 內存管理課程5節課的總結說明
內存管理課程5節課的總結說明
本文是任督二脈之內存管理課程第一節課的總結說明,由于水平有限,可能無法對宋老師所講完全理解通透,如有錯誤,請及時指證。
本文從5個方面進行說明:
1、 物理/虛擬/總線地址概念說明。
2、 MMU是什么,為什么,怎么做。
3、 內存分區和內存映射區。
4、 Buddy算法是個什么鬼。
5、 CMA的工作原理。
物理/虛擬/總線地址概念說明
所謂一花一世界,一葉一菩提,相同的事物在不同的角度可能會有不同的看法,對于物理地址,虛擬地址,總線地址的概念也是如此。
物理地址是MMU的視角所看到的內存地址。
虛擬地址是存在MMU的前提下CPU所看到的內存地址,當然我們實際編程的時候操作的也是虛擬地址。
總線地址是設備的視角所看到的內存地址。
比如一塊內存,物理地址是0,在設備端看起來是0x80000000,而物理地址0又通常被映射為虛擬地址0xc0000000,從而同一地址就具備了三個身份,但他們在物理上指的是同一片區域。
歸根結底,不論是MMU,CPU或程序員,還是設備,他們的終極目的是操作內存,至于怎么操作,它們又都有各自的比較舒服的操作方式,就是所謂的物理地址,虛擬地址和總線地址,至于為什么要通過這種方式操作內存,請參考下一節,MMU是什么,為什么,怎么做。
MMU是什么,為什么,怎么做
通常情況下,應用程序并不需要關心內存實際的物理地址,從應用程序的角度,“我需要的時候你就要給我,至于你是如何分配的,還有多少空閑,我不管”,MMU使這種需求成為可能。
我們知道應用程序的每一個進程都有自己的一張頁表,通常0-3G為用戶空間,3-4G為內核空間,每一個進程都傻傻的以為自己獨自擁有4G的內存空間,從而使得程序員在寫程序時不需要考慮計算機中物理內存的實際容量,但是我們真的沒有這么大的內存啊,怎么辦?沒關系,MMU可以解決。
MMU提供了虛擬地址和物理地址的映射功能,這個功能使每個進程都擁有“4G獨立的內存空間”成為可能。另外MMU還提供內存權限保護,用戶權限保護和Cache緩存控制等功能。
我們使用C語言定義一個const變量,MMU(應該是內核,而不是MMU)會標記該變量所在的內存區間為readonly,當另外一個文件單元通過虛擬地址嘗試寫這個變量,MMU在把虛擬地址轉換為物理地址的過程中發現,這段內存區域是readonly的,那么,不好意思,你無權寫入,并產生一個fault,內核收到這個fault向應用程序發送一個SIGSEGV,應用程序產生段錯誤并結束。
用戶權限保護,同理,MMU會標記內核空間的內存,當一個用戶程序嘗試訪問內核空間內存,也會被拒絕。
另外,MMU還提供Cache緩存控制功能。我們知道設備可通過DMA直接訪問內存,而不需要CPU;另一方面讀寫內存是非常耗時的(相對cache來說),如果我們的CPU存在高速緩存,把最近經常使用的內存緩沖的Cache可以大大的提高程序的效率。但是這時出現了一個問題,如何保證DMA和Cache的一致性問題?MMU提供了Cache是否命中的檢查,從而進一步可以保證DMA與Cache的一致性。
那么MMU是如何實現物理地址到虛擬地址的映射的呢,請看下圖:
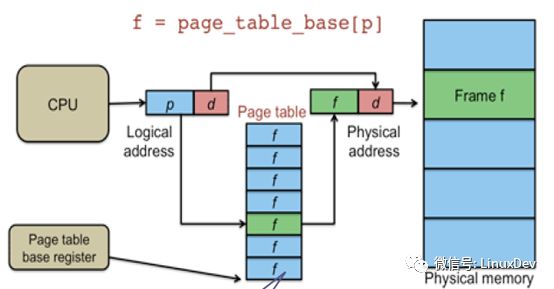
對于一個虛擬地址,0x12345670,地址的高20位表示頁表的物理地址,也就是0x12345(對應圖中的p),通過這個地址找到頁表所在位置,讀取該位置中的數據,這個數據指向物理地址的索引。虛擬地址的低12位表示物理地址索引的偏移值,也就是0x670(對應圖中的d),我們現在有了物理地址的索引值和偏移值,自然就可以找到所對應的物理內存位置。
另外MMU比較重要的一個組成部分需要介紹一下,TLB(Translation Lookaside Buffer)轉換旁路緩存,顧名思義,他是一個物理地址和虛擬地址轉換關系的緩存,是上圖中Page table的cache,也被稱為快表。
最后,附上宋老師的總結:http://mp.weixin.qq.com/s/SdsT6Is0VG84WlzcAkNCJA
內存分區和內存映射區
首先明確內存分區和內存映射區的區別,內存分區指的是實際的物理內存的分區,內存映射區指的是每一個進程所擁有的虛擬地址空間的分區情況。
對于一個運行了linux的設備,通常存在如下分區:DMAzone、Normal zone、HighMem zone。
DMAzone存在的原因是有些設備存在硬件缺陷,無法通過DMA訪問全部的內存空間,為了讓這些設備在需要內存的時候能夠每次都申請到訪問能力范圍內的內存空間,內核規定了一個DMA zone,當這些設備申請內存的時候,指定分配flag為GFP_DMA,它就可以拿到DMA zone的內存。也就是說如果我們的設備不存在這樣的存在缺陷的設備,我們就不需要DMA zone,或者說整個Normal zone都是DMA zone。一般我們稱DMA zong + Normal zone為Low memory zone。
HighMemzone存在原因是,當內存較大時,內核空間的3-4G空間無法把所有物理內存地址一一映射到內核空間,只能映射一部分,那么無法映射的那部分就是高端內存。
可以一一映射到內核空間的那部分內存,除去DMA zone就是Normal zone。
內存映射區可以簡單的理解為,每個進程都擁有的4G空間。其中3-4G為內核空間,這部分空間又被劃分為多個區域,其中與DMA zone和Normal zone存在一一映射關系的區域是DMA+常規內存映射區或者low memory映射區,同時也專門有個區域可以映射HighMem zone,但是并不存在一一映射的關系,這個區域是高端內存映射區。
所謂的一一映射,是指虛擬地址和物理地址只是存在一個物理上的偏移。
在x86系統中,內存分區和內存映射區存在如下的關系:
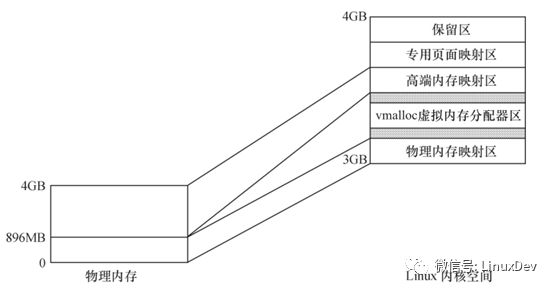
在arm linux中,內存分區和內存映射區的關系請參考內核文檔Documentation/arm/memory.txt
Buddy算法是個什么鬼
Linux的最底層的內存分配算法叫做Buddy算法,它以2的n次方頁為單位對空閑內存進行管理。就是說不管我在應用程序中分了多大的空間,1字節,100KB,或者其它任意的大小,底層實際分配的是以2的n次方個頁對齊的空間,當然并不是每一次用戶空間申請內存都會引起底層的內存分配,slab算法就可以在buddy算法的基礎上對內存進行二次管理,分配更小的內存空間,當然C庫也可以對分配的空間二次利用,比如指定mallopt函數的第一個參數為M_TRIM_THRESHOLD,并設置真正釋放內存給系統的閥值。。
Buddy算法的優點是避免了內存的外部碎片,但是長期運行后,大片的內存會比較少,而1頁,2頁,4頁這種內存會非常多,當我們分配大片連續內存的時候就會出問題,具體解決辦法請參考下一節-CMA的工作原理。
在linux系統中,我們可以通過/proc/buddy文件來查看當前系統空閑的連續內存空間剩余情況。
CMA的工作原理
應用程序中申請一塊內存,在應用程序看來是連續的,因為虛擬地址本身是連續的,但實際的內存空間中,所申請的這片內存未必是連續的,不過這對應用程序來說是沒關系的,因為應用程序不需要關心實際的內存情況,只要MMU把物理地址映射成虛擬地址就好了。但是如果沒有MMU的情況呢,我們又需要一片連續的內存空間,比如設備通過DMA直接訪問內存,這種情況下應該怎么辦呢?
CMA機制就是為了解決上面提到的問題而產生的。DMA zone并不是DMA專屬,其它的程序也可以申請該zone的內存,如果當設備要申請DMA zone空間的一大片連續的內存時候,已經沒有連續的大片內存了,只有1頁,2頁,4頁的這種連續的小內存。解決辦法就是我們標記某一片連續區域為CMA區域,這部分區域在沒有大片連續內存申請的時候只給moveable的程序使用,當大片連續內存請求來的時候,我們去這片區域,把所有moveable的小片內存移動到其它的非CMA區域,更改對應的程序的頁表,然后再把空出來的CMA區域給設備,從而實現了DMA大片連續內存的分配。
CMA機制并不是單獨存在的,它通常服務于DMA設備,在設備調用dma_alloc_coherent函數申請一塊內存后,為了得到一片連續的內存,CMA機制被調用,它保證了申請的內存的連續性。
另外CMA區域通常被分配在高端內存。
任督二脈之內存管理第二節課總結
本文是任督二脈之內存管理課程第二節課的總結說明,由于水平有限,可能無法對宋老師所講完全理解通透,如有錯誤,請及時指證。
本文從4個方面進行說明:
1、 Slab的基本原理以及它的文件接口說明
2、 kmalloc、vmalloc、malloc比較
3、 OOM是什么,為什么,怎么做
4、 FAQ:群里經常問到的,也是比較容易誤解的問題
slab的基本原理以及它的文件接口說明
在第一節課中,我們了解到,Linux的最底層,由Buddy算法管理著所有的空閑頁面,最小單位是2的0次方頁,就是1頁,4K,但是很多時候,我們為一個結構分配空間,也只需要幾十個字節,按頁分配無疑是浪費空間;另外,當我們頻繁的分配和釋放一個結構,我們希望在釋放的時候,這部分內存不要立刻還給Buddy,而是提供一種類似C庫的管理機制,在下一次在分配的時候還可以拿到同一塊內存且保留著基本的數據結構。基于上面兩點,Slab應運而生。總結一下,Slab主要提供以下兩個功能:
A.對從Buddy拿到的內存進行二次管理,以更小的單位進行分配和回收(注意,是回收而不是釋放),防止了空間的浪費。
B. 讓頻繁使用的對象盡量分配在同一塊內存區間并保留基本數據結構,提高程序效率。
那么,Slab是如何工作的呢?
如果某個結構被頻繁的使用,內核源碼就可以針對這個結構建立一個或者多個Slab分區(姑且這么叫),每一個Slab分區從Buddy拿到1頁或者多頁內存,并把這些內存劃分為多個等分的這個結構大小的小塊內存,這些Slab分區只用于分配給這個結構,通常稱這個結構為object,每一次當有該object的分配請求,內核就從對應的Slab分區拿一小塊內存給object,這樣就實現了在同一片內存區間為頻繁使用的object分配內存。請看下圖
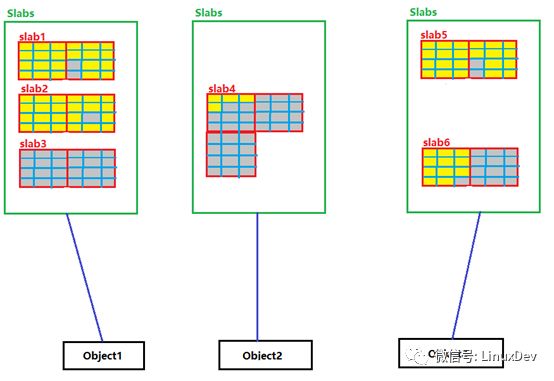
黑框表示頻繁使用的結構;紅框表示slab分區,一個結構內核可能為它分配一個或多個Slab;每個Slab分區有可能包含多個page,被分隔開的多個紅框表示Slab分區的多個pages;藍框表示Slab分區為對應的Object劃分的一個一個的小內存塊。填充黃色的框表示active的object,灰色填充的框表示未active的object,如果整個Slab分區的所有藍框都是灰色的,表示這個Slab分區是未active的。
Linux為用戶提供了Slab的文件查看接口,和命令接口。
文件接口:/proc/slabinfo
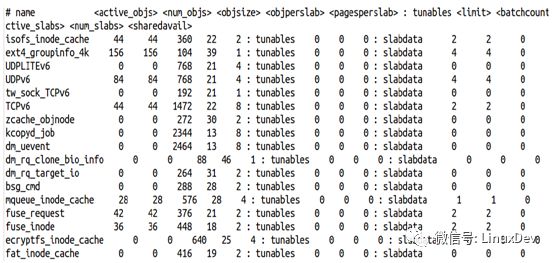
上圖所示為slabinfo文件的內容,第一行為表頭:
Name:Object名字
Active_objs:已經激活的投入使用的object個數
Num_objs:為這個object分配的小內存塊個數
Objsize:每一個內存塊的大小
Objperslab:每一個Slab分區包含的object個數
Pagesperslab:每個Slab分區包含的page的個數
Active_slabs:已經激活的投入使用的Slab分區個數
Num_slabs:為這個object分配的Slab分區個數
我在查看Slabinfo文件的時候,發現有的Num_objs為0,正常Active_objs為0是可以理解的,但是總的object數不應該為0啊,然后繼續看,Active_slabs和Num_slabs也都為0,也就是說,這個時候內存還沒有為這個結構分配Slab分區,一切就都解釋的通了。
另外還有一部分slabinfo的內容是這樣的:
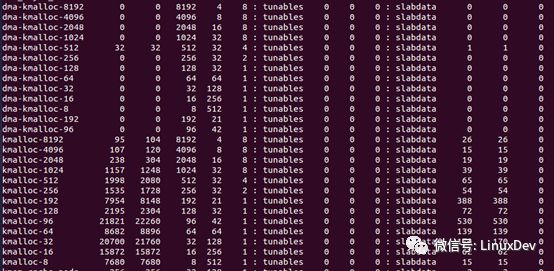
就是說,除了經常頻繁使用的結構,內核為他們分配了slabs,還同時定義了一些特定的slabs供驅動使用。
命令接口:slabtop
直接運行slabtop命令(要加sudo,上面查看slabinfo文件同樣),內容如下
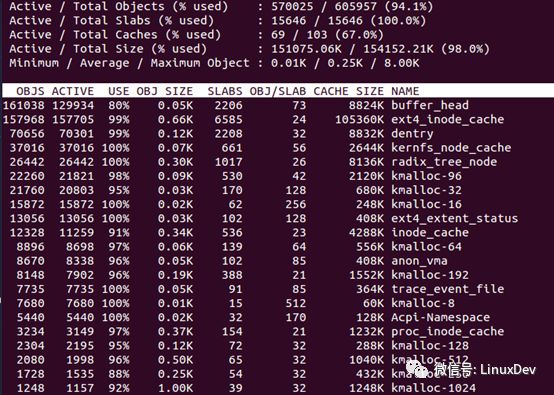
有點類似top命令,按照使用內存的多少進行排序。
最后再說一句,slab只用于分配低端內存,所分配的內存也只會被映射到物理內存映射區,所以vmalloc跟slab一毛錢關系都沒有。
kmalloc、vmalloc、malloc比較
這部分內容牽連太多,也不好區分,直接上圖:
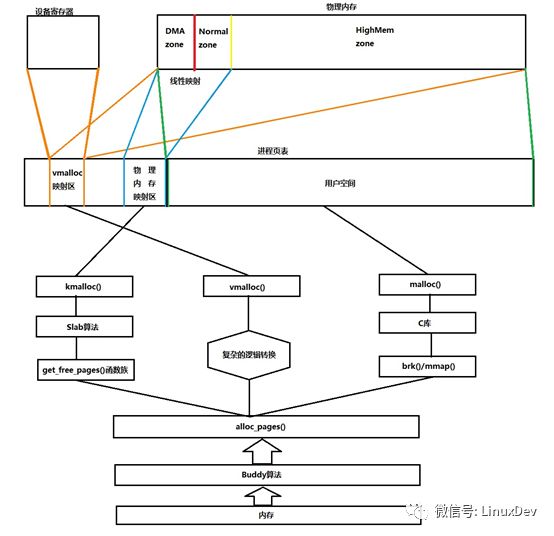
(此圖有誤:highmem不是映射到vmalloc)
如上圖所示:
如上圖所示:
A.kmalloc函數是基于slab算法的,從物理內存的low mem獲取內存,并線性映射到物理內存映射區(映射過程開機就已經完成了),由于是線性映射,物理地址和虛擬地址存在簡單的轉換關系(物理地址和虛擬地址的值只是相差了一個固定的偏移),所以使用kmalloc分配內存是十分高效的。
B. vmalloc函數分配內存的過程需要先通過alloc_pages函數獲取內存(獲取范圍是整個內存條),然后在通過復雜的邏輯轉換(注意,vmalloc并不是簡單的線性映射,它獲取的內存并不是連續的),把物理內存映射到vmalloc映射區。這個過程比較復雜,所以,如果只是使用vmalloc分配很小的內存空間是不合適的。
C. malloc是標準C庫的函數,C庫對申請的內存做二次管理,類似Slab。但是注意一點,當我們使用malloc函數申請一片內存時,實際上是從C庫獲取的內存,就是說,調用malloc返回后,系統未必給你一片真正的內存,分兩種情況
a. C庫還持有足夠的內存,那么malloc就可以直接分配到C庫現有的內存
b. C庫沒有足夠的內存,malloc返回時,系統只是把要申請的內存大小的虛擬地址空間全部映射到同一塊已經清零的物理內存,當我們實際要寫這片內存的時候,才通過brk/mmap系統調用分配真實的物理內存,并改寫進程頁表。
D.另外有一點值得一提,vmalloc映射區,除了vmalloc函數分配的內存會映射在該區域,設備的寄存器也同樣會通過ioremap映射到該區域。
E. 根據上面要點C的描述,在編寫實時程序時,我們可以通過下面這種方式,減少系統內存的頻繁分配,而是基于C庫管理的內存。
#include
#include
#define SOMESIZE (100*1024*1024) // 100MB
int main(int argc, char *argv[])
{
unsigned char *buffer;
int i;
if (!mlockall(MCL_CURRENT | MCL_FUTURE))//鎖定進程當前和將來所有的內存
mallopt(M_TRIM_THRESHOLD, -1UL);//設置C庫釋放內存的閥值為最大正整數
mallopt(M_MMAP_MAX, 0);
buffer = malloc(SOMESIZE);
if (!buffer)
exit(-1);
/*
*Touch each page in this piece of memory to get it
*mapped into RAM
*/
for (i = 0; i < SOMESIZE; i += 4 *1024)//由于COW,確保內存被真實分配
buffer[i] = 0;
free(buffer);
/*
/* 接下來的所有內存分配動作都不是觸發系統內存的真是分配,而是從C庫獲取
*大大提高程序的效率,確保程序實時性。
*/
while(1);
return 0;
}
OOM是什么,為什么,怎么做
什么是OOM:上面提到,當我們使用malloc分配內存時,系統并沒有真正的分配內存,而是采用欺騙性的手段,拖延分配內存的時機,防止無謂的內存消耗,只有在我們寫入的時候,產生page fault才會拿到真實的內存,且是寫多少才分配多少,那么,問題來了,當我們通過malloc獲取一片內存并成功返回,然后開始逐步使用內存,系統也逐步的分配真實的內存給進程,但這個過程中,另外一個耗內存的程序快速的拿走所有的內存,導致我的進程在逐步寫入的過程發現剛剛說好給我的內存現在沒有了,這種情況就是OOM,out of memory!
在Linux系統,每一個進程都有一個oomscore,這個數值越高,說明進程消耗的內存越多,在發生OOM的情況下,oom score越高的進程就越有可能被系統干掉,從而緩解系統的內存壓力。我們可以通過/proc/pid/oom_score文件查看進程的oom score。
那么有沒有什么辦法可以調整進程的oom score,就算這個進程比較耗內存,但是在OOM時候,這個進程仍然不會干掉。系統提供兩個接口文件給用戶:
/proc/pid/oom_ adj:可配置范圍是-17到15,設置為15,oom score最大,最容易被干掉,設置-16,oom score最小,設置-17為禁止使用OOM殺死該進程。
/proc/pid/oom_score_adj:oom score會加上這個值,也可以設置負數,但如果負數的絕對值大于oom score,oom score最小為0。
FAQ
Q.kfree和free函數調用后,內存是否還給了Buddy?
A.kmalloc分配的內存是基于slab的,malloc分配的內存是基于C庫的,slab和C庫都會對內存進行二次管理,實際到底有沒有被釋放,只有Slab和C庫他們自己知道。
Q.kmalloc,vmalloc,malloc他們從哪個zone申請物理內存,然后映射到那個映射區?
A.kmalloc從low mem獲取物理內存,然后映射到內核空間的物理內存映射區,vmalloc和malloc都可以從整個內存條獲取內存,vmalloc申請的內存映射到vmalloc映射區,malloc申請的內存映射到進程的用戶空間。
寫到這里,群里已經發出了第二節課問答集,其它更多內容參考該文檔。
任督二脈之內存管理第三節課總結
本文是任督二脈之內存管理課程第三節課的總結說明,由于水平有限,可能無法對宋老師所講完全理解通透,如有錯誤,請及時指證。
本文從7個方面進行說明:
1、 VMA到底是個什么鬼?
2、 Linux提供的VMA文件接口和命令接口說明。
3、 Page fault的產生原因分析以及與VMA的關系。
4、 物理內存、頁表、進程之間的愛恨情仇。
5、 VSS、RSS、PSS、USS概念說明和實際的應用場景
6、 進程內存使用情況命令接口smem。
7、 內存泄漏的界定和監測辦法。
VMA到底是個什么鬼?
VMA是Virtual MemoryAreas的縮寫,虛擬內存區域,指的是用戶空間0-3G范圍內進程所擁有的多個全部零散分布的連續的虛擬內存空間。
注意上面這句話的三個定語:
用戶空間0-3G范圍內進程所擁有的:VMA區域存在于用戶空間,當然“所擁有”并不是獨占,也有可能是共享的。
多個全部零散分布的:進程擁有多個VMA區域,但是零散分布在0-3G空間。
連續的:這里說的連續,指的是單個VMA區域在虛擬地址空間是連續的。
看完上面的內容基本知道VMA是個什么東西了,那么VMA產生的原因是什么,為什么要搞個這個概念出來,VMA區域是客觀存在的,你不定義VMA的struct,進程的代碼段,數據段,堆,棧都是客觀存在的,進程只要在代碼段按序執行就好了,我管你叫什么名字,所以進程并不需要關心這個概念,真正需要VMA概念的是內核,通過VMA這個概念方便實現對所有進程內存空間的管理。
我們知道一個進程被fork出來,內核會維護一個taskstruct,這個結構的mmap成員維護了一個vm_area_struct的鏈表,這就是VMA的結構,內核通過維護這個結構來實現對進程的內存資源的管理、隔離和共享。
舉個例子:進程使用malloc分配內存,這時C庫沒有足夠的內存,內核的Lazy機制采用欺騙性手段,拖延分配內存的時機,這時,內存并沒有被真正分配,內核只是把所有要分配的頁表都映射到同一片已經清零的物理地址,并標記頁表權限為readonly,但是當malloc返回的時候,對應的heap的VMA區域已經產生了,且已經進入內核管理的vm_area_struct鏈表中了,且權限被標記為讀寫權限,當我們向這片內存寫入的時候,MMU在虛擬地址轉換到物理地址的過程,發現頁表的權限標記為readonly,而你要寫入,這是不被允許的,于是產生Page fault,內核收到Page fault,查看對應的VMA鏈表,發現進程實際是有寫的權限,于是分配頁面,并改寫頁表,但是這整個過程,進程是不知道的,進程只是傻傻的以為,哈哈,老子又拿到了一片內存!
Linux提供的VMA文件接口和命令接口
Linux為用戶提供了VMA查看的命令接口和文件接口。
命令接口:pmap
文件接口:/proc/pid/maps 、 /proc/pid/smaps
這些接口都可以看到進程的VMA區域分布情況,占用空間大小,和相應的權限
此處不做過多說明。
Page fault的產生原因分析以及與VMA的關系
其實上面的“VMA到底是個什么鬼”章節,已經介紹了一種Pagefault產生的原因,也說明了與VMA的關系。下面列舉產生Page fault的4中原因。
A.動態分配內存,第一次寫入,由于內核的Lazy機制,頁表的權限為readonly,VMA權限為r+w,MMU產生Page fault,這種情況是真實的缺頁,下面還會介紹并不是真實的缺頁的情況。這種缺頁也叫做Minor Page fault。
B. 進程訪問自己的VMA區域以外的空間,這種行為被認為是非法的,同樣會產生Page fault,但不會像A中一樣引起真正的內存分配,反而會收到一個segv,程序被干掉。這種情況其實并不是真正的缺頁。
C. 進程訪問自己的VMA區域,但是并沒有執行該操作的權限,比如進程嘗試寫代碼段或者跳轉到數據段執行,這也被認為是非法的,同樣收到segv,程序被干掉。這種情況也不是真正的缺頁。
D.進程訪問自己的VMA區域,且權限正確,但是對應的物理內存內容被swap到硬盤,這種情況毫無疑問才是徹徹底底的缺頁,也會產生Page fault。這種缺頁也叫做Major Page fault。
物理內存、頁表、進程之間的愛恨情仇
此部分說起來比較復雜,直接上圖:
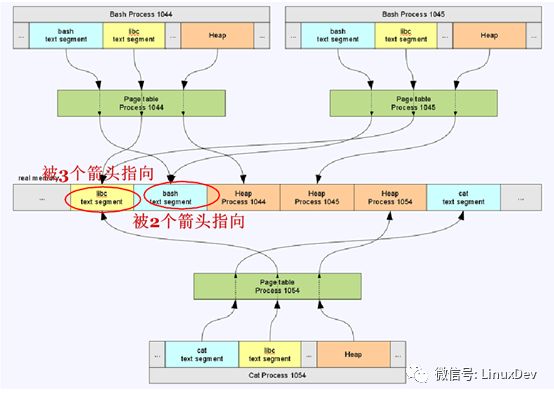
上圖中,process1044,1045,1054是進程的虛擬地址空間,綠色框圖是他們各自的頁表,圖片最中間的是實際的物理內存。進程1044,1045,1054在虛擬地址空間各自擁有多個VMA區域,但是多個進程的VMA可能通過各自頁表指向同一片內存區域,比如上圖中libc代碼段,三個進程的libc的VMA區域都通過頁表指向同一片內存,就是說這三個進程共享這段內存。當然進程的VMA通過頁表指向的內存也有可能是被這個進程獨占的,比如上面三個進程的堆,都是各自獨占的。
舉個例子:假設上圖中的內存是女神,女神為了襯托自己漂亮,身邊難免要有幾個丑女閨蜜,丑女閨蜜就是頁表,屌絲process 1044,1045,1054對女神愛慕已久,只是苦于女神高高在上,無法接近,那么怎么辦,曲線救國,先接近她的閨蜜,三個屌絲通過女神的三個閨蜜都輕松的獲取到女神的基本愛好,喜歡吃什么,喜歡什么顏色,三個屌絲雖然都各自獲取到一份信息,但是這個信息是客觀存在的只有一份(這就是上面說的共享的情況),這時,其中一個屌絲1044,辛苦加班12個月,攢錢給閨蜜買了個大金鏈子,這個大金鏈子就是屌絲1044跟女神所擁有的獨家美好記憶(這就是上面說的獨占的情況)。
VSS、RSS、PSS、USS概念說明和實際的應用場景
話不多說,還是上圖吧:
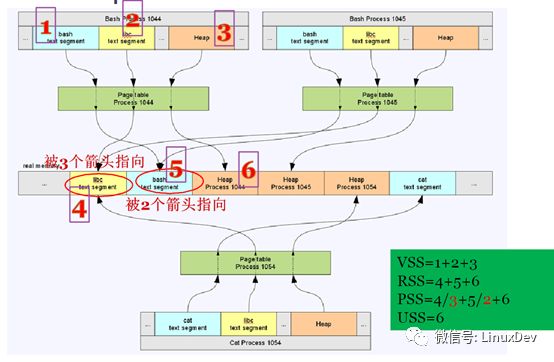
如圖所示:
VSS是進程看到的自己在虛擬內存空間所占用的內存。
RSS是進程實際真正使用的內存。
PSS是多進程共享一片內存的容量取平均數,在加上自己獨占的內存。
USS是進程所獨占的內存容量。
通常,VSS≥RSS>PSS>USS,VSS之所以大于等于RSS,是考慮內核的Lazy機制并沒有真正的分配內存以及內存被換出等情況。
好!繼續舉例子:女神懷了高富帥的娃,苦于腹中胎兒一天天長大,高富帥又不值得托付,所以決定在眾多屌絲中擇一名形象氣質佳的男士作為配偶,屌絲1044,1045,1054踴躍報名,由于三人形象上都不分伯仲,所以女神的主要考察點改為:誰更在乎自己多一點。于是:
VSS:屌絲自以為對女神的在乎程度,知道女神的愛好,還給女神買大金鏈子都計算在內。
RSS:每個人的感知程度不一樣,屌絲縱然萬般寵愛,可女神沒感覺到也是白搭,這個值是女神感受到的在乎程度。
PSS:請來裁判,考察屌絲日常的在乎程度,知道女神愛好+1分,送大金鏈子+3分,這個分數是比較客觀的。
USS:單獨考量每個屌絲送多少大金鏈子。
所以,綜上,我們知道PSS值是比較客觀的值,VSS是一個虛擬的值,RSS是一個實際的值,USS是獨占的值。
進程內存使用情況命令接口smem
Linux提供命令接口smem來查看系統中進程的VSS、RSS、PSS、USS值。
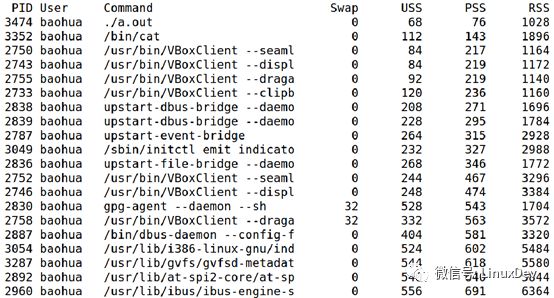
還可以使用—pie選項和—bar選項進程圖形化顯示,更加一目了然。
內存泄漏的界定和監測辦法
進程運行時申請的內存,在進程結束后會被全部釋放。內存泄漏指的是運行的程序,隨著時間的推移,占用的內存容量呈現線性增長,原因是程序中的申請和釋放不成對。
如何監測程序是否出現了內存泄漏的情況,一方面我們可以通過上文提到的smem命令,連續的在多個時間點采樣,記錄USS的變化情況,如果這個值在連續的很長時間里呈現出持續增長,基本就可以斷定程序存在內存泄漏的情況,然后你就可以手動去程序中查找泄漏位置。
另一方面,如果程序代碼量較大,不方便查找定位內存泄漏點,可以使用valgrind和addresssanitizer來查找程序的內存泄漏。兩種方式各有優劣,valgrind在虛擬機中運行程序,所以程序運行效率下降;addresssanitizer則需要改動源碼,在源碼中包含sanitizer/lsan_interface.h文件,然后在需要檢查內存泄漏的地方調用函數__lsan_do_leak_check。兩種方式都可以定位內存泄漏的位置。
任督二脈之內存管理第四節課總結
本文是任督二脈之內存管理課程第四節課的總結說明,由于水平有限,可能無法對宋老師所講完全理解通透,如有錯誤,請及時指證。
發了前幾天的總結后,有群里的朋友@jeff表示,我這樣大篇幅的文字描述,估計沒幾個人有耐心看下去,想想也是,內存管理本身就比較復雜,枯燥,我聽了宋老師的課,了解個一知半解,轉述的過程可能也不到位。所以這一次盡量使用圖片進行說明,然后逐步展開。話不多說,先上圖吧。
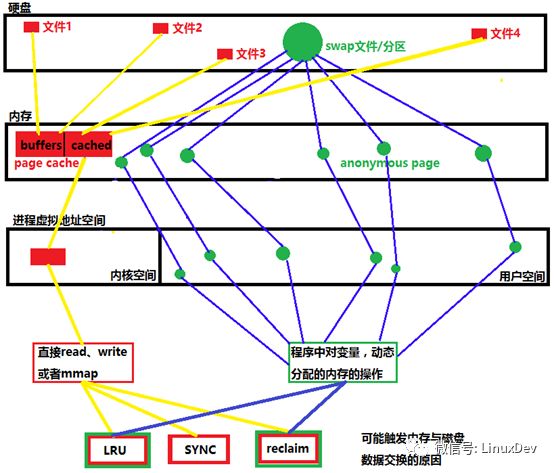
如圖所示:有兩條脈絡,分別用黃線和藍線標識,黃線的脈絡為有文件背景的數據交換過程,藍線為無文件背景的數據交換過程。
那么何為有文件背景的頁File-backedpage,何為無文件背景的頁,也就是匿名頁anonymous page,直接盜用宋老師課件圖片:
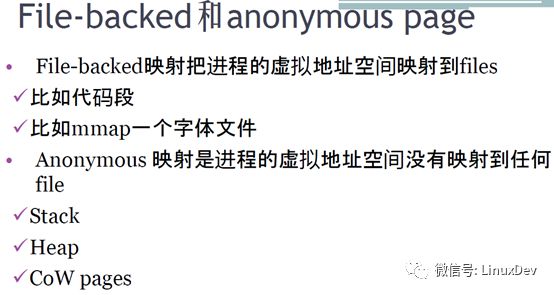
特別說明一下程序的代碼段,程序運行的時候,實際上是把ELF文件的代碼段加載到物理內存的page cache,然后映射到內核空間的page cache頁,所以程序的代碼段也是file backed的。
接下來分兩條脈絡來進行說明和擴展。
Filebacked
在硬盤中能對應到實際的文件的,歸納為file backed,文件在open后,會被加載到物理內存,我們稱這片內存為page cache頁,在3.14版本以前的內核,page cache又被劃分為buffers和cache,3.14版本以后不做區分,全部看作page cache。Page cache被映射到內核空間的虛擬地址,用戶通過兩種方式訪問磁盤上的文件,直接讀寫和mmap到用戶空間,可能觸發page cache頁面和磁盤數據交換的有LRU,手動同步SYNC和內存回收reclaim。
上面的一段話,描述了filebacked的整體脈絡,有一下幾個問題需要單獨說明:
A.3.14版本以前的pagecache劃分為buffers和cache,他們有什么區別?
要說明這個問題,先明確一個概念,page cache作為磁盤的一個緩沖,它緩沖過來的文件內容是可以被犧牲掉的,就是說我內存空間不足的時候,我可以回收這部分內存資源,所以在Linux操作系統看來,這部分內存雖然被占用,但是仍然是available的。

通過free命令,可以看到3.13版本分別列出了buffers和cached的數值,buffers值是直接操作裸分區的pagecache的大小,比如我們通過dd命令讀寫SD卡;cached值是操作文件系統上的文件的page cache的大小,比如直接open dev/sda1/hello.c文件,這個文件的page cache被叫做cached。
看上圖,free命令的第三行,有一個-/+buffers/cache,這個值是如何計算的呢?
上面說過,page cache是可犧牲的,這個值就是page cache被回收后的內存的used和free的值,盜用宋老師課件again。
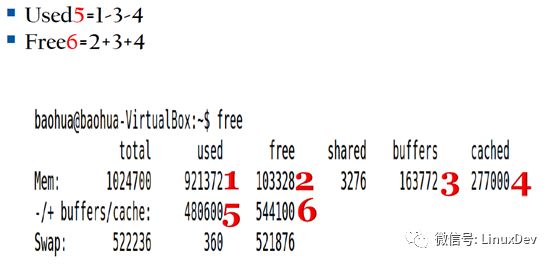
其實這種劃分沒有什么特別的意義,他們的區別是各自的background不同而已,所以3.14版本之后的內核不做buffers和cached的區分,free命令的-/+ buffers/cache這一行也不再需要,只是單獨搞出一個available值,用于表示當前系統中包括已經使用的page cache(可犧牲),到底有多少可利用的內存。

原諒我的free還不夠給力,并沒有列出available值。
B.mmap和直接讀寫有什么區別?
Pagecache被映射到內核空間后,用戶想要操作對應的文件,實際上是對內存里page cache的操作,系統會在合適的時機回寫到磁盤中對應的文件。操作的方式有兩種,直接讀寫,和通過mmap把page cache在映射到用戶空間一份。
程序調用read、write函數的時候,陷入到內核空間,實際調用的是file operation結構的read、write接口,這兩個接口必然要做的一件事就是copy_from_user和copy_to_user,我們知道這兩個函數是會引起內核空間與用戶空間的數據拷貝的,就是說每一次read和write都要進行一次拷貝。
mmap則完全不同,它把pagecache直接映射到用戶空間,現在用戶空間和內核空間的頁表都可以對應到page cache物理內存。然后通過mmap返回的指針來讀寫page cache,這個過程是沒有用戶空間和內核空間的內存拷貝的。
通常在操作顯存設備的時候會使用mmap,比如我可以通過mmap把/dev/fb0映射到用戶空間,通過讀寫mmap返回的指針來實現對屏幕的顯示。
C.LRU是個什么鬼?
LUR,LeastRecently Used,翻譯過來就是最近最少使用,顧名思義,內核把最近最少使用的page cache內容或者anonymous頁面交換出去。上圖,盜圖three
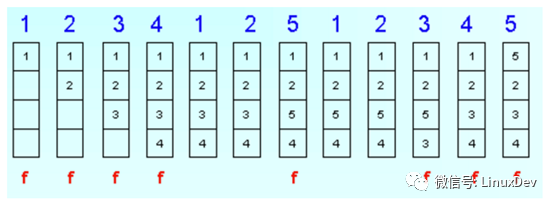
現在cache的大小是4頁,前四次,1,2,3,4文件被一次使用,注意第七次,5文件被使用,系統評估最近最少被使用的文件是3,那么不好意思,3被swap出去,5加載進來,依次類推。
所以LRU可能會觸發pagecache或者anonymous頁與對應文件的數據交換。
D.SYNC指的什么,如何觸發pagecache與文件的數據交換?
系統為用戶提供了,數據從pagecache回寫到文件的接口,sync命令。只要運行sync命令就可以觸發page cache與文件的數據交換。
另外,我們還可以通過向/proc/sys/vm/drop_caches寫入數字來清空對應的caches,一般寫入之前,最好執行一下sync命令來同步一下,以便釋放更多的空間,因為drop_caches只回收cleanpages,不回收dirtypages,所以如果想回收更多的cache,應該在drop_caches之前先執行"sync"命令,把dirtypages變成cleanpages。
echo 1 > /proc/sys/vm/drop_caches //清空 pagecache
echo 2 > /proc/sys/vm/drop_caches //清空 dentries 和 inodes
echo 3 > /proc/sys/vm/drop_caches //清空所有緩存(pagecache、dentries 和 inodes)
anonymous
在進程中定義的堆,棧等沒有文件背景的頁面,如果系統沒有創建swap分區或者swap文件,那不好意思,匿名頁只能常駐內存,直到程序退出,或者發生OOM程序被干掉。與file backed不同的是,anonymous本身就在內存中,而file backed是磁盤中的文件,為了提高效率把內存作為磁盤的緩沖區,就是page cache,page cache可以往對應文件交換,anonymous頁如果過大的話,可以往swap分區或者創建的swap文件中交換。要操作這些匿名頁,直接在程序源碼中操作變量和動態分配內存的指針就好了。
那么,對于anonymous頁,在什么情況下會觸發數據交換呢?
除了LRU會產生匿名頁的交換,內存回收也會引發數據交換,reclaim,Linux有一個后臺進程kswapd,負責回收page cache和匿名頁,回收速度較慢,但是不會影響程序運行,程序不會被delay,當系統內存資源異常緊張時,會觸發Direct reclaim,這個過程回收速度較快,但是進程會被直接delay,直到回收夠足夠的內存。
至于何時kswapd開始回收內存,何時Directreclaim,有三個門限值,min,low,hight,當內存的水位達到low,說明內存緊張,這時kswapd開始工作,慢慢回收內存,直到水位達到high,當系統內存異常緊張時,達到min水位,Direct reclaim被觸發。
Swappiness
當系統內存不足時,可以從filebacked pages或者anonymous pages回收內存,不論哪個被回收,再次被加載進內存一定都會影響程序的效率。具體從哪里回收,Linux提供swappiness值作為衡量標準。
Swappiness越大,越傾向于回收匿名頁;swappiness越小,越傾向于回收file-backed的頁面。當然,它們的回收方法都是一樣的LRU算法。盜圖four。

順便附上一個參考鏈接:http://mp.weixin.qq.com/s/BixMISiPz3sR9FDNfVSJ6w
zRamswap
對于嵌入式設備,它的磁盤是SD卡,MMC,一方面速度較慢,另一方面,有使用壽命的問題,不太適合做swap分區。嵌入式設備一般會從內存中拿出一小部分當作虛擬內存,這個就是zRam。但是這樣直接用又沒有什么意義,因為虛擬內存的目的就是在內存不足時“擴展內存”,現在內存還是那片內存就是換了個說法,所以為了“擴展內存”,當系統把內存交換到這個虛擬內存,通常是以壓縮的方式存儲,當swap in時在解壓。這樣就某種程度的“擴展了內存”,但是缺點是增加了CPU的壓力,需要進行壓縮和解壓縮。
任督二脈之內存管理第五節課總結
本文是任督二脈之內存管理課程第五節課的總結說明,由于水平有限,可能無法對宋老師所講完全理解通透,如有錯誤,請及時指證。
第五節課的內容多且雜,其實完全可以合并到前四節課中。但考慮前四篇總結已經完成,章節插入不方便,所以還是多寫一篇。
本文分成兩部分來論述
1、DMA與Cache一致性問題。
2、 常用的命令接口和文件接口簡要說明。
DMA與Cache一致性問題
關于這一部分,宋老師的文章已經講解的非常細致,我在寫也無非是畫蛇添足,所以此處只做簡單總結。附上文章連接,http://mp.weixin.qq.com/s/5K7rlPXo2yIcoIXXgqqLfQ
而實際上,如果你不是在IC公司,大部分時候你只需要在驅動程序中輕松敲下dma_alloc_coherent來獲取一片能確保DMA和cache一致性的內存就可以了,具體實現細節對你來說可能并不重要。請看下圖:
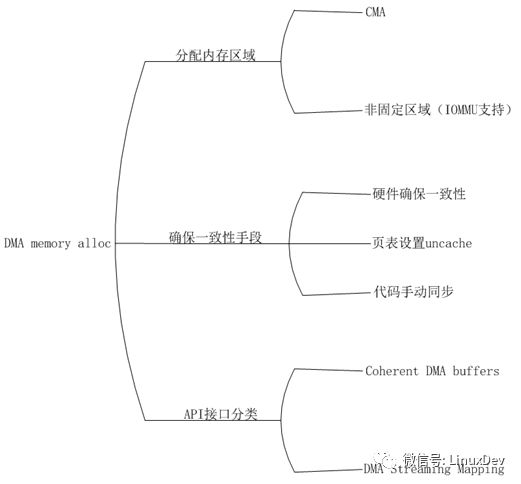
A.DMA的內存分配區域
不論是應用程序還是驅動程序,在獲取內存時都需要獲得一片連續地址的內存,但是由
于DMA設備訪問內存不經過MMU,所以也無法把不連續的物理地址映射為連續的虛擬地址,解決這個問題有兩種方式:
a.在CMA區域申請DMA內存,因為CMA本身是一片連續的物理內存,CMA通常被分配在高端內存,這個時候這片內存會被映射到vmalloc映射區,如果CMA在低端內存,則不需要重新映射,因為低端內存在開機時已經與low Memory映射區建立了一一映射關系。
b.如果設備存在IOMMU,那么做DMA內存分配時則不需要關心具體的內存分配區域,IOMMU會讓設備看到一片連續的地址范圍,它的功能類似MMU,只不過MMU是把物理地址轉換為連續的虛擬地址供CPU使用,而IOMMU是把物理地址轉換為連續的總線地址供設備使用。
B.確保DMA和cache一致性的手段
確保DMA和cache一致性的手段有以下三種:
a.頁表設置uncache
要保證DMA和cache一致性最簡單辦法,在申請到內存后,修改對應的頁表,將頁表的cache屬性改為uncache,這樣,當CPU在訪問該片內存時就不會從cache取數據。
b.硬件確保一致性
有的設備提供了確保一致性的硬件機制,這時我們申請內存后則不需要修改頁表的cache屬性,一致性由硬件來保證。
c.代碼手動同步
如果對應的內存區域已經申請好了,設備直接使用,那么驅動就無法更改對應頁表的cache屬性,這時解決一致性的手段時在每次訪問這篇內存前手動同步cache內容到內存,同時禁止CPU對這片內存的訪問,直到設備訪問完成。實際上下面提到的DMA streaming mapping就是通過這種方式實現的。
C.API接口
當我們的驅動自己獲取內存,可以使用一致性DMA緩沖區API接口,就是
dam_alloc_coherent();如果對應的內存已經被成功分配,我們在使用前需要調用DMA流映射API接口,確保cache的內容被成功flush到內存,對應的函數有dma_map_sg()和dma_map_single(),他們兩個的區別是,sg映射的內存是分散/聚集的,分散在不同的位置,single映射的內存是連續的一片內存,通常是CMA。
常用的命令接口和文件接口簡要說明
A.文件Dirty數據寫回配置接口
/proc/sys/vm/dirty_expire_centisecs:設置Dirty數據的寫回時間期限,超過這個時間,在flusher線程下次喚醒后,寫回這部分數據,單位是百分之一秒,厘秒。
/proc/sys/vm/dirty_writeback_centisecs:flusher線程周期性喚醒的時間,單位是厘秒,設置為0,表示禁止定期寫回。Flusher線程喚醒后會把超過期限的臟頁和進程超過dirty_background_ratio值的臟頁寫回。
/proc/sys/vm/dirty_background_ratio:進程持有的臟頁的個數閥值,單位是頁,超過這個值,flusher線程在下次喚醒后會對臟頁進行寫回。
/proc/sys/vm/dirty_ ratio:進程持有的臟頁的個數閥值,單位是頁,超過這個值,進程delay,無法在進行任何的寫操作,并且進程自行完成臟頁的回寫。
B.Memory Cgroup的使用
控制group的最大使用內存示例如下:
$:cd /sys/fs/cgroup/memory
$:mkdir A //創建一個分組
$:cd A/
$echo $((200*1024*1024)) >memory.limit_in_bytes //設置該組最大可使用內存200M
$:cgexec –g memory:A ./a.out //將a.out添加到組A并執行
C.內存回收接口說明
在內存管理四章節中提到內存回收有三個水位,min,low和hight,當內存的水位達到low,說明內存緊張,這時kswapd開始工作,在后臺慢慢回收內存,直到水位達到high,當系統內存異常緊張時,達到min水位,程序被堵住,Direct reclaim被觸發。具體相關接口如下:
/proc/zoneinfo //該文件可以查看到各個zone的情況,包括各個zone的三個水位設置
/proc/sys/vm/min_free_kbytes //可用于查看和設置min水位的值
其中low水位和high水位沒有對應的設置接口,是通過計算得來的。
Low = min*5/4
High = min*6/4
各個zone的水位標準是按總的水位標準等比例劃分的,比如normal zone是800M,內存一共1G,min_free_kbytes被設置為30720,即30M,那么,normal zone的min水位就等于,800/1024 * 30720,就是24000
D.Swappiness接口
Swappiness越大,越傾向于回收匿名頁;swappiness越小,越傾向于回收file-backed的頁面。當然,它們的回收方法都是一樣的LRU算法。Swappiness的接口有兩個,一個是cgroup里的swappiness,一個是/proc/sys/vm下的swappiness,他們的區別是作用域不同,cgroup里的swappiness只控制組內程序的回收傾向,而/proc/sys/vm/swappiness控制當前整個系統,除了在cgroup被重新定義的程序。
E.Getdelays工具
要使用該工具需要打開內核選項CONFIG_TASK_DELAY_ACCT和CONFIG_TASKSTATS。該工具的源文件在LinuxKernelSource/Documentation/accounting下。使用getdelays可以查看當前系統或者某個進程調度的延時,IO的delay情況,swap和內存回收的delay情況,幫助用戶查看程序的耗時情況。
F.Vmstat命令
該命令可周期性的查看swap in/out和block in/out的情況。
-
CMA
+關注
關注
0文章
29瀏覽量
9983 -
MMU
+關注
關注
0文章
92瀏覽量
18656 -
Buddy
+關注
關注
0文章
5瀏覽量
7554
原文標題:陳延偉:任督二脈之內存管理總結筆記
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監
評論