 知識圖譜在推薦系統中可能的應用價值
知識圖譜在推薦系統中可能的應用價值

我們幾乎每天都會接收到各種各樣的推薦信息,從新聞、購物到吃飯、娛樂。個性化推薦系統作為一種信息過濾的重要手段,可以依據我們的習慣和愛好推薦合適的服務。但傳統的推薦系統容易出現稀疏性和冷啟動的問題,而知識圖譜作為一種新興類型的輔助信息,近幾年逐漸引起了研究人員的關注,本文將向大家介紹知識圖譜的相關知識以及知識圖譜在推薦系統中可能的應用價值。一起來學習一下吧!
小王是一名程序員。早上八點,他被鬧鈴叫醒,拿起手機開始瀏覽手機上的新聞APP推薦的最新消息:
隨后,小王想起昨晚放在購物車里的鞋還沒有下單。于是,他打開了某購物APP,查看了一下自己的購物車:
但是他覺得下面推薦的板鞋似乎更適合自己,于是他買了一雙。
吃完早飯,小王坐地鐵去上班。地鐵上無聊的小王打開了某音樂APP,系統已經為他選好了推薦的歌曲:
到了公司后,小王開始繼續寫沒有完成的代碼,但是始終無法把參數調到滿意的水平。有些煩躁的小王想歇一歇,于是打開了某資訊APP,看了幾個為他推薦的話題:

就在他認真閱讀的時候,經理注意到了他不在干活,很生氣,于是嚴肅地批評了小王。小王感到很委屈,這時手機里的某求職類APP給他發來了推送:
小王覺得這幾個職位都挺適合自己的,于是心里有了跳槽的打算。到了午飯時間,小王打開了某外賣APP,查看了一下系統推薦的附近餐廳:
小王一邊吃著剛剛送來的外賣,一邊瀏覽著某娛樂類APP,查看適合晚上和女朋友一起觀看的演出推薦:
晚上看完演出,小王和女朋友都非常滿意,覺得這個APP的系統推薦很棒。
推薦系統
跟小王一樣,我們幾乎每個人每天都會使用多個APP中的推薦功能,這些功能的背后都是個性化推薦系統(personalized recommender systems)。隨著互聯網技術和產業的迅速發展,接入互聯網的服務器數量和網頁數量也呈指數級上升。用戶面臨著海量的信息,傳統的搜索算法只能呈現給用戶(user)相同的物品(item)排序結果,無法針對不同用戶的興趣愛好提供相應的服務。信息爆炸使得信息的利用率反而降低,這種現象被稱為信息超載(information overload)。
推薦問題從本質上說就是代替用戶評估其從未看過、接觸過和使用過的物品,包括書籍、電影、新聞、音樂、餐館、旅游景點等。推薦系統作為一種信息過濾的重要手段,是當前解決信息超載問題的最有效的方法之一,是面向用戶的互聯網產品的核心技術。
推薦系統的任務和難點
按照預測對象的不同,推薦系統一般可以分成兩類:一類是評分預測(rating prediction),例如在電影類應用中,系統需要預測用戶對電影的評分,并以此為根據推送其可能喜歡的電影。這種場景下的用戶反饋信息表達了用戶的喜好程度,因此這種信息也叫顯式反饋(explicit feedback);另一類是點擊率預測(click-through rateprediction),例如在新聞類應用中,系統需要預測用戶點擊某新聞的概率來優化推薦方案。這種場景下的用戶反饋信息只能表達用戶的行為特征(點擊/未點擊),而不能反映用戶的喜愛程度,因此這種信息也叫隱式反饋(implicit feedback)。
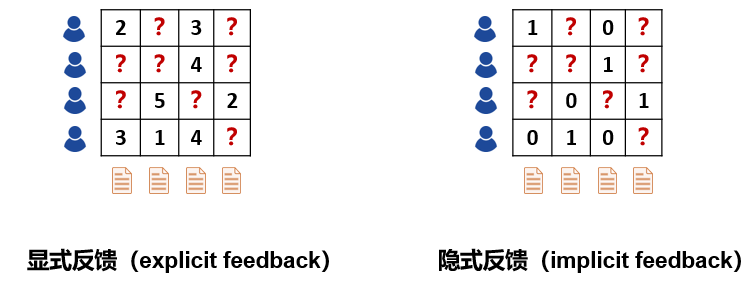
傳統的推薦系統只使用用戶和物品的歷史交互信息(顯式或隱式反饋)作為輸入,這會帶來兩個問題:一,在實際場景中,用戶和物品的交互信息往往是非常稀疏(sparse)的。例如,一個電影類APP可能包含了上萬部電影,然而一個用戶打過分的電影可能平均只有幾十部。使用如此少量的已觀測數據來預測大量的未知信息,會極大地增加算法的過擬合(overfitting)風險;二,對于新加入的用戶或者物品,由于系統沒有其歷史交互信息,因此無法進行準確地建模和推薦,這種情況也叫做冷啟動問題(cold start problem)。
解決稀疏性和冷啟動問題的一個常見思路是在推薦算法中額外引入一些輔助信息(side information)作為輸入。輔助信息可以豐富對用戶和物品的描述、增強推薦算法的挖掘能力,從而有效地彌補交互信息的稀疏或缺失。常見的輔助信息包括:
社交網絡(social networks):一個用戶對某個物品感興趣,他的朋友可能也會對該物品感興趣;
用戶/物品屬性(attributes):擁有同種屬性的用戶可能會對同一類物品感興趣;
圖像/視頻/音頻/文本等多媒體信息(multimedia):例如商品圖片、電影預告片、音樂、新聞標題等;
上下文(context):用戶-物品交互的時間、地點、當前會話信息等。
……
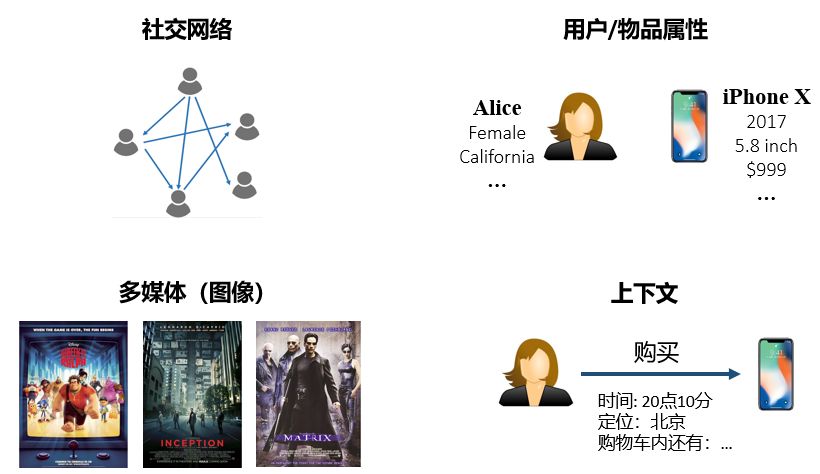
如何根據具體推薦場景的特點將各種輔助信息有效地融入推薦算法一直是推薦系統研究領域的熱點和難點,如何從各種輔助信息中提取有效的特征也是推薦系統工程領域的核心問題。
知識圖譜
在各種輔助信息中,知識圖譜作為一種新興類型的輔助信息近幾年逐漸引起了研究人員的關注。知識圖譜(knowledge graph)是一種語義網絡,其結點(node)代表實體(entity)或者概念(concept),邊(edge)代表實體/概念之間的各種語義關系(relation)。一個知識圖譜由若干個三元組(h、r、t)組成,其中h和t代表一條關系的頭結點和尾節點,r代表關系。
上圖展示的三元組表達了“陳凱歌導演了霸王別姬”這樣一條事實,其中h=陳凱歌、t=霸王別姬、r=導演。
知識圖譜包含了實體之間豐富的語義關聯,為推薦系統提供了潛在的輔助信息來源。知識圖譜在諸多推薦場景中都有應用的潛力,例如電影、新聞、景點、餐館、購物等。和其它種類的輔助信息相比,知識圖譜的引入可以讓推薦結果更加具有以下特征:
精確性(precision)。知識圖譜為物品引入了更多的語義關系,可以深層次地發現用戶興趣;
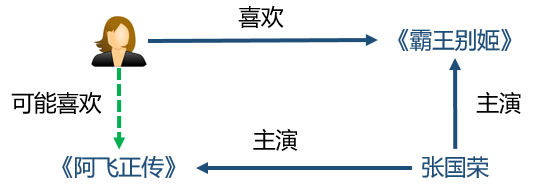
多樣性(diversity)。知識圖譜提供了不同的關系連接種類,有利于推薦結果的發散,避免推薦結果局限于單一類型;
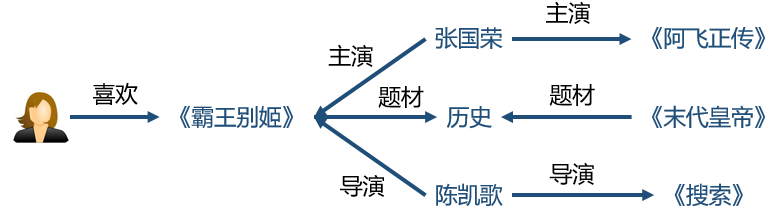
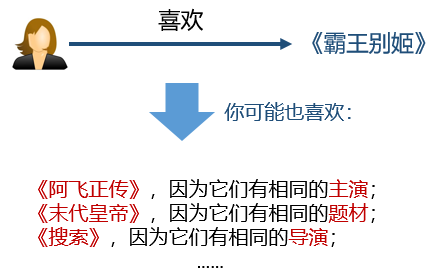
可解釋性(explainability)。知識圖譜可以連接用戶的歷史記錄和推薦結果,從而提高用戶對推薦結果的滿意度和接受度,增強用戶對推薦系統的信任。
這里值得一提的是知識圖譜和物品屬性的區別。物品屬性可以看成是在知識圖譜中和某物品直接相連的一跳(1-hop)的節點,即一個弱化版本的知識圖譜。事實上,一個完整的知識圖譜可以提供物品之間更深層次和更長范圍內的關聯,例如,“《霸王別姬》-張國榮-香港-梁朝偉-《無間道》”。正因為知識圖譜的維度更高,語義關系更豐富,它的處理也因此比物品屬性要更加復雜和困難。
一般來說,現有的可以將知識圖譜引入推薦系統的工作分為兩類:
以LibFM[1]為代表的通用的基于特征的推薦方法(generic feature-based methods)。這類方法統一地把用戶和物品的屬性作為推薦算法的輸入。例如,LibFM將某個用戶和某個物品的所有屬性記為x,然后令該用戶和物品之間的交互強度y(x)依賴于屬性中所有的一次項和二次項:
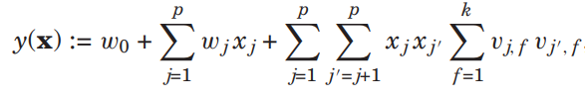
基于該類方法的通用性,我們可以將知識圖譜弱化為物品屬性,然后應用該類方法即可。當然,這種做法的缺點也顯而易見:它并非專門針對知識圖譜設計,因此無法高效地利用知識圖譜的全部信息。例如,該類方法難以利用多跳的知識,也難以引入關系(relation)的信息。
以PER [2]、MetaGraph[3]為代表的基于路徑的推薦方法(path-based methods)。該類方法將知識圖譜視為一個異構信息網絡(heterogeneous information network),然后構造物品之間的基于meta-path或meta-graph的特征。簡單地說,meta-path是連接兩個實體的一條特定的路徑,比如“演員->電影->導演->電影->演員”這條meta-path可以連接兩個演員,因此可以視為一種挖掘演員之間的潛在關系的方式。這類方法的優點是充分且直觀地利用了知識圖譜的網絡結構,缺點是需要手動設計meta-path或meta-graph,這在實踐中難以到達最優;同時,該類方法無法在實體不屬于同一個領域的場景(例如新聞推薦)中應用,因為我們無法為這樣的場景預定義meta-path或meta-graph。
知識圖譜特征學習
知識圖譜特征學習(Knowledge Graph Embedding)為知識圖譜中的每個實體和關系學習得到一個低維向量,同時保持圖中原有的結構或語義信息。事實上,知識圖譜特征學習是網絡特征學習(network embedding)的一個子領域,因為知識圖譜包含特有的語義信息,所以知識圖譜特征學習比通用的網絡特征學習需要更細心和針對性的模型設計。一般而言,知識圖譜特征學習的模型分類兩類:
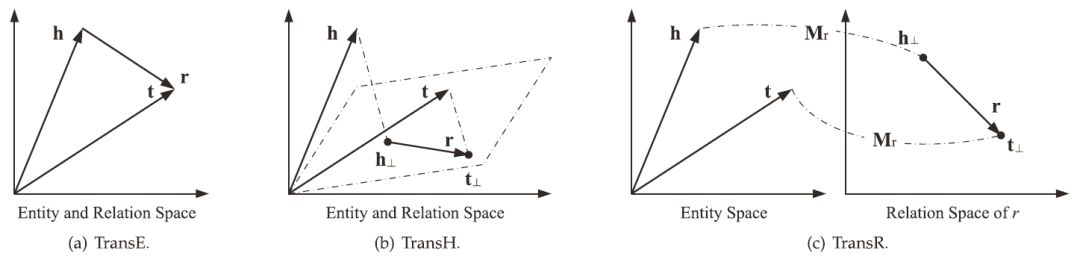
基于距離的翻譯模型(distance-based translational models)。這類模型使用基于距離的評分函數評估三元組的概率,將尾節點視為頭結點和關系翻譯得到的結果。這類方法的代表有TransE、TransH、TransR等;
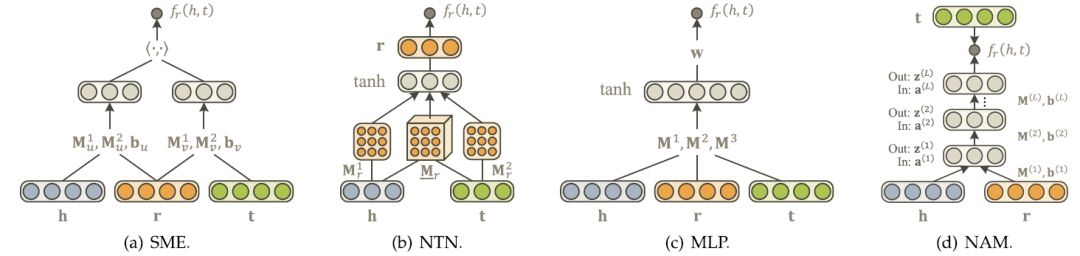
基于語義的匹配模型(semantic-based matching models)。這類模型使用基于相似度的評分函數評估三元組的概率,將實體和關系映射到隱語義空間中進行相似度度量。這類方法的代表有SME、NTN、MLP、NAM等。
由于知識圖譜特征學習為每個實體和特征學習得到了一個低維向量,而且在向量中保持了原圖的結構和語義信息,所以一組好的實體向量可以充分且完全地表示實體之間的相互關系,因為絕大部分機器學習算法都可以很方便地處理低維向量輸入。因此,利用知識圖譜特征學習,我們可以很方便地將知識圖譜引入各種推薦系統算法中。概括地說,知識圖譜特征學習可以:
降低知識圖譜的高維性和異構性;
增強知識圖譜應用的靈活性;
減輕特征工程的工作量;
減少由于引入知識圖譜帶來的額外計算負擔。
在本篇中,我們分別介紹了推薦系統、知識圖譜、以及知識圖譜在推薦系統中的應用價值。作為推薦算法的輔助信息,知識圖譜的引入可以極大地提高推薦系統的精準性、多樣性和可解釋性。在下周的文章中,我們將詳述將知識圖譜引入推薦系統的各種思路與實現,敬請期待!
參考文獻
[1] Factorization machines with libfm
[2] Personalized entity recommendation: A heterogeneous information network approach
[3] Meta-graph based recommendation fusion over heterogeneous information networks
[4] Knowledge graph embedding: A survey of approaches and applications
-
推薦系統
+關注
關注
1文章
44瀏覽量
10226 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7954
原文標題:推薦算法不夠精準?讓知識圖譜來解決
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
KGB知識圖譜基于傳統知識工程的突破分析
KGB知識圖譜技術能夠解決哪些行業痛點?
知識圖譜的三種特性評析
KGB知識圖譜幫助金融機構進行風險預判
KGB知識圖譜通過智能搜索提升金融行業分析能力
一文帶你讀懂知識圖譜
知識圖譜劃分的相關算法及研究

知識圖譜在工程應用中的關鍵技術、應用及案例

通用知識圖譜構建技術的應用及發展趨勢

知識圖譜是NLP的未來嗎?

知識圖譜Knowledge Graph構建與應用
知識圖譜:知識圖譜的典型應用





 工商網監
工商網監
評論