 京微齊力HME-P2系列FPGA的pSRAM讀寫例程分析
京微齊力HME-P2系列FPGA的pSRAM讀寫例程分析

來源:老劉記事兒
最近有客戶反映國產FPGA京微齊力P2器件內部合封的pSRAM控制器讀寫效率很高,能達80%以上,而且合封了4片8bit位寬pSRAM芯片,按250MHz主頻DDR雙沿讀寫算下來80%效率能跑出12.8Gbps的極限帶寬,即使考慮工程布局布線的限制影響因素,按210MHz主頻也應能跑出10.5Gbps讀寫帶寬。
如果真是這樣,這意味著FPGA + SDRAM架構方案的市場應用生態位面臨著挑戰,因為即使采用200MHz主頻的單顆DDR SDRAM也需要32bit位寬才能在理論上達到100%效率時(不可能實現)的12.8Gbps極限帶寬,而SDRAM控制器設計復雜度導致的邏輯資源消耗、SDRAM芯片較高的功耗特性、外掛SDRAM芯片的成本考量等因素會使FPGA + SDRAM架構方案劣于京微齊力的FPGA內部合封4片pSRAM方案。
那么真實情況如何呢?客戶的傳言是確切的么?
帶著疑問,我要來了京微齊力P2器件的pSRAM讀寫例程,進行核實分析。
根據說明,該例程系統框圖如下:
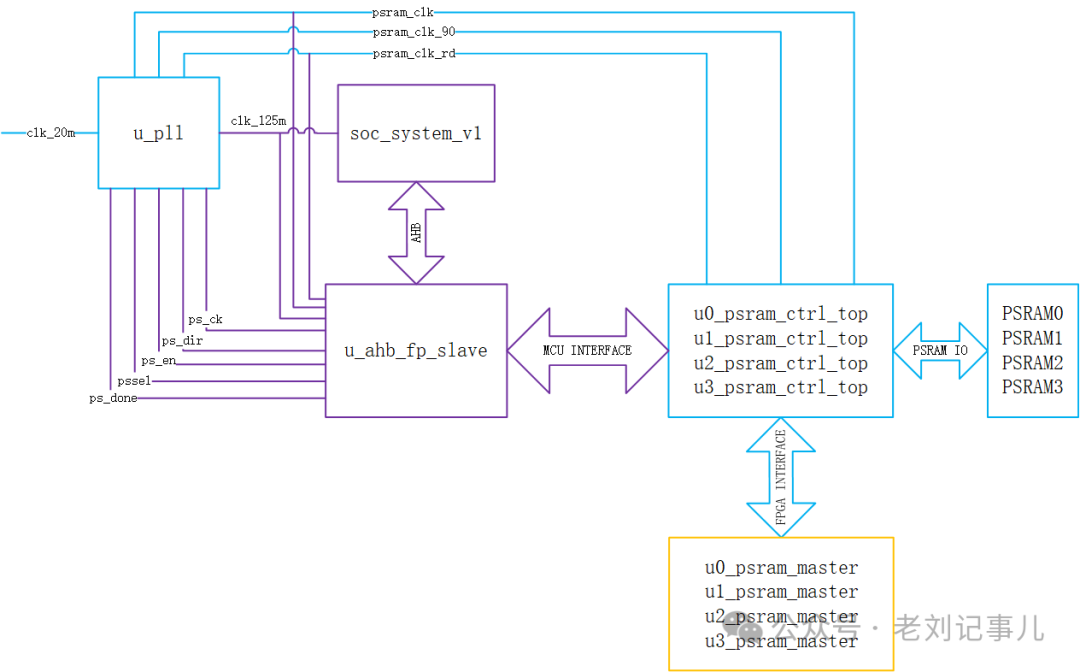
其中,soc_system_v1模塊是指P2器件中自帶的ARM Cortex-M3硬核,在例程中起到對pSRAM的寄存器初始化和Clock Training作用。Clock Training是上電啟動階段指對psram_clk、psram_clk_90和psram_clk_rd這三個時鐘的相位關系進行初始化校準。這三個時鐘的功能可參閱原廠手冊說明(見下圖),在此我們不作更多推敲討論。

不過顯然可以看出,將pSRAM初始化和Clock Training機制放進FPGA自帶的ARM硬核中,對于節省FPGA邏輯資源占用肯定是很有好處的,而且在ARM硬核中實現對pSRAM寄存器狀態和Training結果的打印監測也是十分方便的。原廠例程中就利用了這一點,下圖為例程中ARM硬核控制pSRAM執行初始化和Clock Training階段串口打印的部分信息,顯示了Clock Training的時鐘窗口掃描結果。
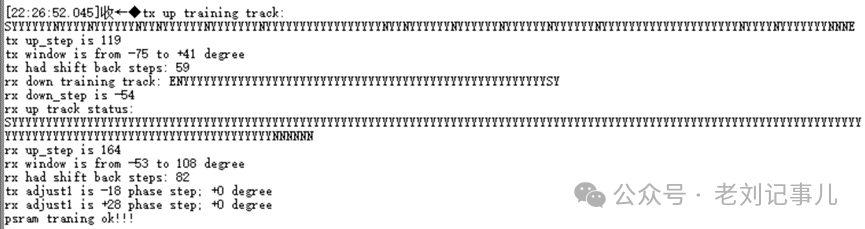
例程提供的pSRAM控制器可允許對4片pSRAM予以分別不同的寄存器初始化配置,使其分別獨立工作在不同的工作狀態下。這為客戶提供了靈活操控的可能性,在必要的應用場合可以靈活搭配形成乒乓操作,譬如4片pSRAM可以配置成同時1寫3讀或3寫1讀,也可以4片統一同步操作讀寫。
例程配套有仿真工程,可以直接從仿真波形中得到pSRAM讀寫效率信息。
仿真例程先是對4片pSRAM分別作了初始化配置動作,而后循環進行Burst 1~128次*2Byte的交替讀寫循環測試。

每次Burst寫入pSRAM的數據會同步存入雙端口RAM中,再將RAM中的數據取出與從pSRAM中相應地址讀出的數據作一致性比對,如果讀寫比對無誤則psram_cmp_flag信號保持為0,否則一旦發生錯誤就會拉高相應pSRAM的psram_cmp_flag信號。

對交替讀寫循環測試的波形放大可以看到,pSRAM的讀寫過程各有快慢兩種響應速度,姑且稱之為 “快寫”、“慢寫”、“快讀”、“慢讀”。
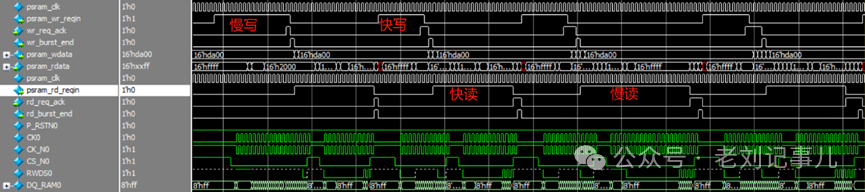
pSRAM寫操作相關的FPGA端用戶接口信號時序抓取波形示例如下:

pSRAM讀操作相關的FPGA端用戶接口信號時序抓取波形示例如下:

各路信號的含義和時序關系說明詳情可參見官方應用手冊,此處不作贅述。
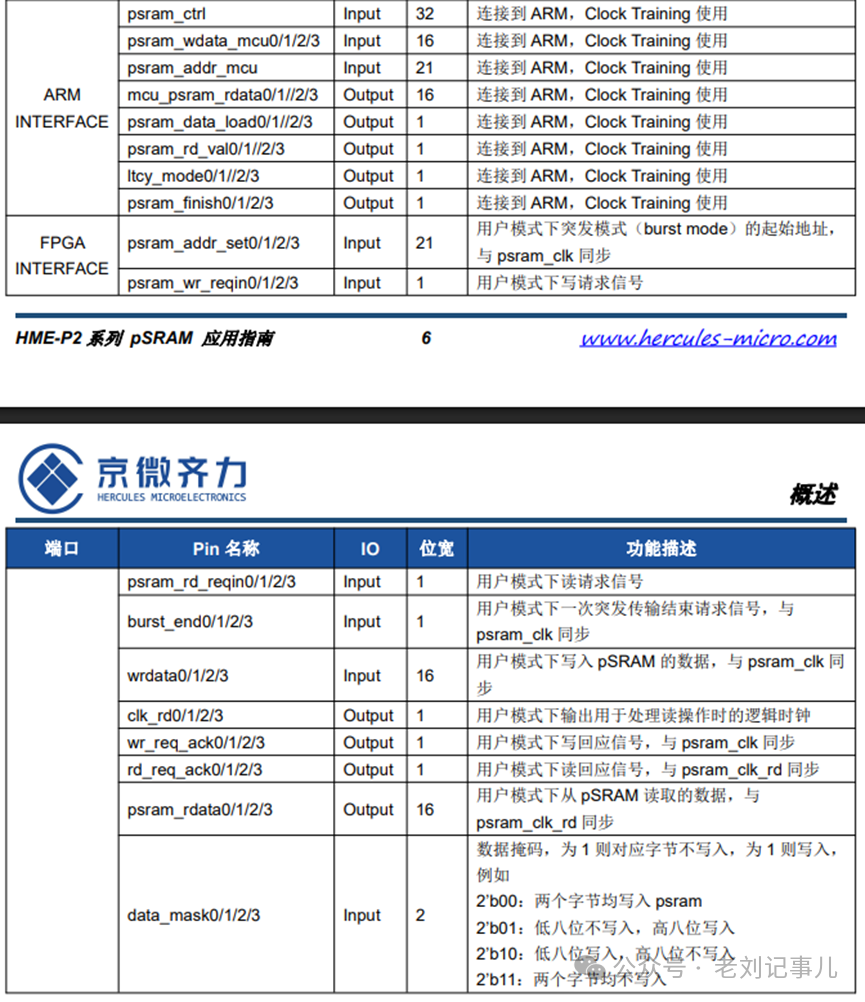
我們只關心讀寫效率的評估,那么把握重點:
psram_wr_reqin和psram_rd_reqin分別是寫請求和讀請求信號;
wr_req_ack和rd_req_ack分別是寫響應和讀響應信號,其中wr_req_ack的高電平比psram_wdata寫有效數據前移了一拍,而rd_req_ack的高電平與psram_rdata讀有效數據是時序對齊的;
讀寫Burst長度分別由rd_burst_len和wr_burst_len決定,實際Burst拍數分別為rd_burst_len+1 和wr_burst_len+1。

對照仿真波形可以確認,例程中的pSRAM讀寫循環是無縫切換的,沒有冗余間隔,因此psram_wr_reqin和psram_rd_reqin的高電平寬度分別就是寫等待和讀等待時長,即除有效讀/寫操作之外被“浪費”的時間。寫等待和讀等待時長所占用的時鐘周期數分別稱為寫等待拍數和讀等待拍數。
“快寫”、“慢寫”、“快讀”、“慢讀”分別的等待拍數見下表:
| 讀寫狀態 | 快寫 | 慢寫 | 快讀 | 慢讀 |
| 等待拍數 | 11 | 18 | 19 | 26 |

“快寫”狀態下,從發起寫請求到第一個有效數據開始寫入,寫等待占用了11個時鐘周期。因此,當Burst為256字節(128拍)時寫效率最高,為:
128/(11+128) =92%
對應P2器件工作在210MHz主頻下的“快寫”帶寬為:
92%×210MHz×2×4片 ×8 bits =12.08 Gbps

“慢寫”狀態下,從發起寫請求到第一個有效數據開始寫入,寫等待占用了18個時鐘周期。因此,當Burst為2字節(1拍)時寫效率最低,為:
1/(18+1) = 5.26%
當Burst為256字節(128拍)時,“慢寫”效率為:
128/(18+128) = 87.6%
對應P2器件工作在210MHz主頻下的“慢寫”帶寬為:
87.6%×210MHz×2×4片 ×8 bits
=11.5 Gbps

“快讀”狀態下,從發起讀請求到第一個有效數據開始讀入,讀等待占用了19個時鐘周期。因此,當Burst為256字節(128拍)時讀效率最高,為:
128/(19+128) =87%
對應P2器件工作在210MHz主頻下的“快讀”帶寬為:
87%×210MHz×2×4片 ×8 bits
=11.42 Gbps

“慢讀”狀態下,從發起讀請求到第一個有效數據開始讀入,讀等待占用了26個時鐘周期。因此,當Burst為2字節(1拍)時讀效率最低,為:
1/(26+1) = 3.7%
當Burst為256字節(128拍)時,“慢讀”效率為:
128/(26+128) = 83.1%
對應P2器件工作在210MHz主頻下的“慢讀”帶寬為:
83.1%×210MHz×2×4片 ×8 bits
=10.9 Gbps
這樣情況就明了了。也就是說:
京微齊力P2器件的pSRAM寫操作在Burst長度為256字節(128拍)的條件下效率最高,為87.6%至92%之間。
保守估計,按210MHz的大型項目(邏輯資源占用80%以上)真實可用主頻估算,在Burst長度為256字節(128拍)的條件下,其寫帶寬可達11.5 Gbps至12.08 Gbps之間。
京微齊力P2器件的pSRAM讀操作在Burst長度為256字節(128拍)的條件下效率最高,為83.1%至87%之間。
保守估計,按210MHz的大型項目(邏輯資源占用80%以上)真實可用主頻估算,在Burst長度為256字節(128拍)的條件下,其讀帶寬可達10.9 Gbps至11.42 Gbps之間。
當然,需要特別注意的是,由于存在內部自刷新過程,和SDRAM一樣,pSRAM在Burst長度較低時,讀寫效率不高。但Burst突發讀寫長度越長,其讀寫效率越高,速度優勢越明顯。
總體而言,京微齊力FPGA的pSRAM讀寫效率,超出預期!
附P2器件(合封4片pSRAM)在不同Burst長度下的讀寫效率列表以供查閱(注意1拍對應2字節):




附在P2器件(合封4片pSRAM)在pSRAM主頻210MHz條件下核算的不同Burst長度下的讀寫速率列表以供查閱(注意1拍對應2字節):




不過這里可以再引出一個問題:
快寫/慢寫(快讀/慢讀)的比例是多少,有何規律?
此處暫且不表,筆者搬磚之余時間有限,且聽下回分解。
-
FPGA
+關注
關注
1645文章
22015瀏覽量
616843 -
SDRAM
+關注
關注
7文章
442瀏覽量
56197 -
京微齊力
+關注
關注
0文章
30瀏覽量
5907
原文標題:老劉記事兒京微齊力FPGA系列之P2器件內部合封pSRAM性能探究(一)
文章出處:【微信號:HME-FPGA,微信公眾號:HME京微齊力】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
京微齊力:國產FPGA老樹開新花,務實做好消費市場再沖高端
國產FPGA簡介
京微齊力HME-P1P60 FPGA榮獲年度最佳處理器/FPGA獎項
京微齊力再次榮獲“IC獨角獸”稱號
京微齊力推出大力神H系列新一代產品H3C08芯片
基于京微齊力HME-M7和國產舜銘存儲鐵電存儲器PB85RS2MC的PLC解決方案

基于FPGA的PLC解決方案

HME FPGA入門指導:HME-P(飛馬)系列開發板實驗教程——LED流水燈

京微齊力采用Imagination AI加速器打造新型智能芯片
國芯思辰|京微齊力FPGA HME-HR02PN3Q32在會議音箱系統中的應用

京微齊力助力國內半導體產業高質量發展貢獻核心力量
京微齊力亮相2024慕尼黑上海電子展






 工商網監
工商網監
評論