") 深度解析知識(shí)圖譜領(lǐng)域幾次發(fā)展的主要技術(shù)突破
深度解析知識(shí)圖譜領(lǐng)域幾次發(fā)展的主要技術(shù)突破
知識(shí)圖譜是人工智能三大分支之一——符號(hào)主義——在新時(shí)期主要的落地技術(shù)方式。該技術(shù)雖然在 2012 年才得名,但它的歷史淵源,卻可以追溯到更早的語(yǔ)義網(wǎng)、描述邏輯、和專家系統(tǒng)。在該技術(shù)的的歷史演變中,多次出現(xiàn)發(fā)展瓶頸,也多次以工程的方式突破了這些瓶頸。
AI科技大本營(yíng)此次邀請(qǐng)到文因互聯(lián) CEO 鮑捷,作為知識(shí)圖譜領(lǐng)域形成過程的親歷者之一,他對(duì)知識(shí)圖譜的歷史淵源進(jìn)行了梳理,深度解析了該領(lǐng)域幾次發(fā)展的主要技術(shù)突破,并分析了其工業(yè)落地的幾個(gè)關(guān)鍵點(diǎn)。
鮑捷,文因互聯(lián) CEO,聯(lián)合創(chuàng)始人。他曾是三星美國(guó)研發(fā)中心研究員,倫斯勒理工學(xué)院(RPI)博士后。他是中國(guó)中文信息學(xué)會(huì)語(yǔ)言與知識(shí)計(jì)算專委會(huì)委員,W3C 顧問委員會(huì)委員,中國(guó)計(jì)算機(jī)協(xié)會(huì)會(huì)刊編委,中文開放知識(shí)圖譜聯(lián)盟(OpenKG)發(fā)起人之一。他的研究領(lǐng)域涉及人工智能諸多方向,如自然語(yǔ)言處理、語(yǔ)義網(wǎng)、機(jī)器學(xué)習(xí)、描述邏輯、信息論、神經(jīng)網(wǎng)絡(luò)、圖像識(shí)別等,已發(fā)表 70 多篇論文。
▌什么是知識(shí)圖譜?
知識(shí)圖譜到底是什么?坦白說我也沒有特別好的答案,知識(shí)圖譜從某種程度來(lái)說是一個(gè)營(yíng)銷名詞,是 2012 年谷歌提出了這樣一個(gè)項(xiàng)目叫“Knowledge Graph”。
一個(gè)有意思的定義是王昊奮老師提出來(lái)的:知識(shí)圖譜旨在描述真實(shí)世界中存在的各種實(shí)體或概念。其中,每個(gè)實(shí)體或概念用一個(gè)全局唯一確定的ID來(lái)標(biāo)識(shí),稱為它們的標(biāo)識(shí)符。每個(gè)屬性-值對(duì)用來(lái)刻畫實(shí)體的內(nèi)在特性,而關(guān)系用來(lái)連接兩個(gè)實(shí)體,刻畫它們之間的關(guān)聯(lián)。
但是在實(shí)踐中我們并不需要太過糾結(jié)什么叫知識(shí)圖譜,什么不是知識(shí)圖譜。有人問我說是否必須要用RDF(資源描述框架)才是知識(shí)圖譜?或者說是不是必須用Neo4j圖數(shù)據(jù)庫(kù)才是知識(shí)圖譜?其實(shí)不是。不在于你具體用了哪一種Syntax,哪一種數(shù)據(jù)存儲(chǔ)的數(shù)據(jù)庫(kù)。關(guān)鍵是它的本質(zhì)是什么。
理解本質(zhì)從了解知識(shí)圖譜的演化過程入手。
▌知識(shí)圖譜的演化
知識(shí)圖譜這個(gè)概念是最近四、五年才為大家所知的,但是這個(gè)技術(shù)本身有非常深厚的發(fā)展基礎(chǔ),我把這個(gè)過程分成六個(gè)階段,合并一下之后大概分成兩個(gè)比較重要的階段。
往前溯可以追溯到五六十年代前,因?yàn)樵谌斯ぶ悄苓@個(gè)領(lǐng)域里,知識(shí)工程作為一個(gè)分支很早就有了。人工智能在大體上有三個(gè)比較大的分支,一個(gè)是神經(jīng)網(wǎng)絡(luò),叫連接主義學(xué)派,另外一個(gè)叫統(tǒng)計(jì)或者經(jīng)驗(yàn)主義學(xué)派,后來(lái)就衍生出了機(jī)器學(xué)習(xí),最后一個(gè)知識(shí)工程這個(gè)方向,我們叫它理性主義或者符號(hào)主義,是從 1956 年這個(gè)學(xué)科形成時(shí)就有的分支。
在六十年代、七十年代的時(shí)候,知識(shí)工程這個(gè)領(lǐng)域往前發(fā)展,不斷的產(chǎn)生出新的邏輯語(yǔ)言和新的實(shí)用方法,像描述邏輯是七十年代就興起了的。在六十年代時(shí)就有一個(gè)叫“Frame Network”(aka “Semantic Network”),語(yǔ)義網(wǎng)絡(luò)。注意,不是“語(yǔ)義網(wǎng)”而是“語(yǔ)義網(wǎng)絡(luò)”,那個(gè)時(shí)候的語(yǔ)義網(wǎng)絡(luò)跟現(xiàn)在的知識(shí)圖譜非常像。所以這個(gè)是不斷循環(huán)的,如果我們把六十年的學(xué)科發(fā)展抽象來(lái)看,實(shí)際上就是一個(gè)從簡(jiǎn)單到復(fù)雜、再?gòu)膹?fù)雜回歸簡(jiǎn)單的過程。
從最終得到的結(jié)果來(lái)看,好像我們現(xiàn)在得到的知識(shí)圖譜跟六十年代就已經(jīng)有的語(yǔ)義網(wǎng)絡(luò)非常像,但這種像只是表面上的。因?yàn)樵诎l(fā)展過程中,我們構(gòu)造了一個(gè)龐大的工業(yè)體系,以及如何從各種各樣的文檔、各種各樣的數(shù)據(jù)里集中編輯、生成知識(shí)圖譜的一整套工業(yè)鏈。所以一個(gè)技術(shù)不能只看它的定義,而是要看它相關(guān)所有實(shí)踐過程中工業(yè)體系的總和。今天知識(shí)圖譜的技術(shù)無(wú)論從深度還是廣度上,都遠(yuǎn)遠(yuǎn)超越六十年代的語(yǔ)義網(wǎng)絡(luò)技術(shù)。
八十年代、九十年代、到兩千年,這中間還有非常多中間技術(shù),我們從中選些重要的事情說一下。
▌?wù)Z義網(wǎng)絡(luò)
這張圖是對(duì)前面那張圖的抽象,我們選其中發(fā)展過程中最重要的節(jié)點(diǎn)。六十年代有一種東西叫“語(yǔ)義網(wǎng)絡(luò)”,語(yǔ)義網(wǎng)絡(luò)在七十年代、八十年代時(shí)演化成了描述邏輯。為什么會(huì)有這種變化?因?yàn)檎Z(yǔ)義網(wǎng)絡(luò)本身只是一種表征,并不具備推理能力。語(yǔ)義網(wǎng)絡(luò)+推理變成了新的邏輯系統(tǒng),叫“描述邏輯”,描述邏輯到兩千年前后跟 Web 技術(shù)結(jié)合在一起,形成了新的語(yǔ)言,比如 OIL 、DAML。
另外一個(gè)分支是 1995 年前后有了元數(shù)據(jù),從元數(shù)據(jù)學(xué)科衍生出一個(gè)分支叫 RDF,后來(lái) RDF 和 DAML 合并起來(lái)就變成了 OWL。下面還有一些更工程的內(nèi)容,包括 schema.org、RDFa、JOSN-LD、GraphpDB,這都是最近 5、6 年興起的新技術(shù)。這些技術(shù)的總和就構(gòu)成了我們所稱的“知識(shí)圖譜”技術(shù),但只是其中一部分。
給大家看一個(gè)語(yǔ)義網(wǎng)絡(luò),語(yǔ)義網(wǎng)絡(luò)其實(shí)就是一個(gè)網(wǎng)絡(luò)。這張圖上有各種不同的概念,比如中間的 Mammal 是哺乳動(dòng)物,貓(cat) 是一種哺乳動(dòng)物,貓有毛;熊是哺乳動(dòng)物,熊也有毛;鯨是一種哺乳動(dòng)物,鯨在水里面生活;魚也在水里面生活,也是一種動(dòng)物;哺乳動(dòng)物是一種脊椎動(dòng)物,也是動(dòng)物的一種。
所有這些節(jié)點(diǎn)和邊的總和就構(gòu)成了一個(gè)網(wǎng)絡(luò),每一條邊上都有一些標(biāo)志的,用術(shù)語(yǔ)來(lái)說就是“有類型的邊”,這種“有類型的邊”連在一起的節(jié)點(diǎn)叫“語(yǔ)義網(wǎng)絡(luò)”,概念是非常簡(jiǎn)單的。
六十年代時(shí)自然語(yǔ)言處理和知識(shí)表現(xiàn)的大拿批評(píng)這種語(yǔ)義網(wǎng)絡(luò),說這個(gè)東西沒辦法用于推理,用術(shù)語(yǔ)來(lái)說是最后沒有“semantics”。這里涉及很多關(guān)系,什么叫 semantics?有的學(xué)者認(rèn)為 semantics 必須是有一套嚴(yán)格的語(yǔ)義定義,這通常是用模型論來(lái)定義,或者過程方法來(lái)定義。其實(shí)也有更淺的對(duì)語(yǔ)義的理解,萬(wàn)事萬(wàn)物之間的關(guān)系就是語(yǔ)義。比如我們打開字典,字典是用一些詞定義另外一些詞,這就是語(yǔ)義。
我們?cè)谶@樣的語(yǔ)義網(wǎng)絡(luò)里,如何定義一個(gè)詞的意義?其實(shí)我們是做不到的。比如在這個(gè)語(yǔ)義網(wǎng)絡(luò)里,居于中間位置的詞是“哺乳動(dòng)物”,它到底是什么?我們很難讓計(jì)算機(jī)理解什么是真正的哺乳動(dòng)物,很難通過它的內(nèi)涵含義來(lái)理解。對(duì)于計(jì)算機(jī)而言,它只能知道萬(wàn)事萬(wàn)物之間的聯(lián)系,也許這對(duì)于機(jī)器自動(dòng)處理來(lái)說就夠了。所以語(yǔ)義網(wǎng)絡(luò)盡管沒有所謂的語(yǔ)義,我們還是把它稱為語(yǔ)義網(wǎng)絡(luò)的原因,因?yàn)檎Z(yǔ)義就是關(guān)系。
▌描述邏輯
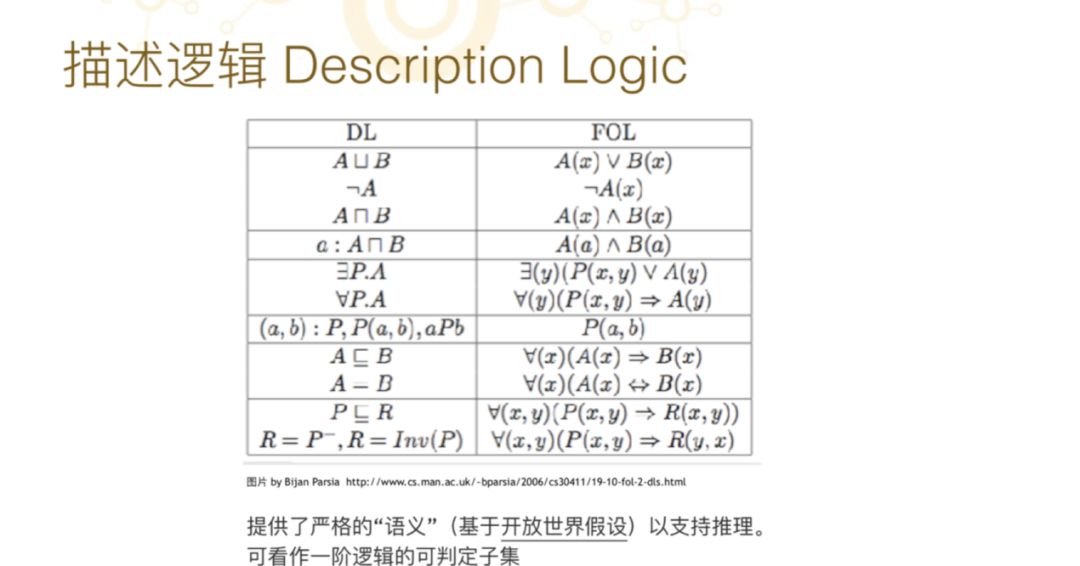
到了八十年代時(shí),描述邏輯就已經(jīng)比較成熟了。描述邏輯是邏輯的一種,我在這里面列了一張表,這是描述邏輯和一階邏輯 (FOL 邏輯)之間的對(duì)應(yīng)。如果大家沒有邏輯基礎(chǔ)也不用害怕,因?yàn)檫@個(gè)圖本質(zhì)上是講很基礎(chǔ)的邏輯定義。
我們有了一個(gè)描述邏輯之后,就可以用計(jì)算機(jī)來(lái)做一些自動(dòng)推理的工作。八十年代到九十年代,描述邏輯學(xué)者們一直都在尋找如何讓計(jì)算機(jī)更好的進(jìn)行邏輯推理,一些比較可判定的所謂計(jì)算機(jī)不會(huì)死機(jī)的那些問題的總和,這種語(yǔ)言稱為“描述邏輯”。
▌OWL
到九十年代時(shí)描述邏輯成為知識(shí)表現(xiàn)領(lǐng)域的一種非常顯學(xué)、非常重要的分支,正好這時(shí)互聯(lián)網(wǎng)興起了。到了 1995 年前后開始了真正知識(shí)圖譜化的第一步,開始把描述邏輯用互聯(lián)網(wǎng)的語(yǔ)言來(lái)重新來(lái)表征,有人用 HTML,也有人用 XML。1999 年馬里蘭大學(xué)開始發(fā)布了第一個(gè)這樣的語(yǔ)言,叫“SHOE”。后來(lái)這個(gè)語(yǔ)言被美國(guó)的國(guó)防部高等研究所資助了一個(gè)項(xiàng)目叫“DAML”,這就是第一個(gè)在美國(guó)這邊把知識(shí)表現(xiàn)語(yǔ)言放在網(wǎng)上一種官方的努力。
與此同時(shí),在歐洲也有一個(gè)非常相似的努力叫“OIL”,大西洋兩岸的同行們一看,大家做的事情非常相似,于是在 2001 年時(shí) W3C 開始把兩邊的努力匯總在一起,出現(xiàn)了一個(gè)語(yǔ)言叫“DAML+OIL”。到了 2004 年時(shí) W3C 進(jìn)一步協(xié)調(diào)大家的努力,合并了一個(gè)新的語(yǔ)言叫“OWL”,2009年發(fā)布了第二版,叫“OWL2”。
從九十年代到 2009 年這十幾年期間,這個(gè)領(lǐng)域不斷向上、向好積極發(fā)展,在那個(gè)時(shí)候我們?cè)?jīng)認(rèn)為 OWL 是描述這個(gè)世界非常好的一種工具,因?yàn)樗鼘?duì)于機(jī)器處理是非常友好的,所以我們就希望把它放到互聯(lián)網(wǎng)上去,讓更多人用到,但是這個(gè)設(shè)想后來(lái)并沒有實(shí)現(xiàn)。
▌W3C OWL 工作組的瓶頸
這里多說幾句 OWL,因?yàn)槲沂?OWL 工作組的一員,所以知道一些早期的事情。OWL有兩個(gè)工作組,最早的一個(gè)工作組是在 2000-2004 年之間,我趕上的是 2007-2010 年的第二個(gè)工作組,這個(gè)工作組的使命是把現(xiàn)有的 OWL 語(yǔ)言進(jìn)一步完善,提供所謂更強(qiáng)的表達(dá)力,或者在機(jī)器處理上比如要進(jìn)行語(yǔ)義數(shù)據(jù)的查詢,我們應(yīng)該用什么樣的,什么可以用、什么不能用、什么能說、什么不能說、什么對(duì)機(jī)器是友好的,OWL 工作組就是做這個(gè)事情。
我們寫了 10 來(lái)個(gè)文檔,加在一起 600 多頁(yè)紙,花了兩年時(shí)間做這個(gè)事情。OWL 工作組除了大學(xué)里來(lái)的人,還有一些企業(yè)的成員,包括 IBM、Oracle、惠普等等,還有一些小的創(chuàng)業(yè)公司。
那個(gè)時(shí)候我們這個(gè)領(lǐng)域遇到了一些瓶頸的,就是 OWL 這個(gè)語(yǔ)言或者語(yǔ)義網(wǎng)整個(gè)領(lǐng)域,在 2000 年前后是大家非常寄予厚望的,就好像現(xiàn)在大家對(duì)于深度學(xué)習(xí)寄予厚望一樣。但是往前走到 2006 年前后遇到了瓶頸,就是沒有人真的去產(chǎn)生這樣的數(shù)據(jù),大多數(shù)日常場(chǎng)景用不到語(yǔ)義。于是這時(shí)候就產(chǎn)生了內(nèi)部的路線斗爭(zhēng),叫“SEMANTIC Web or semantic WEB”,就是到底我們是加強(qiáng)語(yǔ)義呢?還是加強(qiáng)互聯(lián)網(wǎng)屬性呢?有兩組不同的人不斷進(jìn)行爭(zhēng)執(zhí)。
當(dāng)然,還有很多其他的分歧,包括我們到底該怎么去定義什么叫“簡(jiǎn)單”,大家沒有一致的意見。所以我們最終生成的文檔從學(xué)術(shù)角度來(lái)說是非常有價(jià)值,但是對(duì)于工業(yè)應(yīng)用特別是 C 端的互聯(lián)網(wǎng)應(yīng)用沒有達(dá)到預(yù)期。
小結(jié) :從弱語(yǔ)義到強(qiáng)語(yǔ)義的嘗試(邏輯)
前面這一段大體總結(jié)了知識(shí)圖譜技術(shù)發(fā)展的前兩個(gè)大的階段歷史,一個(gè)是從六十年代到九十年代,早期知識(shí)圖譜的原型,包括語(yǔ)義網(wǎng)絡(luò)等等,后面一系列的技術(shù)。
從 2001-2006 年或者 2007 年這段時(shí)間,是不斷加強(qiáng)語(yǔ)義網(wǎng)所謂的語(yǔ)義的過程,就是從弱語(yǔ)義到強(qiáng)語(yǔ)義,從語(yǔ)義網(wǎng)絡(luò)到描述邏輯,一直發(fā)展到 OWL,并行還有另外其他一些,比如基于框架邏輯還有另外一個(gè)語(yǔ)言叫“RIF”。這十幾年時(shí)間都一直不斷在加強(qiáng)語(yǔ)義表現(xiàn)的表達(dá)力,但最后證明這個(gè)做法是不太妥當(dāng)?shù)摹?/p>
▌元數(shù)據(jù)框架到 RDF
我們講過,除了學(xué)術(shù)性非常強(qiáng)的描述邏輯 OWL 分支之外,知識(shí)圖譜還有另外一個(gè)分支是來(lái)自于元數(shù)據(jù)框架的。這個(gè)工作最早是 Guha 在 Apple 做的,Guha 這個(gè)人是非常值得關(guān)注的,因?yàn)槟撤N程度上他是“知識(shí)圖譜之父”,在 1995 年時(shí)他在 Apple 發(fā)明了一個(gè)語(yǔ)言叫“MCF”,因?yàn)樗菚r(shí)候面臨一些問題,就是怎么去表征多媒體的數(shù)據(jù),特別是圖像的數(shù)據(jù),所以他就發(fā)明了一整套的元數(shù)據(jù)表征方法。
到了 1997 年時(shí) Guha 跟Tim Bray 做了 RDF/XML。1999 年網(wǎng)景公司發(fā)明了 RSS 語(yǔ)言,這個(gè)東西現(xiàn)在新一代的朋友們不一定知道了,回到 10 年前時(shí)看新聞都是用 RSS 訂閱的,其實(shí) RSS 的第一個(gè) R 就是 RDF。后來(lái)他們改了其他的名字,從本源上來(lái)講,技術(shù)剛剛開始的時(shí)候這個(gè)技術(shù)是 RDF 的應(yīng)用。1999 年 RDF 被 W3C 收編了,變成了國(guó)際標(biāo)準(zhǔn)。
▌RDF
什么是 RDF?這里給一個(gè)例子,它是非常簡(jiǎn)單的語(yǔ)言,本質(zhì)上是三元組,主語(yǔ)、謂語(yǔ)、賓語(yǔ)就是個(gè)三元組。比如“我叫鮑婕”,“我”是主語(yǔ),“是”是謂語(yǔ),“鮑捷”是賓語(yǔ)。在 RDF 這個(gè)框架下,萬(wàn)事萬(wàn)物各種復(fù)雜的關(guān)系最后都被拆分成三元組,如果從圖形來(lái)表示,三元組就是一個(gè)主語(yǔ)、一個(gè)謂語(yǔ),中間有一條線一個(gè)箭頭是賓語(yǔ),可以把各種各樣的模型都分解成這樣的三元組。
從 1997 年有了 RDF,1998 年有了 RDFS,2004 年邏輯學(xué)家給 RDF 加了一個(gè)語(yǔ)義,因?yàn)樗麄冋J(rèn)為 RDF 必須要能夠推理,所以 2014 年進(jìn)一步加強(qiáng),最后有了 RDF1.1,這是 RDF 大概 20 多年的發(fā)展史。
小結(jié):從弱語(yǔ)義到強(qiáng)語(yǔ)義的嘗試(元數(shù)據(jù))
RDF 和一開始提到描述邏輯方法是不一樣的,因?yàn)槊枋鲞壿嫹椒ㄊ菑膶?shí)驗(yàn)室里來(lái)的,它想構(gòu)造一個(gè)龐大的體系,構(gòu)建一個(gè)完美的知識(shí)表現(xiàn)語(yǔ)言,然后再尋找它的落地。
而 RDF 從一開始就是一個(gè)從實(shí)踐出發(fā)的、自底向上的一個(gè)語(yǔ)言。RDF 相對(duì)于 OWL 而言,是一個(gè)更加偏工程的、應(yīng)用更多的語(yǔ)言,現(xiàn)在有很多人在用 RDF。我們?nèi)粘I钪兴龅降慕^大多數(shù)網(wǎng)站,現(xiàn)在都有某種類型的元數(shù)據(jù),其中相當(dāng)一部分就是用 RDF 不同的變種來(lái)實(shí)現(xiàn)的,所以 RDF 總的來(lái)說是一個(gè)比較成功的技術(shù),因?yàn)樗莵?lái)自于現(xiàn)實(shí)的技術(shù)。
▌關(guān)聯(lián)數(shù)據(jù) Linked Data
從 2001 年這個(gè)領(lǐng)域正式形成,到 2006 年時(shí)語(yǔ)義網(wǎng)的技術(shù)堆棧已經(jīng)變得非常復(fù)雜了。1999 年時(shí)有一個(gè)所謂的“語(yǔ)義網(wǎng)蛋糕模型”,對(duì)語(yǔ)義網(wǎng)不同的技術(shù)做了羅列。2006 年時(shí)語(yǔ)義網(wǎng)技術(shù)已經(jīng)復(fù)雜到?jīng)]有人看得懂,沒有辦法用二維表達(dá),必須用一個(gè)三維的圖才能夠把語(yǔ)義網(wǎng)所有的技術(shù)放在里面。這就帶來(lái)了一個(gè)嚴(yán)重的問題,就是絕大多數(shù)的企業(yè)、開發(fā)者很難理解,無(wú)從下手。
到了 2006 年時(shí)我們的“神”Tim Berners-Lee 出來(lái)思考這個(gè)問題,他想與其要求大家現(xiàn)在把數(shù)據(jù)搞得很漂亮,不如讓大家把數(shù)據(jù)公開出來(lái)。只要數(shù)據(jù)能夠公開出來(lái),數(shù)據(jù)能夠連在一起,我們就會(huì)建立一個(gè)生態(tài),這套想法他稱為“關(guān)聯(lián)數(shù)據(jù)”。
他提出了數(shù)據(jù)發(fā)布的基本原則,上圖是我從他的博客上面提取出來(lái)的,我也非常推薦大家好好看他的博客“Design Issues”,Tim Berners-Lee 會(huì)提前 20 年時(shí)間去想人類的未來(lái)是什么樣的,我們的 Web 到底應(yīng)該遵循什么樣的原則。
在關(guān)聯(lián)數(shù)據(jù)的定義上,他定義了幾層什么是好的關(guān)聯(lián)數(shù)據(jù):第一是在網(wǎng)上,一顆星;二是機(jī)器能夠自動(dòng)讀,這就有兩顆星;三是盡可能用一個(gè)公有的格式,不要是某個(gè)公司私有的,這樣能夠促進(jìn)公開交換,做到這點(diǎn)就有三顆星;因?yàn)槭?W3C 提出來(lái)的,必須用 RDF,用 RDF 就有四顆星;如果 RDF 有 ID 把它連在一起就是五顆星。這就是 Tim Berners-Lee 提出的關(guān)聯(lián)數(shù)據(jù)的五星標(biāo)準(zhǔn)。
小結(jié):從強(qiáng)語(yǔ)義到弱語(yǔ)義的嘗試(關(guān)聯(lián)數(shù)據(jù))
2006 年之所以 Tim Berners-Lee 要推進(jìn)這個(gè)轉(zhuǎn)變,就是因?yàn)樗?dāng)時(shí)看到了有些風(fēng)險(xiǎn)。語(yǔ)義網(wǎng)的頭 5 年時(shí)間并不是特別成功,因?yàn)闆]有人愿意發(fā)布數(shù)據(jù),這時(shí)候 Tim Berners-Lee 出來(lái)帶領(lǐng)大家調(diào)整方向,不要再去強(qiáng)調(diào)很強(qiáng)的語(yǔ)義和推理了,可能一個(gè)比較弱的語(yǔ)義或者一個(gè)結(jié)構(gòu)化本身就已經(jīng)足夠了,這就是 Tim Berners-Lee 用“關(guān)聯(lián)數(shù)據(jù)”概念再次盤活了這個(gè)領(lǐng)域。
▌新的綜合:交換語(yǔ)言
這張圖上總結(jié)了知識(shí)交換語(yǔ)言一系列的發(fā)展,剛才提到 RDF,RDF+HTML,變成了 RDFa,還有另外一種叫 Microformat,這都是非常多網(wǎng)站上已經(jīng)用到的元數(shù)據(jù)語(yǔ)言。RDF+HTML5 就變成了 Microdata,RDF+JSON 就變成了 JSON-LD。所以傳統(tǒng)的 RDF semantics 就是基于 XML 的 semantics,現(xiàn)在不太多見了,因?yàn)槟莻€(gè)東西非常復(fù)雜,學(xué)習(xí)成本非常高。
現(xiàn)在我們看到的大部分 RDF 從概念上是 RDF 的變種,但是語(yǔ)法形式在網(wǎng)站上打開元代碼看都有元數(shù)據(jù)。大概 3 年前統(tǒng)計(jì),有 30% 的網(wǎng)頁(yè)已經(jīng)有語(yǔ)義數(shù)據(jù)了,現(xiàn)在應(yīng)該至少超過一半的網(wǎng)站都有語(yǔ)義數(shù)據(jù),所以 RDF 是很成功的一個(gè)東西。
▌新的綜合:存儲(chǔ)語(yǔ)言(圖數(shù)據(jù)庫(kù))
當(dāng)數(shù)據(jù)多了以后面臨另外一個(gè)問題,就是如何去存儲(chǔ)和操作知識(shí)圖譜的應(yīng)用數(shù)據(jù)。大公司和小公司各自有自己不同的解決方案,統(tǒng)稱為“圖數(shù)據(jù)庫(kù)”。為什么語(yǔ)義網(wǎng)的數(shù)據(jù)庫(kù)稱它為“圖數(shù)據(jù)庫(kù)”?前面幾張 PPT 講到 RDF 時(shí),其實(shí) RDF 就是各種事情之間的關(guān)聯(lián),我們把這種關(guān)聯(lián)畫出來(lái),變成很大的一個(gè)圖,很自然的就用圖數(shù)據(jù)庫(kù)進(jìn)行知識(shí)圖譜的存儲(chǔ)。所以谷歌、微軟各個(gè)大廠都有自己的圖數(shù)據(jù)庫(kù),至少是定制化的數(shù)據(jù)庫(kù)。
圖數(shù)據(jù)庫(kù)這件事情上后來(lái)產(chǎn)生了兩個(gè)新的流派,一個(gè)流派叫“RDF 數(shù)據(jù)庫(kù)”,另外一個(gè)叫“屬性圖數(shù)據(jù)庫(kù)”,雖然同樣是圖,但兩種數(shù)據(jù)庫(kù)關(guān)聯(lián)系統(tǒng)的定義是完全不一樣的。因?yàn)?RDF 這種圖本質(zhì)上強(qiáng)調(diào)推理邏輯;而屬性圖要放開很多,而且屬性圖發(fā)展過程中工程化做得非常好。
小結(jié):從強(qiáng)語(yǔ)義到弱語(yǔ)義的嘗試(圖數(shù)據(jù)庫(kù))
在圖數(shù)據(jù)庫(kù)的嘗試當(dāng)中,我們?cè)俅伟颜Z(yǔ)義給弱化了,從強(qiáng)語(yǔ)義到弱語(yǔ)義,因?yàn)槿绻覀冇脧?qiáng)語(yǔ)義就用 RDF 數(shù)據(jù)庫(kù),如果我們?cè)试S有弱語(yǔ)義就可以用圖數(shù)據(jù)庫(kù)。最后證明,圖數(shù)據(jù)庫(kù)的發(fā)展速度遠(yuǎn)遠(yuǎn)快于 RDF 數(shù)據(jù)庫(kù)。所以從實(shí)踐當(dāng)中總結(jié)出來(lái)的東西總是有生命力的,如果只是基于純理論的思考設(shè)計(jì)出來(lái)的東西通常是沒有生命力的。
Lean semantic Web
在整個(gè)領(lǐng)域發(fā)展過程中,我慢慢也有一些思考。后來(lái)我有一個(gè)博客叫“語(yǔ)義噪聲”,這里記錄了很多我對(duì)語(yǔ)義網(wǎng)大大小小事情的想法。那天統(tǒng)計(jì)了一下,加在一起大概有 300 多頁(yè)紙的內(nèi)容,如果有空了會(huì)整理出來(lái)給大家看。
這里我列舉了一些跟今天講課內(nèi)容關(guān)系比較緊密的東西,包括為什么語(yǔ)義網(wǎng)會(huì)不斷的去簡(jiǎn)化,為什么鏈接數(shù)據(jù)最后要演化成所謂的知識(shí)圖譜。我之前的博客里都寫過,歡迎大家去看一看。
還有 github 上,大連理工大學(xué)的耿新鵬博士把我博客文章整理到 github 上了,大家不用翻墻就可以看得到了。
▌總結(jié)
其實(shí)知識(shí)圖譜從 2012 年谷歌提出之后,它進(jìn)入了新的綜合的過程。知識(shí)圖譜在理論上并沒有特別大的進(jìn)步,因?yàn)檫@些工程包括邏輯推理幾十年來(lái)一直都是這樣。進(jìn)步的地方在哪里?通過實(shí)踐發(fā)現(xiàn),我們要想實(shí)現(xiàn)一個(gè)人工智能非常復(fù)雜的分支,其實(shí)是沒有辦法用那種學(xué)院派辦法來(lái)做的。我們只有理論結(jié)合實(shí)際,甚至從實(shí)踐中出發(fā)總結(jié)出產(chǎn)品來(lái)、總結(jié)出語(yǔ)言來(lái),這樣?xùn)|西的生命力遠(yuǎn)遠(yuǎn)大于一群專家坐在屋子里討論出來(lái)的。
知識(shí)圖譜的領(lǐng)域從 2006 年往前一直不斷從弱語(yǔ)義到強(qiáng)語(yǔ)義的發(fā)展過程中,這個(gè)階段最后被證明是不太成功的。2006 年之后這個(gè)領(lǐng)域不斷的強(qiáng)調(diào)工程、強(qiáng)調(diào)應(yīng)用、強(qiáng)調(diào)數(shù)據(jù)、強(qiáng)調(diào)跟實(shí)踐最相關(guān)的東西,語(yǔ)義也進(jìn)一步弱化,又從強(qiáng)語(yǔ)義再次回歸到弱語(yǔ)義。2012 年谷歌的知識(shí)圖譜是完全拋棄掉語(yǔ)義的。
從二十年來(lái)的歷史表明,從實(shí)踐中總結(jié)的方法要優(yōu)于從頂向下設(shè)計(jì)的方法。如果你有一個(gè)很好的想法或者一個(gè)很好的語(yǔ)言,并不能保證別人就能夠用起來(lái),除了要貼合用戶的需求之外,還有大量工具工作和生產(chǎn)工具的工作,這就形成了產(chǎn)業(yè)鏈。
所以在知識(shí)圖譜領(lǐng)域,我們不能狹隘看它的某一種語(yǔ)言或者某一種技術(shù),它是一個(gè)體系的,就是一大堆結(jié)構(gòu)化數(shù)據(jù)從生產(chǎn)到存儲(chǔ)到檢索的全流程工具豐富程度,才決定這個(gè)技術(shù)能不能落地。簡(jiǎn)單的優(yōu)于強(qiáng)大的,太過復(fù)雜的比如 OWL 最終用不起來(lái),反而比較簡(jiǎn)單的的像 RDF、最近比較火的 JSON-LD 用得越來(lái)越多。越簡(jiǎn)單越好,這就是 20 年來(lái)最核心學(xué)習(xí)到的東西。
▌?wù)雇?/p>
知識(shí)圖譜從 2015 年之后,就在實(shí)踐中應(yīng)用越來(lái)越廣泛。經(jīng)過這幾年培育,在不同的領(lǐng)域里,像醫(yī)療、法律、金融都已經(jīng)有比較好的公司建立起市場(chǎng)口碑了。相信知識(shí)圖譜還會(huì)向更多其他的垂直領(lǐng)域進(jìn)行滲透。
我們這幾年時(shí)間最主要的工作,不管在中國(guó),還是在美國(guó),都是促進(jìn)了知識(shí)圖譜工具的建設(shè)。這是我今天晚上第三次強(qiáng)調(diào)工具了,如果你離開一整套的工具鏈條的話,比如校驗(yàn)工具、編輯工具、檢索工具、推理工具,開發(fā)是非常難做的。
知識(shí)圖譜本質(zhì)上來(lái)說是一種程序,它是為了機(jī)器理解世界是什么時(shí)寫的一種程序。知識(shí)工程和軟件工程一樣,需要很多人在一起協(xié)作才能夠做好。我們經(jīng)過這幾十年軟件工程總結(jié)出一整套的打法來(lái),可以讓比較笨的人或者專業(yè)度不那么強(qiáng)的人,也可以去做開發(fā)工作。對(duì)于知識(shí)工程而言,目前沒有達(dá)到那個(gè)點(diǎn),這就是為什么知識(shí)工程那么貴的原因。但是我相信今后一段時(shí)間內(nèi)工具的建設(shè)會(huì)不斷改善,我們自己也在做一些工具,將來(lái)會(huì)提供給大家用。
▌相關(guān)資料
下面是是跟語(yǔ)義網(wǎng)有關(guān)的參考資料,我刻意沒有去列近期的東西,因?yàn)榻^大多數(shù)重要的東西在 2012 年前就有了,2012 年之后的東西沒有那么太必要搞明白,我們優(yōu)先把這個(gè)領(lǐng)域本源的東西看一下,相信對(duì)大家是有價(jià)值的。如果大家對(duì)英文還 OK,我建議大家讀讀 W3C 一系列標(biāo)準(zhǔn),包括 RDF 有一個(gè)入門指南寫得非常好,OWL 也有一個(gè)入門指南是我參與寫作的。
總的來(lái)說,到目前為止知識(shí)圖譜在中國(guó)沒有特別好的書來(lái)講,王昊奮、漆桂林、陳華鈞老師他們正在寫。其他的包括知識(shí)抽取、知識(shí)檢索工具的總結(jié)在W3C上也有,歡迎大家去看一看,可以解惑。
-
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14052 -
知識(shí)圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7949
原文標(biāo)題:文因互聯(lián)鮑捷:深度解析知識(shí)圖譜發(fā)展關(guān)鍵階段及技術(shù)脈絡(luò) | 公開課筆記
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
NLPIR系統(tǒng)KGB知識(shí)圖譜技術(shù)助力大數(shù)據(jù)深度挖掘
NLPIR大數(shù)據(jù)知識(shí)圖譜完美展現(xiàn)文本數(shù)據(jù)內(nèi)容
KGB知識(shí)圖譜基于傳統(tǒng)知識(shí)工程的突破分析
KGB知識(shí)圖譜技術(shù)能夠解決哪些行業(yè)痛點(diǎn)?
知識(shí)圖譜的三種特性評(píng)析
KGB知識(shí)圖譜幫助金融機(jī)構(gòu)進(jìn)行風(fēng)險(xiǎn)預(yù)判
KGB知識(shí)圖譜通過智能搜索提升金融行業(yè)分析能力
領(lǐng)域知識(shí)圖譜落地實(shí)踐中的問題與對(duì)策
一文帶你讀懂知識(shí)圖譜
通用知識(shí)圖譜構(gòu)建技術(shù)的應(yīng)用及發(fā)展趨勢(shì)

知識(shí)圖譜是NLP的未來(lái)嗎?

知識(shí)圖譜是什么,它在安全領(lǐng)域的應(yīng)用分析
知識(shí)圖譜Knowledge Graph構(gòu)建與應(yīng)用
知識(shí)圖譜:知識(shí)圖譜的典型應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論