 通用計算以及OpenCL究竟是什么?
通用計算以及OpenCL究竟是什么?
OpenCL是當前一個通用的由很多公司和組織共同發起的多CPU\GPU\其他芯片 異構計算(heterogeneous)的標準,它是跨平臺的。旨在充分利用GPU或者FPGA強大的并行計算能力與CPU進行協同工作,更高效的利用硬件高效的完成大規模的(尤其是并行度高的)計算。
01
異構計算、GPGPU與OpenCL
利用GPU對圖像渲染進行加速的技術非常成熟,但是GPU的芯片結構擅長大規模的并行計算,CPU則擅長邏輯和流程控制,為了不局限于圖像渲染,人們希望將這種計算能力擴展到更多領域,所以這也被稱為GPGPU(即通用處計算處理的GPU)。
通俗來講,CPU并不適合計算,它是多指令單數據流(MISD)的體系結構,更加擅長的是做邏輯控制,而數據處理基本是單流水線的,所以我們的代碼for(i=0;...;i++)在CPU上要重復迭代的跑很多遍,但是在GPU上則不是這樣,GPU是典型的單指令多數據(SIMD)的體系結構,它不擅長邏輯控制,但是天生的向量計算機,對于for(i=0;...;i++)這樣的代碼有時只需要跑一遍,所以圖形世界中那么多的頂點、片段才能快速、并行的在顯卡中渲染處理。
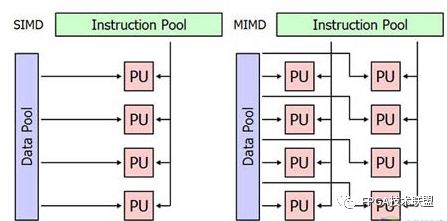
另外,GPU的晶體管可以到幾十億個,而CPU通常只有幾億個.
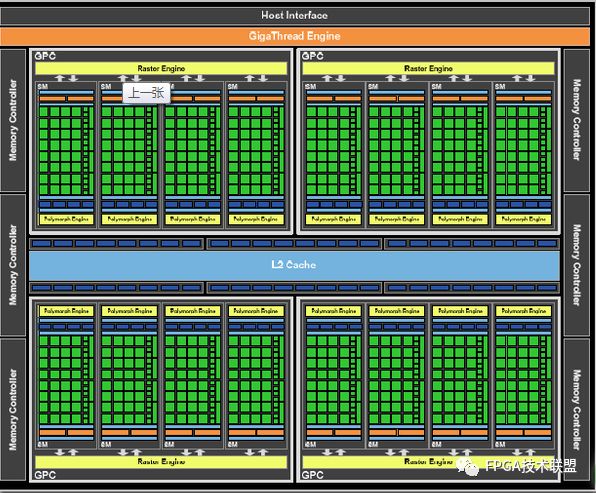
如上圖是NVidia Femi100的結構,它有著大量的并行計算單元。
所以人們就想如何將更多的計算代碼搬到GPU上,讓他不只做rendering,而CPU只負責邏輯控制,這種一個CPU(控制單元)+幾個GPU(有時可能再加幾個CPU)(計算單元)的架構就是所謂的異構編程(heterogeneous),在這里面的GPU就是GPGPU。異構編程的前景和效率是非常振奮人心的,在很多領域,尤其是高并行度的計算中,效率提升的數量級不是幾倍,而是百倍千倍。
NVIDIA在很早就推出了利用其顯卡的GPGPU計算 CUDA架構,當時的影響是很大的,將很多計算工作(科學計算、圖像渲染、游戲)的問題提高了幾個數量級的效率,CUDA是NVDIA主力推的通用計算架構,但是CUDA最大的局限就是它只能使用Nvidia自的顯卡,對于廣大的AMD卡用戶鞭長莫及。
OpenCL則在之后應運而生,它由幾大主流芯片商、操作系統、軟件開發者、學術機構、中間件提供者等公司聯合發起,它最初由Apple提出發起標準,隨后Khronos Group成立工作組,協調這些公司共同維護這套通用的計算語言。Khronos Group聽起來比較熟悉吧,圖像繪制領域著名的軟硬件接口API規范著名的OpenGL也是這個組織維護的,其實他們還維護了很多多媒體領域的規范,可能也是類似于Open***起名的(所以剛聽到OpenCL的時候就在想它與OpenGl有啥關系),OpenCl沒有一個特定的SDK,Khronos Group只是指定標準(你可以理解為他們定義頭文件),而具體的實現則是由不同參與公司來做,這樣你會發現NVDIA將OpenCL做了實現后集成到它的CUDA SDK中,而AMD則將其實現后放在所謂是AMD APP (Accelerated Paral Processing)SDK中,而Intel也做了實現,所以目前的主流CPU和GPU都支持OpenCL架構,雖然不同公司做了不同的SDK,但是他們都遵照同樣的OpenCL規范,也就是說原則上如果你用標準OpenCl頭中定義的那些接口的話,使用NVIDIA的SDK編的程序可以跑在AMD的顯卡上的。但是不同的SDK會有針對他們芯片的特定擴展,這點類似于標磚OpenGL庫和GL庫擴展的關系。
OpenGL的出現使得AMD在GPGPU領域終于迎頭趕上的NVIDIA,但是NVIDIA雖為OpenCL的一員,但是他們似乎更加看重自己的獨門武器CUDA,所以N家對OpenCL實現的擴展也要比AMD少,AMD由于同時做CPU和GPU,還有他們的APU,似乎對OpenCL更來勁一些。
02
OpenCL的誕生
OpenCL也是通過在GPU上寫代碼來加速,只不過他把CPU、GPU、其他什么芯片給統一封裝了起來,更高了一層,對開發者也更友好。
其實最開始顯卡是不存在的,最早的圖形處理是放在CPU上,后來發現可以再主板上放一個單獨的芯片來加速圖形繪制,那時還叫圖像處理單元,直到NVIDIA把這東西做強做大,并且第一給它改了個NB的稱呼,叫做GPU,也叫圖像處理器,后來GPU就以比CPU高幾倍的速度增長性能。
開始的時候GPU不能編程,也叫固定管線的,就是把數據按照固定的通路走完和CPU同樣作為計算處理器,順理成章就出來了可編程的GPU,但是那時候想在GPU上編程可不是容易的事,你只能使用GPU匯編來寫GPU程序,GPU匯編?聽起來就是很高級的玩意兒,所以那時使用GPU繪制很多特殊效果的技能只掌握在少數圖形工程師身上,這種方式叫可編程管線。
很快這種桎桍被打破,GPU上的高級編程語言誕生,在當時更先進的一些顯卡上,像C一樣的高級語言可以使程序員更加容易的往GPU寫代碼,這些語言代表有nvidia和微軟一起創作的CG,微軟的HLSL,openGl的GLSL等等,現在它們也通常被稱為高級著色語言(Shading Language),這些shader目前已經被廣泛應用于我們的各種游戲中。
在使用shading language的過程中,一些科研人員發現很多非圖形計算的問題(如數學、物理領域的并行計算)可以偽裝成圖形問題利用Shading Language實現在GPU上計算,而這結果是在CPU上跑速度的N倍,人們又有了新的想法,想著利用GPU這種性能去解決所有大量并行計算的問題(不只圖形領域),這也叫做通用處理的GPU(GPGPU),很多人嘗試這樣做了,一段時間很多論文在寫怎樣怎樣利用GPU算了哪個東東。。。但是這種工作都是偽裝成圖形處理的形式做的,還沒有一種天然的語言來讓我們在GPU上做通用計算。這時又是NVIDIA帶來了革新,09年前后推出的GUDA架構,可以讓開發者在他們的顯卡上用高級語言編寫通用計算程序,一時CUDA熱了起來,直到現在N卡都印著大大的CUDA logo,不過它的局限就是硬件的限制。
OpenCL則突破了硬件的壁壘,試圖在所有支持的硬件上搭建起通用計算的協同平臺,不管你是cpu還是gpu通通一視同仁,都能進行計算,可以說OpenCL的意義在于模糊了主板上那兩種重要處理器的界限,并使在GPU上跑代碼變得更容易。
01
OpenCL架構
上面說的都是關于通用計算以及OpenCL是什么,下面就提綱挈領的把OpenCL的架構總結一下:以下是OpenCL硬件層的抽象
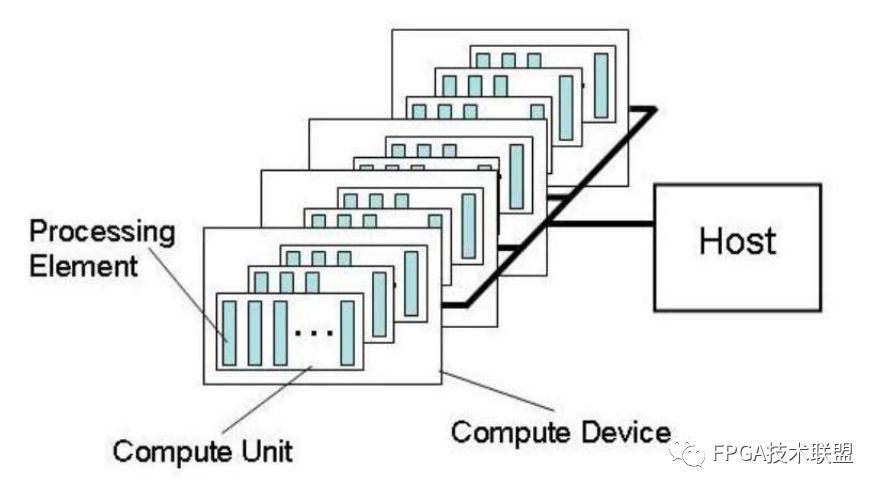
它是一個Host(控制處理單元,通常由一個CPU擔任)和一堆Computer Device(計算處理單元,通常由一些GPU、CPU其他支持的芯片擔任),其中Compute Device切分成很多Processing Element(這是獨立參與單數據計算的最小單元,這個不同硬件實現都不一樣,如GPU可能就是其中一個Processor,而CPU可能是一個Core),其中很多個Processing Element可以組成組為一個Computer Unit,一個Unit內的element之間可以方便的共享memory,也只有一個Unit內的element可以實現同步等操作
02
內存架構
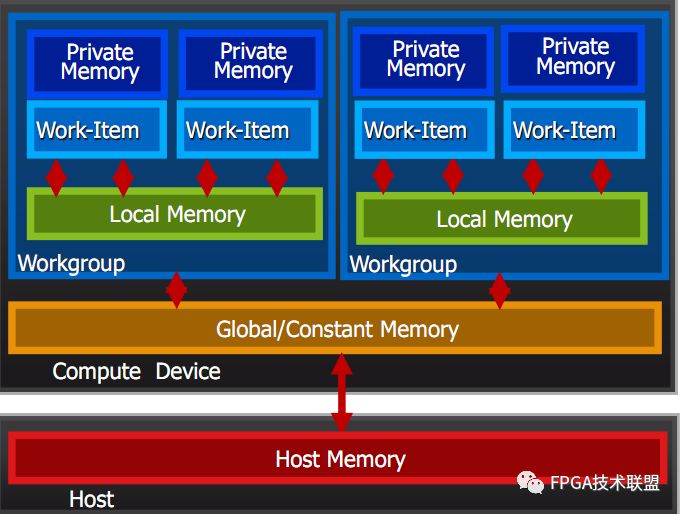
其中Host有自己的內存,而在compute Device上則比較復雜,首先有個常量內存,是所有人能用的,通常也是訪問最快的但是最稀少的,然后每個element有自己的memory,這是private的,一個組內的element有他們共用的一個local memery。仔細分析,這是一個高效優雅的內存組織方式。數據可以沿著Host-》gloabal-》local-》private的通道流動(這其中可能跨越了很多個硬件)
03
軟件層面的組成
這些在SDK中都有對應的數據類型
-
setup相關:
Device:對應一個硬件(標準中特別說明多core的CPU是一個整個Device)
Context:環境上下文,一個Context包含幾個device(單個Cpu或GPU),一個Context就是這些device的一個聯系紐帶,只有在一個Context上的那些Device才能彼此交流工作,你的機器上可以同時存在很多Context。你可以用一個CPu創建context,也可以用一個CPU和一個GPU創建一個。
Command queue:這是個給每個Device提交的指令序列
-
內存相關:
Buffers:這個好理解,一塊內存
Images:畢竟并行計算大多數的應用前景在圖形圖像上,所以原生帶有幾個類型,表示各種維度的圖像。
gpu代碼執行相關:
Program:這是所有代碼的集合,可能包含Kernel是和其他庫,OpenCl是一個動態編譯的語言,代碼編譯后生成一個中間文件(可實現為虛擬機代碼或者匯編代碼,看不同實現),在使用時連接進入程序讀入處理器。
Kernel:這是在element跑的核函數及其參數組和,如果把計算設備看做好多人同時為你做一個事情,那么Kernel就是他們每個人做的那個事情,這個事情每個人都是同樣的做,但是參數可能是不同的,這就是所謂的單指令多數據體系。
WorkI tem:這就是代表硬件上的一個Processing Element,最基本的計算單元
-
同步相關:
Events:在這樣一個分布式計算的環境中,不同單元之間的同步是一個大問題,event是用來同步的
他們的關系如下圖
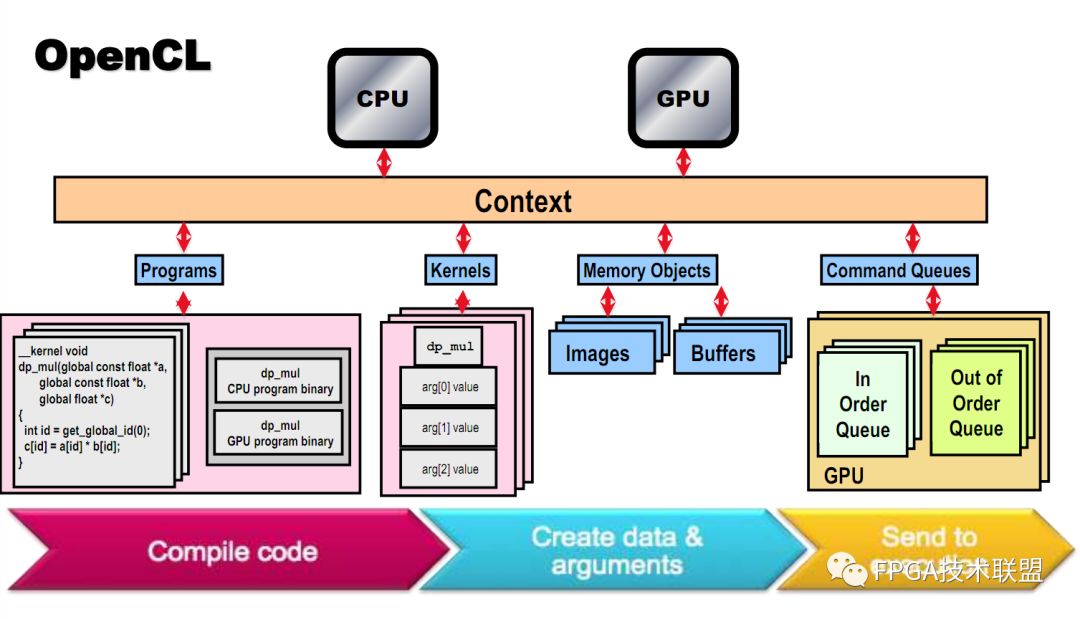
上面就是OpenCL的入門介紹, 在游戲領域,OpenCL已經有了很多成功的實踐,好像EA的F1就已經應用了OpenCL,還有一些做海洋的lib應用OpenCL(海面水波的FFT運算在過去是非常慢的),另外還有的庫干脆利用OpenCL去直接修改現有的C代碼,加速for循環等,甚至還有OpenCl版本的C++ STL,叫thrust,所以我覺得OpenCL可能會真正的給我們帶來些什么
-
gpu
+關注
關注
28文章
4921瀏覽量
130783 -
OpenCL
+關注
關注
2文章
48瀏覽量
33697 -
異構計算
+關注
關注
2文章
105瀏覽量
16618
原文標題:異構計算以及OpenCL介紹
文章出處:【微信號:gh_873435264fd4,微信公眾號:FPGA技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

FOC電機控制究竟該如何學?
工程師在產品選型的時究竟是選CAN還是CANFD接口卡呢?

云驥智行借助NVIDIA Jetson打造“域腦”通用計算平臺
室內導航究竟是如何實現的
ADS1298R PACE_OUT1和PACE_OUT2這兩條引腿究竟是輸入還是輸出?有什么用?怎樣使用?
嵌入式和人工智能究竟是什么關系?
PCM1861 INT腳究竟是輸出還是輸入?
超高頻讀寫器究竟是什么,能做什么?一文讀懂!








 工商網監
工商網監
評論