 介紹了主要的生成模型和代表性的應用
介紹了主要的生成模型和代表性的應用
本文是IJCAI 2018的深度生成模型tutorial,作者是斯坦福大學PH.D Aditya Grover,長達115頁的slides非常詳盡地介紹了主要的生成模型和代表性的應用,希望對大家的學習有所幫助。
生成模型是圖模型和概率編程語言中概率推理的關鍵模型。最近,使用神經網絡對這些模型進行參數化,以及使用基于梯度的技術進行隨機優化的最新進展,使得可以跨多種模態和應用程序對高維數據進行可擴展建模。
本教程的前半部分將提供對深度生成模型的主要家庭成員的整體回顧,包括生成對抗網絡、變分自編碼器和自回歸模型。對于每個模型,我們都將深入討論概率公式、學習算法以及與其他模型的關系。
本教程的后半部分將演示如何在一組具有代表性的推理任務中使用深度生成模型:半監督學習、模仿學習、對抗樣本防御,以及壓縮感知。
最后,我們將討論當前該領域面臨的挑戰,并展望未來的研究方向。
目錄
第一部分:
生成建模的動機,以及與判別模型的對比
生成模型的定義和特征:估計密度、模擬數據、學習表示
傳統的生成建模方法,以及深度神經網絡在有效參數化中的作用
基于學習算法的生成模型的分類:likelihood-based的學習和likelihood-free的學習
Likelihood-based學習實例:
自回歸模型(定向,完全觀察)
變分自編碼器(定向,潛變量)
第二部分:
Likelihood-based學習實例(續):
規范化流模型
likelihood-free學習實例化:
生成對抗網絡
深度生成模型的應用
半監督學習
模仿學習
對抗樣本
壓縮感知
生成模型未來研究的主要挑戰和展望
生成建模概述、與判別模型的對比

生成模型應用領域:
計算語音
自然語言處理
計算機視覺/機器人學
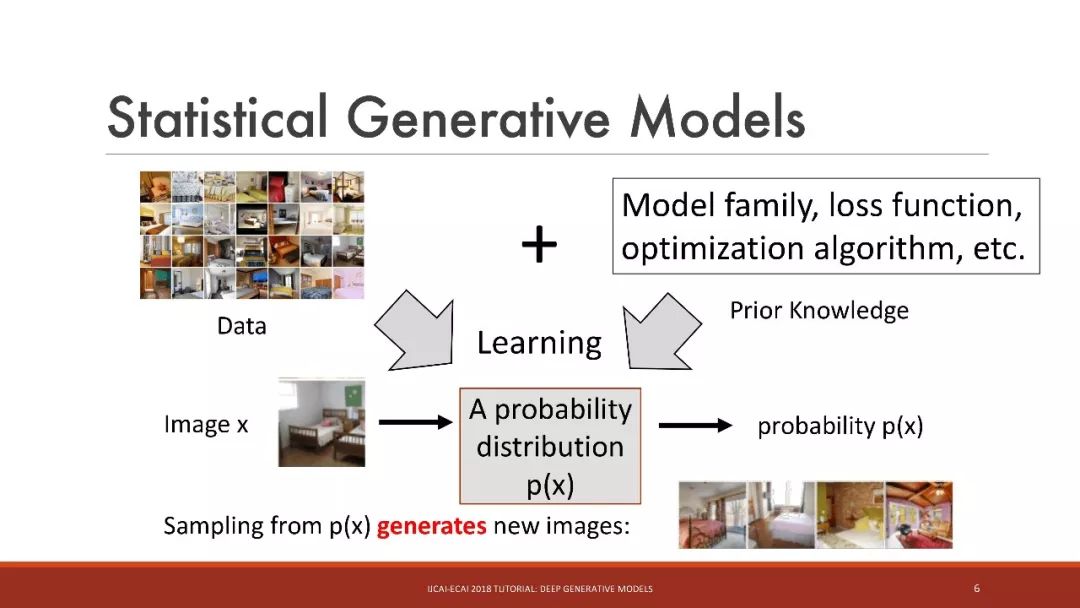
統計生成模型


判別 vs. 生成

生成模型中的學習
給定:來自數據分布和模型家族的樣本
目標是:盡可能地接近數據分布
挑戰:如何評價和優化數據分布和模型分布之間的接近性(closeness)?

最大似然估計
解決方案1: = KL 散度
統計學上有效
需要可跟蹤地評估或優化似然性

最大似然估計
易處理似然性(Tractable likelihoods):有向模型,如自回歸模型
難處理似然性:無向模型,如受限玻爾茲曼機(RBM);有向模型,如變分自編碼器(VAE)
intractable likelihoods的替代選擇:
- 使用MCMC或變分推理進行近似推理
- 利用對抗訓練進行 Likelihood-free的推理
基于似然性的生成模型

提供一個對數似然的解析表達式,即 log N
學習涉及(近似)評估模型對數似然相對于參數的梯度
關鍵設計選擇
有向(Directed)和無向(undirected)
完全觀察 vs. 潛在變量

有向、完全觀察的圖模型
這里的關鍵想法是:將聯合分布分解為易處理條件的乘積

學習和推理
學習最大化數據集上的模型對數似然
易處理條件允許精確的似然評估
訓練期間并行的條件評估
有向模型允許ancestral采樣,每次一個變量

基于神經網絡的參數化

基于MLP的參數化

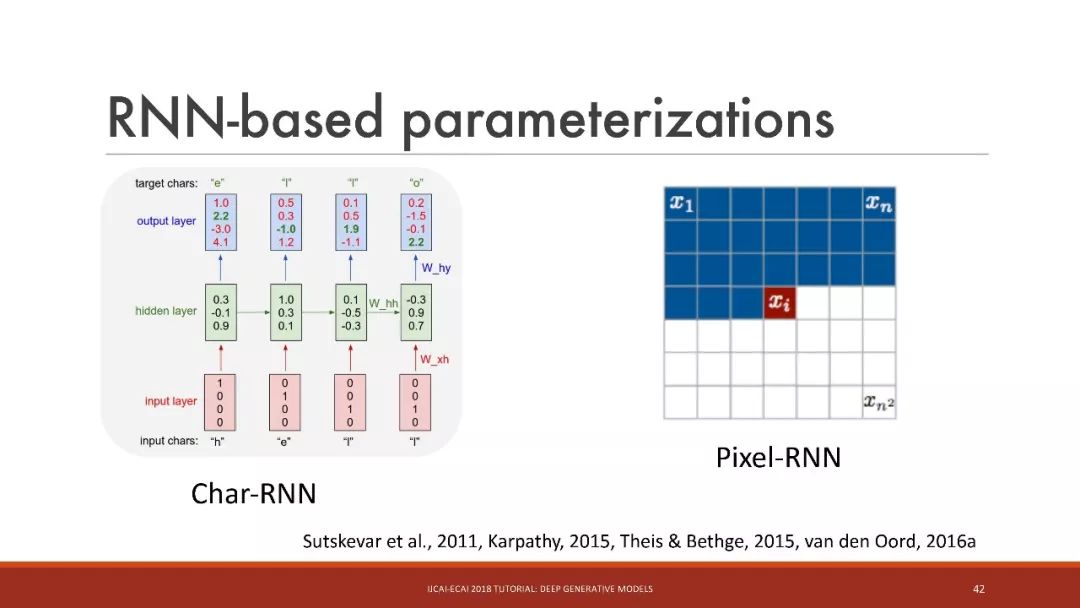
基于RNN的參數化
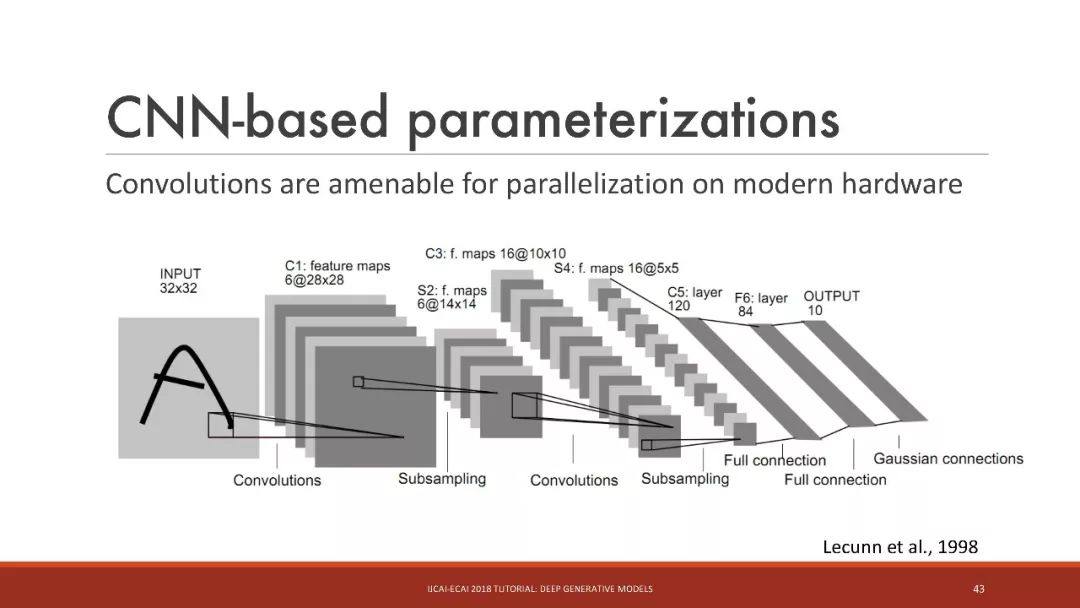
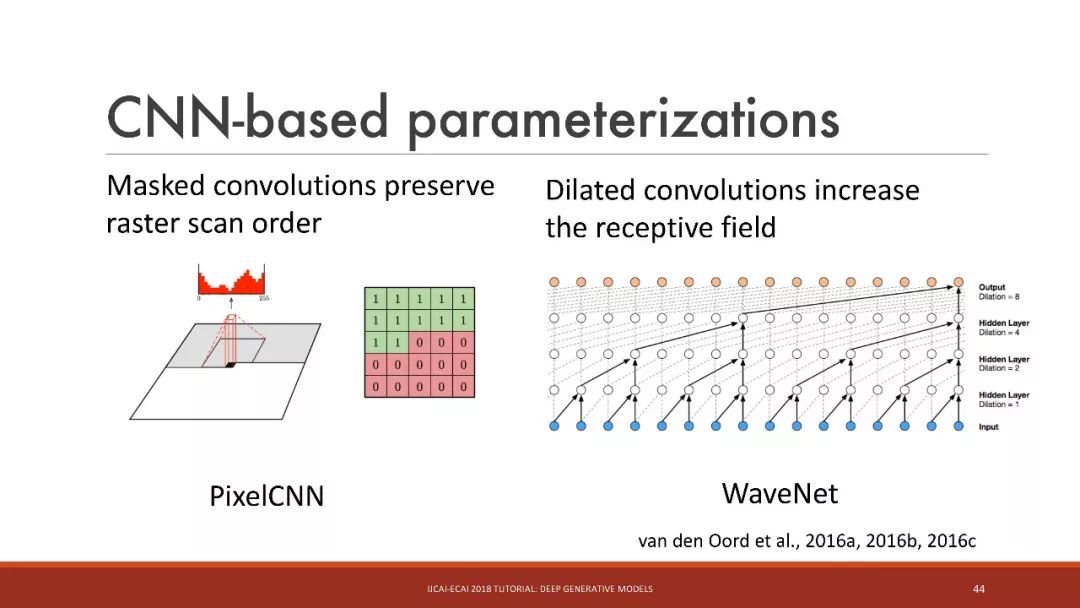
基于CNN的參數化
likelihood-free的生成模型

likelihood-free的生成模型
最佳生成模型:最佳樣本和最高的對數似然
對于不完美的模型,對數似然和樣本是不相關的
Likelihood-free的學習考慮的目標不直接依賴于似然函數


生成對抗網絡
這里的關鍵想法是:generator(生成器)和discriminator(判別器)兩者的博弈
判別器區分真實數據集樣本和來自生成器的假樣本
生成器生成可以欺騙判別器的樣本

對于一個固定的生成器,判別器最大化負交叉熵
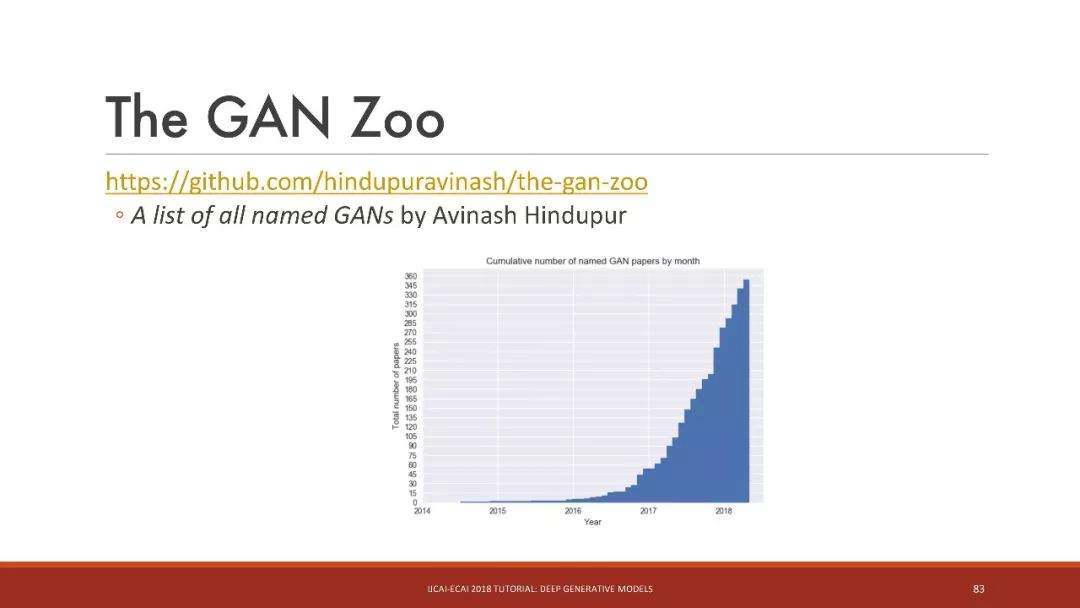
GAN動物園
深度生成模型的應用:半監督學習、模仿學習、對抗樣本、壓縮感知

半監督學習
在這個例子中,我們可以如何利用這些未標記的數據呢?

步驟1:學習標記數據和未標記數據的潛在變量生成模型
步驟2:使用z作為特征,訓練分類器(例如SVM),僅使用有標記的部分


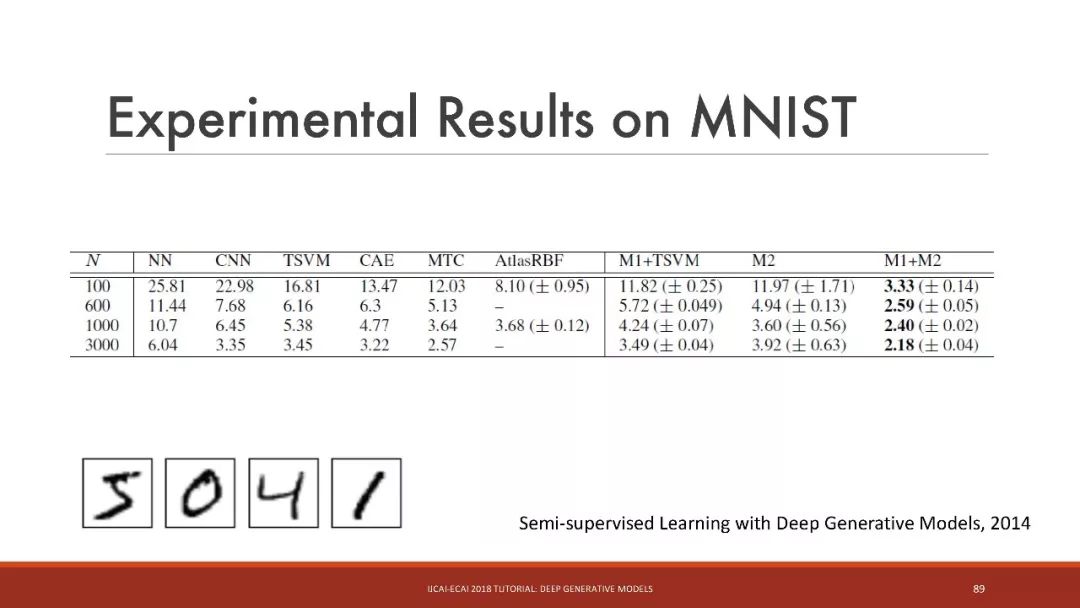

半監督學習的結果


模仿學習
有幾個現有的方法:
行為克隆(Behavioral cloning)
逆向強化學習
學徒學習(Apprenticeship learning)
我們的方法是:生成式的潛變量模型

對抗樣本
添加微小的噪聲,最先進的分類器都有可能被欺騙!

檢測對抗樣本

遷移壓縮感知
從源、數據豐富的域遷移到目標、數據饑渴的域

總結
1. 生成模型的殺手級應用是什么?
基于模型的RL?
2. 什么是正確的評估指標?
從根本上說,它是無監督學習。評估指標定義不明確。
3. 在推理中是否存在基本的權衡?
采樣
評估
潛在特征
-
神經網絡
+關注
關注
42文章
4810瀏覽量
102909 -
編程語言
+關注
關注
10文章
1955瀏覽量
36187
原文標題:【干貨】IJCAI:深入淺出講解深度生成模型(115 PPT)
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
運算放大器的代表性參數
9款具有代表性的系統解決方案
在情感分析中使用知識的一些代表性工作
具有代表性的科學產品
運算放大器的代表性參數詳解
浪潮存儲入選分布式存儲代表性廠商
晶振封裝代表性的網紅型號有哪些?







 工商網監
工商網監
評論