 強化學習究竟是什么?它與機器學習技術有什么聯系?
強化學習究竟是什么?它與機器學習技術有什么聯系?
強化學習在當今世界可謂是日漸流行,讓我們來看一看關于強化學習你不得不知道的5件事。
強化學習是當今社會最熱門的研究課題之一,而且其熱度正與日俱增。讓我們一起來學習下關于強化學習的5個有用知識點。
▌1.強化學習究竟是什么?它與機器學習技術有什么聯系?
強化學習(Reinforcement Learning)是機器學習的一個分支,它的原理是:在交互環境中,智能體利用自身的經驗和反饋,通過試驗和錯誤經驗來進行學習。
有監督學習和強化學習都會明確指出輸入和輸出之間的映射關系,但不同點在于,有監督學習給智能體的反饋是執行正確任務的行為集合,而強化學習反饋的則將獎勵和懲罰轉為積極和消極行為的信號進行反饋。
對于無監督學習,強化學習的目標顯得更加難以實現。無監督學習的目標僅僅是找到數據之間的相似和不同,而強化學習的目標卻是找到一個能最大化智能體總累計獎勵的模型。
強化學習模型中涉及的基本思想和元素見下圖:
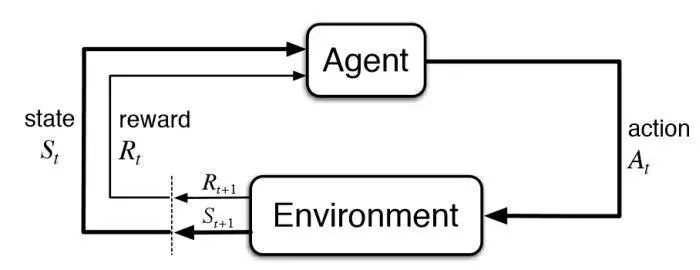
▌2.如何確定一個基本的強化學習問題?
描述強化學習問題的幾個關鍵元素是:
環境:智能體所處的物理世界;
狀態:智能體目前的狀態;
獎勵:從環境中得到的反饋;
方案:將智能體狀態映射到行動的方法;
價值:智能體在特定狀態下執行某項行動獲取未來的獎勵。
一些游戲可以幫助我們很好的理解強化學習問題。以PacMan游戲為例:在這個游戲中,智能體(PacMan)的目標就是在避免與鬼相遇的情況下,盡量在網格中吃到更多的豆子。網格世界就是智能體的交互環境,如果PacMan吃到了豆子就接受獎勵,如果被鬼殺死了(游戲結束)就接受懲罰。在該游戲中,“狀態”就是PacMan在網格中的各個位置,而總累計獎勵就是贏得比賽的勝利。
為了得到最優的方案,智能體既需要探索新的狀態,又要同時盡量取得最多的獎勵。這就是所謂的“探測與開采的權衡”問題。
馬爾可夫決策過程(MDP)是所有強化學習環境的數學框架,幾乎所有強化學習問題都可以使用MDP來搭建模型。一個MDP過程包含一個環境集合(S),每個狀態中包含一個可能的行動集合(A),還包含一個實值獎勵函數R(s)和一個轉移矩陣P(s',s | a)。不過,現實世界的環境中,環境動態的先驗信息可能是未知的,在這種情況下,運用“不理解環境強化學習”算法(model-free RL)去進行預測會更加方便、好用。
Q-learning模型就是一種應用廣泛的不理解環境強化學習模型,因此可以用它來模擬PacMan智能體。Q-learning模型的規則是,在狀態S下執行行動a,不停更新Q值,而迭代更新變量值算法就是該算法的核心。

Figure 2: Reinforcement Learning Update Rule
這是利用一個深度強化學習實現PacMan游戲的視頻:
https://www.youtube.com/watch?v=QilHGSYbjDQ
▌3.最常用的深度學習算法原理是什么?
Q-learning和SARSA是兩種最常見的不理解環境強化學習算法,這兩者的探索原理不同,但是開發原理是相似的。Q-learning是一種離線學習算法,智能體需要從另一項方案中學習到行為a*的價值;SARSA則是一種在線學習算法,智能體可從現有方案指定的當前行為來學習價值。這兩種方法都很容易實現,但缺乏一般性,因為它們無法預估未知狀態的值。
一些更加高級的算法可以克服這個問題,如:Deep Q-Networks(其原理為利用神經網絡來估計Q值)算法,但DQN算法只能應用在離散的低維動作空間中;DDPG(深度確定性策略梯度算法)則是一個理解環境的、在線的算法,它基于行動者-評論家(Actor-Critic,AC)框架,可用于解決連續動作空間上的深度強化學習問題。
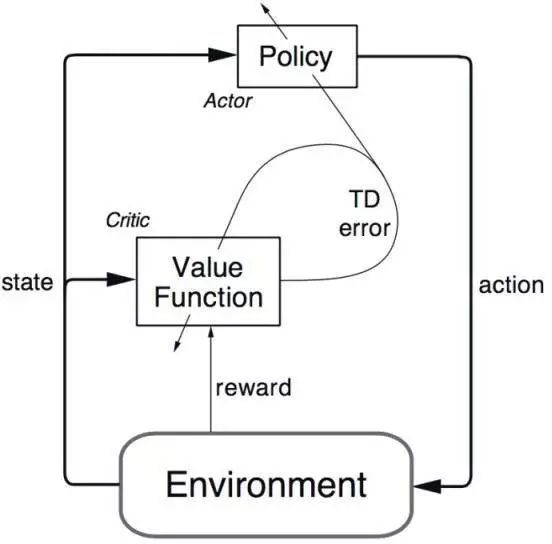
▌4.強化學習有哪些實際應用?
由于強化學習需要大量的數據,因此它最適用于模擬數據領域,如游戲、機器人等。
強化學習廣泛應用于設計游戲中的AI玩家。AlphaGo Zero在傳統中國游戲圍棋中打敗了世界冠軍,這是AI第一次擊敗現實中的世界冠軍。AI還在ATARI游戲、西洋雙陸棋等游戲中有出色的表現。
機器人和工業自動化領域中,深度學習也被廣泛應用,機器人能夠為自己搭建一個高效的自適應控制系統,從而學習自己的經驗和行為。DeepMind關于“帶有異步策略更新的機器人操縱的深度強化學習”就是一個很好的例子。
觀看這個有趣的演示視頻video(https://www.youtube.com/watch?v=ZhsEKTo7V04&t=48s)
強化學習的其他應用包括:文本摘要引擎、從用戶交互中學習并隨時間改進的(文本、語音)對話代理、醫療保健領域的最優治療政策、基于強化學習的在線股票交易代理。
▌5.我該如何開始強化學習?
讀者可以從以下鏈接中了解更多關于強化學習的基本概念:
《Reinforcement Learning-An Introduction》——本書由強化學習之父Richard Sutton和他的博士生導師Andrew Barto共同撰寫。該書的電子版以在http://incompleteideas.net/book/the-book-2nd.html找到。
由David Silver提供的Teaching material視頻課程可供讀者很好的了解強化學習的基礎課程:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
Pieter Abbeel和John Schulman的視頻technical tutoria也是不錯的學習資料:http://people.eecs.berkeley.edu/~pabbeel/nips-tutorial-policy-optimization-Schulman-Abbeel.pdf
開始構建和測試RL代理
若想要開始學習搭建和測試強化學習的智能體,Andrej Karpathy的博客This blog中詳細講述了如何用原始像素的策略梯度來訓練神經網絡ATARI Pong智能體,并提供了130行Python代碼來幫助你建立你的第一個強化學習智能體:http://karpathy.github.io/2016/05/31/rl/
DeepMind Lab是一個開源的3D游戲式平臺,它為機遇智能體可以的人工智能研究提供豐富的模擬環境。
Project Malmo是另一個提供基礎AI研究的在線平臺:https://www.microsoft.com/en-us/research/project/project-malmo/
OpenAI gym則是一個用于構建和比較強化學習算法的工具包:https://gym.openai.com/
-
機器學習
+關注
關注
66文章
8493瀏覽量
134161 -
強化學習
+關注
關注
4文章
269瀏覽量
11525
原文標題:關于強化學習你不得不知道的5件事
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
強化學習新方法,機器人究竟是怎么學習新動作的呢?
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?

一文詳談機器學習的強化學習
機器學習中的無模型強化學習算法及研究綜述







 工商網監
工商網監
評論