 未來的圖像識別:更大規模、自我標注
未來的圖像識別:更大規模、自我標注

2017 年 7 月,最后一屆 ImageNet 挑戰賽落幕。
為何對計算機視覺領域有著重要貢獻的 ImageNet 挑戰賽,會在 8 年后宣告終結?
畢竟計算機系統在圖像識別等任務上的準確率已經超過人類水平,每年一次突破性進展的時代也已經過去。
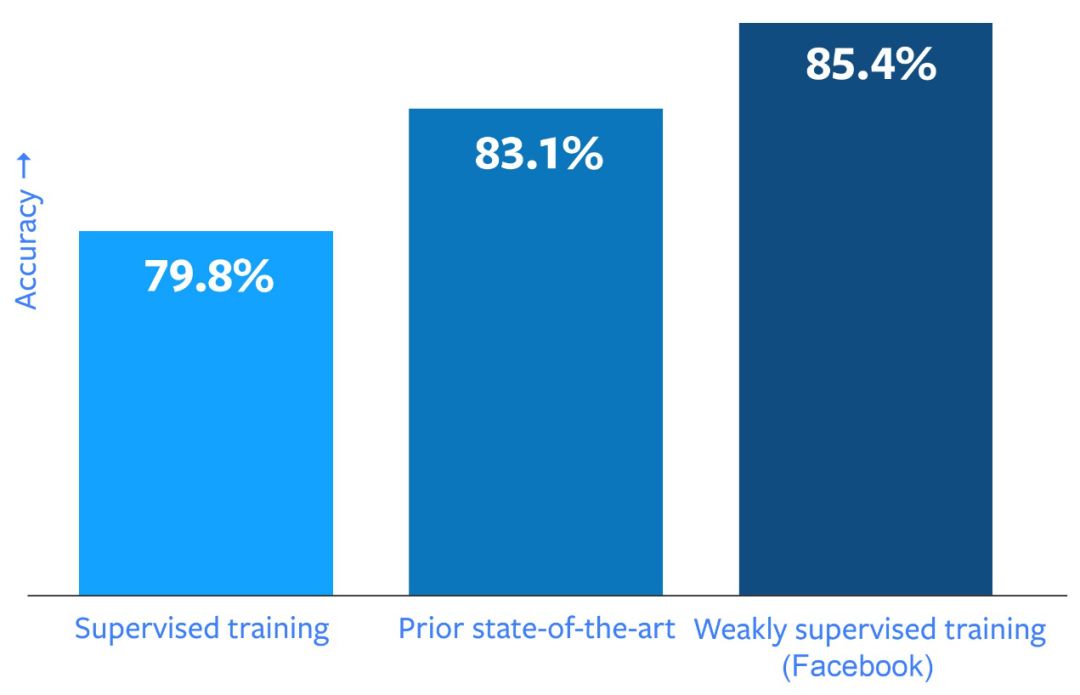
近日,FAIR(Facebook AI Research) 的 Ross Girshick 、何愷明等大神聯手,在 ImageNet-1k 圖像分類數據集上取得了 85.4% 的準確率,超越了目前的最好成績,而且沒有使用專門為訓練深度學習標記的圖像作為訓練數據。

然而,這不能怪大家不努力,只怪 Facebook 實在太土豪。10 億張帶有 hashtag(類似于微博里面的話題標簽)的圖片,以及 336 塊 GPU,敢問誰能有這種壕氣?
Facebook 表示,實驗的成功證明了弱監督學習也能有良好表現,當然,只要數據足夠多。
話不多說,我們一起來看看 Facebook 是怎樣用數據和金錢砸出這個成果的。
以下內容來自 Facebook 官方博客,人工智能頭條 編譯:
圖像識別是人工智能研究的重要領域之一,同時也是 Facebook 的一大重點關注領域。我們的研究人員和工程師希望盡最大的努力打破計算機視覺系統的邊界,然后將我們的研究成功應用到現實世界的問題中。為了改進計算機視覺系統的性能,使其能夠高效地識別和分類各種物體,我們需要擁有至少數十億張圖像的數據集來作為基礎,而不僅僅是百萬量級。
目前比較主流的模型通常是利用人工注釋的單獨標記的數據進行訓練,然而在這種情況下,增強系統的識別能力并不是往里面“扔”更多的圖片那樣簡單。監督學習是勞動密集型的,但是它通常能夠達到最佳的效果,然而手動標記數據集的大小已經接近極限。盡管 Facebook 正在利用 5000 萬幅圖像對一些模型進行訓練,然而在數據全部需要人工標記的前提下,將訓練集擴大到數十億張是不可能實現。
我們的研究人員和工程師想出了一個解決辦法:利用大量帶有“hashtag”的公共圖像集來訓練圖像識別網絡,其中最大的數據集包括 35 億張圖像以及 17000 種 hashtag。這種方法的關鍵是使用現有的、公開的、用戶提供的 hashtag 作為標簽,而不是手動對每張圖片進行分類。
這種方法在我們的測試中運行十分良好。我們利用具有數十億張圖像的數據集來訓練我們的計算機視覺系統,然后在 ImageNet 上獲得了創紀錄的高分(準確率達到了 85.4%)。除了在圖像識別性能方面實現突破之外,本研究還為如何從監督學習轉向弱監督學習轉變提供了深刻的洞見:通過使用現有標簽——在本文這種情況下指的是 hashtag——而不是專門的標簽來訓練 AI 模型。我們計劃在不久的將來會進行開源,讓整個 AI 社區受益。
▌大規模使用 hashtag
由于人們經常用 hashtag 來對照片進行標注,因此我們認為這些圖片是模型訓練數據的理想來源。人們在使用 hashtag 的主要目的是讓其他人發現相關內容,讓自己的圖片更容易被找到,這種意圖正好可以為我們所用。
但是 hashtag 經常涉及非可視化的概念,例如 “#tbt” 代表“throwback Thursday”;有些時候,它們的語義也含糊不清,比如 “#party”,它既可以描述一個活動,也可以描述一個背景,或者兩者皆可。為了更好地識別圖像,這些標簽可以作為弱監督數據,而模糊的或者不相關的 hashtag 則是不相干的標簽噪聲,可能會混淆深度學習模型。
由于這些充滿噪聲的標簽對我們的大規模訓練工作至關重要,我們開發了新的方法:把 hashtag 當作標簽來進行圖像識別實驗,其中包括處理每張圖像的多個標簽(因為用戶往往不會只添加一個 hashtag),對 hashtag 同義詞進行排序,以及平衡常見的 hashtag 和少見的 hashtag 的影響。
為了使標簽對圖像識別訓練更加有用,我們團隊訓練了一個大型的 hashtag 預測模型。這種方法顯示了出色的遷移學習結果,這意味著該模型在圖像分類上的表現可以廣泛適用于其他人工智能系統。
▌在規模和性能上實現突破
如果只是用一臺機器的話,將需要一年多的時間才能完成模型訓練,因此我們設計了一種可以將該任務分配給 336 個 GPU 的方法,從而將總訓練時間縮短至數周。隨著模型規模越來越大——這項研究中最大的是 ResNeXt 101-32x48d,其參數超過了 8.61 億個——這種分布式訓練變得越來越重要。此外,我們還設計了一種刪除重復值(副本)的方法,以確保訓練集和測試集之間沒有重疊。
盡管我們希望看到圖像識別的性能得到一定提升,但試驗結果遠超我們的預期。在 ImageNet 圖像識別基準測試中(該領域最常見的基準測試),我們的最佳模型通過 10 億張圖像的訓練之后(其中包含 1,500 個 hashtag)達到了 85.4% 的準確率,這是迄今為止 ImageNet 基準測試中的最好成績,比之前最先進的模型的準確度高了 2%。再考慮到卷積網絡架構的影響后,我們所觀察到的性能提升效果更為顯著:在深度學習粒使用數十億張帶有 hashtag 的圖像之后,其準確度相對提高了 22.5%。
在 COCO 目標檢測挑戰中,我們發現使用 hashtag 預訓練可以將模型的平均精度(average precision)提高 2% 以上。
這些圖像識別和物體檢測領域的基礎改進,代表了計算機視覺又向前邁出了一步。但是除此之外,該實驗也揭示了與大規模訓練和噪聲標簽相關的挑戰和機遇。
例如,盡管增加訓練數據集規模的大小是值得的,但選擇與特定識別任務相匹配的一組 hashtag 也同樣重要。我們選擇了 10 億張圖像以及 1,500 個與 ImageNet 數據集中的類相匹配的 hashtag,相比同樣的圖像加上 17,000 個 hashtag,前者訓練出來的模型取得了更好的成績。另一方面,對于圖像類別更多更廣泛的任務,使用 17,000 個主 hashtag 訓練出來模型性能改進的更加明顯,這表明我們應該在未來的訓練中增加 hashtag 的數量。
增加訓練數據量通常對圖像分類模型的表現是有益,但它同樣也有可能會引發新的問題,如在圖像內定位物體的能力明顯下降。除此之外我們還觀察到,實驗中最大的模型仍然沒有能夠充分利用 35 億張巨大圖像集的優勢,這表明我們應該構建更大的模型。
▌未來的圖像識別:更大規模、自我標注
本次研究的一個重要結果,甚至比在圖像識別方面的廣泛收益還要重要,是確認了基于 hashtag 來訓練計算機視覺模型是完全可行的。雖然我們使用了一些類似融合相似的 hashtag,降低其他 hashtag 權重的基本技術,但并不需要復雜的“清洗”程序來消除標簽噪聲。相反,我們能夠使用 hashtag 來訓練我們的模型,而且只需要對訓練過程進行微小的調整。當訓練集的規模達到十億級時,我們的模型對標簽噪音表現出了顯著的抗干擾能力,因此數據集的規模在這里顯然是一個優勢。
在不久的將來,我們還會設想使用 hashtag 作為計算機視覺標簽的其他方法。這些方法可能包括使用人工智能來更好地理解視頻片段或更改圖片在 Facebook 信息流中的排名方式。hashtag 還可以幫助系統更具體地識別圖像是不是屬于更細致的子類別,而不僅僅是寬泛的分類。一般情況下,圖片的音頻字幕都是僅寬泛地注釋出物種名稱,如“圖片中有一些鳥類棲息”,但如果我們能夠讓注釋更加精確(例如“一只紅雀棲息在糖楓樹上”),就可以為視障用戶提供更加準確的描述。

此外,這項研究還可以改進新產品以及現有產品中的圖像識別功能帶來。例如,更準確的模型可能會促進我們改進在 Facebook 上呈現 Memories(與QQ的“日跡”相似)的方式。隨著訓練數據集越來越大,我們需要應用弱監督學習——而且從長遠來看,無監督學習會變得越來越重要。
這項研究在論文“Exploring the Limits of Weakly Supervised Pretraining”中有更詳細的描述。
-
圖像識別
+關注
關注
9文章
526瀏覽量
39098 -
人工智能
+關注
關注
1806文章
48996瀏覽量
249246 -
深度學習
+關注
關注
73文章
5561瀏覽量
122780
原文標題:何愷明等在圖像識別任務上取得重大進展,這次用的是弱監督學習
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于DSP的快速紙幣圖像識別技術研究
利用Jetson TK1為低功耗圖像識別挑戰做好準備
圖像識別技術 推動智能科技時代發展
Food2K:大規模食品圖像識別

圖像識別技術原理 深度學習的圖像識別應用研究
模擬矩陣在圖像識別中的應用






 工商網監
工商網監
評論