") 攝像頭相關(guān)的人工智能研究成果
攝像頭相關(guān)的人工智能研究成果
本文來(lái)自馭勢(shì)科技人工智能組組長(zhǎng)潘爭(zhēng)在LiveVideoStackCon 2017大會(huì)上的分享,并由LiveVideoStack整理而成。潘爭(zhēng)回顧了AI在圖像識(shí)別領(lǐng)域的歷史與難點(diǎn),以及在安防和自動(dòng)駕駛方面的實(shí)現(xiàn)思路。
谷歌的人工智能平臺(tái)Alpha Go讓AI再次進(jìn)入了普通老百姓的視野,我記得2016年3月時(shí)Alpha Go第一輪測(cè)試結(jié)果就令大家十分震驚。隨著技術(shù)的進(jìn)步,AI的能力一定會(huì)越來(lái)越強(qiáng)。我們可以看到近兩年AI在深度學(xué)習(xí)方面的技術(shù)進(jìn)展成果顯著。今天我為大家準(zhǔn)備了一些最近與攝像頭相關(guān)的人工智能研究成果。
概覽:
攝像頭里的數(shù)據(jù)寶藏
視覺(jué)識(shí)別的挑戰(zhàn)與應(yīng)對(duì)
AI+安防實(shí)踐
AI+自動(dòng)駕駛實(shí)踐

今天我的分享內(nèi)容主要分為以下幾點(diǎn):第一是我們生活中的這些攝像頭所采集的數(shù)據(jù)中隱藏了哪些值得挖掘的寶藏,以及如果要去挖掘有價(jià)值的數(shù)據(jù)需要面臨的一些挑戰(zhàn)與應(yīng)對(duì)的方法;第二是我在安防與自動(dòng)駕駛領(lǐng)域應(yīng)用AI的一些實(shí)踐經(jīng)驗(yàn)。
1. 攝像頭里的數(shù)據(jù)寶藏
大家可以設(shè)想一下自己周?chē)卸嗌儆^察我們的攝像頭,有我們隨身攜帶的手機(jī)、平板電腦等移動(dòng)設(shè)備的前后攝像頭;如果你開(kāi)車(chē),你的車(chē)至少會(huì)有一兩個(gè)攝像頭;當(dāng)你走在大街上或商場(chǎng)、超市里時(shí),隨便一抬頭都能看到一個(gè)監(jiān)控?cái)z像頭。可以說(shuō)我們的生活布滿(mǎn)了攝像頭,其中記錄了我們生活一點(diǎn)一滴的數(shù)據(jù)便具有了非凡價(jià)值。例如商場(chǎng)的管理人員可通過(guò)攝像頭判斷此時(shí)商場(chǎng)里有多少顧客,大致掌握顧客的男女比例,年齡層次,從而掌握潛在消費(fèi)群體的實(shí)時(shí)動(dòng)向;也可以通過(guò)攝像頭搜尋經(jīng)常前來(lái)消費(fèi)的顧客,并在正確的位置精準(zhǔn)投放相應(yīng)廣告吸引其消費(fèi)從而增加銷(xiāo)售額。而在安防領(lǐng)域,警察可通過(guò)安裝在街道上的攝像頭監(jiān)控預(yù)防群體事件的發(fā)生,迅速識(shí)別定位逃犯并掌握其逃跑路徑從而實(shí)現(xiàn)快速抓捕。還有在自動(dòng)駕駛領(lǐng)域,通過(guò)汽車(chē)上集成的多部攝像頭獲取的數(shù)據(jù)可以告訴自動(dòng)駕駛系統(tǒng)周?chē)?chē)的數(shù)量、相對(duì)速度與距離等,也可識(shí)別車(chē)道線位置,推斷汽車(chē)是否偏離車(chē)道,并在需要變道或剎車(chē)時(shí)及時(shí)作出反應(yīng),保障自動(dòng)駕駛系統(tǒng)的正常運(yùn)行。從攝像頭中發(fā)掘有價(jià)值的數(shù)據(jù)并加以有效利用,無(wú)論對(duì)安防領(lǐng)域還是自動(dòng)駕駛領(lǐng)域而言都非常重要。當(dāng)然數(shù)據(jù)挖掘與處理的過(guò)程也充滿(mǎn)挑戰(zhàn)。
2. 視覺(jué)識(shí)別問(wèn)題中的挑戰(zhàn)與應(yīng)對(duì)
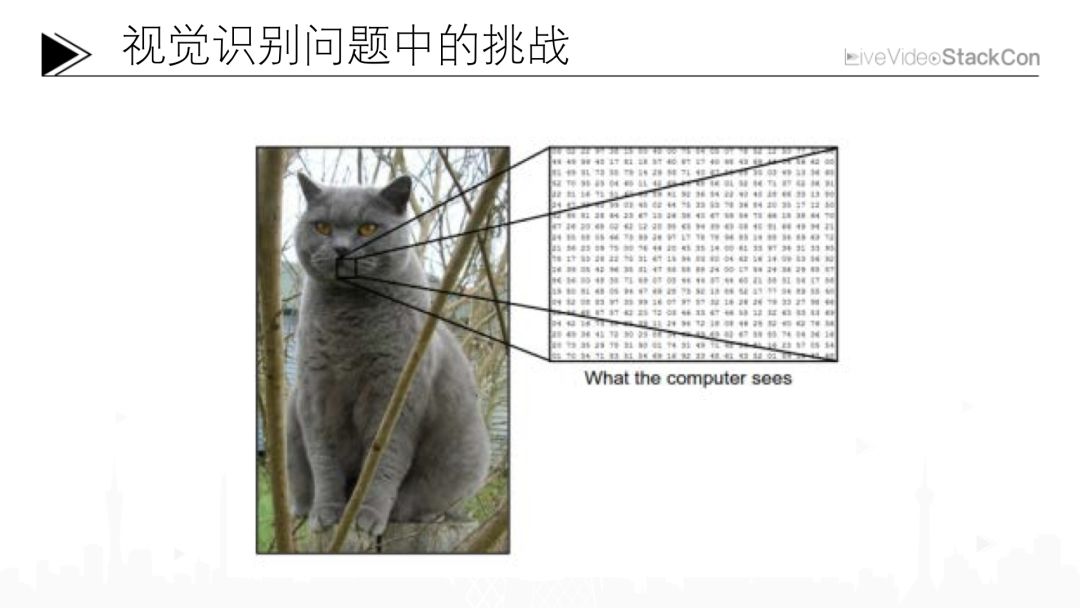
例如上面的這張圖,也許一個(gè)三歲的小孩也能夠識(shí)別出圖片中的物體是一只貓,而對(duì)計(jì)算機(jī)來(lái)說(shuō),這張圖可能只是一系列的數(shù)字。如果我們想通過(guò)這一系列的數(shù)字識(shí)別出這是一只貓則可能會(huì)遇到非常多的挑戰(zhàn)。
挑戰(zhàn)1:視角變化
而隨著視角的變化,例如上圖的同一張人臉會(huì)呈現(xiàn)出非常明顯的差異
挑戰(zhàn)2:光影變化
光影的變化同樣至關(guān)重要,由于光源位置的不同,同樣的幾只企鵝,有可能是全黑的,也有可能是全白的,這對(duì)視覺(jué)識(shí)別也非常具有挑戰(zhàn)性。
挑戰(zhàn)3:尺度變化
姚明與小孩雖存在明顯的尺度差異,但都屬于人類(lèi)。視覺(jué)識(shí)別系統(tǒng)必須能夠?qū)Σ煌叨鹊奈矬w準(zhǔn)確進(jìn)行歸類(lèi)。
挑戰(zhàn)4:形狀變化
處于不同形態(tài)的同一物體同樣是識(shí)別的難點(diǎn),例如無(wú)論“大黃蜂”處于汽車(chē)形態(tài)還是機(jī)器人形態(tài),視覺(jué)識(shí)別系統(tǒng)都應(yīng)將其識(shí)別成“大黃蜂”。
挑戰(zhàn)5:遮擋變化
更大的挑戰(zhàn)在于很多視覺(jué)識(shí)別都需要面臨的遮擋變化,我們必須保證在復(fù)雜環(huán)境的遮擋下仍能夠準(zhǔn)確識(shí)別圖片中的一匹馬與騎馬的人。
挑戰(zhàn)6:背景干擾
還需要解決的是背景干擾問(wèn)題,我們可以輕易識(shí)別出上圖中的人與金錢(qián)豹,但對(duì)計(jì)算機(jī)而言,因?yàn)槟繕?biāo)主體的紋理與背景幾乎難以分別,能夠準(zhǔn)確識(shí)別出同樣結(jié)果的難度非常大。
挑戰(zhàn)7:類(lèi)內(nèi)差距
最后一項(xiàng)挑戰(zhàn)是類(lèi)內(nèi)差距,雖然都是椅子,但設(shè)計(jì)與用處的不同使其外觀差距非常大,而我們希望視覺(jué)識(shí)別算法都能將其識(shí)別為一張椅子。
如何有效解決視覺(jué)識(shí)別領(lǐng)域上述這么多挑戰(zhàn)?
2.1 深度學(xué)習(xí)——卷積神經(jīng)網(wǎng)絡(luò)

如果讓大家完成這樣一個(gè)Python函數(shù),輸入一張圖片的數(shù)據(jù),輸出我們期望得到的圖片類(lèi)型,該如何完成?其實(shí)這個(gè)問(wèn)題已經(jīng)困擾了計(jì)算機(jī)視覺(jué)科學(xué)家大概半個(gè)多世紀(jì)的時(shí)間,從計(jì)算機(jī)被發(fā)明開(kāi)始大家就在思考這個(gè)問(wèn)題,直到最近幾年才有了一個(gè)比較正式的回答,就是我們經(jīng)常提到的深度學(xué)習(xí),具體來(lái)說(shuō)是一個(gè)多層卷積神經(jīng)網(wǎng)絡(luò)。上圖展示了這樣一個(gè)卷積神經(jīng)網(wǎng)絡(luò)的例子,在卷積神經(jīng)網(wǎng)絡(luò)的左邊輸入的是一張圖像的數(shù)據(jù),右邊輸出的是我們期待的圖像所屬類(lèi)別。在這個(gè)網(wǎng)絡(luò)中我們可以看到每一個(gè)藍(lán)色的方框都代表一次卷積操作,之所以叫它多層卷積神經(jīng)網(wǎng)絡(luò)就是因?yàn)橐粡垐D片從輸入原始數(shù)據(jù)到輸出對(duì)應(yīng)類(lèi)別需要經(jīng)過(guò)多次卷積操作,像這個(gè)網(wǎng)絡(luò)需要經(jīng)過(guò)22層卷積才能準(zhǔn)確識(shí)別出圖像所屬的類(lèi)別屬性。每個(gè)卷積都會(huì)有一個(gè)卷積核,這個(gè)卷積核就是我們希望從海量數(shù)據(jù)中學(xué)習(xí)到的參數(shù),學(xué)習(xí)不同的任務(wù)可以得出不同的參數(shù)。而這個(gè)學(xué)習(xí)訓(xùn)練的算法一般是根據(jù)具體任務(wù)通過(guò)使用反向傳播算法進(jìn)行精準(zhǔn)識(shí)別并去學(xué)習(xí)出每一個(gè)卷積核的對(duì)應(yīng)參數(shù)來(lái)。那么這樣一個(gè)卷積神經(jīng)網(wǎng)絡(luò)可以達(dá)到怎樣的圖像識(shí)別性能呢?

這個(gè)問(wèn)題也是在近幾年才有了一個(gè)比較好的回答,我給大家舉個(gè)例子: ImageNet比賽是一項(xiàng)解決通用圖像識(shí)別分類(lèi)問(wèn)題的比賽,通過(guò)統(tǒng)計(jì)計(jì)算機(jī)識(shí)別并歸類(lèi)數(shù)據(jù)集中一千類(lèi)圖片的錯(cuò)誤率來(lái)衡量其視覺(jué)識(shí)別能力的高低。人如果參加ImageNet,錯(cuò)誤率會(huì)保持在5.1%左右。而在深度學(xué)習(xí)面世之前的2011年,ImageNet冠軍的錯(cuò)誤率可達(dá)到25.8%,但在2012深度學(xué)習(xí)面世以后,ImageNet冠軍的錯(cuò)誤率一下降到了16.4%,并且從那之后一直處于直線下降的狀態(tài),直到2015年的正確率已經(jīng)下降到比人還低的3.57%。在人工智能的圍棋還未超越人類(lèi)的2015年,計(jì)算機(jī)在通用圖像識(shí)別領(lǐng)域的性能已經(jīng)超越了人類(lèi),能達(dá)到這樣的成績(jī),卷積神經(jīng)網(wǎng)絡(luò)功不可沒(méi)。
2.2 進(jìn)一步發(fā)展的卷積神經(jīng)網(wǎng)絡(luò)
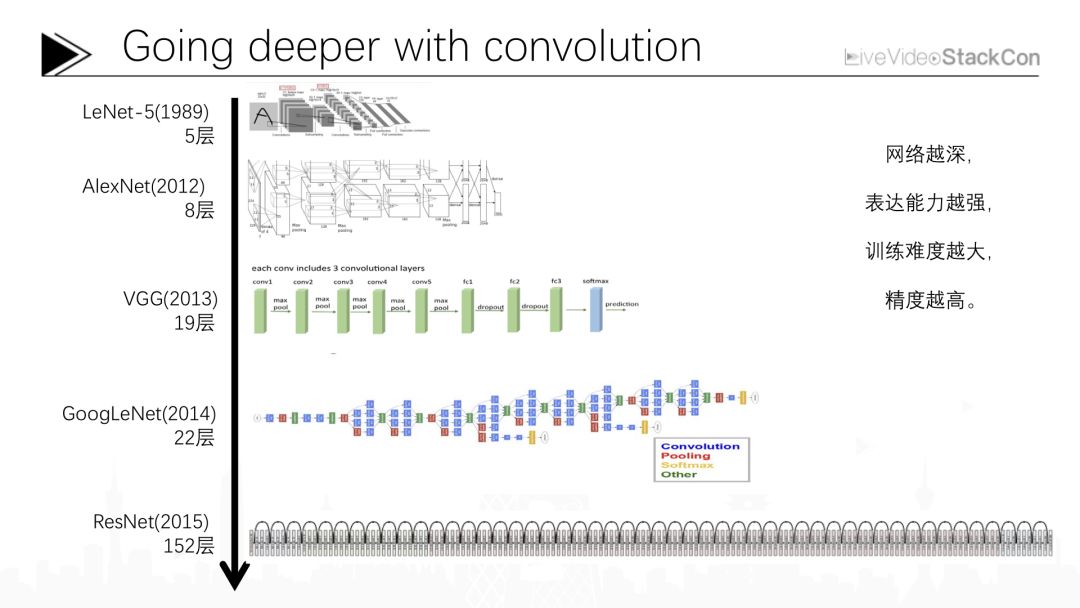
上圖是近幾年我們常用的深度卷積神經(jīng)網(wǎng)絡(luò)的大概結(jié)構(gòu),深度卷積神經(jīng)網(wǎng)絡(luò)最早是由Yann LeCun在1989年提出,當(dāng)時(shí)是一個(gè)僅有5層的卷積神經(jīng)網(wǎng)絡(luò),現(xiàn)在Yann LeCun在Facebook的人工智能研究院作為主任繼續(xù)推進(jìn)卷積神經(jīng)網(wǎng)絡(luò)的研究。最初卷積神經(jīng)網(wǎng)絡(luò)的層數(shù)非常的淺,僅有5層,并且那時(shí)只能完成一些手寫(xiě)體方面的簡(jiǎn)單識(shí)別任務(wù)。在那之后人們對(duì)卷積神經(jīng)網(wǎng)絡(luò)的研究持續(xù)了二十多年,一直到2012年,人們才提出能夠勝任像ImageNet這樣復(fù)雜識(shí)別任務(wù)的更先進(jìn)的卷積神經(jīng)網(wǎng)絡(luò)。AlexNet在2012年借助這樣一個(gè)8層的卷積神經(jīng)網(wǎng)絡(luò)網(wǎng)絡(luò)成為當(dāng)年ImageNet比賽的冠軍,從那之后,又有很多不同的卷積神經(jīng)網(wǎng)絡(luò)被研發(fā)出來(lái),總的趨勢(shì)是越來(lái)越深。例如2013年達(dá)到19層的VGG、2014年Google提出的達(dá)到22層的GoogLeNet,而2015年微軟亞洲研究院研制的多達(dá)152層的卷積神經(jīng)網(wǎng)絡(luò)ResNet其圖像識(shí)別性能已超越人類(lèi)。從卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展我們不難看出,網(wǎng)絡(luò)越深其表達(dá)能力越強(qiáng),卷積神經(jīng)網(wǎng)絡(luò)所能表達(dá)的數(shù)學(xué)函數(shù)復(fù)雜程度就會(huì)越高,這就使其在處理復(fù)雜圖象識(shí)別任務(wù)時(shí)能夠達(dá)到更高的正確率。當(dāng)然隨著網(wǎng)絡(luò)加深增多的是卷積盒的參數(shù),對(duì)應(yīng)計(jì)算量與深度學(xué)習(xí)的訓(xùn)練難度也會(huì)增大,接下來(lái)我將講述近幾年大家在研究深度學(xué)習(xí)時(shí)面臨的三項(xiàng)核心問(wèn)題以及提出的一些能夠解決相應(yīng)問(wèn)題的算法思想。
2.3 視覺(jué)問(wèn)題的深度學(xué)習(xí)方法

之前提到的ImageNet比賽是一個(gè)通用的模擬圖像識(shí)別與分類(lèi)的比賽,并不解決實(shí)際問(wèn)題。與圍棋類(lèi)似,并不能為我們創(chuàng)造任何經(jīng)濟(jì)價(jià)值。如果想應(yīng)用于實(shí)際中的視覺(jué)識(shí)別情景則還需解決以下幾大類(lèi)問(wèn)題:語(yǔ)義分割、物體檢測(cè)、對(duì)比驗(yàn)證。
2.3.1 語(yǔ)義分割
圖像分類(lèi)問(wèn)題需要識(shí)別一張圖片并告訴我們這張圖片中物體的類(lèi)別,簡(jiǎn)而言之就是輸入一張圖片,給出一個(gè)類(lèi)別。語(yǔ)義分割就是希望針對(duì)一張圖片中的每個(gè)像素都輸出一個(gè)類(lèi)別,其中有很多解決方案,例如這幾年提出的FCN、Enet、PSPNet或ICnet等等。這些方法背后的基本框架都是全卷積網(wǎng)絡(luò)。這里的全卷積網(wǎng)絡(luò)與剛才提到的分類(lèi)網(wǎng)絡(luò)唯一不同之處在于全卷積網(wǎng)絡(luò)并不只輸出一個(gè)分類(lèi)標(biāo)簽,而是輸出多個(gè)分類(lèi)結(jié)果,每個(gè)分類(lèi)結(jié)果都對(duì)應(yīng)了圖像中的一個(gè)像素的類(lèi)型值。訓(xùn)練時(shí)會(huì)對(duì)每個(gè)像素分類(lèi)的結(jié)果進(jìn)行誤差計(jì)算,并用反向傳播算法得出訓(xùn)練后的網(wǎng)絡(luò)參數(shù)。
2.3.2 物體檢測(cè)
初期的物體檢測(cè)準(zhǔn)確率很低,無(wú)法滿(mǎn)足應(yīng)用需求。近幾年隨著Faster RCNN、RFCN、SSD等方法的出現(xiàn),物體檢測(cè)的準(zhǔn)確率已經(jīng)基本達(dá)到實(shí)際應(yīng)用的需求。以上這些基于深度學(xué)習(xí)的物體檢測(cè)方法同樣使用全卷積網(wǎng)絡(luò)來(lái)預(yù)測(cè)出物體的每一個(gè)位置,在推斷出此區(qū)域是否屬于某個(gè)物體的同時(shí)對(duì)物體的類(lèi)別、位置與大小進(jìn)行預(yù)測(cè)。與之前的預(yù)測(cè)相比,物體檢測(cè)增加了位置與大小兩個(gè)預(yù)測(cè)維度。如果對(duì)這樣的預(yù)測(cè)的結(jié)果還不滿(mǎn)意的話也可像Faster RCNN這樣將相應(yīng)區(qū)域的圖片或特性分離出并再過(guò)一次網(wǎng)絡(luò)進(jìn)行第二次的分類(lèi)與回歸,這種對(duì)目標(biāo)的多重計(jì)算有助于提升輸出結(jié)果的準(zhǔn)確性。目前最好的物體檢測(cè)方法就是類(lèi)似于Faster RCNN這樣分兩階段的方法,如果大家想嘗試這種物體檢測(cè)方面的應(yīng)用也可從此方法開(kāi)始。
2.3.3 對(duì)比驗(yàn)證
對(duì)比驗(yàn)證簡(jiǎn)單來(lái)說(shuō)就是對(duì)兩個(gè)圖像進(jìn)行對(duì)比并推斷這兩個(gè)圖像是否為同一個(gè)類(lèi)別,最簡(jiǎn)單的應(yīng)用就是人臉識(shí)別。例如借助計(jì)算機(jī)將手機(jī)拍攝的一張人像照片與一張身份證上的照片進(jìn)行對(duì)比并推斷是否為同一個(gè)人。這項(xiàng)技術(shù)在淘寶、支付寶等平臺(tái)都有應(yīng)用,也可用與跟蹤和ReID等方面。這里的跟蹤是指用一個(gè)攝像頭拍攝連續(xù)多幀照片后,識(shí)別并鎖定第一幀里的某個(gè)物體,然后跟蹤后續(xù)幀中這個(gè)物體的移動(dòng)軌跡。
如果這些用于跟蹤物體的圖片來(lái)自不同的攝像頭,那么這就變成了一個(gè)ReID問(wèn)題。ReID在安防領(lǐng)域是一個(gè)非常重要的應(yīng)用,例如一個(gè)小偷在A攝像頭下作案時(shí)被拍攝圖像后,我希望根據(jù)這張圖像在其他攝像頭中搜尋并鎖定這個(gè)小偷,以此來(lái)推測(cè)其作案移動(dòng)的路徑,毫無(wú)疑問(wèn)這會(huì)為警方的刑偵破案提供很大幫助。無(wú)論是人臉識(shí)別還是RelD,其技術(shù)背景都是Siamese network。
它的原理很簡(jiǎn)單,就是將兩張圖片經(jīng)過(guò)同一個(gè)網(wǎng)絡(luò)提取特征。在訓(xùn)練此網(wǎng)絡(luò)時(shí)我們希望盡量縮小同一張人臉照片輸出結(jié)果的差距,擴(kuò)大不同人臉照片輸出結(jié)果的差距。通過(guò)這種訓(xùn)練方式能夠讓網(wǎng)絡(luò)學(xué)習(xí)到如何分析比對(duì)同一張人臉具有什么相似的特征,不同的人臉具有什么不同的特征。在人臉識(shí)別方面,計(jì)算機(jī)更早地超過(guò)人類(lèi)。大概2013年在LFW人臉驗(yàn)證比賽上,人類(lèi)對(duì)于臉部的識(shí)別驗(yàn)證準(zhǔn)確率在97%左右,而計(jì)算機(jī)已可達(dá)到99%以上,這無(wú)疑是深度學(xué)習(xí)在人臉驗(yàn)證領(lǐng)域的突破。
之前我與大家分享的都是一些籠統(tǒng)的方法,接下來(lái)我會(huì)結(jié)合過(guò)去我在安防與自動(dòng)駕駛領(lǐng)域的工作經(jīng)驗(yàn)為大家介紹一些研究成果,
3. AI+安防
首先說(shuō)一下安防,在安防領(lǐng)域有以下幾類(lèi)大家比較關(guān)心的問(wèn)題。第一個(gè)問(wèn)題是通過(guò)攝像頭確認(rèn)目標(biāo)的位置也就是“人在哪里?”。知道人在哪里之后就需要明確目標(biāo)屬性“你是誰(shuí)?”、“你從哪里來(lái)?”、“你要到哪里去?”這些看似充滿(mǎn)哲學(xué)意味的問(wèn)題同樣也是安防領(lǐng)域最重要的三個(gè)問(wèn)題。回答這三個(gè)問(wèn)題之后我們還希望確認(rèn)目標(biāo)的行為特征“人做了什么?”這對(duì)安防領(lǐng)域而言同樣重要。接下來(lái)讓我們看一下,如何解決這幾個(gè)問(wèn)題。
3.1 “人在哪里?”
首先我們需要確認(rèn)“人在哪里?”。安防領(lǐng)域中最基礎(chǔ)的便是對(duì)物體的檢測(cè),例如上圖展示了一個(gè)在安防場(chǎng)景里進(jìn)行人物檢測(cè)的實(shí)例。我們使用類(lèi)似Faster RCNN技術(shù)對(duì)這樣一個(gè)安防場(chǎng)景中人的上半身進(jìn)行檢測(cè),檢測(cè)上半身主要是因?yàn)槿俗钪匾奶卣骷性谏习肷恚掳肷斫?jīng)常會(huì)被其他物體遮擋,同理上半身的特征暴露幾率更高,更容易進(jìn)行特征識(shí)別。因?yàn)閭鹘y(tǒng)Faster RCNN方法在識(shí)別速度上處于劣勢(shì),所以我們對(duì)Faster RCNN進(jìn)行了一些簡(jiǎn)化,使其在識(shí)別速度上有了比較大的提升,并且能夠允許我們僅借助移動(dòng)端GPU就可實(shí)現(xiàn)實(shí)時(shí)檢測(cè)的效果。
為了驗(yàn)證此算法的運(yùn)行極限,我們進(jìn)行了一個(gè)規(guī)模更大的實(shí)驗(yàn)。此實(shí)驗(yàn)場(chǎng)景為北京站前廣場(chǎng),這里人流密集,比一般的監(jiān)控場(chǎng)景更復(fù)雜,我們想通過(guò)此實(shí)驗(yàn)測(cè)試我們算法可同時(shí)檢測(cè)人數(shù)的極限。經(jīng)過(guò)測(cè)試我們發(fā)現(xiàn)即便在如此大的場(chǎng)景之下算法依舊能夠較穩(wěn)定地檢測(cè)出場(chǎng)景中中絕大多數(shù)行人,漏檢與誤檢幾率也維持在較低水平。我們?cè)诖_認(rèn)目標(biāo)位置之后需要進(jìn)一步確認(rèn)目標(biāo)的移動(dòng)軌跡與行為動(dòng)機(jī)。
3.2 “人從哪里來(lái),到哪里去?”
上圖是一個(gè)較典型的物體跟蹤實(shí)驗(yàn)情景,我們讓這些群眾演員隨機(jī)游走,通過(guò)深度學(xué)習(xí)方法對(duì)每個(gè)人的運(yùn)動(dòng)軌跡進(jìn)行跟蹤。從左上角的圖中我們可以看到每個(gè)人身上都會(huì)有一個(gè)圈,如果圈的顏色沒(méi)有變化說(shuō)明對(duì)這個(gè)人保持正常的跟蹤狀態(tài)。可以看到利用這種檢測(cè)跟蹤技術(shù)可穩(wěn)定地跟蹤大部分目標(biāo)。借助攝像頭輸出的深度圖,我們還可以如右下角圖片展示的那樣得出每個(gè)人在三維空間中的位置并變換視角進(jìn)行監(jiān)控,或是如在左下角圖片展示的那樣得到一個(gè)俯視的運(yùn)行軌跡,這樣就可得知每個(gè)人在監(jiān)控畫(huà)面當(dāng)中的位置動(dòng)態(tài)變化軌跡。
3.3 “這些人是誰(shuí)?”
跟蹤上每一個(gè)人之后,更重要的是確認(rèn)跟蹤目標(biāo)的身份。安防領(lǐng)域的終極目標(biāo)就是希望明確監(jiān)控畫(huà)面中每個(gè)人的身份信息,而能從一個(gè)人的圖像中獲取到的最明顯的身份特征信息就是人臉。我開(kāi)發(fā)了這樣一項(xiàng)技術(shù)——遠(yuǎn)距離人臉識(shí)別。在上圖展示的大場(chǎng)景中我們可以看到其中大部分人離攝像頭的距離至少有30米~40米,在這樣一個(gè)遠(yuǎn)距離監(jiān)控場(chǎng)景下人臉采到的圖像質(zhì)量會(huì)出現(xiàn)明顯的損失,例如人臉的位姿變化。我們希望借助在這樣一個(gè)不佳的監(jiān)控場(chǎng)景中獲取的人臉圖片與人臉特征庫(kù)中的證件信息進(jìn)行比對(duì)并獲取目標(biāo)人物的身份信息,其原理也是剛才提到的Siamese Network——通過(guò)使用幾千萬(wàn)甚至上億數(shù)據(jù)進(jìn)行訓(xùn)練,得出一個(gè)較為穩(wěn)定的人臉特征并在人臉庫(kù)中檢索出符合此特征的目標(biāo)人物身份信息,從而識(shí)別目標(biāo)身份。
3.4 “這些人在干什么?”
安防領(lǐng)域最后關(guān)心的是目標(biāo)的行為特征“這個(gè)人在干什么?”其本質(zhì)是明確每個(gè)人的各個(gè)關(guān)節(jié)的運(yùn)動(dòng)狀態(tài),我們稱(chēng)之為POSE識(shí)別。雖然POSE識(shí)別看上去并不屬于檢測(cè)、跟蹤或是語(yǔ)義分割的范疇,但我們也可將其歸結(jié)為一種物體檢測(cè),只不過(guò)我們檢測(cè)的不再是人的運(yùn)動(dòng)軌跡,而是檢測(cè)每個(gè)人的脖子、肩膀、肘關(guān)節(jié)等部分的相對(duì)位置,這與之前的物體檢測(cè)相比更為復(fù)雜。近幾年,借助深度學(xué)習(xí)技術(shù),POSE識(shí)別取得了非常明顯的進(jìn)步。微軟Xbox 360上配備的kinect便是通過(guò)可感知深度的攝像頭對(duì)一兩個(gè)人進(jìn)行POSE識(shí)別而現(xiàn)在隨著技術(shù)的發(fā)展,即便僅通過(guò)普通的RGB攝像頭也能實(shí)現(xiàn)對(duì)整個(gè)廣場(chǎng)上多個(gè)目標(biāo)同時(shí)進(jìn)行POSE識(shí)別,這也是近幾年深度學(xué)習(xí)的一個(gè)重要突破。通過(guò)這種實(shí)時(shí)POSE識(shí)別我們不光可識(shí)別每個(gè)人在廣場(chǎng)中的位置、運(yùn)動(dòng)軌跡,還可識(shí)別每個(gè)人的動(dòng)作以及動(dòng)作背后隱藏的人與人之間的關(guān)系,從而在監(jiān)控畫(huà)面中獲取更多有價(jià)值的信息。
4. AI+自動(dòng)駕駛

之前我們講述了AI在安防監(jiān)控領(lǐng)域的一些應(yīng)用,接下來(lái)我會(huì)介紹一些最近正在嘗試的有關(guān)自動(dòng)駕駛方面的實(shí)踐。其實(shí)在自動(dòng)駕駛領(lǐng)域也需要很多攝像頭數(shù)據(jù),我們會(huì)在自動(dòng)駕駛汽車(chē)中安裝多個(gè)攝像頭。傳統(tǒng)汽車(chē)領(lǐng)域車(chē)身上的一兩個(gè)攝像頭主要用來(lái)拍攝汽車(chē)周?chē)沫h(huán)境圖像,而在自動(dòng)駕駛領(lǐng)域則需要更多的攝像頭完成更復(fù)雜的工作。例如特斯拉已經(jīng)在其還無(wú)法完全實(shí)現(xiàn)自動(dòng)駕駛的汽車(chē)上安裝了7個(gè)攝像頭;如果想要實(shí)現(xiàn)真正的自動(dòng)駕駛,為了保證畫(huà)面的無(wú)死角需要安裝更多攝像頭,那么攝像頭采集的數(shù)據(jù)能夠幫助我們做什么呢?很多信息需要通過(guò)攝像頭獲取,例如車(chē)道線、前后左右有無(wú)行人與車(chē)輛等障礙物、紅綠燈識(shí)別、可行駛區(qū)域識(shí)別等都是來(lái)源于通過(guò)攝像捕獲的數(shù)據(jù)。
4.1 車(chē)道線識(shí)別
圖片中展示的車(chē)道線識(shí)別,也許大家曾在一些行車(chē)記錄儀或ADOS中見(jiàn)過(guò)。但有別于傳統(tǒng)對(duì)單車(chē)道線的簡(jiǎn)單標(biāo)記,我們現(xiàn)在更關(guān)注的是多車(chē)道線識(shí)別。以前的車(chē)道線識(shí)別僅是左右各一根,而我們希望能夠識(shí)別一整條馬路上的多根車(chē)道線。這種對(duì)于多根車(chē)道線的識(shí)別,一方面可為處于自動(dòng)駕駛狀態(tài)下的車(chē)輛提供變道、駛出高速等路徑更改操作必要的數(shù)據(jù),另一方面能夠協(xié)助汽車(chē)進(jìn)行橫向定位。如果能夠同時(shí)識(shí)別出所有車(chē)道,自動(dòng)駕駛系統(tǒng)就能確認(rèn)汽車(chē)當(dāng)前在第幾條車(chē)道上,從而計(jì)算下一步需要切換到哪一條車(chē)道,這對(duì)自動(dòng)駕駛而言十分重要。檢測(cè)車(chē)道線可歸結(jié)為對(duì)物體的檢測(cè),大家可以將每條車(chē)道線理解為一個(gè)物體。當(dāng)然在面臨彎曲的車(chē)道線時(shí)還需要估計(jì)每條車(chē)道曲線的參數(shù),需要更多的處理分析以更好地模擬車(chē)道線的變化。
4.2 行人與車(chē)輛檢測(cè)
除了車(chē)道線識(shí)別,另外一個(gè)比較重要的問(wèn)題是對(duì)行人與車(chē)輛的實(shí)時(shí)檢測(cè)。這是安全性上十分重要的兩項(xiàng)指標(biāo),需要知曉周?chē)?chē)輛的位置、距離和速度才能獲取決策所需要的參數(shù)。上圖是我們?cè)诒本┧沫h(huán)這樣相對(duì)簡(jiǎn)單的封閉道路環(huán)境下進(jìn)行的車(chē)輛檢測(cè)實(shí)驗(yàn)。檢測(cè)車(chē)輛的算法與我們之前提到的在安防領(lǐng)域里檢測(cè)人的算法類(lèi)似,都是基于Faster RCNN架構(gòu),但自動(dòng)駕駛領(lǐng)域?qū)τ?jì)算能力的要求更高。因?yàn)槠?chē)的安全永遠(yuǎn)擺在第一位,并且經(jīng)過(guò)每一步計(jì)算更新出的行駛策略必須符合道路交通安全法規(guī),而我們?nèi)粘I钪惺褂玫腉PU遠(yuǎn)無(wú)法達(dá)到如此嚴(yán)格的性能要求。因此我們需要花很多的時(shí)間將神經(jīng)網(wǎng)絡(luò)盡可能精簡(jiǎn)與壓縮以實(shí)現(xiàn)更快的運(yùn)行速度,從而能夠在有限的硬件性能下滿(mǎn)足對(duì)行人與車(chē)輛的實(shí)時(shí)監(jiān)測(cè)要求。
我們還在更復(fù)雜的道路環(huán)境下測(cè)試了檢測(cè)算法。上圖是一個(gè)人車(chē)混行的道路環(huán)境,難點(diǎn)一主要在于大量汽車(chē)造成的遮擋問(wèn)題,難點(diǎn)二主要在于身著各色服飾的群眾,這種道路環(huán)境無(wú)論是對(duì)人還是對(duì)車(chē)輛的檢測(cè)而言都是一個(gè)非常大的挑戰(zhàn)。當(dāng)然在如此復(fù)雜的環(huán)境下我們現(xiàn)有的算法仍會(huì)出現(xiàn)一些錯(cuò)誤,這還需要我們積累更多的數(shù)據(jù)與改進(jìn)方案以實(shí)現(xiàn)進(jìn)一步的提升,讓我們的自動(dòng)駕駛系統(tǒng)能夠通過(guò)視覺(jué)層面上的識(shí)別保證在如此復(fù)雜人車(chē)混行道路環(huán)境下駕駛過(guò)程的安全性。
4.3 紅綠燈識(shí)別
視覺(jué)識(shí)別還可幫助我們識(shí)別紅綠燈的狀態(tài),同樣是一個(gè)比較標(biāo)準(zhǔn)的物體檢測(cè)問(wèn)題。但紅綠燈檢測(cè)與之前提到的行人與車(chē)輛檢測(cè)相比,困難之處在于紅綠燈在圖像中是一個(gè)非常小的物體,越小的物體檢測(cè)難度越大。為了解決此問(wèn)題我們提高了標(biāo)準(zhǔn)檢測(cè)方法輸出的圖像分辨率,提升最后一層深度學(xué)習(xí)網(wǎng)絡(luò)對(duì)細(xì)小的物體的檢測(cè)敏感度。
這樣便可幫助我們對(duì)紅綠燈等小物體實(shí)現(xiàn)更準(zhǔn)確的檢測(cè)。上圖是我們?cè)谖宓揽诟浇粋€(gè)道路環(huán)境比較復(fù)雜的路段測(cè)試紅綠燈檢測(cè)算法的準(zhǔn)確性,可以看到雖然這段路上有很多紅綠燈,但基本上大部分的紅綠燈都可以被準(zhǔn)確檢測(cè)到。當(dāng)然紅綠燈不一定需要通過(guò)視覺(jué)識(shí)別進(jìn)行檢測(cè),有時(shí)我們可以結(jié)合一些地圖信息進(jìn)一步提高紅綠燈檢測(cè)結(jié)果的準(zhǔn)確性,盡可能降低依賴(lài)純視覺(jué)圖像信息進(jìn)行紅綠燈檢測(cè)時(shí)出現(xiàn)錯(cuò)誤的概率。
4.4 可行駛區(qū)域識(shí)別
對(duì)自動(dòng)駕駛系統(tǒng)而言最后一個(gè)關(guān)鍵問(wèn)題是明確汽車(chē)的可行駛區(qū)域。所謂可行使區(qū)域就是理論上路面沒(méi)有障礙物,允許汽車(chē)安全通過(guò)的區(qū)域,那么確定汽車(chē)可行駛區(qū)域的關(guān)鍵點(diǎn)就是確定路面上的障礙物,那么如何識(shí)別道路上的障礙物呢?障礙物的種類(lèi)有很多,故我們通過(guò)另一種思路來(lái)解決這個(gè)問(wèn)題,也就是對(duì)可行使區(qū)域進(jìn)行分割,這就使命題變?yōu)橐粋€(gè)比較標(biāo)準(zhǔn)的圖像語(yǔ)義分割問(wèn)題。上圖是我們?cè)诒本┪瀛h(huán)路上進(jìn)行的測(cè)試,可以看到道路中的紫色部分為可行駛區(qū)域。
在這種封閉環(huán)路上測(cè)試此技術(shù)的效果往往是比較穩(wěn)定的,但距離將其推廣并應(yīng)用于類(lèi)似人車(chē)混行等復(fù)雜道路環(huán)境還很遠(yuǎn),需要積累更多數(shù)據(jù)才能進(jìn)一步提高精度滿(mǎn)足道路安全駕駛的需求。同時(shí)除了識(shí)別可行使區(qū)域,大家可以看到圖像中的高亮部分展示的是車(chē)道線、交通標(biāo)識(shí)等必要的目標(biāo)識(shí)別。這些識(shí)別在為自動(dòng)駕駛安全穩(wěn)定運(yùn)行提供必要的駕駛輔助信息的同時(shí)也為深度學(xué)習(xí)在準(zhǔn)確預(yù)測(cè)可行使區(qū)域和監(jiān)測(cè)車(chē)輛行人等方面提供了必要的參考數(shù)據(jù)。
這便意味著這樣一個(gè)多任務(wù)網(wǎng)絡(luò)需要利用有限的計(jì)算資源更加迅速地完成多個(gè)駕駛行為監(jiān)測(cè)任務(wù),從而在出現(xiàn)行駛突發(fā)狀況時(shí)更快作出反應(yīng)與干預(yù),保證人車(chē)安全。而在深度學(xué)習(xí)領(lǐng)域,同時(shí)訓(xùn)練兩個(gè)任務(wù)相對(duì)于單獨(dú)訓(xùn)練一個(gè)任務(wù)所達(dá)成的效果更好。
-
攝像頭
+關(guān)注
關(guān)注
61文章
4946瀏覽量
97575 -
人工智能
+關(guān)注
關(guān)注
1804文章
48589瀏覽量
245883 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14173瀏覽量
169223
原文標(biāo)題:隱藏在攝像頭里的AI
文章出處:【微信號(hào):livevideostack,微信公眾號(hào):LiveVideoStack】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
谷歌推出用于自拍攝像頭的防臉部失真算法
蘋(píng)果變了,竟然允許對(duì)外公布人工智能研究成果
百度人工智能大神離職,人工智能的出路在哪?
人工智能就業(yè)前景
人工智能的影響超乎你想象
解讀人工智能的未來(lái)
人工智能醫(yī)生未來(lái)或上線,人工智能醫(yī)療市場(chǎng)規(guī)模持續(xù)增長(zhǎng)
【HarmonyOS HiSpark AI Camera】智能小車(chē)+智能攝像頭
基于Movidius Myriad 2的人臉識(shí)別攝像頭解決方案
路徑規(guī)劃用到的人工智能技術(shù)
人工智能分類(lèi)垃圾桶原理
人工智能芯片是人工智能發(fā)展的
物聯(lián)網(wǎng)人工智能是什么?
重塑未來(lái)地圖行業(yè)的秘密武器:攝像頭+人工智能
dfrobotHUSKYLENS 人工智能攝像頭簡(jiǎn)介






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論