 TI Edge AI - AM6xA 處理器與深度學習加速器及其效率
TI Edge AI - AM6xA 處理器與深度學習加速器及其效率

TI 處理器與深度學習加速器
[TI]的AM6xA(如[AM68Ax]和[AM69Ax])邊緣AI處理器采用異構架構,帶有用于深度學習計算的專用加速器。這個加速器被稱為MMA -矩陣乘法加速器。該MMA與TI自己的C7x數字信號處理器一起,可以進行高效的張量,矢量和標量處理。加速器是獨立的深度學習處理,不依賴于主機ARM CPU。由于模型計算有大量的數據傳輸,加速器有自己的DMA引擎和內存子系統,與SoC的其余部分連接到相同的DDR。這與專有的Super-tiling技術一起,導致高達90%的加速器引擎利用率和DDR帶寬驅動盡可能低的功耗,以實現節能計算。
*附件:am68a 數據手冊.pdf
*附件:am69a數據手冊.pdf
 image586×586 85.1 KB
image586×586 85.1 KBMMA架構(來源:TI)
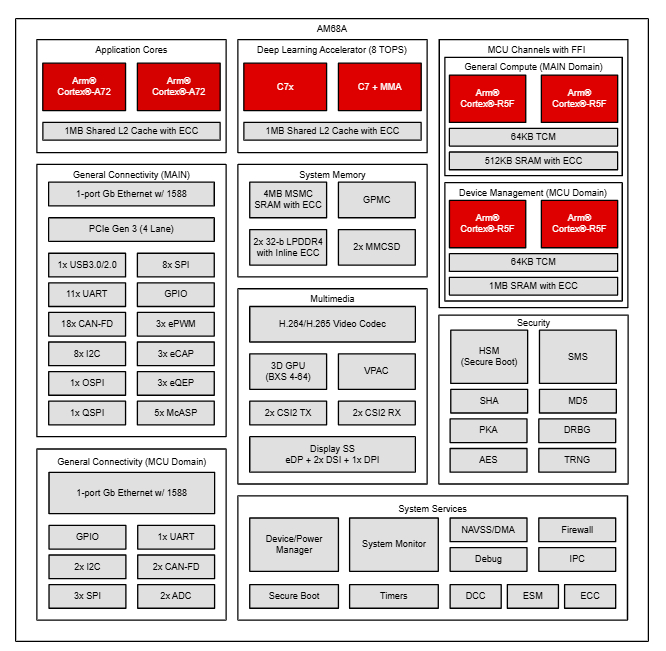
使用MMA作為AI功能的加速,整體SoC框圖如下圖所示。產品組合中的每個邊緣AI設備(如AM62A、AM68A等)的架構都是相似的。
 image865×320 68.2 KB
image865×320 68.2 KBAM6xA處理器框圖(來源:TI)
基于異構架構,片上系統(SoC)經過優化,可在多核Cortex-A微處理單元(mpu)上輕松編程,同時集成深度學習、成像、視覺、視頻和圖形處理等計算密集型任務。任務被卸載到專用硬件加速器和可編程核心上。使用高帶寬互連和智能存儲器架構對這些核心進行整體系統級集成,可實現高吞吐量和能源效率。通過系統組件的預集成實現優化的系統BOM。請注意,像AM62A這樣的成本和功耗優化的SoC并不包括所有硬件功能,例如GPU和DMPAC,或者可能包括性能降低的加速器變體以降低功耗。
深度學習效率
通常,TOPS(每秒tera次操作)用于衡量深度學習的性能比較。TOPS不能完全涵蓋深度學習性能的所有方面,因為它還依賴于內存(DDR)容量和神經網絡架構。
實際的推理時間取決于系統架構利用系統中最優數據流的效率。因此,更好的性能基準是給定模型在給定輸入圖像分辨率下的推理時間。更快的推理時間允許處理更多的圖像,從而產生更高的每秒幀數(FPS)。因此,FPS除以TOPS (FPS/TOPS)顯示了建筑的效率。同樣,FPS/瓦特是嵌入式處理器能源效率的一個很好的基準。
特性
處理器內核:
- 高達雙 64 位 Arm Cortex-A72 微處理器子系統,頻率高達 2GHz
- 每個雙核 Cortex-A72 群集 1MB 共享 L2 緩存
- 每個 Cortex-A72 內核 32KB L1 D-Cache 和 48KB L1 I-Cache
- 深度學習加速器:
- 高達 8 萬億次每秒作 (TOPS)
- 帶有圖像信號處理器 (ISP) 和多個視覺輔助加速器的視覺處理加速器 (VPAC)
- 雙核 Arm Cortex-R5F MCU,在通用計算分區中高達 1.0GHz,帶 FFI
- 16KB L1 D-Cache、16KB L1 I-Cache 和 64KB L2 TCM
- 雙核 Arm? Cortex-R5F? MCU,頻率高達 1.0 GHz,支持設備管理
- 32K L1 D-Cache、32K I-Cache 和 64K L2 TCM,所有內存均支持 SECDED ECC
- 帶有圖像信號處理器 (ISP) 和多個視覺輔助加速器的視覺處理加速器 (VPAC)
- 480 MPixel/s 圖像處理器
- 支持高達 16 位的輸入 RAW 格式
- 寬動態范圍 (WDR)、鏡頭畸變校正 (LDC)、視覺成像子系統 (VISS) 和多標量 (MSC) 支持
- 輸出顏色格式 : 8 位、12 位和 YUV 4:2:2、YUV 4:2:0、RGB、HSV/HSL
多媒體:
- 顯示子系統支持:
- 3D 圖形處理單元
- IMG BXS-4-64,高達 800MHz
- 50GFLOPS,4GTexels/秒
500MTexels/s,>8GFLOPs
- 支持至少 2 個合成圖層
- 最高支持 2048x1080 @60fps
- 支持 ARGB32、RGB565 和 YUV 格式
- 支持 2D 圖形
- OpenGL ES 3.1、Vulkan 1.2
- 兩個 CSI2.0 4L 攝像機串行接口 (CSI-Rx) 加上帶 DPHY 的 CSI2.- 4L Tx (CSI-Tx)
- 視頻編碼器/解碼器
- 支持 5.1 級高級的 HEVC (H.265) 主要配置文件
- 支持 5.2 級 H.264 BaseLine/Main/High 配置文件
- 支持高達 4K UHD 分辨率 (3840 × 2160)
- 4K60 H.264/H.265 編碼/解碼(高達 480MP/s)
內存子系統:
- 高達 4MB 的片上 L3 RAM,具有 ECC 和一致性
- ECC 錯誤保護
- 共享一致性緩存
- 支持內部 DMA 引擎
- 最多兩個帶 ECC 的外部內存接口 (EMIF) 模塊
- 支持 LPDDR4 內存類型
- 支持高達 4266MT/s 的速度
- 多達 2 個 32 位數據總線,每個 EMIF 具有高達 17GB/s 的內聯 ECC
- 通用內存控制器 (GPMC)
- 在 MAIN 域中最多兩個 512KB 片上 SRAM,受 ECC 保護
設備安全性:
- 具有安全運行時支持的安全啟動
- 客戶可編程根密鑰,最高 RSA-4K 或 ECC-512
- 嵌入式硬件安全模塊
- 加密硬件加速器 – 具有 ECC、AES、SHA、RNG、DES 和 3DES 的 PKA
高速串行接口:
- 一個 PCI-Express (PCIe) Gen3 控制器
- 每個控制器最多 4 個通道
- 第 1 代 (2.5GT/s)、第 2 代 (5.0GT/s) 和第 3 代 (8.0GT/s)作,具有自動協商功能
- 一個 USB 3.0 雙角色設備 (DRD) 子系統
- 兩個 CSI2.0 4L 攝像機串行接口 RX (CSI-RX) 和兩個帶 DPHY 的 CSI2.0 4L TX (CSI-TX)
- 符合 MIPI CSI 1.3 標準 + MIPI-DPHY 1.2
- CSI-RX 支持 1、2、3 或 4 數據通道模式,每通道高達 2.5Gbps
- CSI-TX 支持 1、2 或 4 數據通道模式,每通道高達 2.5Gbps
以太網:
- 兩個以太網 RMII/RGMII 接口
閃存接口:
- 嵌入式多媒體卡接口 (eMMC? 5.1)
- 1 個安全數字 3.0/安全數字輸入輸出 3.0 接口 (SD3.0/SDIO3.0)
- 兩個同步閃存接口配置為
- 一個 OSPI 或 HyperBus? 或 QSPI,以及
- 一個 QSPI
技術/封裝:
- 16nm FinFET 技術
- 23mm x 23mm、0.8mm 間距、770 引腳 FCBGA (ALZ)
技術文檔
=TI 選擇的此產品的熱門文檔
-
處理器
+關注
關注
68文章
19874瀏覽量
234747 -
加速器
+關注
關注
2文章
827瀏覽量
39067 -
AI
+關注
關注
88文章
34964瀏覽量
278500 -
深度學習
+關注
關注
73文章
5560瀏覽量
122738
發布評論請先 登錄
TPU處理器的特性和工作原理
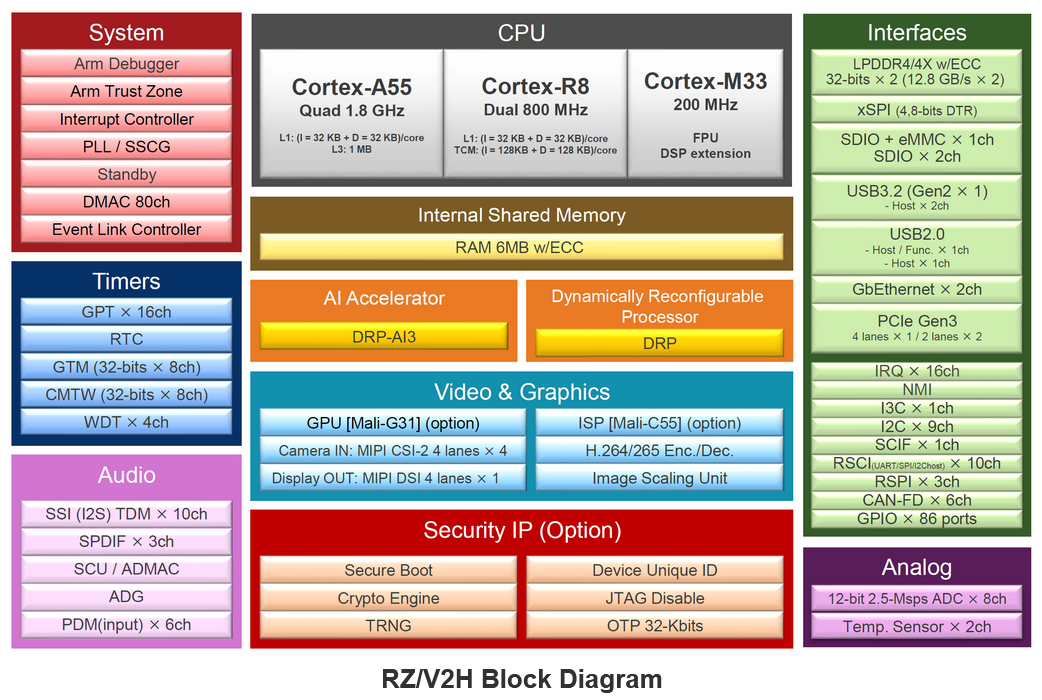
AI MPU# 瑞薩RZ/V2H 四核視覺 ,采用 DRP-AI3 加速器和高性能實時處理器
端側 AI 音頻處理器:集成音頻處理與 AI 計算能力的創新芯片

使用TI Edge AI Studio和AM62A進行基于視覺AI的缺陷檢測

AM6442、AM6422、AM6412和AM2434處理器的硬件設計指南
AM3874 AM3872 AM3871 Sitara ARM微處理器數據表
什么是神經網絡加速器?它有哪些特點?
GPMC并口多通道AD采集案例,基于TI AM62x四核處理器平臺!





 工商網監
工商網監
評論