(nèi),只要客戶立項并確定其所采用的工藝,就可以進行快速定制并實現(xiàn)交付。這可以成為用戶大規(guī)模商用中的一大助力。
從市場角度來看,未來3~5年,存算一體芯片將在AIoT和邊緣計算領(lǐng)域迎來爆發(fā)式增長,市場潛力集中于實時健康監(jiān)測(如可穿戴ECG實時分析)、工業(yè)預(yù)測性維護(振動/溫度信號邊緣診斷)及智慧家居(能效優(yōu)化、數(shù)據(jù)安全與保護)等場景,這就需要高能效比與低成本的產(chǎn)品,精準匹配邊緣側(cè)對“高能效+低成本+實時處理”的核心需求。
蘋芯科技已經(jīng)推出支持圖像、語音等多模態(tài)融合處理的N300 ,未來將把這些核心能力,比如CNN/Transformer硬件加速、動態(tài)數(shù)據(jù)流調(diào)度引擎向更多模態(tài)擴展,推出新的解決方案。“存算一體仍然處于快速發(fā)展階段,這個技術(shù)是不斷被喚醒的,不斷有新的熱點出現(xiàn)。我們已經(jīng)推出一顆芯片和一個IP,實現(xiàn)了多模態(tài)融合感知。下一步我們將開發(fā)一款LPU(語言處理單元)方向的產(chǎn)品,針對CNN/Transformer硬件加速,把傳送這件事情做到邊緣側(cè)去。”蘋芯透露。
為此,蘋芯科技未來將聚焦22/14nm工藝升級與新型eNVM(如MRAM/RRAM)存算架構(gòu)集成,通過混合精度計算優(yōu)化和稀疏化加速引擎提升算法效率,同時完善開源編譯器工具鏈(支持多模態(tài)模型一鍵部署)并拓展異構(gòu)計算IP庫。
蘋芯科技還計劃在未來的研發(fā)工作中,進一步提高存算一體核心單元計算能效比,并聯(lián)合代工廠推進eNVM工藝量產(chǎn),構(gòu)建覆蓋智能穿戴、智慧家居等場景的“存算+”生態(tài),突破設(shè)計自動化工具與跨平臺適配瓶頸,加速技術(shù)規(guī)模化落地。
-
AI
+關(guān)注
關(guān)注
88文章
34592瀏覽量
276312 -
NPU
+關(guān)注
關(guān)注
2文章
325瀏覽量
19599 -
蘋芯科技
+關(guān)注
關(guān)注
1文章
24瀏覽量
346
發(fā)布評論請先 登錄
Pimchip-N300 | MCU廠商邁向AI時代的“一站式鑰匙”

PIMCHIP S300 全球首款28nm節(jié)點實現(xiàn)存算一體產(chǎn)品化AI芯片
【一文看懂】什么是端側(cè)算力?

蘋芯出席2024中國AI芯片開發(fā)者論壇
存算一體行業(yè)2024年回顧與2025年展望
蘋芯科技:邊緣和端側(cè)AI算力或成2025年重要增長點,存算一體架構(gòu)崛起是必然趨勢

存算于芯 · 智啟未來 — 2024蘋芯科技產(chǎn)品發(fā)布會盛大召開
廣和通開啟端側(cè)AI新時代
蘋芯科技亮相2024中國AI芯片開發(fā)者論壇
端側(cè)AI浪潮已來!炬芯科技發(fā)布新一代端側(cè)AI音頻芯片,能效比和AI算力大幅度提升

存算一體架構(gòu)創(chuàng)新助力國產(chǎn)大算力AI芯片騰飛
科技新突破:首款支持多模態(tài)存算一體AI芯片成功問世

蘋芯科技發(fā)布AI革命新品,引領(lǐng)高效能計算新紀元
蘋芯科技引領(lǐng)存算一體技術(shù)革新 PIMCHIP系列芯片重塑AI計算新格局






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論