") 有了OpenAI Five,它已經(jīng)可以在比賽中擊敗業(yè)余玩家
有了OpenAI Five,它已經(jīng)可以在比賽中擊敗業(yè)余玩家
編者按:關(guān)于OpenAI的那篇博客,相信很多玩家一早起來(lái)就已經(jīng)看過(guò)了。昨晚打完Dota2時(shí),云玩家小編也在Reddit上看了相關(guān)視頻,還和隊(duì)友一起推測(cè)了會(huì)兒內(nèi)在機(jī)制。但不曾想,我這一睡就又錯(cuò)過(guò)了頭條。本文會(huì)重新編譯原博內(nèi)容,并補(bǔ)上被大家忽視的一些關(guān)鍵點(diǎn)。
去年,OpenAI的強(qiáng)化學(xué)習(xí)bot在中路solo中擊敗職業(yè)選手Dendi,贏得眾人矚目,但Dota2是一個(gè)5人游戲,在那之后,我們目標(biāo)是制作一個(gè)由神經(jīng)網(wǎng)絡(luò)構(gòu)成的5人團(tuán)隊(duì),它能在8月份舉辦的Ti8國(guó)際邀請(qǐng)賽上,用有限的英雄擊敗職業(yè)隊(duì)。時(shí)至今日,我們有了OpenAI Five,它已經(jīng)可以在比賽中擊敗業(yè)余玩家。
OpenAI Five玩的是限制版的Dota2,它只會(huì)瘟疫法師、火槍、毒龍、冰女和巫妖5個(gè)英雄,因?yàn)殓R像訓(xùn)練,它的對(duì)手也只能玩這5個(gè)。游戲的“限制性”主要體現(xiàn)在以下幾方面:
英雄受限(上述5個(gè));
沒(méi)有假眼和真眼;
沒(méi)有肉山;
不能隱身(消耗品和相關(guān)物品,可以理解為沒(méi)有霧、微光、隱刀、大隱刀、隱身符等);
沒(méi)有召喚物和分身(沒(méi)有分身斧、分身符、支配頭盔等);
沒(méi)有圣劍、魔瓶、補(bǔ)刀斧、飛鞋、知識(shí)之書(shū)、凝魂之露(沒(méi)有骨灰?);
每隊(duì)五只無(wú)敵信使(和加速模式一樣);
不能掃描。
這些限制使OpenAI Five的游戲和正常游戲有一定區(qū)別,尤其是隊(duì)長(zhǎng)模式,但總體而言,它和隨機(jī)征召等模式差別不大(對(duì)于冰女這樣的五號(hào)位,沒(méi)有眼完全沒(méi)法玩吧!)。
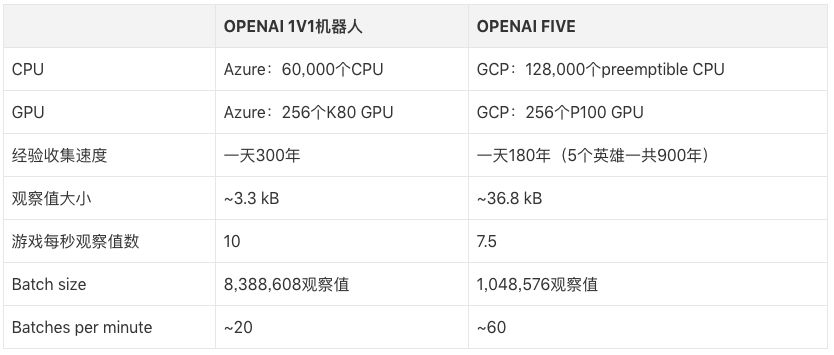
OpenAI Five每天玩的游戲量相當(dāng)于人類(lèi)玩家180年的積累,和圍棋AI一樣,它從自學(xué)中提取經(jīng)驗(yàn)。訓(xùn)練設(shè)備是256個(gè)GPU和128,000個(gè)CPU,使用的強(qiáng)化學(xué)習(xí)算法是近端策略優(yōu)化(PPO)。因?yàn)椴煌⑿坶g技能、出裝各異,這5個(gè)英雄使用的是5個(gè)獨(dú)立的LSTM,無(wú)人類(lèi)數(shù)據(jù),由英雄從自己的數(shù)據(jù)中學(xué)習(xí)可識(shí)別策略。
實(shí)驗(yàn)表明,在沒(méi)有根本性進(jìn)展的前提下,強(qiáng)化學(xué)習(xí)可以利用LSTM進(jìn)行大規(guī)模的、可實(shí)現(xiàn)的長(zhǎng)期規(guī)劃,這出乎我們的意料。為了考察這個(gè)成果,7月28日,OpenAI Five會(huì)和頂級(jí)玩家進(jìn)行比賽,屆時(shí)玩家可以在Twitch上觀看實(shí)況轉(zhuǎn)播。
OpenAI Five擊敗OpenAI員工隊(duì)伍
問(wèn)題
如果一個(gè)AI能在像星際、Dota這樣復(fù)雜的游戲里超越人類(lèi)水平,那它就是一個(gè)里程碑。相較于AI之前在國(guó)際象棋和圍棋里取得的成就,游戲能更好地捕捉現(xiàn)實(shí)世界中的混亂和連續(xù)性,這就意味著能解決游戲問(wèn)題的AI系統(tǒng)具有更好的通用性。醉翁之意不在酒,它的目標(biāo)也不僅僅是游戲。
Dota2是一款實(shí)時(shí)戰(zhàn)略游戲,一場(chǎng)比賽由2支隊(duì)伍構(gòu)成,每支隊(duì)伍5人,在游戲中,每個(gè)玩家需要操控一個(gè)“英雄”單位。如果AI想玩Dota2,它必須掌握以下幾點(diǎn):
時(shí)間較長(zhǎng)。Dota2的運(yùn)行幀數(shù)是30幀每秒,一場(chǎng)游戲平均45分鐘,也就是一場(chǎng)游戲要跑80,000幀左右。在游戲中,大多數(shù)動(dòng)作(action,例如讓英雄移動(dòng)到某一位置)產(chǎn)生的獨(dú)立影響相對(duì)較小,但一些獨(dú)立動(dòng)作,比如TP,就可能會(huì)對(duì)游戲戰(zhàn)略產(chǎn)生重大影響。同時(shí),游戲中也存在一些貫徹始終的戰(zhàn)略,比如推線、farm(刷錢(qián))和gank(抓人)。OpenAI Five的觀察頻率是4幀一次,也就是場(chǎng)均20,000個(gè)動(dòng)作,而國(guó)際象棋一般在40步以內(nèi)就能決出勝負(fù),圍棋是150步。這些動(dòng)作幾乎都具有戰(zhàn)略性意義。
視野有限。在Dota2中,地圖本身是黑的,只能靠英雄和建筑提供一定視野(禁止插眼),這就意味著比賽要根據(jù)不完整的數(shù)據(jù)信息進(jìn)行推斷,同時(shí)預(yù)測(cè)敵方英雄的發(fā)育進(jìn)度。國(guó)際象棋和圍棋都是全知視角。
高維的、連續(xù)的動(dòng)作空間。在比賽中,一個(gè)英雄可以采取的動(dòng)作有數(shù)十個(gè),其中有些是對(duì)英雄使用的,有些是點(diǎn)地面的。對(duì)于每個(gè)英雄,我們把這些連續(xù)的動(dòng)作空間分割成170,000個(gè)可能的動(dòng)作(有CD,不是每個(gè)都能用),除去其中的連續(xù)部分,平均每幀約有1000個(gè)動(dòng)作可以選擇。而在國(guó)際象棋中,每個(gè)節(jié)點(diǎn)的分支因子只有35個(gè),圍棋則是平均250個(gè)。
高維的、連續(xù)的觀察空間。Dota2的地圖相當(dāng)豐富,比如一場(chǎng)比賽中有10個(gè)英雄、幾十個(gè)建筑、多個(gè)NPC單位,以及包括神符、樹(shù)木、圣壇(火鍋)等在內(nèi)的諸多要素。我們的模型通過(guò)V社的Bot API觀察游戲狀態(tài),用20,000個(gè)數(shù)據(jù)(大多數(shù)是浮點(diǎn)數(shù)據(jù))總結(jié)了整張地圖的所有信息。相較之下,國(guó)際象棋只有約70個(gè)(8×8棋盤(pán)),圍棋只有約400個(gè)(19×19棋盤(pán))。
Dota2的游戲規(guī)則非常復(fù)雜——它已經(jīng)被積極開(kāi)發(fā)了十幾年,游戲邏輯代碼也有數(shù)十萬(wàn)行。對(duì)于AI來(lái)說(shuō),這個(gè)邏輯需要幾毫秒才能執(zhí)行,而國(guó)際象棋和圍棋只需幾納秒。目前,游戲還在以每?jī)芍芤淮蔚念l率持續(xù)更新,不斷改變語(yǔ)義環(huán)境。
我們的方法
我們使用的算法是前陣子剛推出的PPO,這次用的是它的大規(guī)模版本。和去年的1v1機(jī)器人一樣,OpenAI Five也是從自學(xué)中總結(jié)游戲經(jīng)驗(yàn),它們從隨機(jī)參數(shù)開(kāi)始訓(xùn)練,不使用任何人類(lèi)數(shù)據(jù)。
強(qiáng)化學(xué)習(xí)(RL)研究人員一般認(rèn)為,如果想讓智能體在長(zhǎng)時(shí)間游戲中表現(xiàn)出色,就難免需要一些根本上的新突破,比如hierarchical reinforcement learning(分層強(qiáng)化學(xué)習(xí))。但實(shí)驗(yàn)結(jié)果表明,我們應(yīng)該給予已有算法更多信任,如果規(guī)模夠大、結(jié)構(gòu)夠合理,它們也能表現(xiàn)出色。
智能體的訓(xùn)練目標(biāo)是最大化未來(lái)回報(bào),這些回報(bào)被折扣因子γ加權(quán)。在OpenAI Five的近期訓(xùn)練中,我們把因子γ從0.998提高到了0.9997,把評(píng)估未來(lái)獎(jiǎng)勵(lì)的半衰期從46秒延長(zhǎng)到了五分鐘。為了體現(xiàn)這個(gè)進(jìn)步的巨大,這里我們列幾個(gè)數(shù)據(jù):在PPO這篇論文中,最長(zhǎng)半衰期是0.5秒;在Rainbow這篇論文中,最長(zhǎng)半衰期是4.4秒;而在Observe and Look Further這篇論文中,最長(zhǎng)半衰期是46秒。
盡管當(dāng)前版本的OpenAI Five在“補(bǔ)刀”上表現(xiàn)不佳(大約是Dota玩家的中位數(shù)),但它對(duì)于經(jīng)驗(yàn)、金錢(qián)的的優(yōu)先級(jí)匹配策略和專(zhuān)業(yè)選手基本一致。為了獲得長(zhǎng)期回報(bào),犧牲短期回報(bào)是很正常的,就好比隊(duì)友抱團(tuán)推塔時(shí),玩家不該自己在線上補(bǔ)刀刷錢(qián)。這是個(gè)振奮人心的發(fā)現(xiàn),因?yàn)槲覀兊腁I系統(tǒng)真的在進(jìn)行長(zhǎng)期優(yōu)化。
模型結(jié)構(gòu)
看不清圖請(qǐng)向論智君索取
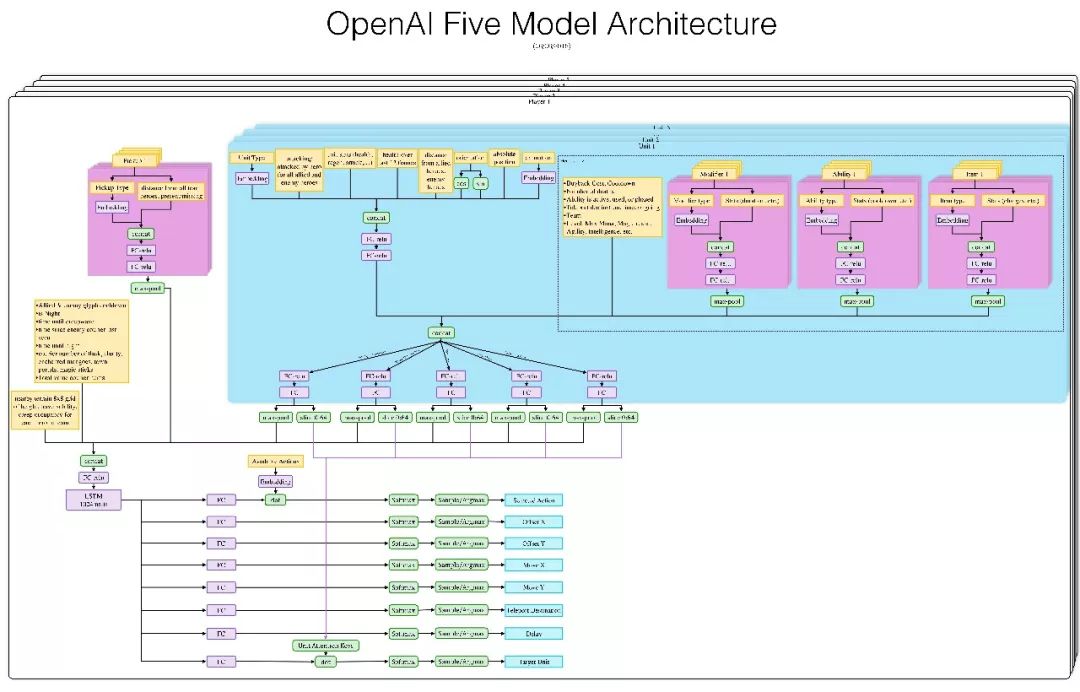
每個(gè)OpenAI Five神經(jīng)網(wǎng)絡(luò)都包含一個(gè)單層的LSTM(左下淡紫),其中有1024個(gè)神經(jīng)元。輸入當(dāng)前的游戲狀態(tài)(從Valve的Bot API中提取)后,它會(huì)單獨(dú)計(jì)算各個(gè)action head(輸出動(dòng)作標(biāo)簽),如圖中下方亮藍(lán)色方框中的X坐標(biāo)、Y坐標(biāo)、目標(biāo)單位等,再把所有action head合并成一系列動(dòng)作。
下圖是OpenAI Five使用的觀察空間和動(dòng)作空間的交互式演示。它把整張地圖看做一個(gè)有20,000個(gè)數(shù)據(jù)的列表,并通過(guò)8個(gè)列舉值的列表來(lái)采取行動(dòng)。這個(gè)場(chǎng)景是夜魘上天輝高地,我們選中冰女,可以發(fā)現(xiàn),冰女腳下的9×9小方格表示她可以前進(jìn)位置,其中白色目標(biāo)方塊的坐標(biāo)是(-300,0)。大方框表示可以放Nova地方,目標(biāo)分別是投石車(chē)、小兵、毒龍、巫妖、瘟疫法師和另一個(gè)冰女。
OpenAI Five可以就自己觀察到的內(nèi)容對(duì)缺失信息做出反應(yīng)。例如火槍的一技能是榴霰彈,這是一個(gè)范圍傷害,雖然除了星際玩家以外的正常玩家都看得到這個(gè)區(qū)域,但它并不屬于OpenAI Five的觀察范圍。即便“看不到”,每當(dāng)AI走進(jìn)霰彈區(qū)時(shí),它們還是會(huì)急著走出來(lái),因?yàn)槟菚r(shí)它們的血量在不斷下降。
探索
既然AI可以學(xué)會(huì)“深謀遠(yuǎn)慮”,那接下來(lái)的問(wèn)題就是環(huán)境探索。前文提到了,OpenAI Five玩的是限制版Dota2,即便少了很多復(fù)雜內(nèi)容,它還有上百種道具、數(shù)十種建筑物、法術(shù)、單位類(lèi)型和游戲機(jī)制要學(xué)習(xí)——其中某些內(nèi)容的組合還會(huì)產(chǎn)生更強(qiáng)大的東西。對(duì)于智能體來(lái)說(shuō),有效探索這個(gè)組合廣闊的空間并不容易。
OpenAI Five的學(xué)習(xí)方法是自我訓(xùn)練(從隨機(jī)參數(shù)開(kāi)始),這就為探索環(huán)境提供了初級(jí)經(jīng)驗(yàn)。為了避免“戰(zhàn)略崩潰”,我們把自我訓(xùn)練分成兩部分,其中80%是AI和自己對(duì)戰(zhàn),剩下20%則是AI和上一版AI對(duì)戰(zhàn)。經(jīng)過(guò)幾個(gè)小時(shí)的訓(xùn)練,帶線、刷錢(qián)、中期抓人等戰(zhàn)略陸續(xù)出現(xiàn)了。幾天后,它們已經(jīng)學(xué)會(huì)了基礎(chǔ)的人類(lèi)戰(zhàn)略:搶對(duì)面的賞金神符,走到己方外塔附近補(bǔ)刀刷錢(qián),不停把英雄送去占線擴(kuò)大優(yōu)勢(shì)。在這個(gè)基礎(chǔ)上,我們做了進(jìn)一步訓(xùn)練,這時(shí),OpenAI Five就已經(jīng)能熟練掌握5人推塔這樣的高級(jí)策略了,
2017年3月,我們的第一個(gè)智能體擊敗了機(jī)器人,卻對(duì)人類(lèi)玩家手足無(wú)措。為了強(qiáng)制在戰(zhàn)略空間進(jìn)行探索,在訓(xùn)練期間(并且只在訓(xùn)練期間),我們隨機(jī)化了它的各項(xiàng)屬性(血量、移速、開(kāi)始等級(jí)等),之后它開(kāi)始能戰(zhàn)勝一些玩家。后來(lái),它又在另一名測(cè)試玩家身上屢戰(zhàn)屢敗,我們就又增加了隨機(jī)訓(xùn)練,AI變強(qiáng)了,那名玩家也開(kāi)始輸了。
OpenAI Five使用了我們之前為1v1智能體編寫(xiě)的隨機(jī)數(shù)據(jù),它也啟用了一種新的“分路”方法。在每次訓(xùn)練比賽開(kāi)始時(shí),我們隨機(jī)地將每個(gè)英雄“分配”給一些線路子集,并對(duì)其進(jìn)行懲罰以避開(kāi)這幾路。
上述探索自然離不開(kāi)回報(bào)的指引。我們?yōu)镈ota2設(shè)計(jì)的回報(bào)機(jī)制基于人類(lèi)玩家對(duì)行為的具體評(píng)判:團(tuán)隊(duì)作用、技能施放、死亡次數(shù)、助攻次數(shù)和擊殺次數(shù)等。為了防止智能體鉆漏洞,我們的方法是計(jì)算另一隊(duì)的平均表現(xiàn),然后用本隊(duì)英雄表現(xiàn)減去這個(gè)值來(lái)具體評(píng)判。
英雄的技能點(diǎn)法、裝備和信使管理都從腳本導(dǎo)入。
團(tuán)隊(duì)合作
Dota2是個(gè)團(tuán)隊(duì)合作游戲,但OpenAI Five的5名英雄間不存在神經(jīng)網(wǎng)絡(luò)上的明確溝通渠道。他們的團(tuán)隊(duì)合作由一個(gè)名為“team spirit”的超參數(shù)控制,范圍是0到1,由它給每個(gè)英雄的加權(quán),讓它們知道這時(shí)是團(tuán)隊(duì)利益更重要還是個(gè)人刷錢(qián)更重要。
Rapid
這個(gè)AI是在我們的強(qiáng)化學(xué)習(xí)訓(xùn)練系統(tǒng)Rapid上實(shí)現(xiàn)的,后者可以應(yīng)用于Gym環(huán)境庫(kù)。我們已經(jīng)用Rapid解決了OpenAI的許多其他問(wèn)題,比如Competitive Self-Play。
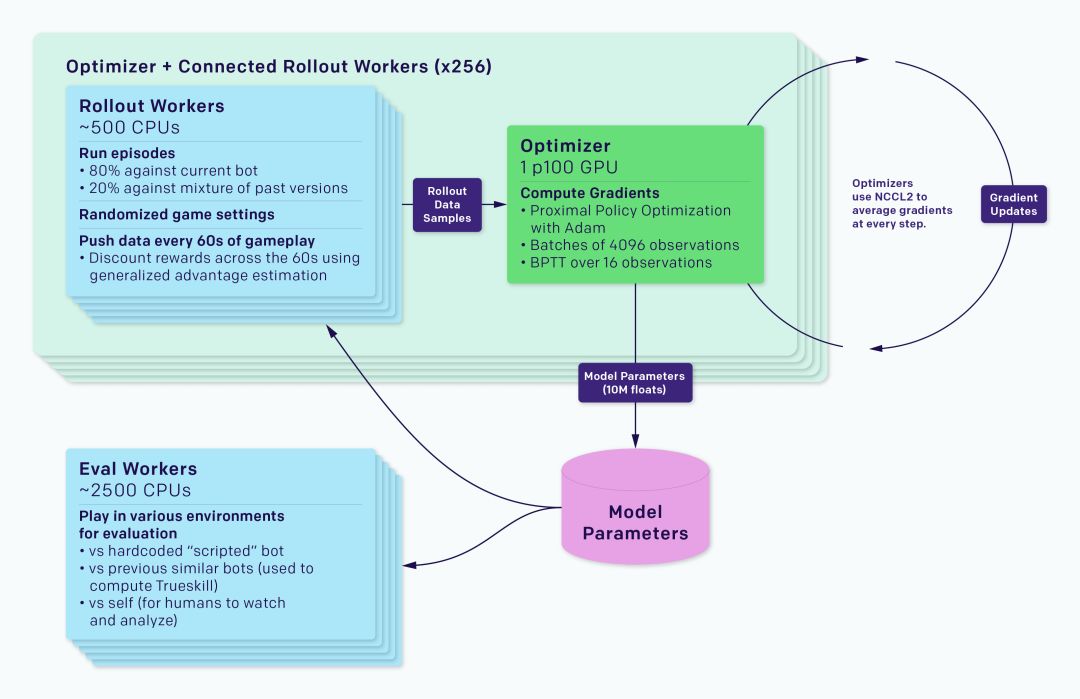
整個(gè)訓(xùn)練系統(tǒng)被分為rollout workers和optimizer兩部分,其中前者運(yùn)行一個(gè)游戲副本,并用一個(gè)智能體收集經(jīng)驗(yàn),后者則在一系列GPU中執(zhí)行同步梯度下降。rollout workers通過(guò)Redis跟optimizer同步經(jīng)驗(yàn)。如上圖所示,每個(gè)實(shí)驗(yàn)還包括一個(gè)Eval workers的過(guò)程,它的作用是評(píng)估經(jīng)過(guò)訓(xùn)練的智能體和參考智能體。除此之外還有一些監(jiān)控軟件,如TensorBoard、Sentry和Grafana。
在同步梯度下降過(guò)程中,每個(gè)GPU在各自batch計(jì)算梯度,然后再對(duì)梯度進(jìn)行全局平均。我們最初使用MPI的allreduce進(jìn)行平均,但現(xiàn)在用我們自己的NCCL2封裝來(lái)并行GPU計(jì)算和網(wǎng)絡(luò)數(shù)據(jù)傳輸。
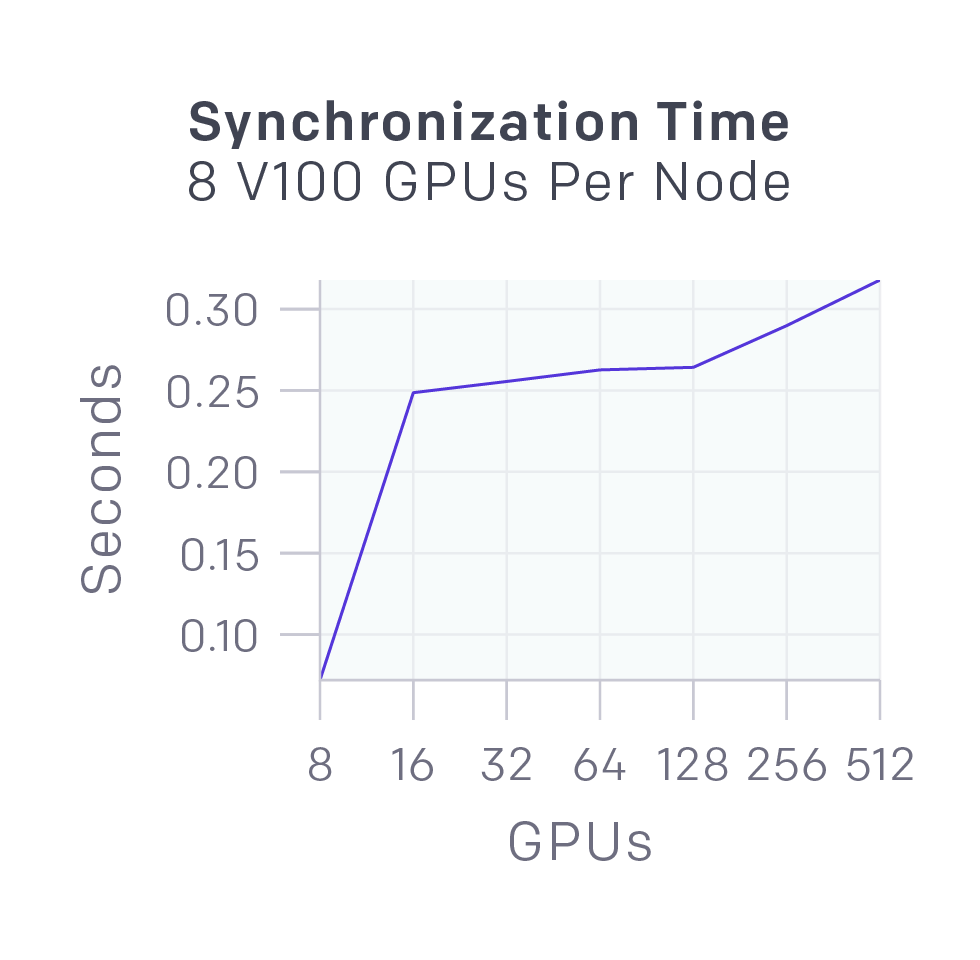
上圖顯示了不同數(shù)量的GPU同步58MB數(shù)據(jù)(OpenAI Five參數(shù))的延遲,幾乎可以被并行運(yùn)行的GPU計(jì)算所掩蓋。
我們還為Rapid開(kāi)發(fā)了Kubernetes、Azure和GCP后端。
游戲
到目前為止,OpenAI Five已經(jīng)在限制版Dota2中獲得了非常輝煌的戰(zhàn)績(jī):
頂級(jí)OpenAI員工隊(duì)伍:天梯分2500+(前46%玩家)
觀看比賽的最強(qiáng)觀眾隊(duì)(包括解說(shuō)Blitz):天梯分4000-6000(前90-99%玩家)——非開(kāi)黑
V社員工隊(duì)伍:天梯分2500-4000(前46-90%玩家)
業(yè)余選手隊(duì)伍:天梯分4200(前93%玩家)——開(kāi)黑隊(duì)
半職業(yè)隊(duì):天梯分5500(前99%玩家)——開(kāi)黑隊(duì)
4月23日,OpenAI Five首次擊敗機(jī)器人腳本;5月15日,它在和OpenAI員工隊(duì)的較量中1勝1負(fù),首次戰(zhàn)勝人類(lèi)玩家;6月6日,它突破OpenAI隊(duì)、觀眾隊(duì)和V社隊(duì)的封鎖,決定性地贏得了所有的比賽。之后我們又和業(yè)余隊(duì)、半職業(yè)隊(duì)進(jìn)行了非正式比賽,OpenAI Five沒(méi)有像預(yù)想中那樣一敗涂地,而是在和兩個(gè)隊(duì)的前三場(chǎng)比賽中都贏了兩場(chǎng)。
這些AI機(jī)器人的團(tuán)隊(duì)合作幾乎是壓倒性的,它們就像5個(gè)無(wú)私的玩家,知道最好的總體戰(zhàn)略。——Blitz
我們也從OpenAI Five的比賽中觀察到了一些東西:
它們會(huì)為了搶奪敵方優(yōu)勢(shì)路舍棄自家優(yōu)勢(shì)路(天輝的下路和夜魘的上路),使對(duì)方無(wú)力回防。這種戰(zhàn)略近幾年常出現(xiàn)在職業(yè)隊(duì)伍比賽中,解說(shuō)Blitz也稱(chēng)自己是從液體(李逵)那里得知這點(diǎn)的。
推動(dòng)局勢(shì)轉(zhuǎn)變,比對(duì)面更快地把戰(zhàn)局從前期推進(jìn)中期。這樣做的具體方法是:(1)如下圖所示,成功的gank;(2)在對(duì)面抱團(tuán)后,及時(shí)反制。
它們?cè)谏贁?shù)領(lǐng)域背離了目前的游戲風(fēng)格,比如AI前期會(huì)給輔助更多經(jīng)驗(yàn)和錢(qián),讓它們?cè)趶?qiáng)勢(shì)期打足傷害,擴(kuò)大局面優(yōu)勢(shì),打贏團(tuán)戰(zhàn),然后抓住對(duì)方失誤快速致勝。
AI和人類(lèi)的差別
OpenAI Five可以觀察的信息和人類(lèi)玩家相同,游戲里有什么數(shù)據(jù),它就看到什么數(shù)據(jù)。比如玩家需要手動(dòng)去檢查英雄位置、血量情況和身上的裝備。我們的方法并沒(méi)有從根本上與觀察狀態(tài)相關(guān)聯(lián),但僅從游戲渲染像素看,它就需要數(shù)千個(gè)GPU。
對(duì)于許多人關(guān)心的APM問(wèn)題,OpenAI Five只有150-170(每4幀一次動(dòng)作,理論上最高有450)。但需要注意的是,這150是有效操作,不是逛街和打字嘲諷,它的平均反應(yīng)時(shí)間為80ms,比人類(lèi)快。
這兩個(gè)差異在1v1中最為重要,但在比賽中,我們發(fā)現(xiàn)人類(lèi)玩家可以輕松適跟上AI的節(jié)奏,所以雙方競(jìng)技還是比較公平的。事實(shí)上去年Ti7期間,一些職業(yè)玩家也和我們的1v1 AI做了多次訓(xùn)練,根據(jù)Blitz的說(shuō)法,1v1 AI改變了人們對(duì)1v1的看法(AI采用了快節(jié)奏的游戲風(fēng)格,現(xiàn)在每個(gè)人都適應(yīng)了)。
令人驚訝的發(fā)現(xiàn)
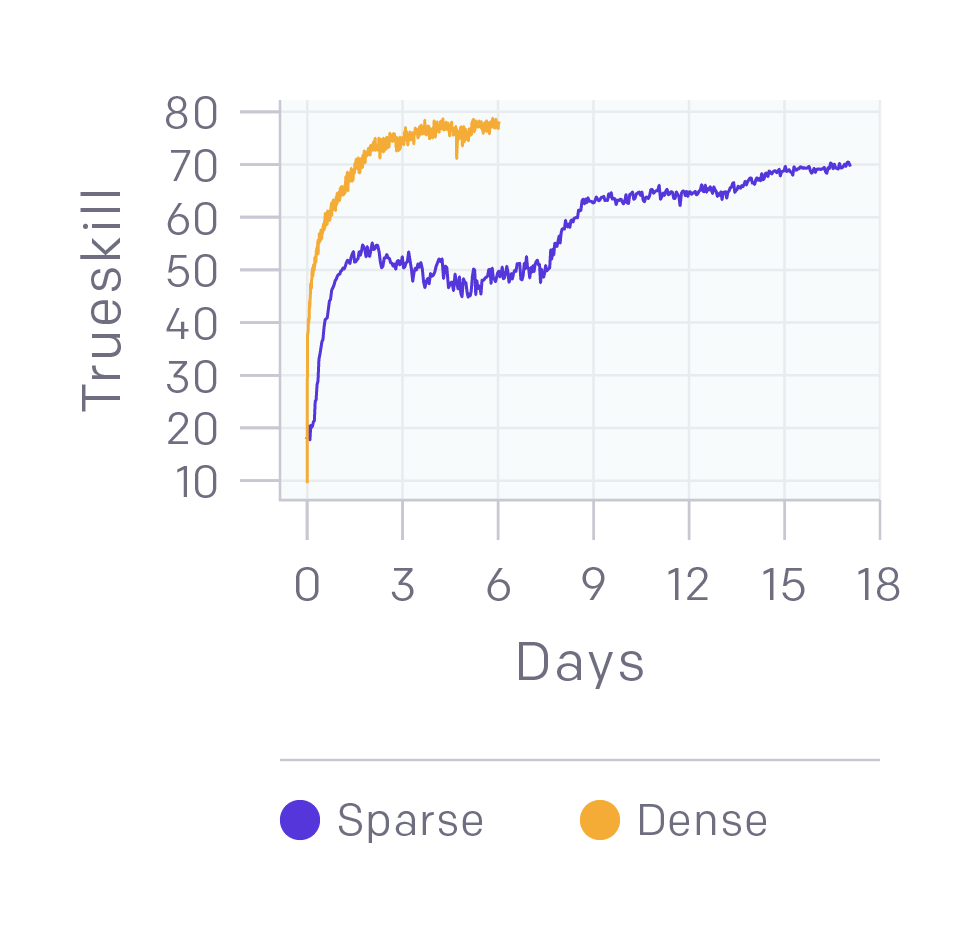
二元回報(bào)能夠提供良好的表現(xiàn)。1v1模型的回報(bào)是多尺度的,包括擊殺英雄、連續(xù)擊殺等。我們做了一個(gè)實(shí)驗(yàn),讓智能體只能從輸贏中獲得回報(bào)。如上圖所示,和常見(jiàn)的平滑曲線(黃線)相比,雖然它(紫線)在訓(xùn)練中期出現(xiàn)了一個(gè)較慢并且稍微平穩(wěn)的階段,但它的訓(xùn)練結(jié)果和黃線很接近。這個(gè)實(shí)驗(yàn)用了4,500個(gè)CPU和16個(gè)k80 GPU,模型性能達(dá)到半專(zhuān)業(yè)級(jí)(70個(gè)TrueSkill),而我們的1v1模型是90個(gè)TrueSkill。
可以自學(xué)卡兵。在去年的1v1模型中,我們獨(dú)立訓(xùn)練模型卡兵,并附加一個(gè)“卡兵塊”獎(jiǎng)勵(lì)。我們團(tuán)隊(duì)的一名員工在訓(xùn)練2v2模型時(shí),因?yàn)橐菁伲谑墙ㄗh他(現(xiàn)在的)妻子看看要花多久才能提高性能。令人驚訝的是,這個(gè)模型居然在沒(méi)有任何特殊指引和回報(bào)激勵(lì)的情況下得出了卡兵會(huì)產(chǎn)生優(yōu)勢(shì)的結(jié)論。
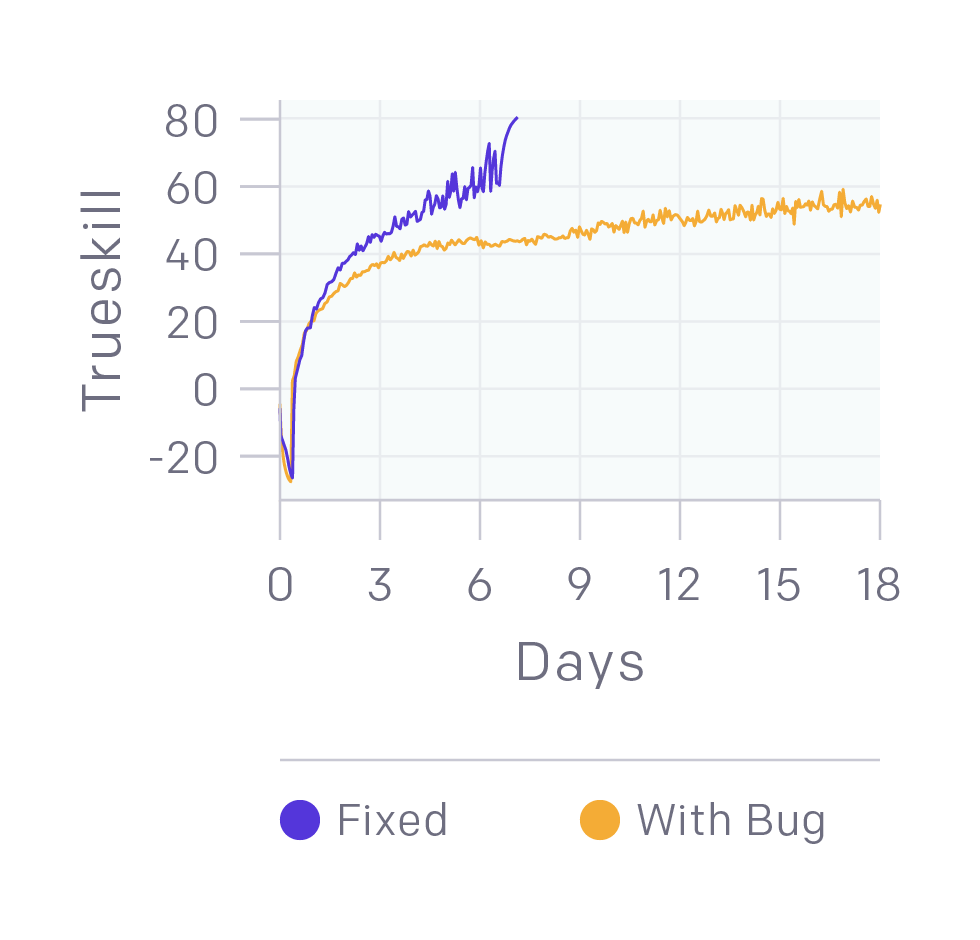
我們?nèi)栽谛迯?fù)錯(cuò)誤。上圖中的黃線模型已經(jīng)可以擊敗業(yè)余玩家,但修復(fù)了一些Bug后,它的提升非常明顯。這給我們帶來(lái)的啟示是即便已經(jīng)擊敗更強(qiáng)的人類(lèi)玩家,我們的模型還是可能隱藏著嚴(yán)重錯(cuò)誤。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4811瀏覽量
103053 -
AI
+關(guān)注
關(guān)注
88文章
34589瀏覽量
276253 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11535
原文標(biāo)題:一文解析OpenAI Five,一個(gè)會(huì)打團(tuán)戰(zhàn)的Dota2 AI
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論