 NVMe高速傳輸卻不用XDMA設計之1
NVMe高速傳輸卻不用XDMA設計之1
NVMe IP放棄XDMA原因
選用XDMA做NVMe IP的關鍵傳輸模塊,可以加速IP的設計,但是XDMA對于開發者來說,還是不方便,原因是它就象一個黑匣子,調試也非一番周折,尤其是后面PCIe4.0升級。因此決定直接采用PCIe設計,雖然要費一番周折,但是目前看,還是值得的,uvm驗證也更清晰。
PCIe 加速模塊設計
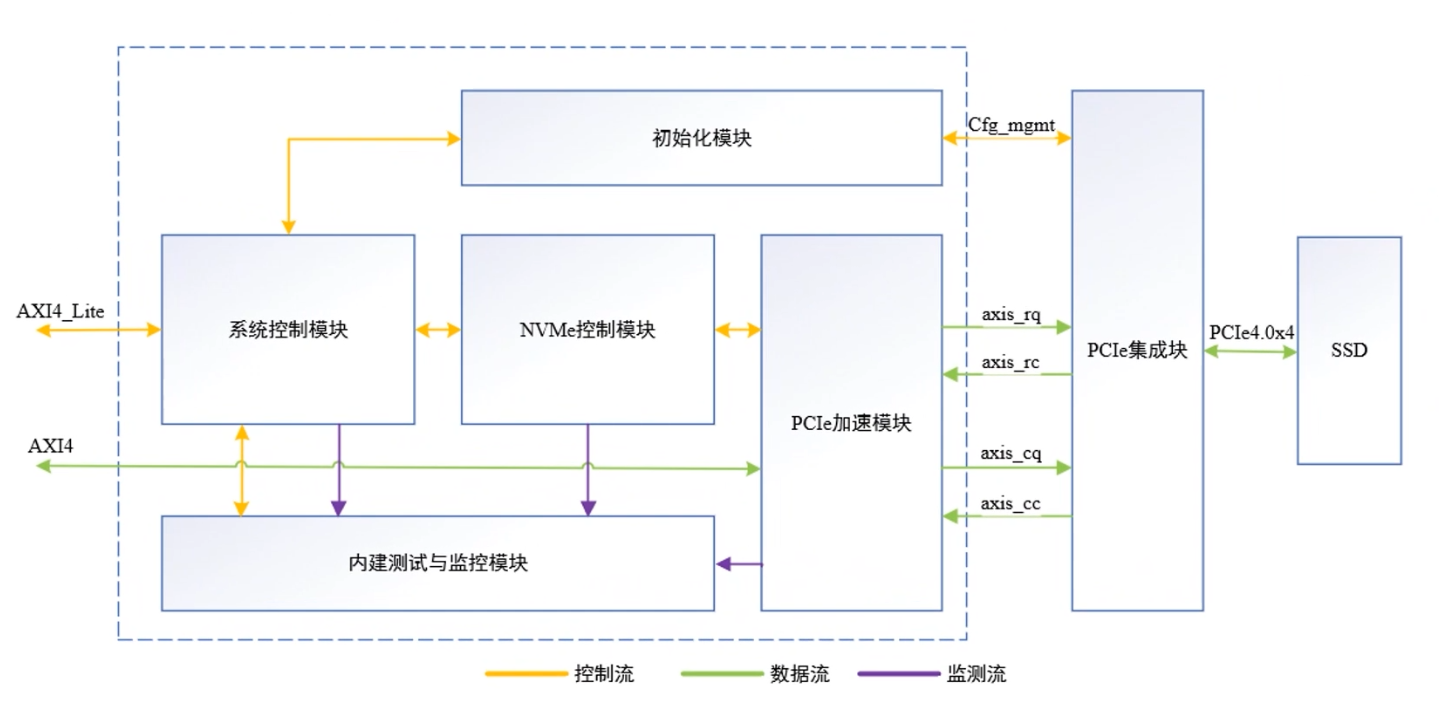
PCIe 加速模塊負責處理PCIe事務層,并將其與NVMe功能和AXI接口直接綁定。如圖1所示,PCIe加速模塊按照請求發起方分為請求模塊和應答模塊。請求模塊負責將內部請求事務轉換為配置管理接口信號或axis請求方請求接口信號(axis_rq),以及解析 axis 請求方完成接口信號(axis_rc);應答模塊負責接收axis完成方請求接口信號(axis_cq),將請求內容轉換為AXI4接口信號或其它內部信號做進一步處理,同時將應答事務通過axis完成方完成接口axis_cc)發送給PCIE集成塊.
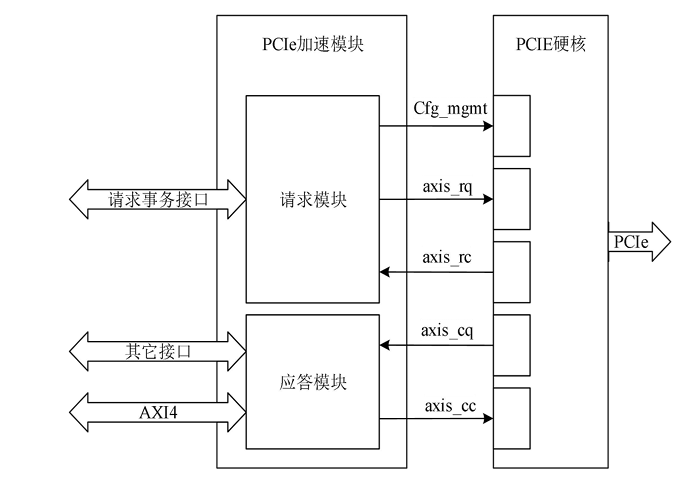
圖1 PCIe加速模塊結構和連接關系圖
PCIe 加速模塊不僅承擔了TLP與其它接口信號的轉換功能,也是降低傳輸延遲增加吞吐量的核心部件。接下來分別對請求模塊和應答模塊的結構設計進行具體分析。
PCIe 請求模塊設計
請求模塊的具體任務是將系統的請求轉換成為axis接口形式的TLP或配置管理接口信號。這些請求主要包含初始化配置請求和門鈴寫請求。初始化配置請求由初始化模塊發起,當配置請求的總線號為0時,請求通過Cfg_mgmt接口發送給PCIE集成塊;當配置請求的總線號不為0時,請求以PCIe配置請求TLP的格式從axis_rq接口發送到PCIE集成塊,然后由硬核驅動數據鏈路層和物理層通過PCIe接口發送給下游設備,下游設備的反饋通過axis_rc接口以Cpl或CplD的形式傳回。門鈴寫請求由NVMe控制模塊發起,請求以PCIe存儲器寫請求TLP的格式從axis_rq接口交由PCIE集成塊發送。
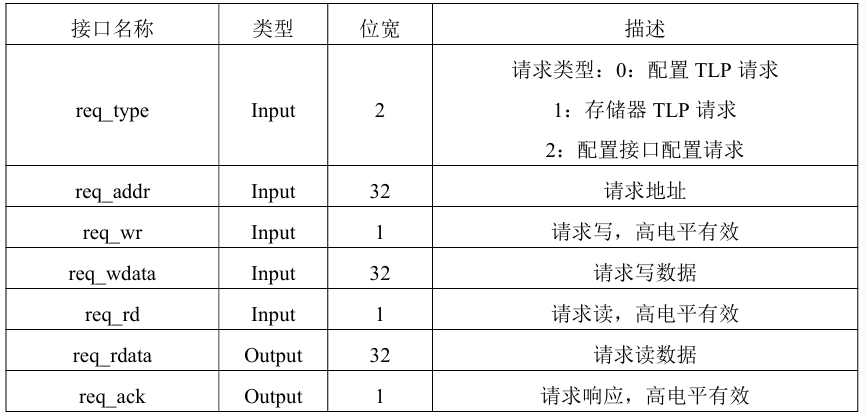
由于發起請求的模塊存在多個,并且在時間順序上初始化模塊先占用請求,NVMe控制模塊后占用請求,不會出現請求的競爭,因此設置一條內部請求總線用于發起請求和接收響應,該請求總線也作為請求模塊的上游接口。請求模塊的請求總線接口說明如表1所示。無論是配置請求還是門鈴寫請求,請求的數據長度都只有一個雙字,因此設置讀寫數據位寬均為32比特。
表1 請求總線接口
在接收到請求總線接口的請求事務后,當請求類型的值為0時,表示通過PCIE集成塊的配置管理接口發送請求,由于請求接口的接口和時序與配置管理接口基本一致,因此此時直接將請求接口信號驅動到配置管理接口完成請求的發送,請求讀數據和響應也通過選通器連接到配置管理接口。當請求類型值不為0時,則需要將請求轉換為TLP以axis接口形式發送,這一過程通過請求狀態機實現,請求狀態機的狀態轉移圖如圖2所示。
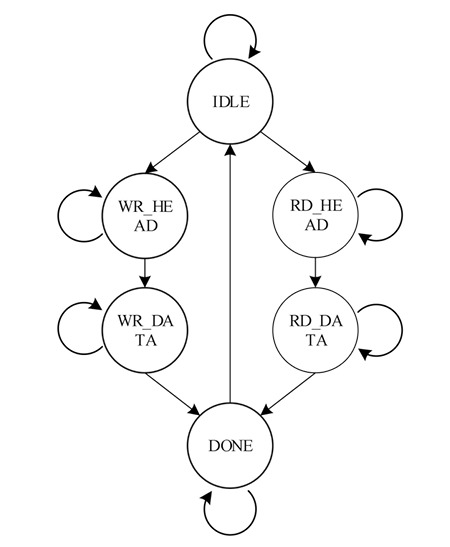
圖2 PCIe請求狀態轉移圖
各狀態說明如下:
IDLE:空閑狀態,復位后的初始狀態。當請求寫有效或請求讀有效,且請求類型值不為0時,如果請求寫有效跳轉到WR_HEAD狀態,如果請求讀有效或讀寫同時有效跳轉到RD_HEAD狀態,否則保持IDLE狀態。實際的上層設計中讀寫請求不會同時發生,這里的狀態跳轉條件增加了讀優先設計,從而避免異常情況的出現。
WR_HEAD:請求寫TLP頭發送狀態。該狀態下根據請求類型、請求地址組裝寫請求的TLP報文頭部,并將報文頭部通過axis_rq接口發送。當axis_rq接口握手時跳轉到WR_DATA狀態。
WR_DATA:請求寫TLP數據發送狀態。該狀態下將請求寫的數據通過axis_rq接口發送,當axis_rq接口握手時跳轉到DONE狀態。
RD_HEAD:請求讀TLP頭發送狀態。該狀態下組裝讀請求TLP報頭通過axis_rq接口發送,當接口握手時跳轉到RD_DATA狀態。
RD_DATA:請求讀CplD接收狀態。該狀態下監測axis_rc接口信號,當出現數據傳輸有效時,啟動握手并接受數據,然后跳轉到DONE狀態。
DONE:請求完成狀態。該狀態下使能req_ack請求響應信號,如果是讀請求同時將RD_DATA狀態下接收的數據發送到req_rdata請求讀數據接口。一個時鐘周期后回到IDLE狀態。
-
接口
+關注
關注
33文章
8961瀏覽量
153295 -
高速傳輸
+關注
關注
0文章
27瀏覽量
9149 -
nvme
+關注
關注
0文章
243瀏覽量
23138
發布評論請先 登錄
Xilinx FPGA NVMe Host Controller IP,NVMe主機控制器
Xilinx FPGA高性能NVMe SSD主機控制器,NVMe Host Controller IP
NVME控制器設計1
NVMe協議簡要分析
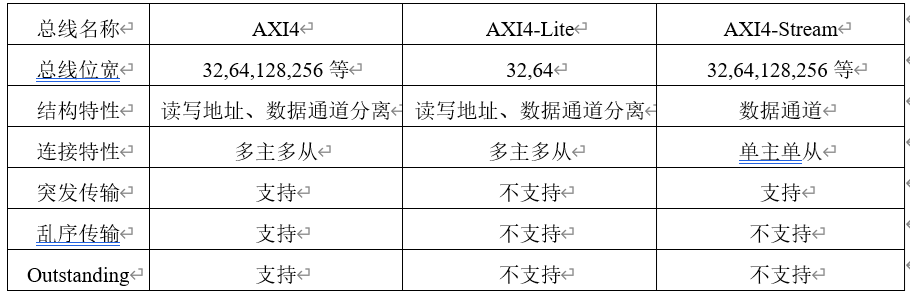
NVMe協議簡介之AXI總線
NVMe協議研究掃盲
PCIE高速傳輸解決方案FPGA技術XILINX官方XDMA驅動
PMC與Mellanox聯合展示 NVMe over RDMA 以及P2P的高速傳輸

NVMe IP over PCIe 4.0:擺脫XDMA,實現超高速!
NVMe簡介之AXI總線
NVMe IP高速傳輸卻不依賴XDMA設計之二:PCIe讀寫邏輯





 工商網監
工商網監
評論