 重新思考 AI 時代的分布式計算
重新思考 AI 時代的分布式計算

DeepSeek的崛起,不僅因其巨大成就,更因其高效性而在AI行業引起了震動。雖然大家的關注重點大都放在DeepSeek僅花費了560萬美元的訓練成本,而OpenAI花費超過1億美元,但其中更深層次的關注點在于這一效率突破揭示了傳統分布式計算范式與AI工作負載獨特需求之間的根本不匹配。
AI技術浪潮對基礎設施選型帶來了深層挑戰:當前廣泛部署的分布式計算架構本質上仍是為解決20世紀的大規模數據處理問題而設計,卻承擔著運行21世紀AI工作負載的重任。DeepSeek的突破性實踐揭示了一個關鍵命題——業界需要從根本上重新思考如何實現AI的分布式計算,其影響將遠遠超出訓練成本的范疇。
分布式計算與AI發展不匹配
傳統的分布式計算是基于一些假設而設計的,而這些假設在人工智能時代已不復存在。不妨想想經典的 MapReduce 范式,它徹底改變了大數據處理:它擅長處理高度并行的問題,即數據可以清晰地分區,并且計算在很大程度上是獨立的。然而,Transformer 架構展現出了截然不同的計算模式。
Transformer 訓練在注意力計算過程中涉及密集的、all-to-all的通信模式。每個 token 都可能關注其他所有 token,從而產生隨序列長度平方增長的通信需求。這與傳統分布式系統處理良好的稀疏、分層通信模式截然相反。注意力機制的全局依賴性意味著,在傳統分布式工作負載中行之有效的“分而治之”策略在AI中變得適得其反。
再看內存訪問模式,問題更為嚴重。傳統的分布式計算假設計算可以與數據共存,從而最大限度地減少網絡流量——這是自集群計算早期以來一直指導系統設計的原則。但Transformer 架構需要在海量參數空間(有時甚至高達數千億個參數)中頻繁同步梯度更新。由此產生的通信開銷可能會占據總訓練時間的大部分,這也解釋了為什么增加更多 GPU 往往會帶來的收益遞減,而非設計良好的分布式系統所預期的線性擴展。
DeepSeek 效率革命的經驗教訓
DeepSeek 的成就不僅在于其巧妙的算法,更在于其架構選擇能夠更好地契合 AI 工作負載的特性。其混合專家 (MoE) 方法通過使計算再次稀疏化,從根本上改變了分布式計算方程。MoE 架構并非要求每個 GPU 都處理所有參數,而是在每次計算中僅激活模型的子集,從而顯著降低了通信需求。
更有趣的是,DeepSeek 強調“蒸餾”和強化學習,而非傳統的監督微調,這表明它正在轉向更高效的通信訓練范式。與監督學習相比,基于獎勵的強化學習可以比需要跨所有節點緊密同步標記訓練數據的監督學習更自然地分布。但更深層次的教訓并非關于具體的技術,而是關于如何將AI工作負載與分布式系統協同設計,而不是強迫AI工作負載適應現有的分布式計算模式。這代表著我們需要從根本上對分布式系統設計思維方式進行轉變。
重新思考分布式人工智能系統:三個核心原則
如果從頭開始為AI工作負載設計分布式計算,會是什么樣子?總的來說可以歸納為以下三個原則:
1. 異步優先設計:傳統參數服務器假設同步更新以保持一致性,這一原則借鑒自數據庫系統,在數據庫系統中,正確性至關重要。但AI訓練本身對某些不一致性具有魯棒性;即使梯度過時,模型也能收斂。采用有限異步可以顯著降低通信開銷,同時保持訓練效率。這不僅僅關乎最終一致性,而是設計能夠容忍并從受控不一致性中受益的系統。
2. 分層通信模式:AI 原生的分布式系統應該利用 Transformer 架構中自然的層級結構,而非扁平的all-to-all通信。層內注意力模式與跨層依賴關系不同,這為多層通信優化提供了機會。我們需要能夠理解這些計算依賴關系并相應地優化通信的分布式系統。
3. 自適應資源分配:與資源需求可預測的傳統工作負載不同,AI 訓練表現出階段依賴性行為。早期訓練側重于學習基本模式,對通信精度的要求低于后期的微調階段。分布式系統應該在整個訓練過程中調整其通信策略和資源分配,而不是將其視為靜態工作負載。
基礎設施投資悖論
業界目前應對 AI 擴展挑戰的措施,例如 Stargate 宣布的 5000 億美元基礎設施投資,基本上都遵循著“大同小異”的策略:更大的 GPU 集群、更快的互連速度、更高的內存帶寬。雖然有必要,但這種策略治標不治本,就像在高速公路上增加車道,卻不解決交通信號燈的配時問題。
如果目前的趨勢持續下去,AI訓練可能會在幾十年內消耗掉全球相當一部分電力。但能源消耗不僅僅取決于操作次數,它很大程度上受到數據移動的影響。在對節能分布式系統的研究過程中可以觀察到,數據移動通常比計算本身消耗的能量高出幾個數量級。更好的分布式計算架構可以最大限度地減少不必要的通信,從而實現大量的能源節約,使AI的發展更具可持續性。
跨層優化:尚未開發的前沿
最有前景的方法涉及跨層優化,而傳統系統在維護抽象邊界時會避免使用這種優化。例如,現代 GPU 支持混合精度計算,但分布式系統很少能夠智能地利用這一能力。梯度更新可能不需要與前向傳播相同的精度,這意味著精度感知通信協議有機會將帶寬需求降低 50% 或更多。
同樣,從谷歌的TPU到新興的神經形態芯片,AI專用硬件的興起也帶來了新的分布式計算挑戰。這些架構通常具有不統一的內存層次結構和專用互連,無法清晰地映射到傳統的分布式計算抽象上。我們需要新的分布式系統設計,能夠利用這些硬件特定的優化,同時保持可移植性。
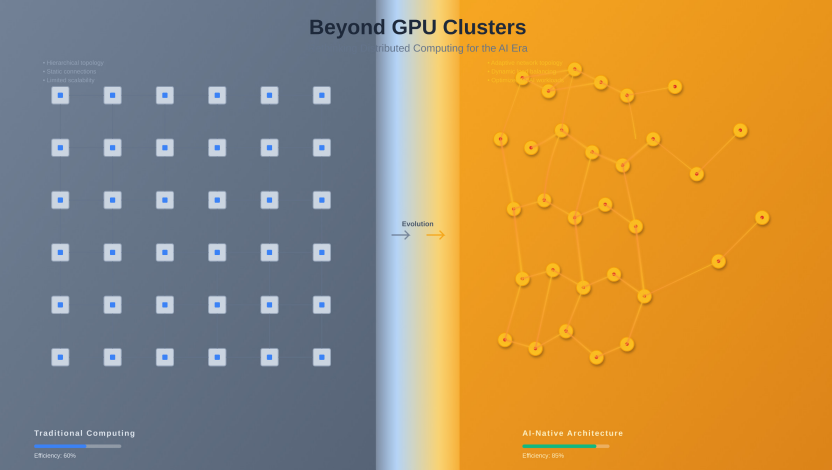
從傳統的基于網格的分布式計算架構(左)到AI原生的流暢互連系統設計(右)的演變。可視化顯示幾何節點從僵化的層級模式演變為針對AI工作負載通信模式優化的自適應、密集連接的類神經架構。
展望:后 GPU 時代
或許最重要的是,我們目前以 GPU 為中心的 AI 基礎設施觀念可能只是暫時的。隨著我們越來越接近摩爾定律和登納德縮放定律的極限,未來很可能屬于專用的異構計算架構。量子-經典混合系統、神經形態處理器和光學計算平臺將需要全新的分布式計算范式。
在這個過渡中成功的組織將不是那些擁有最多GPU的組織,而是那些最理解如何為AI工作負載編排復雜的、異構的分布式系統的組織。DeepSeek的效率突破只是一個開始,它表明,架構創新并非僅僅是原始計算能力,仍然是AI進步的關鍵。
隨著AI行業日趨成熟,超越了當前“投入更多計算”的階段,分布式系統的基本原則——一致性、可用性、分區容錯性和效率,將決定哪些方法能夠持續發展。未來的道路需要我們摒棄對傳統分布式計算模式的執著,擁抱專為 AI 工作負載優化的設計。這不僅僅是一個優化問題,更是對如何為 AI 優先的世界構建分布式系統的根本性反思。
*本文轉自SDNLAB,編譯自 CACM Blog,作者:Akshay Mittal。
原文鏈接:https://cacm.acm.org/blogcacm/rethinking-distributed-computing-for-the-ai-era/
-
AI
+關注
關注
88文章
35476瀏覽量
281205 -
DeepSeek
+關注
關注
2文章
804瀏覽量
1821
發布評論請先 登錄
訊維AI分布式控制系統的核心優勢和應用場景
訊維AI分布式系統的十大優勢
使用VirtualLab Fusion中分布式計算的AR波導測試圖像模擬
VirtualLab Fusion應用:基于分布式計算的AR光波導中測試圖像的仿真
分布式云化數據庫有哪些類型
基于ptp的分布式系統設計
HarmonyOS Next 應用元服務開發-分布式數據對象遷移數據權限與基礎數據

訊維AI分布式無紙化交互系統:突破傳統,引領AI智能會商新革命!

分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進

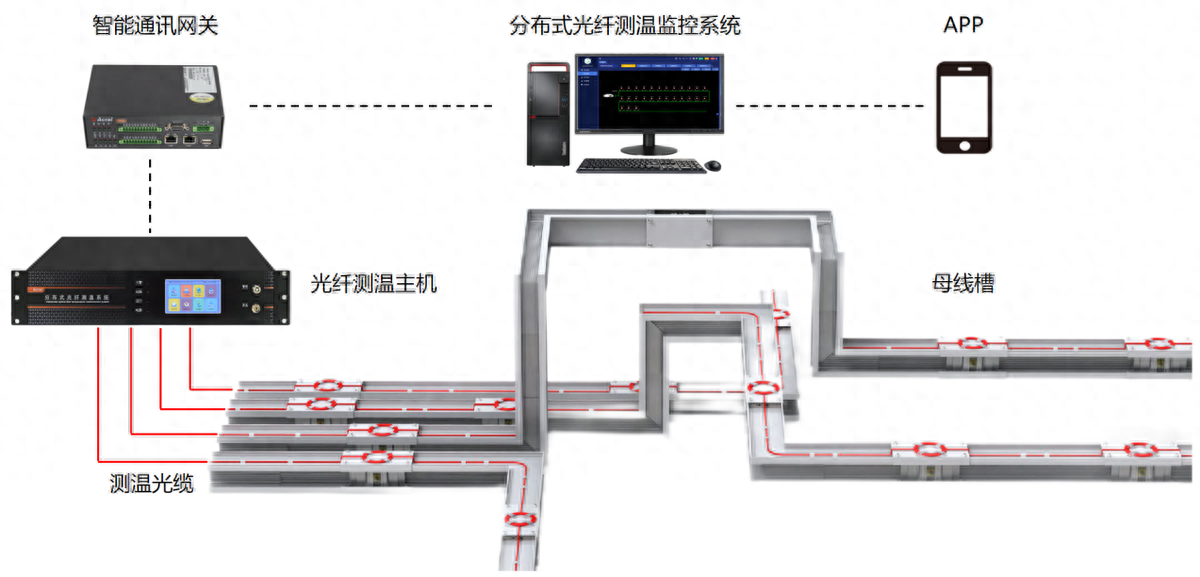
分布式光纖測溫是什么?應用領域是?





 工商網監
工商網監
評論