") 4分鐘訓練好AlexNet,6.6分鐘訓練好ResNet-50,創(chuàng)造了AI訓練世界新紀錄
4分鐘訓練好AlexNet,6.6分鐘訓練好ResNet-50,創(chuàng)造了AI訓練世界新紀錄
騰訊機智機器學習平臺和香港浸會大學計算機科學系褚曉文教授團隊合作,在ImageNet數(shù)據(jù)集上,4分鐘訓練好AlexNet,6.6分鐘訓練好ResNet-50,創(chuàng)造了AI訓練世界新紀錄。本文帶來詳細解讀。
2018年6月25日,OpenAI在其Dota2 5v5中取得一定成績后介紹,其在訓練中batch size取100W,而1v1的訓練batch size更是達到800W;訓練時間則是以周計。騰訊內部對游戲AI一直非常重視,也面臨大batch size收斂精度和低訓練速度慢的問題;目前batch size超過10K則收斂不到基準精度,訓練時間以天計,這對于快速迭代模型來說是遠遠不夠的。
目前業(yè)界考驗大batch size收斂能力和大數(shù)據(jù)集上訓練速度的一個權威基準是如何在ImageNet數(shù)據(jù)集上,用更大的batch size,在更短的時間內將ResNet-50/AlexNet這兩個典型的網(wǎng)絡模型訓練到標準精度;國外多個團隊作了嘗試并取得了進展,比如UC Berkely等高校的團隊可在20分鐘將ResNet-50訓練到基準精度。
研究和解決這個問題,可以積累豐富的大batch size收斂優(yōu)化經驗和大集群高性能訓練經驗,并將這些經驗應用到解決游戲AI類實際業(yè)務中;這也是我們研究這個問題的初衷。
4分鐘內訓練ImageNet
騰訊機智機器學習平臺團隊,在ImageNet數(shù)據(jù)集上,4分鐘訓練好AlexNet,6.6分鐘訓練好ResNet-50,創(chuàng)造了AI訓練世界新紀錄。
在這之前,業(yè)界最好的水平來自:
① 日本Perferred Network公司Chainer團隊,其15分鐘訓練好ResNet-50;
②UC Berkely等高校的團隊,11分鐘訓練好AlexNet.
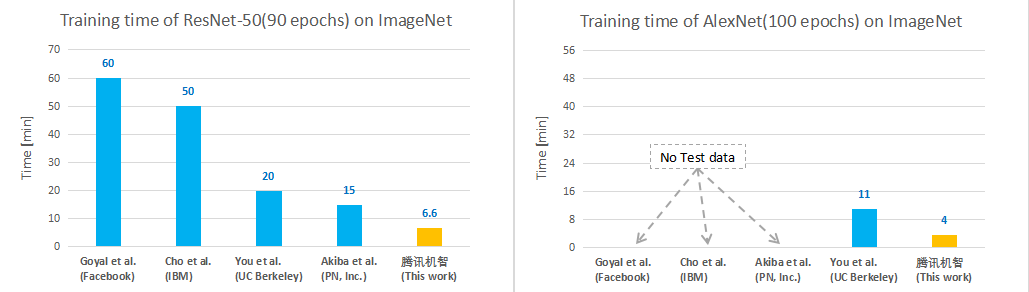
圖示 國內外各團隊訓練ImageNet速度
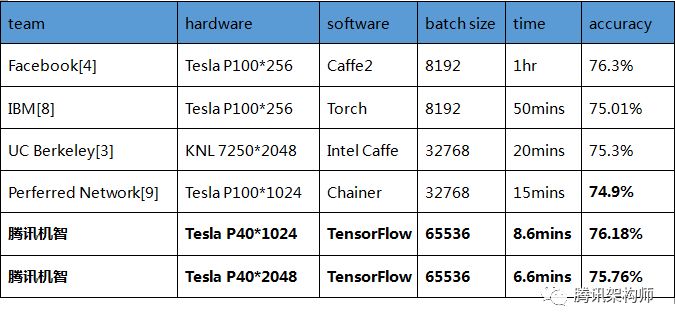
圖示各平臺ResNet-50訓練軟硬件參數(shù)配置及性能
注:batch size為256時基準準確度為75.3%。

圖示 各平臺AlexNet訓練軟硬件參數(shù)配置及性能
注:“--”表示相關團隊沒有對應的測試數(shù)據(jù)
機器學習領域訓練背景
在AlexNet網(wǎng)絡模型出現(xiàn)后的過去幾年中,深度學習有了長足的發(fā)展和進步,尤其是在圖像、語音、機器翻譯、自然語言處理等領域帶來了跨越式提升。在AlphaGo使用深度學習方法戰(zhàn)勝世界圍棋冠軍李世石之后,大家對人工智能未來的期望被再一次點燃,人工智能成為各個領域議論的焦點。但與之相伴的也有很多問題:
?數(shù)據(jù)量大:
有些模型的訓練數(shù)據(jù)動輒上TB,使得多輪訓練時數(shù)據(jù)讀取成為非常耗時的部分。
?計算模型復雜:
深度網(wǎng)絡的一個特點就是結構越深、越復雜,所表達的特征就越豐富,在此思想下,最新的網(wǎng)絡結構越來越復雜,從AlexNet的8層,VGG-19的19層,ResNet-50的50層,到Inception-ResNet-V2的467層和ResNet-1000的1202層等。
?參數(shù)量大:
深度神經網(wǎng)絡由于層次很多,參數(shù)量往往很大。ResNet-50有2500萬參數(shù)量,AlexNet有6200萬的參數(shù)量,而VGG-16參數(shù)量則達到1.38億,有的語言模型參數(shù)量甚至超過10個億[5]。
?超參數(shù)范圍廣泛:
隨著模型復雜度的提升,模型中可供調節(jié)的超參數(shù)數(shù)量及數(shù)值范圍也在增多。例如,在CIFAR-10數(shù)據(jù)集上訓練的ResNet模型有16個可調的超參數(shù)[8],當多數(shù)超參數(shù)的取值為連續(xù)域的情況下,如此少量的超參數(shù)仍然可能造成組合爆炸。因此,最近也出現(xiàn)了以谷歌的Vizier為代表的系統(tǒng),采用優(yōu)化的搜索及學習算法為模型自動適配合適的超參數(shù)值的集合。
所有上面這些問題,對訓練速度帶來巨大的挑戰(zhàn)和要求。
從2010年以來,每年的ImageNet大規(guī)模視覺識別挑戰(zhàn)賽(ILSVRC[1],下文簡稱ImageNet挑戰(zhàn)賽)作為最權威的檢驗圖像識別算法性能的基準,都是機器學習領域的焦點。
隨著全世界研究者的不斷努力,ImageNet的Top-5錯誤率從2010年的28%左右,下降到2012年的15.4%(AlexNet),最終在2017年Top-5錯誤率已經下降到3%左右,遠優(yōu)于人類5%的水平[2]。
在這個迭代過程其中,兩個典型的網(wǎng)絡,AlexNet和ResNet-50具有里程碑的意義。然而,在一個英偉達的 M40 GPU 上用 ResNet-50 訓練 ImageNet 需要 14 天;如果用一個串行程序在單核 CPU 上訓練可能需要幾十年才能完成[3]。因此,如何在更短的時間內在ImageNet上訓練好AlexNet和ResNet-50一直是科研工作者研究的課題。
很多研究團隊都進行了深入嘗試,比如Facebook人工智能實驗室與應用機器學習團隊可在1小時訓練好ImageNet[4];目前業(yè)界最好的水平來自:
①日本Perferred Network公司Chainer團隊,其15分鐘訓練好ResNet-50;[9]
②UC Berkely等高校的團隊,11分鐘訓練好AlexNet.[3]
機智團隊想在這個問題上做出新貢獻,推動AI行業(yè)向前發(fā)展,助力AI業(yè)務取得成功。
訓練速度提升的挑戰(zhàn)
如第二節(jié)所述,由于以上四個主要矛盾,深度學習訓練時間常常以小時和天計算,如何提升訓練效率,加快模型訓練迭代效率,成了機智團隊的關注重點。要提升訓練速度,主要面臨挑戰(zhàn)有如下幾個方面:
3.1 大batch size帶來精度損失
為了充分利用大規(guī)模集群算力以達到提升訓練速度的目的,人們不斷的提升batch size大小,這是因為更大的batch size允許我們在擴展GPU數(shù)量的同時不降低每個GPU的計算負載。
然而,過度增大batch size會帶來明顯的精度損失!這是因為在大batch size(相對于訓練樣本數(shù))情況下,樣本隨機性降低,梯度下降方向趨于穩(wěn)定,訓練就由SGD向GD趨近,這導致模型更容易收斂于初始點附近的某個局部最優(yōu)解,從而抵消了計算力增加帶來的好處。如何既增大batch size,又不降低精度,是機智團隊面臨的首要挑戰(zhàn)。
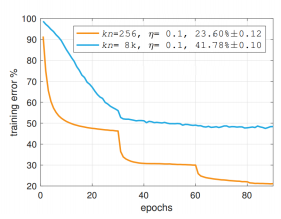
圖示 大batch size帶來精度下降
3.2 多機多卡擴展性差
深度訓練通常采用數(shù)據(jù)并行模式,數(shù)據(jù)并行模式將樣本分配給不同的GPU進行訓練。相比模型并行,數(shù)據(jù)并行簡單且可擴展,成為目前主流的分布式訓練方式。
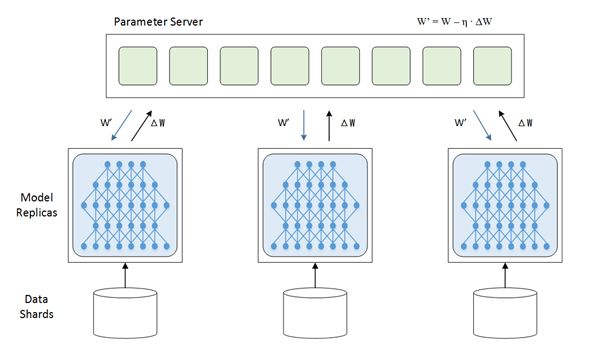
圖示 數(shù)據(jù)并行
分布式訓練數(shù)據(jù)并行模式下,經典的部署方式是獨立的參數(shù)服務器(Parameter Server)來做訓練過程中梯度的收集、分發(fā)和更新工作,每一次迭代所有的GPU都要與PS多次通信來獲取、更新參數(shù);當節(jié)點超過一定數(shù)量時,PS的帶寬以及處理能力將成為整個系統(tǒng)的瓶頸。
AI訓練系統(tǒng)和傳統(tǒng)后臺系統(tǒng)之間的一個最主要區(qū)別是,傳統(tǒng)后臺系統(tǒng)可以通過增加節(jié)點的方式來分擔訪問請求,節(jié)點之間沒有強相關的關系;而AI訓練系統(tǒng)在訓練模型時需要參與訓練的所有節(jié)點都不斷的與模型參數(shù)服務器交換和更新數(shù)據(jù),這無形中相當于對整個系統(tǒng)增加了一把大鎖,對整個系統(tǒng)中單節(jié)點的帶寬和處理能力要求非常高,這也是AI訓練系統(tǒng)的特別之處,不能通過簡單的增加節(jié)點來提升系統(tǒng)負載能力,還需要解決多節(jié)點的擴展性問題。
所以如何在架構部署和算法層面減少對帶寬需求,控制多機擴展中參數(shù)傳輸對訓練速度的影響,使AI訓練集群性能可線性擴展,是機智團隊面臨的另一項挑戰(zhàn)。
3.3 如何選擇合適的超參
此外,由于超參較多,而每一個超參分布范圍較廣,使得超參調優(yōu)的耗時較長,特別是針對ImageNet這種超大數(shù)據(jù)集的情況。前文提過,CIFAR-10數(shù)據(jù)集上訓練的ResNet模型就有16個超參。
隨著項目進展,團隊還引入了很多新的關鍵技術,如后面將會提到的LARS算法、分層同步算法、梯度融合策略,Batch Norm替換等都會增加模型超參數(shù)量,如何在可接受的時間內尋找到較優(yōu)解,是機智團隊面臨的第三個重大挑戰(zhàn)。
訓練速度提升的關鍵技術
機智團隊針對上述挑戰(zhàn),分別在大batch size訓練,多機擴展性,及超參調整方法上取得突破,并應用到ImageNet訓練場景中,能夠在6.6分鐘內完成ResNet-50訓練,4分鐘完成AlexNet訓練——這是迄今為止ImageNet訓練的最高世界紀錄。在這個過程中,機智團隊在吸收業(yè)界最佳實踐的同時,深度融合了多項原創(chuàng)性關鍵技術。
4.1 超大batch size 的穩(wěn)定收斂能力
1)半精度訓練與層次自適應速率縮放(LARS)算法相結合
為了提升大batch size情況下的可擴展性,機智團隊將訓練數(shù)據(jù)和參數(shù)采用半精度浮點數(shù)的方式來表示,以減少計算量的同時降低帶寬需求。但半精度浮點數(shù)的表示方式不可避免的會降低模型收斂精度。
為了解決精度下降問題,機智團隊引入了層次自適應速率縮放(LARS)算法。LARS算法由You et al. (2017)[3]最先提出,該算法通過對不同的層使用不同的Learning Rate,大幅度提升了大batch size場景下的訓練精度,但實際測試發(fā)現(xiàn),直接將LARS算法應用于半精度模型訓練造成很大的精度損失,這是由于乘以LARS系數(shù)后, 很多參數(shù)因半精度數(shù)值表示范圍較小而直接歸0。
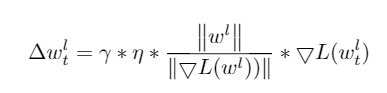
圖示 LARS學習率更新公式
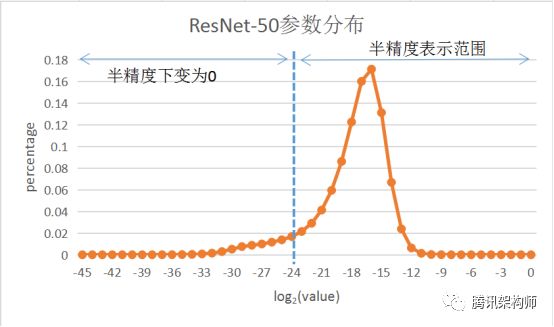
圖示 參數(shù)用半精度表示導致精度丟失
為此,機智團隊引入了混合精度訓練方法來解決這個問題,通過將半精度參數(shù)轉化成單精度,然后再與LARS結合,即半精度訓練,單精度LARS優(yōu)化及參數(shù)更新。相應的,在更新參數(shù)時使用loss scaling方法成倍擴大loss(并對應減少學習率)避免歸0影響精度。測試結果顯示,這一方法,一方面保證了計算速度,另一方面也取得了很好的收斂效果。
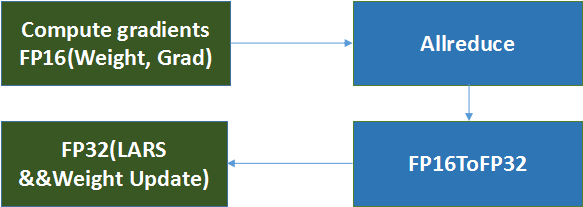
圖示 混合精度訓練
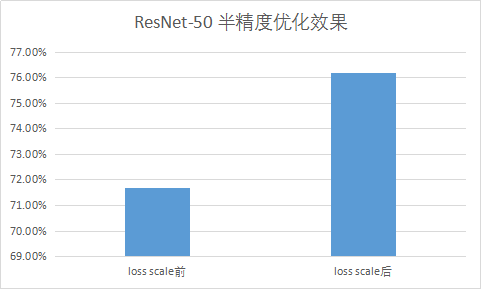
圖示 ResNet-50 半精度優(yōu)化效果
2)模型和參數(shù)的改進
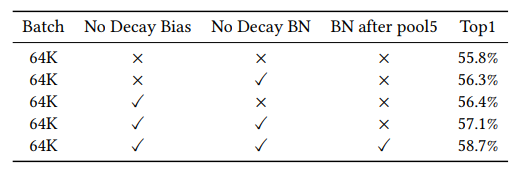
我們在32K下復現(xiàn)了You et al. (2017)的測試結果,但batch size擴展到64K時,訓練精度未能達到基準準確性。為了提高在64K下的收斂準確性,我們對參數(shù)和模型進行了改進:1) 只對weight做正則化。 2)在You et al. (2017)模型的基礎上,進一步改進AlexNet模型。
正則化通過在損失函數(shù)后加一項懲罰項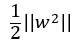 ,是常用的防止模型過擬合的策略。大多數(shù)深度學習框架默認會對所有可學習的參數(shù)做正則化,包括weight, bias, BN beta和gamma(batch norm中可學習的參數(shù))。我們發(fā)現(xiàn)bias, beta, gamma的參數(shù)量相對于weight來說非常小,對于AlexNet模型,bias, beta, gamma參數(shù)量總和僅占總參數(shù)量的0.02%。
,是常用的防止模型過擬合的策略。大多數(shù)深度學習框架默認會對所有可學習的參數(shù)做正則化,包括weight, bias, BN beta和gamma(batch norm中可學習的參數(shù))。我們發(fā)現(xiàn)bias, beta, gamma的參數(shù)量相對于weight來說非常小,對于AlexNet模型,bias, beta, gamma參數(shù)量總和僅占總參數(shù)量的0.02%。
因此,bias, beta, gamma不會給模型帶來過擬合,如果我們對這些參數(shù)進行正則化,增加了計算量,還會讓模型損失一些靈活性。經過實驗驗證,我們發(fā)現(xiàn)不對bias, beta, gamma做正則化,模型提高了約1.3%的準確性。
優(yōu)化正則化策略后模型收斂性得到了提升,但是AlexNet還是沒有達到基準準確性。通過對AlexNet訓練參數(shù)和輸出特征的分析,我們發(fā)現(xiàn)Pool5的特征分布(如下圖示,顏色淺表示數(shù)據(jù)分布少,顏色深的表示數(shù)據(jù)分布多,總體看數(shù)據(jù)分布范圍很廣)隨著迭代步數(shù)的增加,方差越來越大,分布變化很劇烈,這樣會導致學習和收斂變得困難。

圖示 Pool5的輸出特征分布圖(橫軸是迭代步數(shù),縱軸是特征分布)
這個結果啟發(fā)我們在Pool5后插入一個Batch Norm層,用以規(guī)范特征的分布。如下圖所示,完善AlexNet后,BN5后面輸出的特征圖分布更加均勻,64K batch在100 epochs下收斂到58.7%,不損失準確性的同時完成了加速訓練。
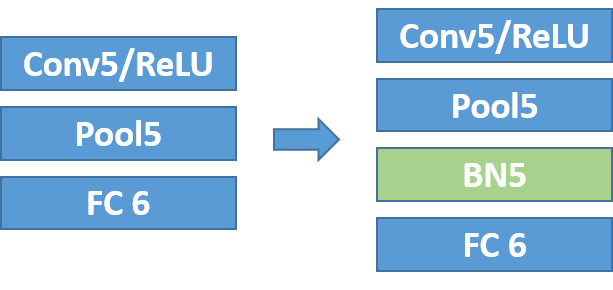
圖示 使用Batch Norm改造AlexNet
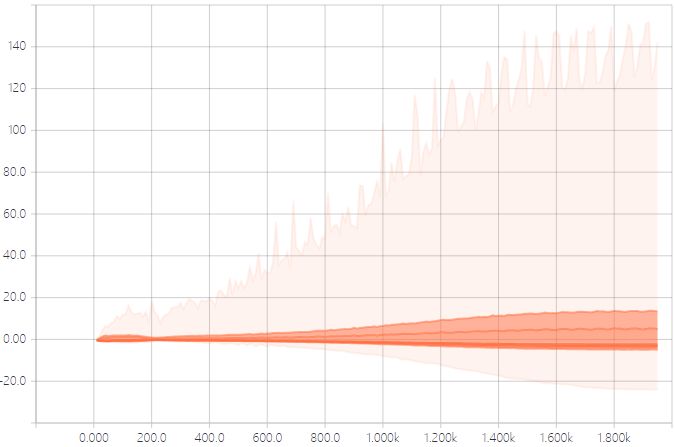
圖示 Pool5+BN5的輸出特征分布圖(橫軸是迭代步數(shù),縱軸是特征分布)
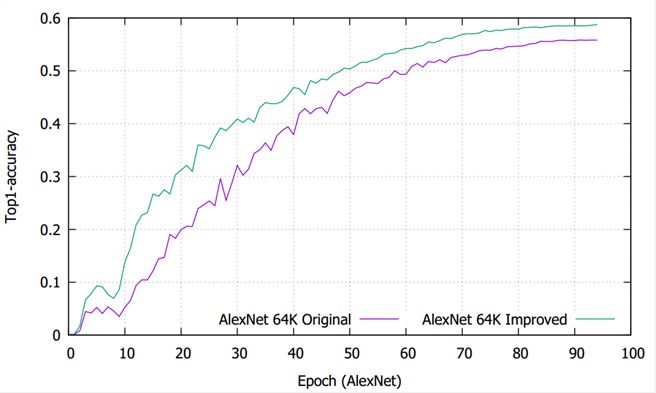
圖示 使用BN改造AlexNet前后的收斂精度比較
3)超參調優(yōu)
模型超參調優(yōu)是深度學習中成本最高的部分之一,大模型的訓練過程是以小時或天計算的,特別是訓練數(shù)據(jù)集較大的情況下。因此需要有更高效的思路和方法來調優(yōu)超參,機智平臺團隊在這個方面主要采取了如下思路:
?參數(shù)步長由粗到細:調優(yōu)參數(shù)值先以較大步長進行劃分,可以減少參數(shù)組合數(shù)量,當確定大的最優(yōu)范圍之后再逐漸細化調整,例如在調整學習速率時,采取較大步長測試發(fā)現(xiàn):學習率lr較大時,收斂速度前期快、后期平緩,lr較小時,前期平緩、后期較快,根據(jù)這個規(guī)律繼續(xù)做細微調整,最終得到多個不同區(qū)間的最佳學習速率;
?低精度調參:在低精度訓練過程中,遇到的最大的一個問題就是精度丟失的問題,通過分析相關數(shù)據(jù),放大低精度表示邊緣數(shù)值,保證參數(shù)的有效性是回歸高精度計算的重要方法;
?初始化數(shù)據(jù)的調參:隨著網(wǎng)絡層數(shù)的增多,由于激活函數(shù)的非線性,初始化參數(shù)使得模型變得不容易收斂,可以像VGGNet那樣通過首先訓練一個淺層的網(wǎng)絡,再通過淺層網(wǎng)絡的參數(shù)遞進初始化深層網(wǎng)絡參數(shù),也可以根據(jù)輸入輸出通道數(shù)的范圍來初始化初始值,一般以輸入通道數(shù)較為常見;對于全連接網(wǎng)絡層則采用高斯分布即可;對于shortcut的batch norm,參數(shù)gamma初始化為零。
以上思路在4分鐘訓練ImageNet項目中提升了調參效率。但調參是個浩繁的工作,后續(xù)將由內部正在測試的AutoML系統(tǒng)來進行。
通過以上三個方面,在ImageNet數(shù)據(jù)集上,機智平臺可將ResNet-50/AlexNet在batch size 為64K時訓練到基準精度!
圖示 AlexNet 收斂性優(yōu)化

圖示 ResNet-50 收斂性優(yōu)化
4.2 超大規(guī)模GPU集群(1024+GPUs)線性擴展能力
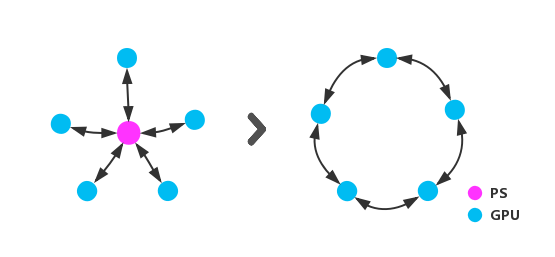
1)參數(shù)更新去中心化
數(shù)據(jù)并行訓練方式下,每一次迭代都需要做梯度規(guī)約,以TensorFlow為代表的經典分布式訓練部署方式中,中心化的參數(shù)服務器(Parameter Server)承擔了梯度的收集、平均和分發(fā)工作,這樣的部署方式下PS的訪問帶寬容易成為瓶頸,嚴重影響可擴展性,機智團隊最初應對方法是引入HPC領域常用的去中心化的Allreduce方式,然而目前流行的NCCL2或baidu-allreduce中的Allreduce采用的基于環(huán)形拓撲的通信方式,在超大規(guī)模GPU集群場景下數(shù)據(jù)通信會有很大的延時開銷。
機智團隊進一步將Allreduce算法進行了改進,并成功的部署在1024+GPUs的異構集群中,達到了理想的擴展效率。
圖示 去中心化的參數(shù)規(guī)約

圖示 原始版本的Ring Allreduce
2)利用分層同步和梯度分段融合優(yōu)化Ring Allreduce
在分布式通信中,參數(shù)傳輸耗時可用如下公式表達:
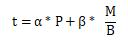
其中α代表單節(jié)點單次數(shù)據(jù)傳輸?shù)难訒r,比如準備數(shù)據(jù),發(fā)送數(shù)據(jù)接口調用等;P為數(shù)據(jù)在節(jié)點間傳輸?shù)拇螖?shù),通常是節(jié)點個數(shù)的一個倍數(shù),β為參數(shù)傳輸耗時的系數(shù),不同參數(shù)傳輸方法,這個系數(shù)不同;B為網(wǎng)絡帶寬,M為參數(shù)總字節(jié)數(shù),(M/B)為單次完整參數(shù)傳輸耗時。[6]
由以上公式可以看出,參數(shù)M越大,第二項所占的比重就越大,受第一項的影響就越小,即P對整體時間的影響則越小;參數(shù)M越小,則第一項所占的時間不可忽略,隨著P的增大,對總體時間則影響越大。對于傳輸采取Ring Allreduce算法來講,全局規(guī)約操作對帶寬的需求接近于常數(shù),不隨節(jié)點數(shù)增加而增加,所以β* (M/B)接近為常數(shù),可變因數(shù)為α* P;網(wǎng)絡模型越小,傳輸?shù)臄?shù)據(jù)量越小越散,則α* P 這塊的比重越大,整體的擴展性也就越差。
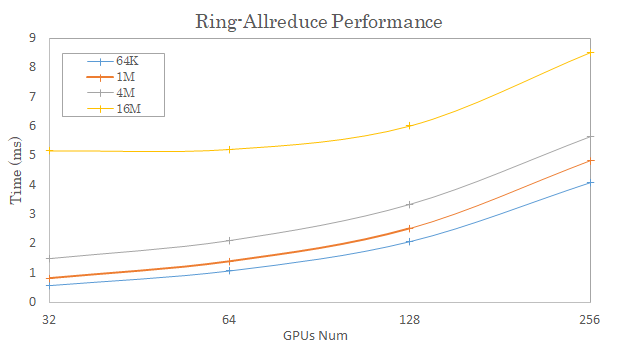
比如,在AlexNet神經網(wǎng)絡中,除了兩層參數(shù)量較大的全連接層,其余的BN層和卷積層參數(shù)量較少,各層的參數(shù)分布差異很大。在我們的實驗環(huán)境中,使用Ring Allreduce傳輸方式,測試不同數(shù)據(jù)包大小傳輸耗時如下圖所示。從圖中可以看出,Ring Allreduce的時間開銷會隨著GPU個數(shù)的增加而顯著增大。
圖示 Ring-Allreduce不同節(jié)點數(shù)下的傳輸耗時
此外,傳輸數(shù)據(jù)塊太小也不能充分利用帶寬,多個小塊傳輸帶來極大的overhead,如圖所示。可以看到發(fā)送同量數(shù)據(jù)時,小數(shù)據(jù)包額外開銷大,不能高效利用帶寬。
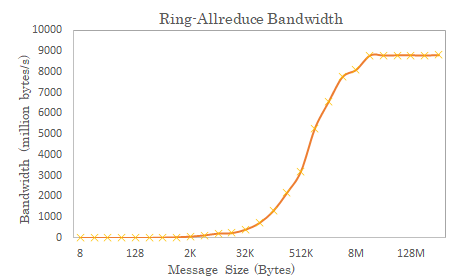
圖示 在100Gbps RoCE v2網(wǎng)絡中使用2機8卡Ring-Allreduce測試帶寬
經過以上對神經網(wǎng)絡每層的參數(shù)和數(shù)據(jù)包傳輸特性的分析,機智團隊得出以下結論:
(1)隨著集群節(jié)點增多,Ring Allreduce傳輸模式不夠高效。隨著節(jié)點增多,傳輸耗時中α* P部分比例會逐步增大。
(2)Ring Allreduce算法對小Tensor不夠友好。算法將待規(guī)約的數(shù)據(jù)拆分為N等份(N為節(jié)點總數(shù)),這導致節(jié)點數(shù)大幅增加時,Tensor碎片化,通信網(wǎng)絡傳輸大量小數(shù)據(jù)包,帶寬利用率很低。
針對上述問題,機智團隊提出了如下改進方案:
(1)分層同步與Ring Allreduce有機結合:對集群內GPU節(jié)點進行分組,減少P對整體時間的影響。如前論述,當P的值對系統(tǒng)性能影響較大時,根據(jù)具體的集群網(wǎng)絡結構分層,同時跨節(jié)點規(guī)約使用Ring Allreduce算法規(guī)約, 這一改進有效的減少了每層Ring參與的節(jié)點數(shù),降低了傳輸耗時中α* P 的占比。如下圖所示。原本需要對16個(即P=16)GPU進行AllReduce,現(xiàn)將16個GPU分為4組,每組4個GPU,首先在組內進行Reduce(4組并行執(zhí)行,P1=4),然后再以每組的主GPU間進行Allreduce(P2=4),最后在每組內進行Broadcast(P3=4),這樣便大大地減少了P的影響,從而提高Allreduce的性能。
(2)梯度融合,多次梯度傳輸合并為一次:根據(jù)具體模型設置合適的Tensor size閾值,將多次梯度傳輸合并為一次,同時超過閾值大小的Tensor不再參與融合;這樣可以防止Tensor過度碎片化,從而提升了帶寬利用率,降低了傳輸耗時。
(3)GDR技術加速Ring Allreduce:在前述方案的基礎上,將GDR技術應用于跨節(jié)點Ring,這減少了主存和顯存之間的Copy操作,同時為GPU執(zhí)行規(guī)約計算提供了便利;
注:GDR(GPU Direct RDMA)是RDMA技術的GPU版本,可以提供遠程節(jié)點間顯存直接訪問,能大幅降低了CPU工作負載。
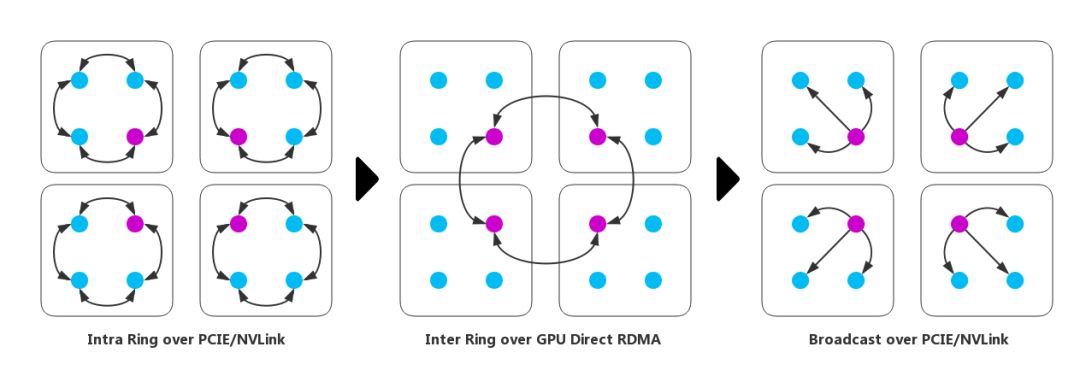
圖示 改進的分層Ring Allreduce with GDR
在具體到ImageNet訓練問題中,在測試梯度融合時,機智團隊根據(jù)對模型各層參數(shù)大小分析和實測結果,提出了分段融合策略,將AlexNet和ResNet-50各層分為兩段,各融合為一個Tensor參與Ring Allreduce。經過測試和分析,在1024卡場景下,AlexNet在20層和21層處分段可以達到最好效果;ResNet-50在76層和77層之間分段速度達到最優(yōu),如下圖所示。
經分段融合策略后,極大提高了反向計算和傳輸?shù)牟⑿卸龋嵘擞柧毸俣取D壳胺侄稳诤弦芽筛鶕?jù)前向計算和反向計算耗時,及傳輸耗時,結合實際硬件配置和網(wǎng)絡模型對傳輸性能進行建模,自動實現(xiàn)最優(yōu)分段策略,自適應地選擇需要合并的參數(shù),以達到系統(tǒng)最佳擴展性能。
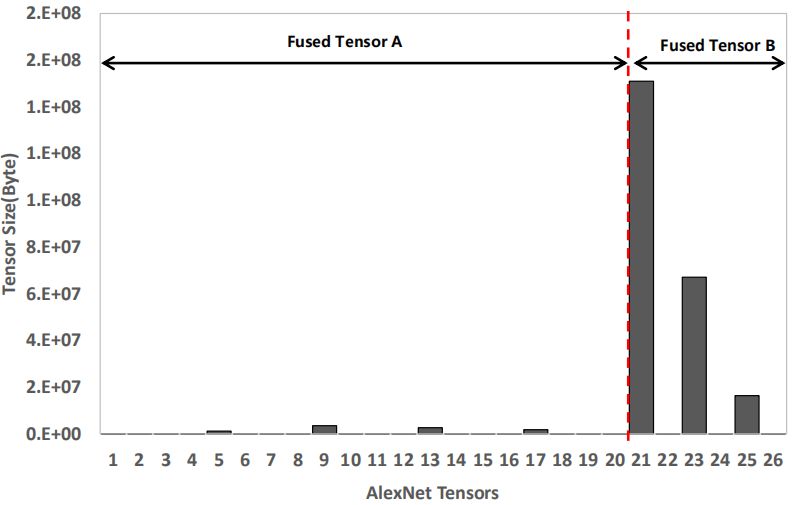
圖示 AlexNet梯度分段融合策略

圖示 ResNet-50梯度分段融合策略
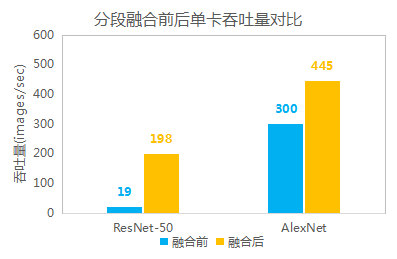
圖示 1024卡場景下分段融合前后吞吐量對比
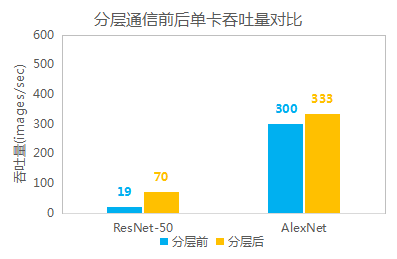
圖示 1024卡場景下分層同步前后吞吐量對比
3)使用Pipeline機制降低IO延遲
GPU引入深度學習之后,模型訓練速度越來越快,最優(yōu)加速性能不僅依賴于高速的計算硬件,也要求有一個高效的數(shù)據(jù)輸入管道。
在一輪訓練迭代中,CPU首先從磁盤讀取數(shù)據(jù)并作預處理,然后將數(shù)據(jù)加載到計算設備(GPU)上去。一般實現(xiàn)中,當 CPU 在準備數(shù)據(jù)時,GPU處于閑置狀態(tài);相反,當GPU在訓練模型時,CPU 處于閑置狀態(tài)。因此,總訓練時間是 CPU預處理 和 GPU訓練時間的總和。
機智團隊為解決IO問題,將訓練樣本集部署在由SSD盤組成的存儲系統(tǒng)上,以保證CPU訪問數(shù)據(jù)的帶寬不受網(wǎng)絡限制;同時,更為關鍵的是引入了Pipeline機制,該機制將一次訓練迭代中的數(shù)據(jù)讀入及處理和模型計算并行起來,在做模型計算的同時做下一輪迭代的數(shù)據(jù)讀取處理并放入自定義“無鎖”隊列,并通過GPU預取機制提前把處理好的數(shù)據(jù)從隊列中同步到GPU顯存中,當做下一輪的模型計算時直接從顯存讀取數(shù)據(jù)而不需要再從CPU或磁盤讀取,做到將數(shù)據(jù)讀取隱藏,IO和計算并行起來。

圖示 Pipeline機制示意圖
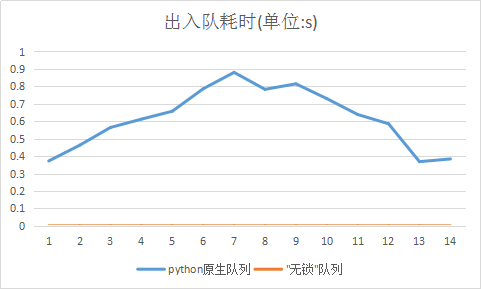
圖示 “無鎖”隊列出入隊耗時對比
通過以上三方面,機智平臺在1024卡以上跑ResNet-50,擴展性也可以達到~99%,在2048卡上跑ResNet-50,擴展性還可以保持在97%!
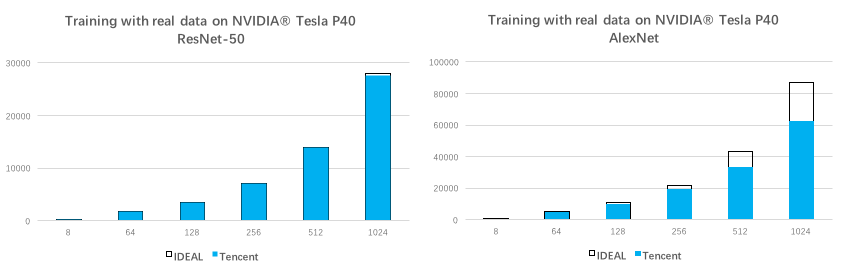
圖示 ResNet-50/AlexNet多機擴展性
平臺價值
人工智能越來越多的融入到人們生活當中,涵蓋各行各業(yè),包括衣食住行,交通、個性化產品等;可以服務于人們需求的人工智能服務在未來會像水和電一樣成為基本需求,機智機器學習平臺正是在這種背景下應運而生。
提升訓練ImageNet的速度,只是機智團隊推動AI發(fā)展工作中一小部分;事實上,服務好游戲AI等AI業(yè)務,助力AI團隊在建設AI服務時,聚焦用戶需求,而AI服務背后的模型訓練、優(yōu)化,模型部署和運營觸手可得,才是機智的真正使命。機智機器學習平臺當前主要提供訓練加速能力。
1)訓練加速
快速完成模型訓練意味著可以做更多的模型/算法嘗試;這不僅是體現(xiàn)平臺能力的一個重要指標,也是增加業(yè)務競爭力的一個關鍵所在。如果一個產品模型的訓練時間以周記或以月記,那這個產品也是生命力不旺盛的。以下是機智的兩個典型應用案例:
?X業(yè)務的訓練數(shù)據(jù)是結構化數(shù)據(jù)且量大,模型比較復雜;一直以來訓練好一個模型需要一天以上,這對于快速迭代模型算法來說是遠遠不夠的。在應用了機智機器學習平臺后,可以在約10分鐘時間迭代一個模型,極大的加速了訓練迭代效率,為業(yè)務的成功奠定了堅實的基礎。
?計算機視覺,是人工智能應用的重要領域,已在交通、安防、零售、機器人等各種場景中應用開來。計算機視覺中網(wǎng)絡模型的關鍵部件就是CNN,快速的將CNN網(wǎng)絡訓練好可以極大的提升產品落地速度。以業(yè)界最著名的ImageNet數(shù)據(jù)集為例,要將ResNet-50模型在其上訓練到75%以上準確率,普通單機單卡需要一周左右時間。在機智機器學習平臺上,這樣的應用只需要6.6分鐘。
展望
未來,機智團隊將繼續(xù)保障游戲AI業(yè)務的快速迭代,把解決imagenet訓練問題中所積累的加速方案應用到游戲AI中,將游戲AI的大batch size收斂問題和訓練速度問題徹底解決,協(xié)助業(yè)務取得新的突破性成果。此外,機智團隊將在平臺性能,功能上持續(xù)完善:
1)平臺性能
機智將結合模型壓縮/剪枝,量化技術,在通信傳輸中統(tǒng)籌多種all-reduce算法,做到對不同場景的模型:
?計算瓶頸的模型多機達到線性擴展
?傳輸瓶頸的模型多機達到90%以上擴展效率
2)平臺功能
a)AutoML(自動調參)
機智團隊認為,算法工程師應當專注于創(chuàng)建新網(wǎng)絡,推導新公式,調整超參數(shù)的浩繁工作,交給機智平臺幫你自動完成。
b)一站式的管理服務
機器學習的模型訓練過程是個復雜的系統(tǒng)工整,涉及到對可視化任務的管理,對各種資源的管理(比如CPU, GPU, FPGA, ASIC等)和調度,對訓練數(shù)據(jù)和結果數(shù)據(jù)的管理,高質量的服務體系等,將這一整套流程都打通,并且做到對用戶友好,所見即所得,是算法工程師驗證想法最基本的需求。機智平臺將提供一站式的管理服務,想你所想,助你成功。
此外,計算機視覺類加速只是起點,未來在功能方面,機智平臺將支持多場景、多模型;結合更廣義的AutoML技術,讓AI技術賦能更廣大的業(yè)務,我們的目標是:
為用戶提供訓練,推理,模型托管全流程計算加速服務。
最終,建立從訓練加速到部署上線一站式服務平臺,打造AI服務基礎設施,助力AI業(yè)務取得成功。
致謝
在研究和解決imagenet訓練項目中,機智團隊小伙伴們通力合作,最終在這個問題上取得了突破。在此要特別感謝團隊內小伙伴——TEG兄弟部門運營管理部,香港浸會大學計算機科學系褚曉文教授團隊;是大家的精誠團結和專業(yè)精神,才得以讓我們在這個業(yè)界權威基準上取得新的重大突破。
此外還要隆重感謝機智平臺合作伙伴——TEG兄弟部門AI平臺部,網(wǎng)絡平臺部,感謝兄弟部門小伙伴們一直以來的支持和信任。期盼在未來的前進道路上,機智團隊仍然能與各位同行,去創(chuàng)造新的好成績。
-
機器學習
+關注
關注
66文章
8493瀏覽量
134161 -
數(shù)據(jù)集
+關注
關注
4文章
1223瀏覽量
25294
原文標題:世界紀錄!4分鐘訓練完ImageNet!可擴展超大規(guī)模GPU收斂算法詳解
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
當訓練好的神經網(wǎng)絡用于應用的時候,權值是不是不能變了?
請教Vision做OCR識別數(shù)字,可以訓練,但訓練好的對訓練樣本處理出現(xiàn)問題,見圖片閾值無法調節(jié),求教_(:зゝ∠)_
請問Labveiw如何調用matlab訓練好的神經網(wǎng)絡模型呢?
基于Keras利用訓練好的hdf5模型進行目標檢測實現(xiàn)輸出模型中的表情或性別gradcam
MATLAB訓練好的神經網(wǎng)絡移植到STM32F407上
用S3C2440訓練神經網(wǎng)絡算法
【CANN訓練營第三季】基于Caffe ResNet-50網(wǎng)絡實現(xiàn)圖片分類
事半功倍 VR訓練可讓運動員訓練效果倍增
node.js在訓練好的神經網(wǎng)絡模型識別圖像中物體的方法
索尼發(fā)布新的方法,在ImageNet數(shù)據(jù)集上224秒內成功訓練了ResNet-50
嵌入式AI簡報 |特斯拉發(fā)布AI訓練芯片Dojo D1






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論