") 用AlexNet對(duì)cifar-10數(shù)據(jù)進(jìn)行分類
用AlexNet對(duì)cifar-10數(shù)據(jù)進(jìn)行分類
上周我們用PaddlePaddle和Tensorflow實(shí)現(xiàn)了圖像分類,分別用自己手寫(xiě)的一個(gè)簡(jiǎn)單的CNN網(wǎng)絡(luò)simple_cnn和LeNet-5的CNN網(wǎng)絡(luò)識(shí)別cifar-10數(shù)據(jù)集。在上周的實(shí)驗(yàn)表現(xiàn)中,經(jīng)過(guò)200次迭代后的LeNet-5的準(zhǔn)確率為60%左右,這個(gè)結(jié)果差強(qiáng)人意,畢竟是二十年前寫(xiě)的網(wǎng)絡(luò)結(jié)構(gòu),結(jié)果簡(jiǎn)單,層數(shù)也很少,這一節(jié)中我們講講在2012年的Image比賽中大放異彩的AlexNet,并用AlexNet對(duì)cifar-10數(shù)據(jù)進(jìn)行分類,對(duì)比上周的LeNet-5的效果。
什么是AlexNet?
AlexNet在ILSVRC-2012的比賽中獲得top5錯(cuò)誤率15.3%的突破(第二名為26.2%),其原理來(lái)源于2012年Alex的論文《ImageNet Classification with Deep Convolutional Neural Networks》,這篇論文是深度學(xué)習(xí)火爆發(fā)展的一個(gè)里程碑和分水嶺,加上硬件技術(shù)的發(fā)展,深度學(xué)習(xí)還會(huì)繼續(xù)火下去。
AlexNet網(wǎng)絡(luò)結(jié)構(gòu)
由于受限于當(dāng)時(shí)的硬件設(shè)備,AlexNet在GPU粒度都做了設(shè)計(jì),當(dāng)時(shí)的GTX 580只有3G顯存,為了能讓模型在大量數(shù)據(jù)上跑起來(lái),作者使用了兩個(gè)GPU并行,并對(duì)網(wǎng)絡(luò)結(jié)構(gòu)做了切分,如下:
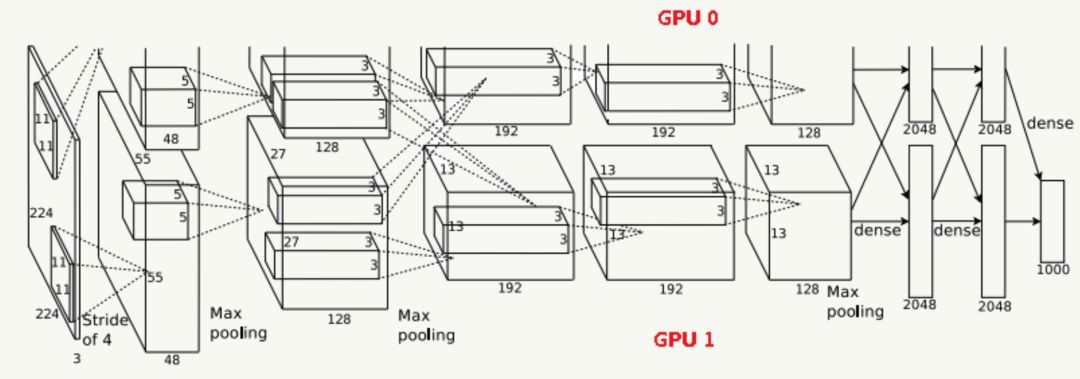
網(wǎng)絡(luò)結(jié)構(gòu)
Input輸入層
輸入為224×224×3的三通道RGB圖像,為方便后續(xù)計(jì)算,實(shí)際操作中通過(guò)padding做預(yù)處理,把圖像變成227×227×3。
C1卷積層
該層由:卷積操作 + Max Pooling + LRN(后面詳細(xì)介紹它)組成。
卷積層:由96個(gè)feature map組成,每個(gè)feature map由11×11卷積核在stride=4下生成,輸出feature map為55×55×48×2,其中55=(227-11)/4+1,48為分在每個(gè)GPU上的feature map數(shù),2為GPU個(gè)數(shù);
激活函數(shù):采用ReLU;
Max Pooling:采用stride=2且核大小為3×3(文中實(shí)驗(yàn)表明采用2×2的非重疊模式的Max Pooling相對(duì)更容易過(guò)擬合,在top 1和top 5下的錯(cuò)誤率分別高0.4%和0.3%),輸出feature map為27×27×48×2,其中27=(55-3)/2+1,48為分在每個(gè)GPU上的feature map數(shù),2為GPU個(gè)數(shù);
LRN:鄰居數(shù)設(shè)置為5做歸一化。
最終輸出數(shù)據(jù)為歸一化后的:27×27×48×2。
C2卷積層
該層由:卷積操作 + Max Pooling + LRN組成
卷積層:由256個(gè)feature map組成,每個(gè)feature map由5×5卷積核在stride=1下生成,為使輸入和卷積輸出大小一致,需要做參數(shù)為2的padding,輸出feature map為27×27×128×2,其中27=(27-5+2×2)/1+1,128為分在每個(gè)GPU上的feature map數(shù),2為GPU個(gè)數(shù);
激活函數(shù):采用ReLU;
Max Pooling:采用stride=2且核大小為3×3,輸出feature map為13×13×128×2,其中13=(27-3)/2+1,128為分在每個(gè)GPU上的feature map數(shù),2為GPU個(gè)數(shù);
LRN:鄰居數(shù)設(shè)置為5做歸一化。
最終輸出數(shù)據(jù)為歸一化后的:13×13×128×2。
C3卷積層
該層由:卷積操作 + LRN組成(注意,沒(méi)有Pooling層)
輸入為13×13×256,因?yàn)檫@一層兩個(gè)GPU會(huì)做通信(途中虛線交叉部分)
卷積層:之后由384個(gè)feature map組成,每個(gè)feature map由3×3卷積核在stride=1下生成,為使輸入和卷積輸出大小一致,需要做參數(shù)為1的padding,輸出feature map為13×13×192×2,其中13=(13-3+2×1)/1+1,192為分在每個(gè)GPU上的feature map數(shù),2為GPU個(gè)數(shù);
激活函數(shù):采用ReLU;
最終輸出數(shù)據(jù)為歸一化后的:13×13×192×2。
C4卷積層
該層由:卷積操作 + LRN組成(注意,沒(méi)有Pooling層)
卷積層:由384個(gè)feature map組成,每個(gè)feature map由3×3卷積核在stride=1下生成,為使輸入和卷積輸出大小一致,需要做參數(shù)為1的padding,輸出feature map為13×13×192×2,其中13=(13-3+2×1)/1+1,192為分在每個(gè)GPU上的feature map數(shù),2為GPU個(gè)數(shù);
激活函數(shù):采用ReLU;
最終輸出數(shù)據(jù)為歸一化后的:13×13×192×2。
C5卷積層
該層由:卷積操作 + Max Pooling組成
卷積層:由256個(gè)feature map組成,每個(gè)feature map由3×3卷積核在stride=1下生成,為使輸入和卷積輸出大小一致,需要做參數(shù)為1的padding,輸出feature map為13×13×128×2,其中13=(13-3+2×1)/1+1,128為分在每個(gè)GPU上的feature map數(shù),2為GPU個(gè)數(shù);
激活函數(shù):采用ReLU;
Max Pooling:采用stride=2且核大小為3×3,輸出feature map為6×6×128×2,其中6=(13-3)/2+1,128為分在每個(gè)GPU上的feature map數(shù),2為GPU個(gè)數(shù).
最終輸出數(shù)據(jù)為歸一化后的:6×6×128×2。
F6全連接層
該層為全連接層 + Dropout
使用4096個(gè)節(jié)點(diǎn);
激活函數(shù):采用ReLU;
采用參數(shù)為0.5的Dropout操作
最終輸出數(shù)據(jù)為4096個(gè)神經(jīng)元節(jié)點(diǎn)。
F7全連接層
該層為全連接層 + Dropout
使用4096個(gè)節(jié)點(diǎn);
激活函數(shù):采用ReLU;
采用參數(shù)為0.5的Dropout操作
最終輸出為4096個(gè)神經(jīng)元節(jié)點(diǎn)。
輸出層
該層為全連接層 + Softmax
使用1000個(gè)輸出的Softmax
最終輸出為1000個(gè)分類。
AlexNet的優(yōu)勢(shì)
1.使用了ReLu激活函數(shù)
----原始Relu-----
AlexNet引入了ReLU激活函數(shù),這個(gè)函數(shù)是神經(jīng)科學(xué)家Dayan、Abott在《Theoretical Neuroscience》一書(shū)中提出的更精確的激活模型。原始的Relu激活函數(shù)(可參見(jiàn) Hinton論文:《Rectified Linear Units Improve Restricted Boltzmann Machines》)我們比較熟悉,即max(0,x)
,這個(gè)激活函數(shù)把負(fù)激活全部清零(模擬上面提到的稀疏性),這種做法在實(shí)踐中即保留了神經(jīng)網(wǎng)絡(luò)的非線性能力,又加快了訓(xùn)練速度。但是這個(gè)函數(shù)也有缺點(diǎn):
在原點(diǎn)不可微反向傳播的梯度計(jì)算中會(huì)帶來(lái)麻煩,所以Charles Dugas等人又提出Softplus來(lái)模擬上述ReLu函數(shù)(可視作其平滑版):
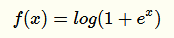
實(shí)際上它的導(dǎo)數(shù)就是一個(gè)
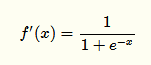
過(guò)稀疏性
當(dāng)學(xué)習(xí)率設(shè)置不合理時(shí),即使是一個(gè)很大的梯度,在經(jīng)過(guò)ReLu單元并更新參數(shù)后該神經(jīng)元可能永不被激活。
----Leaky ReLu----
為了解決上述過(guò)稀疏性導(dǎo)致的大量神經(jīng)元不被激活的問(wèn)題,Leaky ReLu被提了出來(lái):
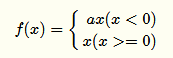
其中α是人工制定的較小值(如:0.1),它一定程度保留了負(fù)激活信息。
還有很多其他的對(duì)于ReLu函數(shù)的改進(jìn),如Parametric ReLu,Randomized ReLu等,此處就不再展開(kāi)講了。
2.Local Response Normalization 局部響應(yīng)均值
LRN利用相鄰feature map做特征顯著化,文中實(shí)驗(yàn)表明可以降低錯(cuò)誤率,公式如下:
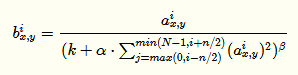
公式的直觀解釋如下:
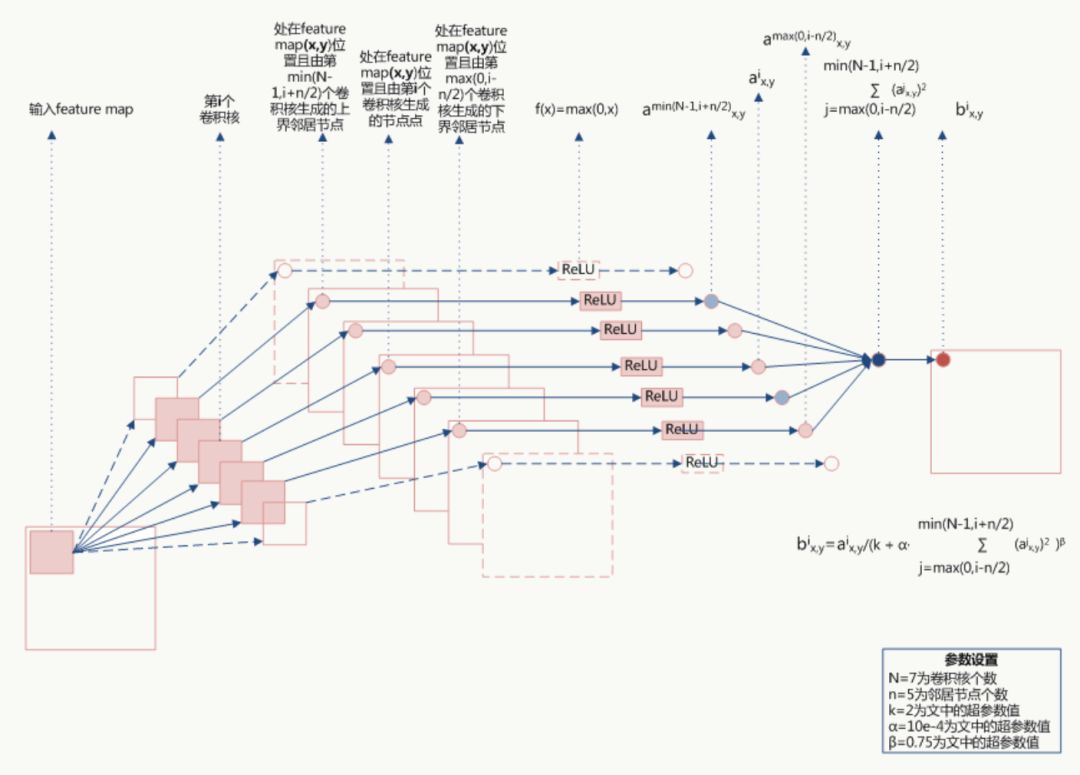
由于α都是經(jīng)過(guò)了RELU的輸出,所以一定是大于0的,函數(shù)
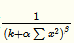
取文中參數(shù)的圖像如下(橫坐標(biāo)為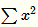 ):
):
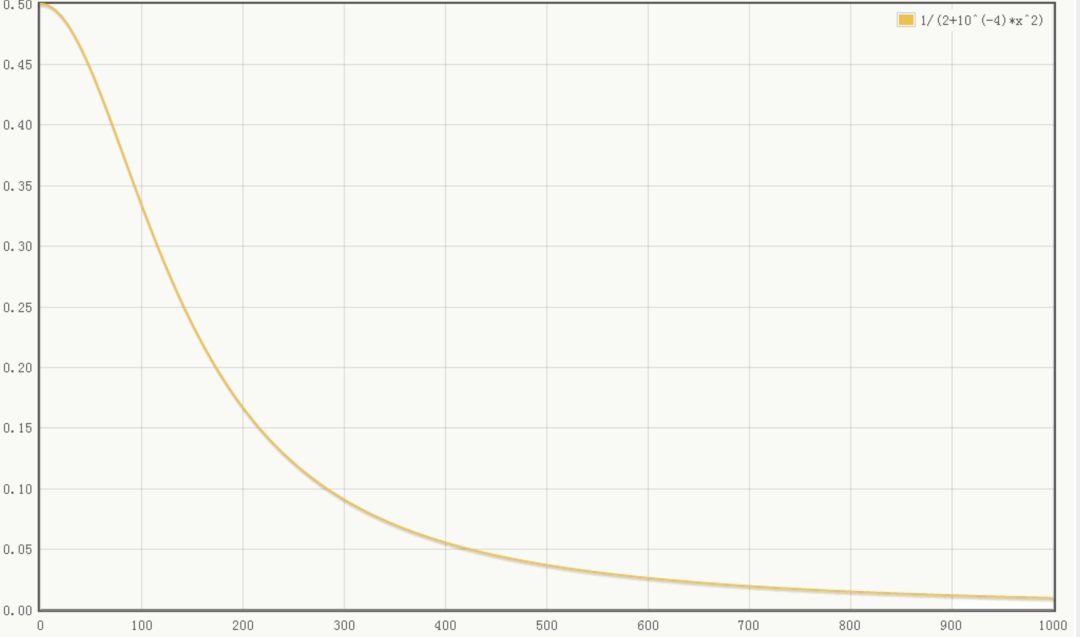
當(dāng)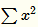 值較小時(shí),即當(dāng)前節(jié)點(diǎn)和其鄰居節(jié)點(diǎn)輸出值差距不明顯且大家的輸出值都不太大,可以認(rèn)為此時(shí)特征間競(jìng)爭(zhēng)激烈,該函數(shù)可以使原本差距不大的輸出產(chǎn)生顯著性差異且此時(shí)函數(shù)輸出不飽和
值較小時(shí),即當(dāng)前節(jié)點(diǎn)和其鄰居節(jié)點(diǎn)輸出值差距不明顯且大家的輸出值都不太大,可以認(rèn)為此時(shí)特征間競(jìng)爭(zhēng)激烈,該函數(shù)可以使原本差距不大的輸出產(chǎn)生顯著性差異且此時(shí)函數(shù)輸出不飽和
當(dāng)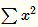 值值較大時(shí),說(shuō)明特征本身有顯著性差別但輸出值太大容易過(guò)擬合,該函數(shù)可以令最終輸出接近0從而緩解過(guò)擬合提高了模型泛化性。
值值較大時(shí),說(shuō)明特征本身有顯著性差別但輸出值太大容易過(guò)擬合,該函數(shù)可以令最終輸出接近0從而緩解過(guò)擬合提高了模型泛化性。
3.Dropout
Dropout是文章亮點(diǎn)之一,屬于提高模型泛化性的方法,操作比較簡(jiǎn)單,以一定概率隨機(jī)讓某些神經(jīng)元輸出設(shè)置為0,既不參與前向傳播也不參與反向傳播,也可以從正則化角度去看待它。(關(guān)于深度學(xué)習(xí)的正則化年初的時(shí)候在公司做過(guò)一個(gè)分享,下次直接把pdf放出來(lái))
從模型集成的角度來(lái)看:
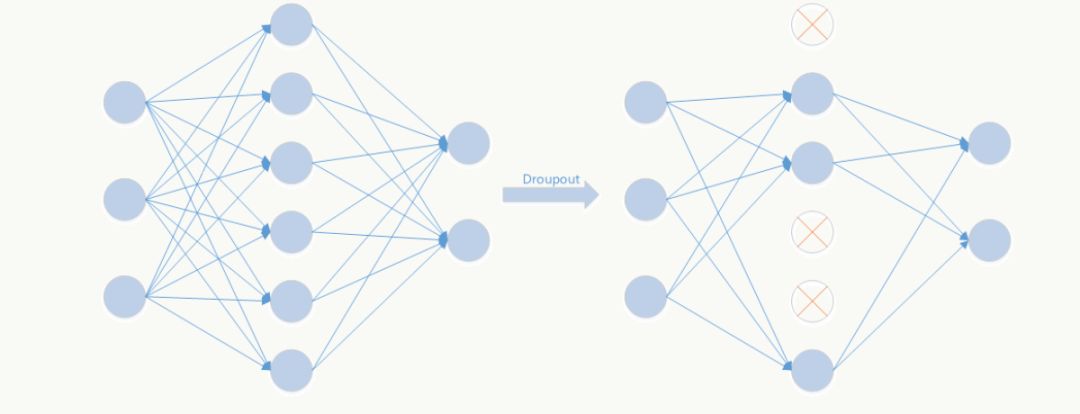
無(wú)Dropout網(wǎng)絡(luò):
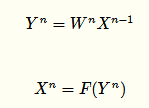
有Dropout網(wǎng)絡(luò):
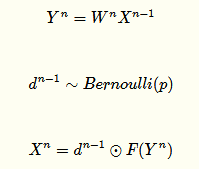
其中p為Dropout的概率(如p=0.5,即讓50%的神經(jīng)元隨機(jī)失活),n為所在的層。
它是極端情況下的Bagging,由于在每步訓(xùn)練中,神經(jīng)元會(huì)以某種概率隨機(jī)被置為無(wú)效,相當(dāng)于是參數(shù)共享的新網(wǎng)絡(luò)結(jié)構(gòu),每個(gè)模型為了使損失降低會(huì)盡可能學(xué)最“本質(zhì)”的特征,“本質(zhì)”可以理解為由更加獨(dú)立的、和其他神經(jīng)元相關(guān)性弱的、泛化能力強(qiáng)的神經(jīng)元提取出來(lái)的特征;而如果采用類似SGD的方式訓(xùn)練,每步迭代都會(huì)選取不同的數(shù)據(jù)集,這樣整個(gè)網(wǎng)絡(luò)相當(dāng)于是用不同數(shù)據(jù)集學(xué)習(xí)的多個(gè)模型的集成組合。
用PaddlePaddle實(shí)現(xiàn)AlexNet
1.網(wǎng)絡(luò)結(jié)構(gòu)(alexnet.py)
這次我寫(xiě)了兩個(gè)alextnet,一個(gè)加上了局部均值歸一化LRN,一個(gè)沒(méi)有加LRN,對(duì)比效果如何
#coding:utf-8 ''' Created by huxiaoman 2017.12.5 alexnet.py:alexnet網(wǎng)絡(luò)結(jié)構(gòu) ''' import paddle.v2 as paddle import os with_gpu = os.getenv('WITH_GPU', '0') != '1' def alexnet_lrn(img): conv1 = paddle.layer.img_conv( input=img, filter_size=11, num_channels=3, num_filters=96, stride=4, padding=1) cmrnorm1 = paddle.layer.img_cmrnorm( input=conv1, size=5, scale=0.0001, power=0.75) pool1 = paddle.layer.img_pool(input=cmrnorm1, pool_size=3, stride=2) conv2 = paddle.layer.img_conv( input=pool1, filter_size=5, num_filters=256, stride=1, padding=2, groups=1) cmrnorm2 = paddle.layer.img_cmrnorm( input=conv2, size=5, scale=0.0001, power=0.75) pool2 = paddle.layer.img_pool(input=cmrnorm2, pool_size=3, stride=2) pool3 = paddle.networks.img_conv_group( input=pool2, pool_size=3, pool_stride=2, conv_num_filter=[384, 384, 256], conv_filter_size=3, pool_type=paddle.pooling.Max()) fc1 = paddle.layer.fc( input=pool3, size=4096, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) fc2 = paddle.layer.fc( input=fc1, size=4096, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) return fc2 def alexnet(img): conv1 = paddle.layer.img_conv( input=img, filter_size=11, num_channels=3, num_filters=96, stride=4, padding=1) cmrnorm1 = paddle.layer.img_cmrnorm( input=conv1, size=5, scale=0.0001, power=0.75) pool1 = paddle.layer.img_pool(input=cmrnorm1, pool_size=3, stride=2) conv2 = paddle.layer.img_conv( input=pool1, filter_size=5, num_filters=256, stride=1, padding=2, groups=1) cmrnorm2 = paddle.layer.img_cmrnorm( input=conv2, size=5, scale=0.0001, power=0.75) pool2 = paddle.layer.img_pool(input=cmrnorm2, pool_size=3, stride=2) pool3 = paddle.networks.img_conv_group( input=pool2, pool_size=3, pool_stride=2, conv_num_filter=[384, 384, 256], conv_filter_size=3, pool_type=paddle.pooling.Max()) fc1 = paddle.layer.fc( input=pool3, size=4096, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) fc2 = paddle.layer.fc( input=fc1, size=4096, act=paddle.activation.Relu(), layer_attr=paddle.attr.Extra(drop_rate=0.5)) return fc3
2.訓(xùn)練代碼(train_alexnet.py)
#coding:utf-8 ''' Created by huxiaoman 2017.12.5 train_alexnet.py:訓(xùn)練alexnet對(duì)cifar10數(shù)據(jù)集進(jìn)行分類 ''' import sys, os import paddle.v2 as paddle #alex模型為不帶LRN的 from alexnet import alexnet #alexnet_lrn為帶有l(wèi)rn的 #from alextnet import alexnet_lrn with_gpu = os.getenv('WITH_GPU', '0') != '1' def main(): datadim = 3 * 32 * 32 classdim = 10 # PaddlePaddle init paddle.init(use_gpu=with_gpu, trainer_count=7) image = paddle.layer.data( name="image", type=paddle.data_type.dense_vector(datadim)) # Add neural network config # option 1. resnet # net = resnet_cifar10(image, depth=32) # option 2. vgg #net = alexnet_lrn(image) net = alexnet(image) out = paddle.layer.fc( input=net, size=classdim, act=paddle.activation.Softmax()) lbl = paddle.layer.data( name="label", type=paddle.data_type.integer_value(classdim)) cost = paddle.layer.classification_cost(input=out, label=lbl) # Create parameters parameters = paddle.parameters.create(cost) # Create optimizer momentum_optimizer = paddle.optimizer.Momentum( momentum=0.9, regularization=paddle.optimizer.L2Regularization(rate=0.0002 * 128), learning_rate=0.1 / 128.0, learning_rate_decay_a=0.1, learning_rate_decay_b=50000 * 100, learning_rate_schedule='discexp') # End batch and end pass event handler def event_handler(event): if isinstance(event, paddle.event.EndIteration): if event.batch_id % 100 == 0: print "\nPass %d, Batch %d, Cost %f, %s" % ( event.pass_id, event.batch_id, event.cost, event.metrics) else: sys.stdout.write('.') sys.stdout.flush() if isinstance(event, paddle.event.EndPass): # save parameters with open('params_pass_%d.tar' % event.pass_id, 'w') as f: parameters.to_tar(f) result = trainer.test( reader=paddle.batch( paddle.dataset.cifar.test10(), batch_size=128), feeding={'image': 0, 'label': 1}) print "\nTest with Pass %d, %s" % (event.pass_id, result.metrics) # Create trainer trainer = paddle.trainer.SGD( cost=cost, parameters=parameters, update_equation=momentum_optimizer) # Save the inference topology to protobuf. inference_topology = paddle.topology.Topology(layers=out) with open("inference_topology.pkl", 'wb') as f: inference_topology.serialize_for_inference(f) trainer.train( reader=paddle.batch( paddle.reader.shuffle( paddle.dataset.cifar.train10(), buf_size=50000), batch_size=128), num_passes=200, event_handler=event_handler, feeding={'image': 0, 'label': 1}) # inference from PIL import Image import numpy as np import os def load_image(file): im = Image.open(file) im = im.resize((32, 32), Image.ANTIALIAS) im = np.array(im).astype(np.float32) im = im.transpose((2, 0, 1)) # CHW im = im[(2, 1, 0), :, :] # BGR im = im.flatten() im = im / 255.0 return im test_data = [] cur_dir = os.path.dirname(os.path.realpath(__file__)) test_data.append((load_image(cur_dir + '/image/dog.png'), )) probs = paddle.infer( output_layer=out, parameters=parameters, input=test_data) lab = np.argsort(-probs) # probs and lab are the results of one batch data print "Label of image/dog.png is: %d" % lab[0][0] if __name__ == '__main__': main()
用Tensorflow實(shí)現(xiàn)AlexNet
1.網(wǎng)絡(luò)結(jié)構(gòu)
def inference(images): ''' Alexnet模型 輸入:images的tensor 返回:Alexnet的最后一層卷積層 ''' parameters = [] # conv1 with tf.name_scope('conv1') as scope: kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv1 = tf.nn.relu(bias, name=scope) print_activations(conv1) parameters += [kernel, biases] # lrn1 with tf.name_scope('lrn1') as scope: lrn1 = tf.nn.local_response_normalization(conv1, alpha=1e-4, beta=0.75, depth_radius=2, bias=2.0) # pool1 pool1 = tf.nn.max_pool(lrn1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool1') print_activations(pool1) # conv2 with tf.name_scope('conv2') as scope: kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[192], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv2 = tf.nn.relu(bias, name=scope) parameters += [kernel, biases] print_activations(conv2) # lrn2 with tf.name_scope('lrn2') as scope: lrn2 = tf.nn.local_response_normalization(conv2, alpha=1e-4, beta=0.75, depth_radius=2, bias=2.0) # pool2 pool2 = tf.nn.max_pool(lrn2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool2') print_activations(pool2) # conv3 with tf.name_scope('conv3') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv3 = tf.nn.relu(bias, name=scope) parameters += [kernel, biases] print_activations(conv3) # conv4 with tf.name_scope('conv4') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv4 = tf.nn.relu(bias, name=scope) parameters += [kernel, biases] print_activations(conv4) # conv5 with tf.name_scope('conv5') as scope: kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype=tf.float32, stddev=1e-1), name='weights') conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME') biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases') bias = tf.nn.bias_add(conv, biases) conv5 = tf.nn.relu(bias, name=scope) parameters += [kernel, biases] print_activations(conv5) # pool5 pool5 = tf.nn.max_pool(conv5, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool5') print_activations(pool5) return pool5, parameters
完整代碼可見(jiàn):alexnet_tf.py
實(shí)驗(yàn)結(jié)果對(duì)比
三個(gè)代碼跑完后,對(duì)比了一下實(shí)驗(yàn)結(jié)果,如圖所示:

可以看到,在batch_size,num_epochs,devices和thread數(shù)都相同的條件下,加了LRN的paddlepaddle版的alexnet網(wǎng)絡(luò)結(jié)果效果最好,而時(shí)間最短的是不加LRN的alexnet,在時(shí)間和精度上都比較平均的是tensorflow版的alexnet,當(dāng)然,tf版的同樣加了LRN,所以LRN對(duì)于實(shí)驗(yàn)效果還是有一定提升的。
總結(jié)
AlexNet在圖像分類中是一個(gè)比較重要的網(wǎng)絡(luò),在學(xué)習(xí)的過(guò)程中不僅要學(xué)會(huì)寫(xiě)網(wǎng)絡(luò)結(jié)構(gòu),知道每一層的結(jié)構(gòu),更重要的是得知道為什么要這樣設(shè)計(jì),這樣設(shè)計(jì)有什么好處,如果對(duì)某些參數(shù)進(jìn)行一些調(diào)整結(jié)果會(huì)有什么變化?為什么會(huì)產(chǎn)生這樣的變化。在實(shí)際應(yīng)用中,如果需要對(duì)網(wǎng)絡(luò)結(jié)構(gòu)做一些調(diào)整,應(yīng)該如何調(diào)整使得網(wǎng)絡(luò)更適合我們的實(shí)際數(shù)據(jù)?這些才是我們關(guān)心的。也是面試中常常會(huì)考察的點(diǎn)。昨天面試了一位工作五年的算法工程師,問(wèn)道他在項(xiàng)目中用的模型是alexnet,對(duì)于alexnet的網(wǎng)絡(luò)結(jié)構(gòu)并不是非常清楚,如果要改網(wǎng)絡(luò)結(jié)構(gòu)也不知道如何改,這樣其實(shí)不好,僅僅把模型跑通只是第一步,后續(xù)還有很多工作要做,這也是作為算法工程師的價(jià)值體現(xiàn)之一。本文對(duì)于alexnet的網(wǎng)絡(luò)結(jié)構(gòu)參考我之前的領(lǐng)導(dǎo)寫(xiě)的文章,如過(guò)有什么不懂的可以留言。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5516瀏覽量
121562 -
cnn
+關(guān)注
關(guān)注
3文章
353瀏覽量
22338 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60633
原文標(biāo)題:【深度學(xué)習(xí)系列】用PaddlePaddle和Tensorflow實(shí)現(xiàn)經(jīng)典CNN網(wǎng)絡(luò)AlexNet
文章出處:【微信號(hào):AI_shequ,微信公眾號(hào):人工智能愛(ài)好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
存內(nèi)計(jì)算芯片研究進(jìn)展以及應(yīng)用-以基于Nor Flash的卷積神經(jīng)網(wǎng)絡(luò)量化以及部署

線性分類器
干貨 | TensorFlow的55個(gè)經(jīng)典案例
使用CIFAR-10彩色圖片訓(xùn)練出現(xiàn)報(bào)錯(cuò)信息及解決
在arm_nnexamples_cifar10_inputs.h 中所使用的輸入值為什麼會(huì)有負(fù)數(shù)的情況
用Win10系統(tǒng)如何跑NMSIS的cifar10例程?
機(jī)器學(xué)習(xí)的突飛猛進(jìn),這些進(jìn)步很可疑
如何用單獨(dú)的GPU,在CIFAR-10圖像分類數(shù)據(jù)集上高效地訓(xùn)練殘差網(wǎng)絡(luò)
如何使用神經(jīng)網(wǎng)絡(luò)模型加速圖像數(shù)據(jù)集的分類
計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理這兩個(gè)領(lǐng)域AI進(jìn)展的真實(shí)情況
李飛飛等人ICLR2019論文構(gòu)建人類眼睛感知評(píng)估(HYPE),帶給你新的認(rèn)知

Edgeboard試用—基于CIFAR10分類模型的移植
信息保留的二值神經(jīng)網(wǎng)絡(luò)IR-Net,落地性能和實(shí)用性俱佳





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論