 幾種常見的用于回歸問題的機器學習算法
幾種常見的用于回歸問題的機器學習算法
當我們要解決任意一種機器學習問題時,都需要選擇合適的算法。在機器學習中存在一種“沒有免費的午餐”定律,即沒有一款機器學習模型可以解決所有問題。不同的機器學習算法表現取決于數據的大小和結構。所以,除非用傳統的試錯法實驗,否則我們沒有明確的方法證明某種選擇是對的。
但是,每種機器學習算法都有各自的有缺點,這也能讓我們在選擇時有所參考。雖然一種算法不能通用,但每個算法都有一些特征,能讓人快速選擇并調整參數。接下來,我們大致瀏覽幾種常見的用于回歸問題的機器學習算法,并根據它們的優點和缺點總結出在什么情況下可以使用。
線性和多項式回歸
首先是簡單的情況,單一變量的線性回歸是用于表示單一輸入自變量和因變量之間的關系的模型。多變量線性回歸更常見,其中模型是表示多個輸入自變量和輸出因變量之間的關系。模型保持線性是因為輸出是輸入變量的線性結合。
第三種行間情況稱為多項式回歸,這里的模型是特征向量的非線性結合,即向量是指數變量,sin、cos等等。這種情況需要考慮數據和輸出之間的關系,回歸模型可以用隨機梯度下降訓練。
優點:
建模速度快,在模型結構不復雜并且數據較少的情況下很有用。
線性回歸易于理解,在商業決策時很有價值。
缺點:
對非線性數據來說,多項式回歸在設計時有難度,因為在這種情況下必須了解數據結構和特征變量之間的關系。
綜上,遇到復雜數據時,這些模型的表現就不理想了。
神經網絡包含了許多互相連接的節點,稱為神經元。輸入的特征變量經過這些神經元后變成多變量的線性組合,與各個特征變量相乘的值稱為權重。之后在這一線性結合上應用非線性,使得神經網絡可以對復雜的非線性關系建模。神經網絡可以有多個圖層,一層的輸出會傳遞到下一層。在輸出時,通常不會應用非線性。神經網絡用隨機梯度下降和反向傳播算法訓練。
優點:
由于神經網絡有很多層(所以就有很多參數),同時是非線性的,它們能高效地對復雜的非線性關系進行建模。
通常我們不用擔心神經網絡中的數據,它們在學習任何特征向量關系時都很靈活。
研究表明,單單增加神經網絡的訓練數據,不論是新數據還是對原始數據進行增強,都會提高網絡性能。
缺點:
由于模型的復雜性,它們不容易被理解。
訓練時可能有難度,同時需要大量計算力、仔細地調參并且設置好學習速率。
它們需要大量數據才能達到較高的性能,與其他機器學習相比,在小數據集上通常表現更優。
回歸樹和隨機森林
首先從基本情況開始,決策樹是一種直觀的模型,決策者需要在每個節點進行選擇,從而穿過整個“樹”。樹形歸納是將一組訓練樣本作為輸入,決定哪些從哪些屬性分割數據,不斷重復這一過程,知道所有訓練樣本都被歸類。在構建樹時,我們的目標是用數據分割創建最純粹的子節點。純粹性是通過信息增益的概念來衡量的。在實際中,這是通過比較熵或區分當前數據集中的單一樣本和所需信息量與當前數據需要進一步區分所需要的信息量。
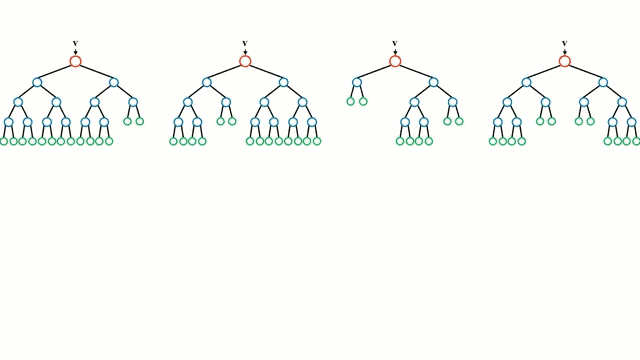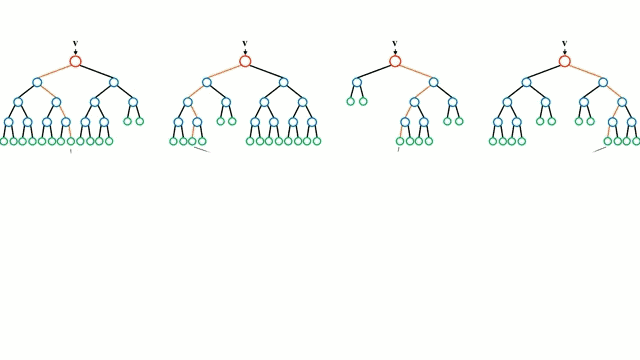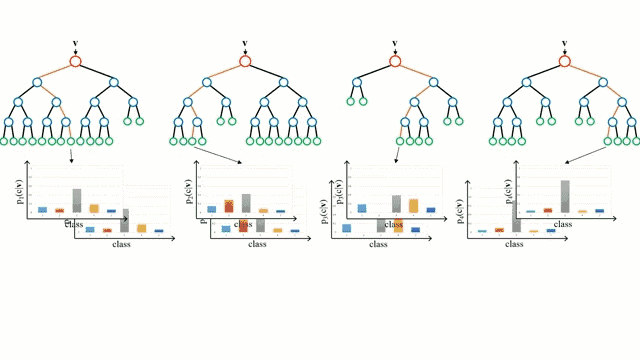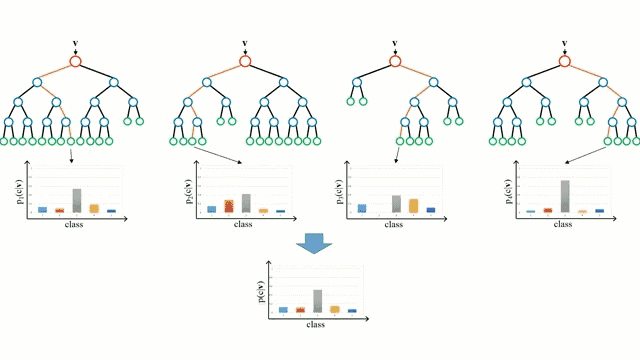
隨機森林是決策樹的簡單集成,即是輸入向量經過多個決策樹的過程。對于回歸,所有樹的輸出值是平均的;對于分類,最終要用投票策略決定。
優點:
對復雜、高度非線性的關系非常實用。它們通常能達到非常高的表現性能,比多項式回歸更好。
易于使用理解。雖然最后的訓練模型會學會很多復雜的關系,但是訓練過程中的決策邊界易于理解。
缺點:
由于訓練決策樹的本質,它們更易于過度擬合。一個完整的決策樹模型會非常復雜,并包含很多不必要的結構。雖然有時通過“修剪”和與更大的隨機森林結合可以減輕這一狀況。
利用更大的隨機森林,可以達到更好地效果,但同時會拖慢速度,需要更多內存。
這就是三種算法的優缺點總結。希望你覺得有用!
-
神經網絡
+關注
關注
42文章
4811瀏覽量
103013 -
機器學習
+關注
關注
66文章
8496瀏覽量
134217
原文標題:如何為你的回歸問題選擇最合適的機器學習算法?
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「# ROS 2智能機器人開發實踐」閱讀體驗】視覺實現的基礎算法的應用
十大鮮為人知卻功能強大的機器學習模型

常見網絡負載均衡的幾種方式
機器學習模型市場前景如何
常見xgboost錯誤及解決方案
華為云 Flexus X 實例部署安裝 Jupyter Notebook,學習 AI,機器學習算法
傳統機器學習方法和應用指導

zeta在機器學習中的應用 zeta的優缺點分析
NPU與機器學習算法的關系
人工智能、機器學習和深度學習存在什么區別






 工商網監
工商網監
評論