") 總結(jié)機(jī)器學(xué)習(xí)小白必學(xué)的10種算法
總結(jié)機(jī)器學(xué)習(xí)小白必學(xué)的10種算法

在機(jī)器學(xué)習(xí)中,有一種叫做「沒(méi)有免費(fèi)的午餐」的定理。簡(jiǎn)而言之,它指出沒(méi)有任何一種算法對(duì)所有問(wèn)題都有效,在監(jiān)督學(xué)習(xí)(即預(yù)測(cè)建模)中尤其如此。
例如,你不能說(shuō)神經(jīng)網(wǎng)絡(luò)總是比決策樹好,反之亦然。有很多因素在起作用,例如數(shù)據(jù)集的大小和結(jié)構(gòu)。
因此,你應(yīng)該針對(duì)具體問(wèn)題嘗試多種不同算法,并留出一個(gè)數(shù)據(jù)「測(cè)試集」來(lái)評(píng)估性能、選出優(yōu)勝者。
當(dāng)然,你嘗試的算法必須適合你的問(wèn)題,也就是選擇正確的機(jī)器學(xué)習(xí)任務(wù)。打個(gè)比方,如果你需要打掃房子,你可能會(huì)用吸塵器、掃帚或拖把,但是你不會(huì)拿出鏟子開始挖土。
大原則
不過(guò)也有一個(gè)普遍原則,即所有監(jiān)督機(jī)器學(xué)習(xí)算法預(yù)測(cè)建模的基礎(chǔ)。
機(jī)器學(xué)習(xí)算法被描述為學(xué)習(xí)一個(gè)目標(biāo)函數(shù) f,該函數(shù)將輸入變量 X 最好地映射到輸出變量 Y:Y = f(X)
這是一個(gè)普遍的學(xué)習(xí)任務(wù),我們可以根據(jù)輸入變量 X 的新樣本對(duì) Y 進(jìn)行預(yù)測(cè)。我們不知道函數(shù) f 的樣子或形式。如果我們知道的話,我們將會(huì)直接使用它,不需要用機(jī)器學(xué)習(xí)算法從數(shù)據(jù)中學(xué)習(xí)。
最常見(jiàn)的機(jī)器學(xué)習(xí)算法是學(xué)習(xí)映射 Y = f(X) 來(lái)預(yù)測(cè)新 X 的 Y。這叫做預(yù)測(cè)建模或預(yù)測(cè)分析,我們的目標(biāo)是盡可能作出最準(zhǔn)確的預(yù)測(cè)。
對(duì)于想了解機(jī)器學(xué)習(xí)基礎(chǔ)知識(shí)的新手,本文將概述數(shù)據(jù)科學(xué)家使用的 top 10 機(jī)器學(xué)習(xí)算法。
1. 線性回歸
線性回歸可能是統(tǒng)計(jì)學(xué)和機(jī)器學(xué)習(xí)中最知名和最易理解的算法之一。
預(yù)測(cè)建模主要關(guān)注最小化模型誤差或者盡可能作出最準(zhǔn)確的預(yù)測(cè),以可解釋性為代價(jià)。我們將借用、重用包括統(tǒng)計(jì)學(xué)在內(nèi)的很多不同領(lǐng)域的算法,并將其用于這些目的。
線性回歸的表示是一個(gè)方程,它通過(guò)找到輸入變量的特定權(quán)重(稱為系數(shù) B),來(lái)描述一條最適合表示輸入變量 x 與輸出變量 y 關(guān)系的直線。
例如:y = B0 + B1 * x
我們將根據(jù)輸入 x 預(yù)測(cè) y,線性回歸學(xué)習(xí)算法的目標(biāo)是找到系數(shù) B0 和 B1 的值。
可以使用不同的技術(shù)從數(shù)據(jù)中學(xué)習(xí)線性回歸模型,例如用于普通最小二乘法和梯度下降優(yōu)化的線性代數(shù)解。
線性回歸已經(jīng)存在了 200 多年,并得到了廣泛研究。使用這種技術(shù)的一些經(jīng)驗(yàn)是盡可能去除非常相似(相關(guān))的變量,并去除噪音。這是一種快速、簡(jiǎn)單的技術(shù),可以首先嘗試一下。
2. Logistic 回歸
Logistic 回歸是機(jī)器學(xué)習(xí)從統(tǒng)計(jì)學(xué)中借鑒的另一種技術(shù)。它是解決二分類問(wèn)題的首選方法。
Logistic 回歸與線性回歸相似,目標(biāo)都是找到每個(gè)輸入變量的權(quán)重,即系數(shù)值。與線性回歸不同的是,Logistic 回歸對(duì)輸出的預(yù)測(cè)使用被稱為 logistic 函數(shù)的非線性函數(shù)進(jìn)行變換。
logistic 函數(shù)看起來(lái)像一個(gè)大的 S,并且可以將任何值轉(zhuǎn)換到 0 到 1 的區(qū)間內(nèi)。這非常實(shí)用,因?yàn)槲覀兛梢砸?guī)定 logistic 函數(shù)的輸出值是 0 和 1(例如,輸入小于 0.5 則輸出為 1)并預(yù)測(cè)類別值。
由于模型的學(xué)習(xí)方式,Logistic 回歸的預(yù)測(cè)也可以作為給定數(shù)據(jù)實(shí)例(屬于類別 0 或 1)的概率。這對(duì)于需要為預(yù)測(cè)提供更多依據(jù)的問(wèn)題很有用。
像線性回歸一樣,Logistic 回歸在刪除與輸出變量無(wú)關(guān)的屬性以及非常相似(相關(guān))的屬性時(shí)效果更好。它是一個(gè)快速的學(xué)習(xí)模型,并且對(duì)于二分類問(wèn)題非常有效。
3. 線性判別分析(LDA)
Logistic 回歸是一種分類算法,傳統(tǒng)上,它僅限于只有兩類的分類問(wèn)題。如果你有兩個(gè)以上的類別,那么線性判別分析是首選的線性分類技術(shù)。
LDA 的表示非常簡(jiǎn)單直接。它由數(shù)據(jù)的統(tǒng)計(jì)屬性構(gòu)成,對(duì)每個(gè)類別進(jìn)行計(jì)算。單個(gè)輸入變量的 LDA 包括:
每個(gè)類別的平均值;
所有類別的方差。
進(jìn)行預(yù)測(cè)的方法是計(jì)算每個(gè)類別的判別值并對(duì)具備最大值的類別進(jìn)行預(yù)測(cè)。該技術(shù)假設(shè)數(shù)據(jù)呈高斯分布(鐘形曲線),因此最好預(yù)先從數(shù)據(jù)中刪除異常值。這是處理分類預(yù)測(cè)建模問(wèn)題的一種簡(jiǎn)單而強(qiáng)大的方法。
4. 分類與回歸樹
決策樹是預(yù)測(cè)建模機(jī)器學(xué)習(xí)的一種重要算法。
決策樹模型的表示是一個(gè)二叉樹。這是算法和數(shù)據(jù)結(jié)構(gòu)中的二叉樹,沒(méi)什么特別的。每個(gè)節(jié)點(diǎn)代表一個(gè)單獨(dú)的輸入變量 x 和該變量上的一個(gè)分割點(diǎn)(假設(shè)變量是數(shù)字)。
決策樹的葉節(jié)點(diǎn)包含一個(gè)用于預(yù)測(cè)的輸出變量 y。通過(guò)遍歷該樹的分割點(diǎn),直到到達(dá)一個(gè)葉節(jié)點(diǎn)并輸出該節(jié)點(diǎn)的類別值就可以作出預(yù)測(cè)。
決策樹學(xué)習(xí)速度和預(yù)測(cè)速度都很快。它們還可以解決大量問(wèn)題,并且不需要對(duì)數(shù)據(jù)做特別準(zhǔn)備。
5. 樸素貝葉斯
樸素貝葉斯是一個(gè)簡(jiǎn)單但是很強(qiáng)大的預(yù)測(cè)建模算法。
該模型由兩種概率組成,這兩種概率都可以直接從訓(xùn)練數(shù)據(jù)中計(jì)算出來(lái):1)每個(gè)類別的概率;2)給定每個(gè) x 的值,每個(gè)類別的條件概率。一旦計(jì)算出來(lái),概率模型可用于使用貝葉斯定理對(duì)新數(shù)據(jù)進(jìn)行預(yù)測(cè)。當(dāng)你的數(shù)據(jù)是實(shí)值時(shí),通常假設(shè)一個(gè)高斯分布(鐘形曲線),這樣你可以簡(jiǎn)單的估計(jì)這些概率。
樸素貝葉斯之所以是樸素的,是因?yàn)樗僭O(shè)每個(gè)輸入變量是獨(dú)立的。這是一個(gè)強(qiáng)大的假設(shè),真實(shí)的數(shù)據(jù)并非如此,但是,該技術(shù)在大量復(fù)雜問(wèn)題上非常有用。
6. K 近鄰算法
KNN 算法非常簡(jiǎn)單且有效。KNN 的模型表示是整個(gè)訓(xùn)練數(shù)據(jù)集。是不是很簡(jiǎn)單?
KNN 算法在整個(gè)訓(xùn)練集中搜索 K 個(gè)最相似實(shí)例(近鄰)并匯總這 K 個(gè)實(shí)例的輸出變量,以預(yù)測(cè)新數(shù)據(jù)點(diǎn)。對(duì)于回歸問(wèn)題,這可能是平均輸出變量,對(duì)于分類問(wèn)題,這可能是眾數(shù)(或最常見(jiàn)的)類別值。
訣竅在于如何確定數(shù)據(jù)實(shí)例間的相似性。如果屬性的度量單位相同(例如都是用英寸表示),那么最簡(jiǎn)單的技術(shù)是使用歐幾里得距離,你可以根據(jù)每個(gè)輸入變量之間的差值直接計(jì)算出來(lái)其數(shù)值。
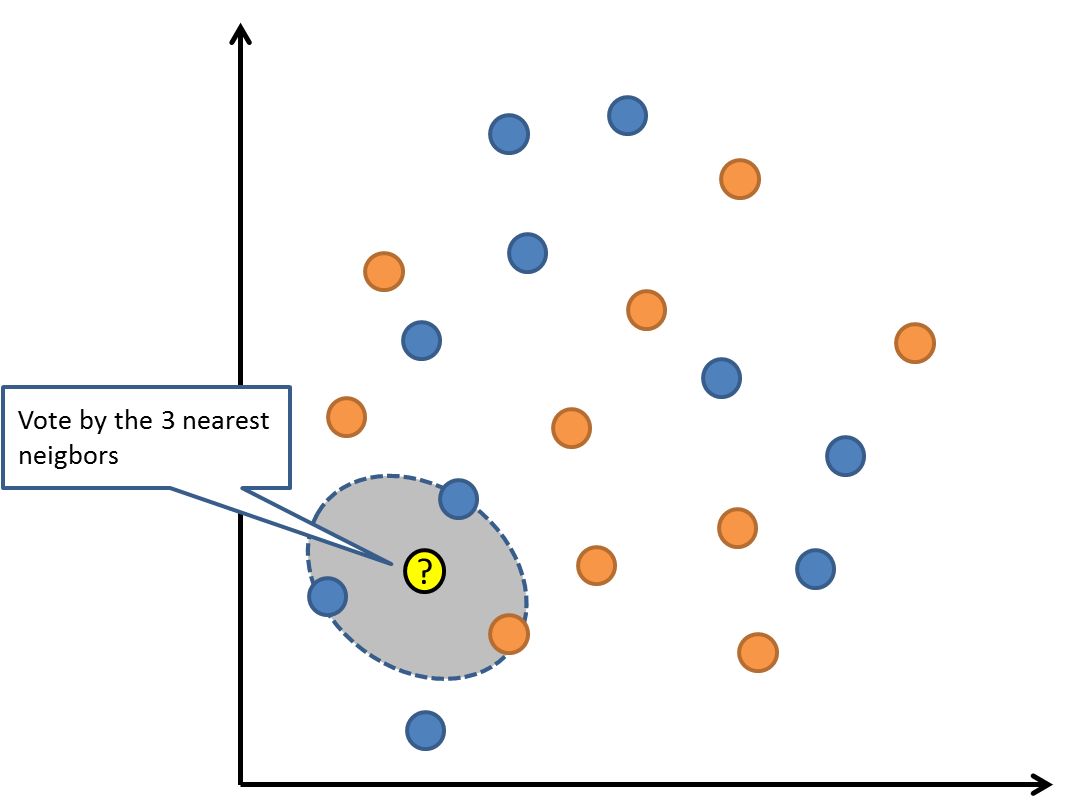
KNN 需要大量?jī)?nèi)存或空間來(lái)存儲(chǔ)所有數(shù)據(jù),但是只有在需要預(yù)測(cè)時(shí)才執(zhí)行計(jì)算(或?qū)W習(xí))。你還可以隨時(shí)更新和管理訓(xùn)練實(shí)例,以保持預(yù)測(cè)的準(zhǔn)確性。
距離或緊密性的概念可能在非常高的維度(很多輸入變量)中會(huì)瓦解,這對(duì)算法在你的問(wèn)題上的性能產(chǎn)生負(fù)面影響。這被稱為維數(shù)災(zāi)難。因此你最好只使用那些與預(yù)測(cè)輸出變量最相關(guān)的輸入變量。
7. 學(xué)習(xí)向量量化
K 近鄰算法的一個(gè)缺點(diǎn)是你需要遍歷整個(gè)訓(xùn)練數(shù)據(jù)集。學(xué)習(xí)向量量化算法(簡(jiǎn)稱 LVQ)是一種人工神經(jīng)網(wǎng)絡(luò)算法,它允許你選擇訓(xùn)練實(shí)例的數(shù)量,并精確地學(xué)習(xí)這些實(shí)例應(yīng)該是什么樣的。
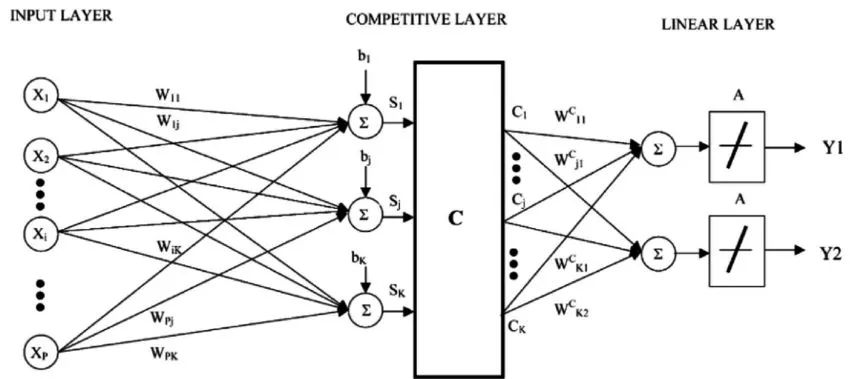
LVQ 的表示是碼本向量的集合。這些是在開始時(shí)隨機(jī)選擇的,并逐漸調(diào)整以在學(xué)習(xí)算法的多次迭代中最好地總結(jié)訓(xùn)練數(shù)據(jù)集。在學(xué)習(xí)之后,碼本向量可用于預(yù)測(cè)(類似 K 近鄰算法)。最相似的近鄰(最佳匹配的碼本向量)通過(guò)計(jì)算每個(gè)碼本向量和新數(shù)據(jù)實(shí)例之間的距離找到。然后返回最佳匹配單元的類別值或(回歸中的實(shí)際值)作為預(yù)測(cè)。如果你重新調(diào)整數(shù)據(jù),使其具有相同的范圍(比如 0 到 1 之間),就可以獲得最佳結(jié)果。
如果你發(fā)現(xiàn) KNN 在你的數(shù)據(jù)集上達(dá)到很好的結(jié)果,請(qǐng)嘗試用 LVQ 減少存儲(chǔ)整個(gè)訓(xùn)練數(shù)據(jù)集的內(nèi)存要求。
8. 支持向量機(jī)(SVM)
支持向量機(jī)可能是最受歡迎和最廣泛討論的機(jī)器學(xué)習(xí)算法之一。
超平面是分割輸入變量空間的一條線。在 SVM 中,選擇一條可以最好地根據(jù)輸入變量類別(類別 0 或類別 1)對(duì)輸入變量空間進(jìn)行分割的超平面。在二維中,你可以將其視為一條線,我們假設(shè)所有的輸入點(diǎn)都可以被這條線完全的分開。SVM 學(xué)習(xí)算法找到了可以讓超平面對(duì)類別進(jìn)行最佳分割的系數(shù)。
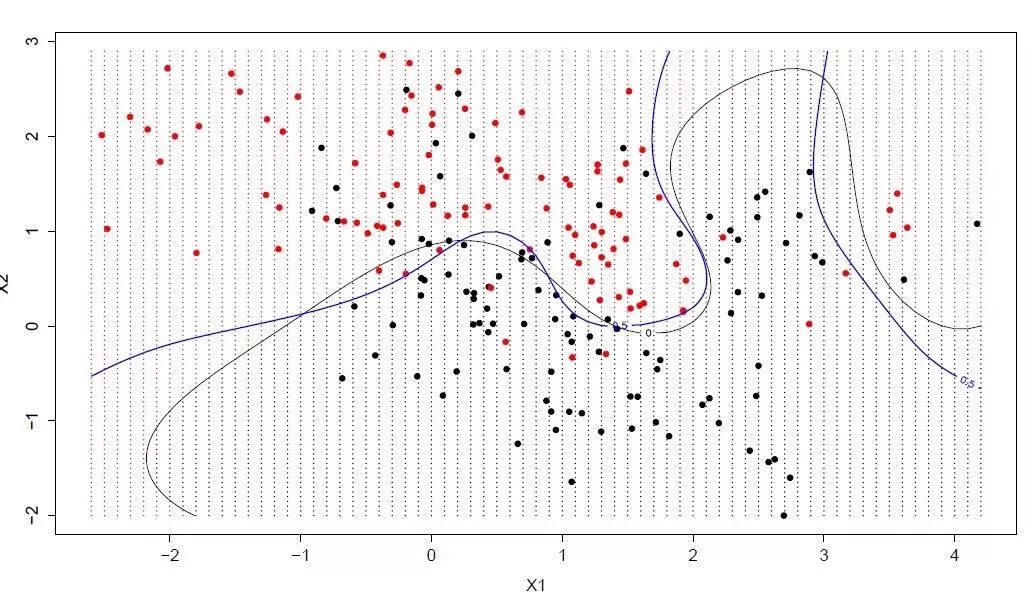
超平面和最近的數(shù)據(jù)點(diǎn)之間的距離被稱為間隔。分開兩個(gè)類別的最好的或最理想的超平面具備最大間隔。只有這些點(diǎn)與定義超平面和構(gòu)建分類器有關(guān)。這些點(diǎn)被稱為支持向量,它們支持或定義了超平面。實(shí)際上,優(yōu)化算法用于尋找最大化間隔的系數(shù)的值。
SVM 可能是最強(qiáng)大的立即可用的分類器之一,值得一試。
9. Bagging 和隨機(jī)森林
隨機(jī)森林是最流行和最強(qiáng)大的機(jī)器學(xué)習(xí)算法之一。它是 Bootstrap Aggregation(又稱 bagging)集成機(jī)器學(xué)習(xí)算法的一種。
bootstrap 是從數(shù)據(jù)樣本中估算數(shù)量的一種強(qiáng)大的統(tǒng)計(jì)方法。例如平均數(shù)。你從數(shù)據(jù)中抽取大量樣本,計(jì)算平均值,然后平均所有的平均值以便更好的估計(jì)真實(shí)的平均值。
bagging 使用相同的方法,但是它估計(jì)整個(gè)統(tǒng)計(jì)模型,最常見(jiàn)的是決策樹。在訓(xùn)練數(shù)據(jù)中抽取多個(gè)樣本,然后對(duì)每個(gè)數(shù)據(jù)樣本建模。當(dāng)你需要對(duì)新數(shù)據(jù)進(jìn)行預(yù)測(cè)時(shí),每個(gè)模型都進(jìn)行預(yù)測(cè),并將所有的預(yù)測(cè)值平均以便更好的估計(jì)真實(shí)的輸出值。
隨機(jī)森林是對(duì)這種方法的一種調(diào)整,在隨機(jī)森林的方法中決策樹被創(chuàng)建以便于通過(guò)引入隨機(jī)性來(lái)進(jìn)行次優(yōu)分割,而不是選擇最佳分割點(diǎn)。
因此,針對(duì)每個(gè)數(shù)據(jù)樣本創(chuàng)建的模型將會(huì)與其他方式得到的有所不同,不過(guò)雖然方法獨(dú)特且不同,它們?nèi)匀皇菧?zhǔn)確的。結(jié)合它們的預(yù)測(cè)可以更好的估計(jì)真實(shí)的輸出值。
如果你用方差較高的算法(如決策樹)得到了很好的結(jié)果,那么通常可以通過(guò) bagging 該算法來(lái)獲得更好的結(jié)果。
10. Boosting 和 AdaBoost
Boosting 是一種集成技術(shù),它試圖集成一些弱分類器來(lái)創(chuàng)建一個(gè)強(qiáng)分類器。這通過(guò)從訓(xùn)練數(shù)據(jù)中構(gòu)建一個(gè)模型,然后創(chuàng)建第二個(gè)模型來(lái)嘗試糾正第一個(gè)模型的錯(cuò)誤來(lái)完成。一直添加模型直到能夠完美預(yù)測(cè)訓(xùn)練集,或添加的模型數(shù)量已經(jīng)達(dá)到最大數(shù)量。
AdaBoost 是第一個(gè)為二分類開發(fā)的真正成功的 boosting 算法。這是理解 boosting 的最佳起點(diǎn)。現(xiàn)代 boosting 方法建立在 AdaBoost 之上,最顯著的是隨機(jī)梯度提升。
AdaBoost 與短決策樹一起使用。在第一個(gè)決策樹創(chuàng)建之后,利用每個(gè)訓(xùn)練實(shí)例上樹的性能來(lái)衡量下一個(gè)決策樹應(yīng)該對(duì)每個(gè)訓(xùn)練實(shí)例付出多少注意力。難以預(yù)測(cè)的訓(xùn)練數(shù)據(jù)被分配更多權(quán)重,而容易預(yù)測(cè)的數(shù)據(jù)分配的權(quán)重較少。依次創(chuàng)建模型,每個(gè)模型在訓(xùn)練實(shí)例上更新權(quán)重,影響序列中下一個(gè)決策樹的學(xué)習(xí)。在所有決策樹建立之后,對(duì)新數(shù)據(jù)進(jìn)行預(yù)測(cè),并且通過(guò)每個(gè)決策樹在訓(xùn)練數(shù)據(jù)上的精確度評(píng)估其性能。
因?yàn)樵诩m正算法錯(cuò)誤上投入了太多注意力,所以具備已刪除異常值的干凈數(shù)據(jù)非常重要。
總結(jié)
初學(xué)者在面對(duì)各種機(jī)器學(xué)習(xí)算法時(shí)經(jīng)常問(wèn):「我應(yīng)該用哪個(gè)算法?」這個(gè)問(wèn)題的答案取決于很多因素,包括:
(1)數(shù)據(jù)的大小、質(zhì)量和特性;
(2)可用的計(jì)算時(shí)間;
(3)任務(wù)的緊迫性;
(4)你想用這些數(shù)據(jù)做什么。
即使是經(jīng)驗(yàn)豐富的數(shù)據(jù)科學(xué)家在嘗試不同的算法之前,也無(wú)法分辨哪種算法會(huì)表現(xiàn)最好。雖然還有很多其他的機(jī)器學(xué)習(xí)算法,但本篇文章中討論的是最受歡迎的算法。如果你是機(jī)器學(xué)習(xí)的新手,這將是一個(gè)很好的學(xué)習(xí)起點(diǎn)。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8500瀏覽量
134418 -
線性回歸
+關(guān)注
關(guān)注
0文章
41瀏覽量
4431
原文標(biāo)題:機(jī)器學(xué)習(xí)萌新必學(xué)的Top10算法
文章出處:【微信號(hào):Imgtec,微信公眾號(hào):Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
機(jī)器學(xué)習(xí)之高級(jí)算法課程學(xué)習(xí)總結(jié)
系統(tǒng)機(jī)器學(xué)習(xí)算法總結(jié)知識(shí)分享
機(jī)器學(xué)習(xí)算法常用指標(biāo)匯總

機(jī)器學(xué)習(xí)十大算法精髓總結(jié)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論