 基于深度學習自動化的前端開發解析
基于深度學習自動化的前端開發解析

作者:Ashwin Kumar編譯:weakish
編者按:Ashwin Kumar之前是Sway Finance的聯合創始人,Sway Finance是Y Combinator孵化的一家初創企業,使用機器學習技術自動化會計。后來去了Insight,在Insight開發了一個模型,允許用戶從手繪的示意圖創建可以工作的HTML網站。現任Mythic深度學習科學家。
對所有規模的公司而言,創建直觀、沉浸式的用戶體驗都是一個關鍵的目標。創建用戶體驗是一個以原型、設計、測試為周期的快速過程。Facebook這樣的巨頭有充足的資源,可以在設計過程中投入整個團隊,設計過程可能長達數周,涉及多個相關者;小企業沒有這樣的資源,因此它們的用戶界面做出來可能會不太好。
我在Insight的目標是使用現代深度學習算法顯著地流水線化設計工作流程,賦能任何企業快速創建和測試網頁。
今天的設計工作流程
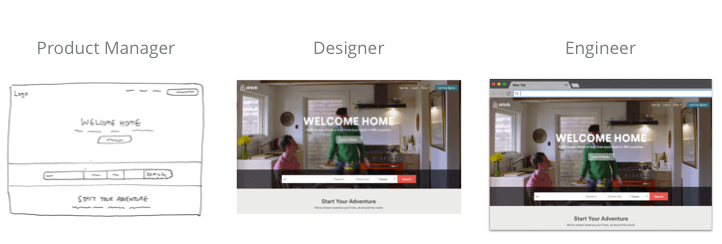
經過多個相關者的設計工作流程
一個典型的設計工作流程可能是這樣的:
產業經理進行用戶研究,得出一些規格要求
設計師接收需求,探索低保真原型,并逐漸創建高保真模型
工程師將設計實現為代碼并最終交付產品至用戶
研發周期的長度可能很快成為瓶頸,Airbnb這樣的公司開始使用機器學習使這一過程更高效。
盡管看起來這是一個很有前途的機器輔助設計的樣例,我們并不清楚這一模型多大程度上是完全基于端到端訓練的,多大程度上依賴手工提取的特征。我們無法知道確切的答案,因為這是一個閉源的專有實現。我希望開發一個繪圖到代碼技術的開源版本,面向更廣泛的開發者和設計師。
理想情況下,我的模型將可以接受一個簡單的手繪網站設計原型,并立刻基于圖像生成可以工作的HTML網站:
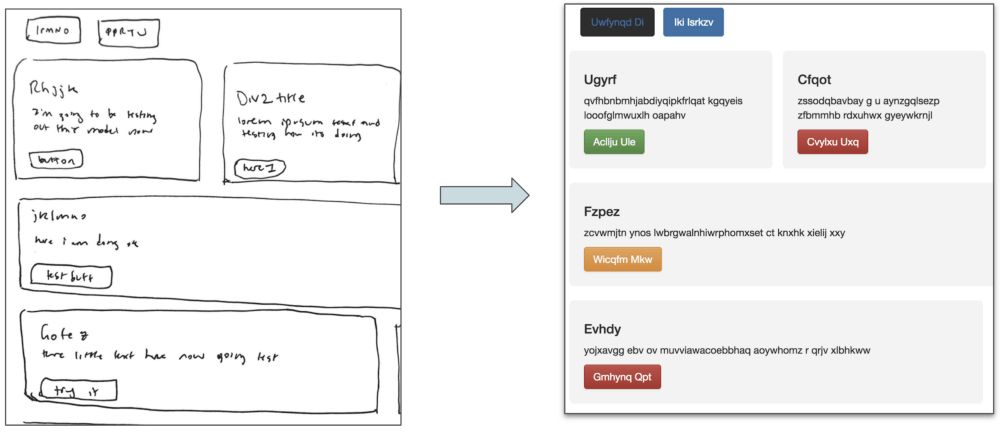
SketchCode模型接受手繪示意圖,生成HTML代碼
事實上,上圖是我的模型在測試圖像集上生成的真實網站!相關代碼發布在我的GitHub上:ashnkumar/sketch-code
從圖像標注汲取靈感
我打算解決的問題屬于程序生成任務,自動生成可以工作的源代碼。不過,程序生成大多涉及從自然語言規格聲明或執行追蹤(execution trace)生成代碼,而我的案例將基于圖像(手繪示意圖)生成代碼。
在機器學習中,圖像標注是一個研究很充分的領域,圖像標注尋找能夠將圖像和文本相聯系的學習模型,特別是基于源圖像內容生成描述。
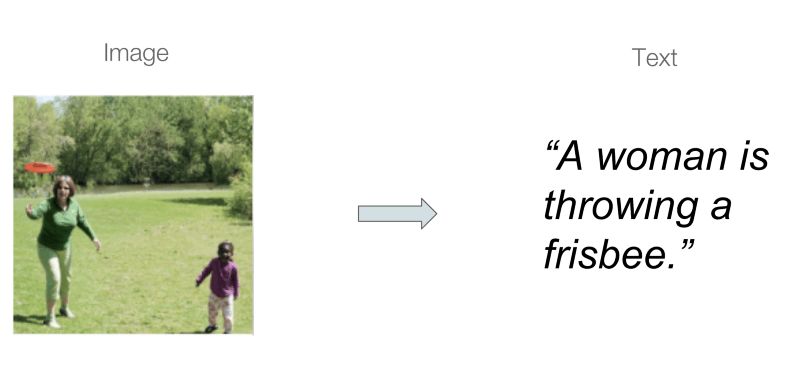
文本:一個扔飛盤的婦女
受最近的pix2code論文和Emil Wallner的相關項目的啟發,我決定重塑我的任務為圖像標注任務,以手繪網站示意圖為輸入圖像,相應的HTML代碼為輸出文本。
獲取合適的數據集
從圖像標注的角度來說,理想的數據集將是數以千計的成對的手繪草圖和相應的HTML代碼。毫不意外,我沒法找到這樣的數據集,我需要為這一任務創建自己的數據集。
我從pix2code論文的開源數據庫開始,其中包含1750張合成的網站截屏以及相關的源代碼。
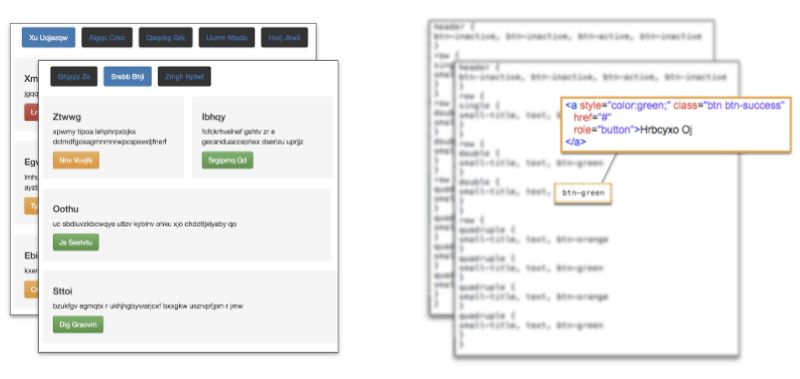
pix2code數據集
這是一個很好的數據庫,可以作為我自己的數據集的基礎:
數據集中生成的網站包含一些簡單的Bootstrap元素的組合,例如按鈕、文本框和div。盡管這意味著我的模型的“詞匯表”將限于少數元素——可供選擇的生成網站的元素——這一方法可以簡單地推廣至更大的元素詞匯表。
每個樣本的源代碼包含一個領域特定語言(DSL)的token,該DSL是論文作者專門創建的。每個token對應一段HTML和CSS,有一個編譯器將DSL編譯成可以工作的HTML代碼。
讓圖像看起來像是手繪的
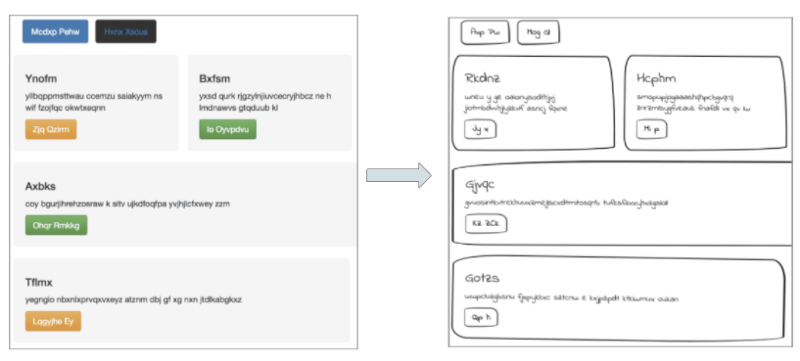
轉換彩色網站圖像至手繪版本
為了修改數據集以適應我自己的任務,我需要讓這些網站圖像看起來像是手繪的。我嘗試使用python中的OpenCV和PIL庫修改每張圖像,例如轉換為灰度圖像,等高線檢測。
最終,我決定直接修改原網站的CSS樣式表,進行以下操作:
修改網頁元素的圓角邊框以曲線化按鈕和div的邊角。
調整邊框的厚度,以模擬手繪草圖,并添加下降陰影。
修改字體為手繪風格字體。
最后,我通過添加傾斜、移動、旋轉以增強這些圖像,以模擬實際手繪草圖的變化性。
使用圖像標注模型架構
現在我已經有數據了,終于可以把數據傳給模型了!
我使用了一個圖像標注的模型架構,主要包含三部分:
使用卷積神經網絡(CNN)從源圖像提取圖像特征的計算機視覺模型
基于門控循環單元(GRU)的編碼源代碼token序列的語言模型
接受前兩步的輸出作為輸入,預測序列中的下一個token的解碼器模型(也是GRU)
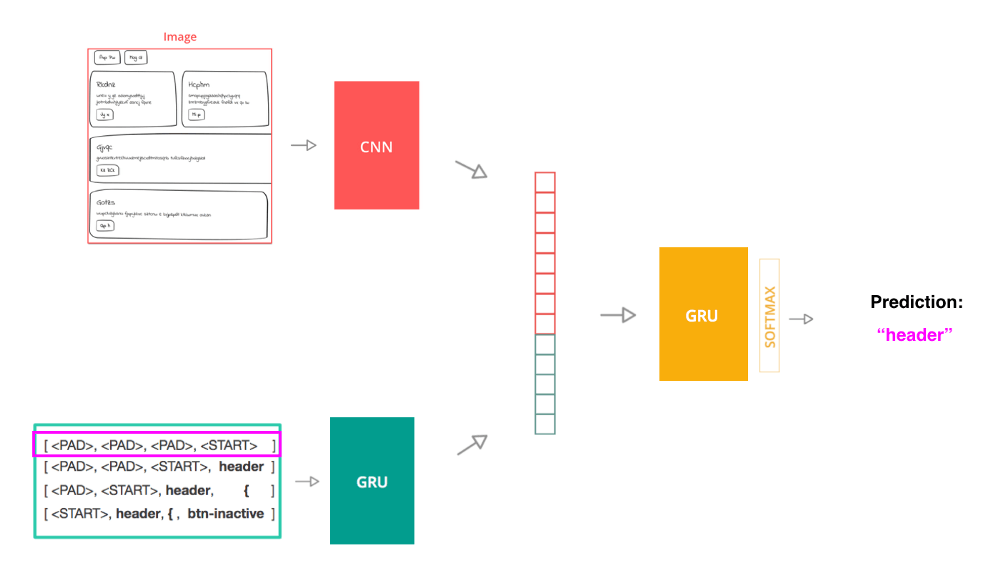
訓練使用token序列作為輸入的模型
為了訓練這一模型,我將源代碼拆分成token序列。模型的單個輸入是一個序列和源代碼圖像,標簽為文檔中的下一個token。模型使用交叉熵作為損失函數,比較模型的下一個token預測和實際的下一個token。
在推理階段,當模型用來從頭生成代碼的時候,過程略有不同。圖像仍然由CNN處理,但文本過程僅僅使用一個開始序列作為種子。在每一步中,模型將預測的下一token序列附加到當前輸入序列,并傳給模型作為新輸入序列。不斷重復這一過程,直至模型預測一個
一旦模型生成了預測token的集合,編譯器轉換DSL token至可由任何瀏覽器渲染的HTML。
使用BLEU分數評估模型
我決定使用BLEU分數評估模型。BLEU分數是機器翻譯任務中一個常用的指標,這一指標衡量機器生成文本在多大程度上接近由人類基于相同輸入生成的文本。
基本上,BLEU比較生成文本和參考文本的n元序列,以創建準確率變體。用BLEU評估這一項目很合適,因為它基于實際生成的HTML元素,以及元素之間的關系。
最棒的是,我可以通過查看生成網站實際看到BLEU分數!
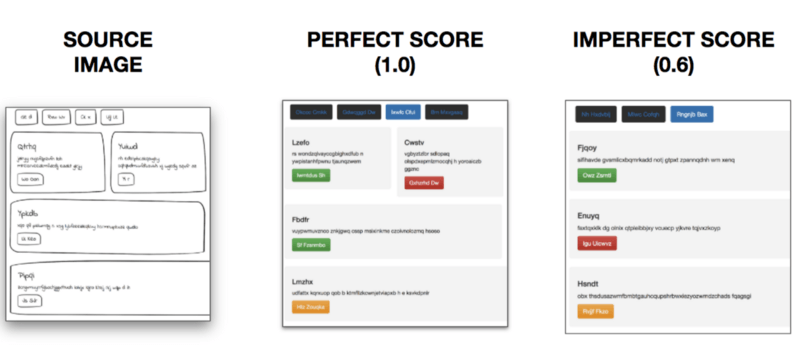
可視化BLEU分數
給定源圖像,完美的BLEU分數(1.0)意味著正確的元素位于正確的位置,而較低的分數預測錯誤的元素,或者元素位于錯誤的位置。最終模型能夠在評估數據集上取得0.76的BLEU分數。
額外獎勵——定制風格
我意識到模型提供了一個額外獎勵,由于模型僅僅生成網頁的骨架,我可以在編譯過程中加入定制的CSS層,然后立刻獲得所得網站的不同風格。
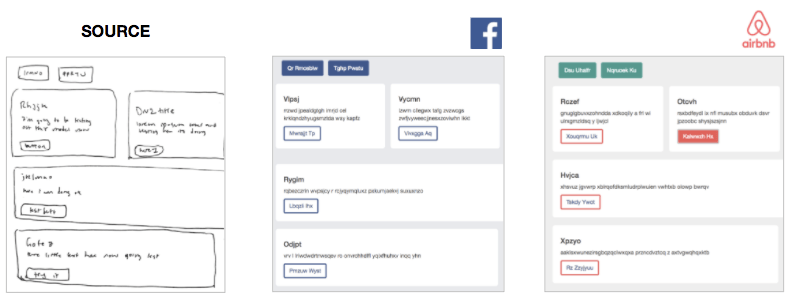
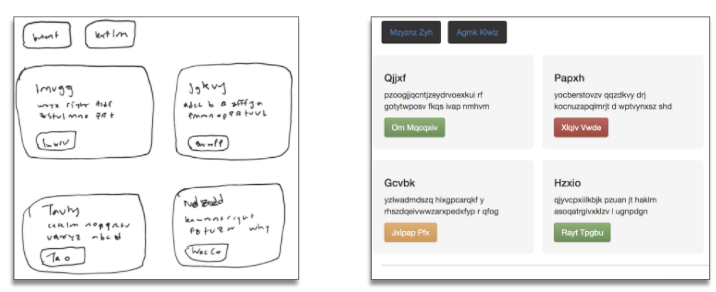
同一草圖對應不同風格
樣式解耦模型生成過程帶來了很大的優勢:
想要在自家公司使用SketchCode模型的前端工程師可以如原樣使用模型,僅僅修改一個CSS文件,使網站適配公司的風格指南
內置可伸縮性——基于單一源圖像,模型的輸出可以立刻編譯至5、10、50種不同的預定義分割,因此用戶可以可視化多個版本的網站,并在瀏覽器中瀏覽查看。
總結和未來方向
利用圖像標注方面的研究,SketchCode能夠接受手繪網站示意圖,并在數秒之內將它們轉換為可以工作的HTML網站。
這一模型具有一些限制,這也意味著未來可以做的改進:
由于訓練模型的詞匯表僅包括16個元素,它無法預測在數據中未見的token。下一步可能使用更多元素生成額外的網站樣本,例如圖像、下拉菜單、表單——Bootstrap組件是一個很好的開始。
生產環境中的實際網站有很多變化。創建更能反映這些變化的訓練數據集的一個很好的方法是抓取實際網站的HTML/CSS代碼和網站內容截屏。
手繪同樣有很多通過修改CSS無法完全捕捉的變化。在手繪草圖數據中生成更多變化的一個很好的方法是使用對抗生成網絡創建逼真的手繪網站圖像。
如前所述,你可以在GitHub上找到此項目的代碼:ashnkumar/sketch-code
原文地址:https://blog.insightdatascience.com/automated-front-end-development-using-deep-learning-3169dd086e82
-
深度學習
+關注
關注
73文章
5561瀏覽量
122812 -
前端開發
+關注
關注
0文章
27瀏覽量
4657
原文標題:從草圖到網站:基于深度學習自動化前端開發
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
自動化計算機的功能與用途

行業首創:基于深度學習視覺平臺的AI驅動輪胎檢測自動化

智能讀碼器:工業自動化的眼睛與大腦
AI自動化生產:深度學習在質量控制中的應用

基于 Docker 與 Jenkins 實現自動化部署
M12連接器技術規格解析:工業自動化的優選方案

串口屏自動化測試
自動化創建UI并解析數據
自動化創建UI并解析數據
自動化AI開發平臺功能介紹
Appium +iOS自動化測試教程(實踐、總結 、踩坑)
探索Playwright:前端自動化測試的新紀元
搭載瑞芯微RK3588J芯片——HZHY-MT100G:深度解析工業通信與電力自動化協議的集成與應用






 工商網監
工商網監
評論