 NVIDIA全棧加速代理式AI應用落地
NVIDIA全棧加速代理式AI應用落地

在近期舉辦的 AWS 中國峰會上,NVIDIA 聚焦于“NVIDIA 全棧加速代理式 AI 應用落地”,深入探討了代理式 AI (Agentic AI) 技術的前沿發展以及在企業級應用中的深遠影響。本文將為您詳細介紹此次分享的技術亮點及實踐應用。
AI Agent 技術發展現狀
隨著人工智能技術的不斷演進,從感知式 AI 到生成式 AI,再到代理式 AI,我們正見證全新工作方式的誕生。代理式 AI 不僅使更強大的 AI 應用成為可能,而且正迅速成為解決特定業務問題的關鍵工具。數據顯示,到 2025 年,約有一半的組織將使用 AI智能體(AI Agent) 幫助解決特定業務問題。隨著技術發展,每個人都可以創建自己的 AI Agent。一些工作流可使周期時間縮短 40%。根據 Gartner 報告,到 2028 年,約三分之一的企業級軟件開發將引入 AI Agent,而 2024 年這一數字不到 1%,可見相關方面發展迅速。
AI Agent 工作原理與架構
AI Agent 的運行需要人類撰寫 prompt,設定角色、場景、任務及需要 AI 執行的操作,并告知整體信息。之后,大語言模型自行生成計劃,確定工具,甚至協同調動其他 Agent。經過一系列分析和生成后,需通過批判總結決定 Agent 是繼續迭代還是返回結果給用戶。
首先,Agent 需持續學習和迭代。通過建立飛輪系統,讓模型在實際應用中學習,反哺模型迭代,提高模型魯棒性和適應性。其次,作為企業級應用,安全性和隱私保護至關重要。需保證結果可靠性,盡量避免大語言模型幻覺。同時,人機或用戶與 AI 的交互應盡可能友好,以發揮最佳效果。
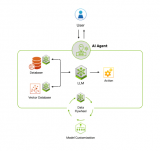
AI Agent 技術框架與實現
一、AI Agent 構建模塊
構建 AI Agent,有三個重要組成部分,從下往上看:
NVIDIANIM是預構建的容器工具,使用非常簡單,只需幾分鐘即可部署企業級安全穩定的大語言模型推理服務。通過 docker 拉取一個 docker 鏡像,完成下載模型等前置工作后,就可以通過一個 Open AI API 或其他行業標準的 API 格式來調用,從而得到一個線上生產環境可用的、安全穩定的大語言模型推理服務。NIM 集成了優化的推理引擎,如 TensorRT-LLM、vLLM 等,這些推理引擎可以幫助優化首 token 延遲、吞吐等指標,在 TCO 可控的情況下,盡量提高吞吐和整體細分表現。此外 NIM 可以在任意地點便捷部署和擴展,包括數據中心、工作站,甚至云上或邊緣(如公有云、混合云、私有云等)。NVIDIA 也與國內外的云廠商進行集成,如亞馬遜云科技等,可在云上快速使用產品。
NVIDIA NeMo是一套數據飛輪框架,涵蓋模型訓練和應用的多個模塊。通過該數據飛輪,我們可以持續優化迭代模型和應用。
與 AI Agent 最為緊密的是NVIDIA AI Blueprint,它是我們提供的工作流,可向開發者展示如何快速構建安全的、企業級應用。NVIDIA AI Blueprint 涵蓋 PDF 轉音頻、視頻搜索與總結等多模態模型和工具,可以通過“搭積木”的方式,將多個 Blueprint 模塊化的組成一個工作流來解決復雜問題。同時也可以調用外部工具,使整個應用場景或覆蓋面更加全面。典型應用包括 AI 研究助理 Agent、客服機器人、安全 AI Agent 等,均作為參考,用戶可通過 NeMo 構建符合應用場景的內容。
二、生成式 AI 數據飛輪:
數據飛輪是一種反饋循環機制,通過從交互或流程中收集數據,持續優化 AI 模型,進而產生更優的結果和更有價值的數據。
NVIDIA NeMo 是一個生成式 AI 的框架,其中:
NeMo Curator:在模型預訓練階段需獲取大量數據集,但是從網上獲取的海量數據集質量往往參差不齊。需要進行質量篩選和去重等步驟。通過集成的 GPU 加速模塊,對于十分耗時的質量檢測、去重等步驟,可以通過 NeMo Curator 快速實現。
NeMo Customizer:模型數據收集完成后,可通過 NeMo Customizer 開始模型訓練或微調。
NeMo Evaluator:模型訓練好后,由 NeMo Evaluator 評估其質量,判斷其是否符合預期、滿足業務需求。
訓練好的模型上線部署后,我們將其構建成更復雜的工作流,將單個 NIM 和其他工具總結成 Blueprint,以服務我們的業務場景。
在 RAG(檢索增強生成)或 Agent 過程中,向量檢索是一個十分重要的技術模塊。NVIDIA cuVS集成了 GPU 加速的 ANN (Approximate Nearest Neighbors) 算法,可以提高向量檢索的效率。作為企業級應用,安全性和隱私保護至關重要,NVIDIA Guardrails作為 AI 護欄,可以檢測生成過程中比較危險或不太友好的內容,使線上服務更加安全可靠。
經過上述鏈路,最后線上驗證過的數據通過回路回到數據集,這部分數據再經過 NeMo Customizer 進行訓練微調,就完成了數據閉環。通過這樣一步一步的迭代,線上數據反哺回模型訓練。
三、面向企業應用的大語言模型定制
我們的模型能力不斷增強,使得線上服務效果更加安全可靠。Customizer 涵蓋的能力多元,從最初的簡單微調、復雜的 sft,到現在常用的強化學習方法。我們還可根據企業特定場景進行相應微調。
以 DeepSeek-V3 訓練為例,Transformer Engine 集成了類似 DeepSeek-V3 的 FP8 block wise 算子和 recipe。在 Megatron-Core 層面,基于 DeepSeek-V3 特定架構,支持了 MLA 結構。同時,對 MTP 也有較好支持,還有負載均衡和路由策略。除了支持外,還有相關優化。
DeepSeek-V3 使用 DualPipe 流水線并行策略,Megatron-Core 中也有類似策略,稱為 1F1B (F: Forward, B: Backward)。通過 1F1B 的流水線機制,很好地將 MoE 計算與通信進行 overlap,減小訓練延遲,提高訓練效率。
同時,對于 DeepSeek 開源的內容,我們也有較好集成。在并行方面,Megatron-Core 擅長并行,我們做了 MoE parallel folding。這是指在一個模型里既有 Attention 層,也有 MoE 層,我們針對不同層進行處理。可以使用 parallel folding 方法,將其并行策略解耦,即 Attention 部分和 MoE 層分別采用不同的并行策略,以達到整體更好的效率。NeMo,即更面向用戶的層面,除了支持 DeepSeek 的 sft,同時也支持把 DeepSeek-R1 蒸餾到小模型。
四、加速推理的優化技術
如今模型越來越大,參數達到千億級,需要更強的推理算力。同時,這些模型都是推理模型,邏輯推理需要更多的思考時間,甚至需要超過 100 倍的思考 token。此外,我們的模型現在也支持更長的上下文窗口,在使用過程中,無論是對話系統中的多輪對話,還是 Agent 使用過程中的 Agent-to-Agent、human-to-Agent 等交互手段,都會使上下文 context 變得更長,甚至達到百萬級輸入 token 以上,這些都對計算推理提出了更多的挑戰,也推動著新型優化技術的誕生。
1. 分離式部署 (PD 分離):
大語言模型的推理分為兩個階段。第一個是預填充 (Prefill) 階段,這是一個計算密集 (Compute-Bound) 階段,需要較多算力。第二個是解碼 (Decode) 階段,在這個階段,隨著吐出的 token 越來越多,它進入了一個內存密集 (Memory-Bound) 階段。為了更好地利用預填充和解碼的相關特性來優化首 token 延遲和吞吐,分離式部署是比較適應大語言模型推理場景的部署技術。將預填充和解碼兩個階段分開,結合其計算特點,分配適合其特定型號的 GPU,并針對不同特性制定不同策略,結合線上 SLA 服務標準,分配不同數量的節點,以優化首 token 延遲和吞吐。
2. NVIDIA Dynamo:
NVIDIA Dynamo是針對分離式部署或大規模分布式部署的框架,具備以下特點:
分布式部署:支持便捷地擴充至上千卡 GPU 的線上部署。
GPU 管理及調度(GPU 規劃器):可根據線上實時請求變化或 SLA 服務標準動態調整預填充節點或解碼節點的數量,以更好地滿足服務需求。
智能路由:在多個節點的情況下,可以結合 KV Cache 等指標,將 decode 任務分配給最佳節點。
典型應用場景案例
一、AI 研究助理 Agent
AI 研究助理 Agent 執行 PDF 轉音頻的任務。將論文、博客等文檔輸入到模型中,通過工具轉換為 markdown 文件。在此過程中,需要為 Agent 提供復雜的 prompt。首先,按照要求整理出文件大綱,然后根據大綱將腳本分段,進行深入探索并總結有思考性的內容。然后,對整體腳本進行優化,并將多個部分組合輸出整理成結構化文本。在這個過程中,人類需要做的是梳理出多個 prompt,并在多個階段調用不同尺寸的模型來處理不同任務。文檔輸入時內容龐雜,使用尺寸更大的模型來處理復雜任務。總結時可使用尺寸更小的模型來提高工作流的經濟效益。通過這一系列步驟后,輸出文本再通過類似 ElevenLabs 的 TTS 服務或 TTS 模型合成為音頻文件,返回給用戶。
二、軟件安全檢測 Agent
隨著 CVE.org 記錄的漏洞突破 20 萬大關,軟件安全補丁管理面臨嚴峻挑戰。傳統人工分析、日常掃描漏洞需耗時數日,而基于事件驅動 RAG 技術的軟件安全檢測 Agent 可將緩解時間壓縮至秒級,通過實時檢測新軟件包或漏洞特征,智能判定組件風險,并自主執行全流程檢查清單,最終向安全團隊提交包含可操作建議的分析報告。
三、視頻分析 Agent
用于視頻搜索和總結的 Agent 每天可分析 10 萬 PB 級的視頻數據。該 Agent 使用NVIDIA Cosmos Nemotron的視覺語言模型,可以從視頻數據中提取文本信息,再通過NeMo Retriever Embedding抽取為 embedding,形成向量數據庫。同時,并行流程通過分析從視頻中提取的信息構建圖數據庫。當有新視頻輸入時,就可通過召回鏈路查詢上述數據庫,再通過大模型進行總結生成,完成整個視頻分析鏈路。
總結
從 AI 研究助理、軟件安全檢測到大規模視頻分析,這些應用場景正切實推動代理式 AI 落地,在解決復雜業務問題、提升工作效率方面發揮關鍵作用。NVIDIA 通過全棧解決方案和工具,助力企業構建安全、穩定、高效的代理式 AI 應用。
-
NVIDIA
+關注
關注
14文章
5308瀏覽量
106344 -
AI
+關注
關注
88文章
35093瀏覽量
279522 -
人工智能
+關注
關注
1806文章
49008瀏覽量
249305 -
AWS
+關注
關注
0文章
436瀏覽量
25272
原文標題:NVIDIA 全棧加速代理式 AI 應用落地
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA技術助力企業創建主權AI智能體
NVIDIA攜手諾和諾德借助AI加速藥物研發
NVIDIA攜手微軟加速代理式AI發展
NVIDIA攜手谷歌云助力企業引入代理式AI
Cadence 利用 NVIDIA Grace Blackwell 加速AI驅動的工程設計和科學應用
英偉達GTC2025亮點:NVIDIA、Alphabet 和谷歌攜手開啟代理式與物理AI的未來

英偉達GTC2025亮點:Oracle與NVIDIA合作助力企業加速代理式AI推理

Oracle 與 NVIDIA 合作助力企業加速代理式 AI 推理

NVIDIA Blackwell RTX PRO 提供工作站和服務器兩種規格,助力設計師、開發者、數據科學家和創作人員構建代理式

NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺






 工商網監
工商網監
評論