") Apache Spark上的分布式機(jī)器學(xué)習(xí)的介紹
Apache Spark上的分布式機(jī)器學(xué)習(xí)的介紹

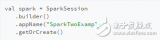
Spark是一個(gè)基于內(nèi)存計(jì)算的開(kāi)源的集群計(jì)算系統(tǒng),目的是讓數(shù)據(jù)分析更加快速。Spark非常小巧玲瓏,由加州伯克利大學(xué)AMP實(shí)驗(yàn)室的Matei為主的小團(tuán)隊(duì)所開(kāi)發(fā)。使用的語(yǔ)言是Scala,項(xiàng)目的core部分的代碼只有63個(gè)Scala文件,非常短小精悍。
聲明:本文內(nèi)容及配圖由入駐作者撰寫(xiě)或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
intel
+關(guān)注
關(guān)注
19文章
3495瀏覽量
188295 -
代碼
+關(guān)注
關(guān)注
30文章
4895瀏覽量
70525 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8500瀏覽量
134415
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
熱點(diǎn)推薦
RDMA技術(shù)在Apache Spark中的應(yīng)用
背景介紹 在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,Apache?Spark已經(jīng)成為了處理大規(guī)模數(shù)據(jù)集的首選框架。作為一個(gè)開(kāi)源的分布式計(jì)算系統(tǒng),Spark因其高

spark集群使用hanlp進(jìn)行分布式分詞操作說(shuō)明
本篇分享一個(gè)使用hanlp分詞的操作小案例,即在spark集群中使用hanlp完成分布式分詞的操作,文章整理自【qq_33872191】的博客,感謝分享!以下為全文: 分兩步:第一步:實(shí)現(xiàn)
發(fā)表于 01-21 10:45
【學(xué)習(xí)打卡】OpenHarmony的分布式任務(wù)調(diào)度
、同步、注冊(cè)、調(diào)用)機(jī)制。分布式任務(wù)調(diào)度程序是能夠跨多個(gè)服務(wù)器啟動(dòng)調(diào)度作業(yè)或工作負(fù)載的軟件解決方案,整個(gè)過(guò)程是不需要人來(lái)值守的。舉個(gè)例子,我們可以在一臺(tái)或多臺(tái)機(jī)器上安裝分布式調(diào)度器,用
發(fā)表于 07-18 17:06
Spark機(jī)器學(xué)習(xí)庫(kù)的各種機(jī)器學(xué)習(xí)算法
本文將簡(jiǎn)要介紹Spark機(jī)器學(xué)習(xí)庫(kù)(Spark MLlibs APIs)的各種機(jī)器
發(fā)表于 09-28 16:44
?1次下載
如何使用Apache Spark 2.0
,Spark 2.0現(xiàn)在比以往更易使用。在這部分,我將介紹如何使用Apache Spark 2.0。并將重點(diǎn)關(guān)注DataFrames作為新Dataset API的無(wú)類(lèi)型版本。 到
發(fā)表于 09-28 19:00
?0次下載
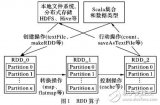
Spark分布式下的模糊C均值算法
針對(duì)聚類(lèi)算法需要處理數(shù)據(jù)集的規(guī)模越來(lái)越大、時(shí)效性要求越來(lái)越高,對(duì)算法的大數(shù)據(jù)適應(yīng)能力和性能要求更高的問(wèn)題,提出一種在Spark分布式內(nèi)存計(jì)算平臺(tái)下的模糊C均值(FCM)算法Spark-FCM。首先
發(fā)表于 12-23 09:59
?0次下載
機(jī)器學(xué)習(xí)實(shí)例:Spark與Python結(jié)合設(shè)計(jì)
Apache Spark是處理和使用大數(shù)據(jù)最廣泛的框架之一,Python是數(shù)據(jù)分析、機(jī)器學(xué)習(xí)等領(lǐng)域最廣泛使用的編程語(yǔ)言之一。如果想要獲得更棒的機(jī)器
發(fā)表于 07-01 10:15
?2903次閱讀
spark和hadoop的區(qū)別
Apache Spark 是專(zhuān)為大規(guī)模數(shù)據(jù)處理而設(shè)計(jì)的快速通用的計(jì)算引擎。Hadoop是一個(gè)由Apache基金會(huì)所開(kāi)發(fā)的分布式系統(tǒng)基礎(chǔ)架構(gòu)。用戶可以在不了解
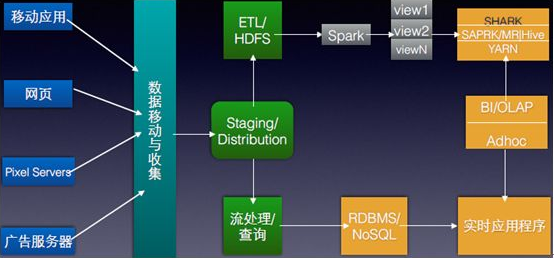
Apache Spark的分布式深度學(xué)習(xí)框架BigDL的概述
該視頻概述了Apache Spark *的BigDL分布式深度學(xué)習(xí)框架。
Apache Ignite上的TensorFlow!分布式內(nèi)存數(shù)據(jù)源
另一個(gè)基準(zhǔn)測(cè)試表明 Ignite Dataset 如何與分布式 Apache Ignite 集群協(xié)作。這是 Apache Ignite 作為 HTAP 系統(tǒng)的默認(rèn)用例,它使您能夠在每秒 10 Gb 的網(wǎng)絡(luò)集群

Apache Spark 3.2有哪些新特性
單節(jié)點(diǎn)機(jī)器或集群上執(zhí)行數(shù)據(jù)工程、數(shù)據(jù)科學(xué)和機(jī)器學(xué)習(xí)的最廣泛使用的引擎。 Spark 3.2 繼續(xù)以使 S
一文詳細(xì)了解APACHE SPARK開(kāi)源框架
Apache Spark 是一個(gè)開(kāi)源框架,適用于跨集群計(jì)算機(jī)并行處理大數(shù)據(jù)任務(wù)。它是在全球廣泛應(yīng)用的分布式處理框架之一。
利用Apache Spark和RAPIDS Apache加速Spark實(shí)踐
在第三期文章中,我們?cè)敿?xì)介紹了如何充分利用 Apache Spark 和 Apache RAPIDS 加速器 Spark 。 大多數(shù)團(tuán)隊(duì)
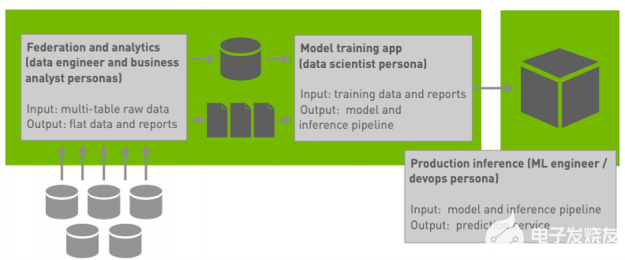
Spark 3.4用于分布式模型訓(xùn)練和大規(guī)模模型推理
使用 Spark 3.4 簡(jiǎn)化分布式深度學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論