 RDMA技術在Apache Spark中的應用
RDMA技術在Apache Spark中的應用

背景介紹
在當今數據驅動的時代,ApacheSpark已經成為了處理大規模數據集的首選框架。作為一個開源的分布式計算系統,Spark因其高效的大數據處理能力而在各行各業中廣受歡迎。無論是金融服務、電信、零售、醫療保健還是物聯網,Spark的應用幾乎遍及所有需要處理海量數據和復雜計算的領域。它的快速、易用和通用性,使得數據科學家和工程師能夠輕松實現數據挖掘、數據分析、實時處理等任務。
然而,在Spark的燦爛光環背后,一個核心的技術挑戰一直困擾著用戶和開發者--Shuffle過程中的網絡瓶頸。
在大規模數據處理時,Shuffle是Spark中不可或缺的一環,它涉及大量數據在不同節點間的交換,是整個數據處理過程中最耗時的部分之一。隨著數據量的不斷增長,網絡傳輸成為了顯著的性能瓶頸,這不僅影響了處理速度,還影響了整體的資源利用效率和系統的可擴展性。
ApacheSparkShuffle
在Spark中,Shuffle是數據處理過程的一個關鍵階段,發生在數據需要redistribute的情況。

圖一:shuffle中的數據流向
每個左上角的彩色條帶代表Spark在Shuffle前計算得到的一個數據塊。假設這些數據塊分別存放在集群的不同的節點上。此刻,假設我們希望“根據顏色將這些數據塊進行分組”,那么Shuffle過程就會啟動:
首先,每臺機器上的數據塊會按顏色進行本地第一次聚合(從左上角的彩色條帶變為中上部的彩色條帶)。這些經過聚合的數據就成了Shuffle的中間數據。接下來,Spark會將中間數據以文件的形式暫存到各自節點的硬盤上(從中上部的條帶變為"File")。這一部分稱為Shuffle的Map階段。
在這之后,所有相同顏色的數據塊會通過網絡第二次聚合到一個指定的節點上(從中上部的彩色條帶移動至中下部)。這一階段稱為Shuffle的Reduce階段。
至此,Spark完成了“根據顏色將數據塊進行分組”這個要求,Shuffle過程結束。
在實際的操作中,Shuffle是一個非常耗時的過程,因為它涉及到大量的數據在網絡中的傳輸。如果Shuffle管理得不好,它會成為Spark作業性能瓶頸的主要原因。
解決SparkShuffle網絡傳輸性能瓶頸的關鍵
為了克服這一挑戰,近年來,遠程直接內存訪問(RDMA)技術逐漸進入了專家們的視野。RDMA允許內存數據直接從一個系統傳輸到另一個系統,而無需通過操作系統的干預,這顯著減少了數據傳輸過程中的延遲和CPU的使用率。在高性能計算和大規模數據中心環境中,RDMA已經顯示出了其強大的網絡加速能力。
將RDMA技術應用于ApacheSpark,尤其是在Shuffle過程中,可以大幅度減輕網絡瓶頸帶來的影響。通過利用RDMA的高帶寬和低延遲特性,Spark的數據處理性能有望得到顯著的提升。
RDMA相比傳統網絡技術的優勢
KernelBypass:
傳統的網絡通信需要操作系統內核參與數據的發送和接收,這會增加額外的延遲。每個數據包在傳輸過程中都需要經過操作系統的網絡協議棧,這個過程中涉及多次上下文切換和數據拷貝。如下圖所示。
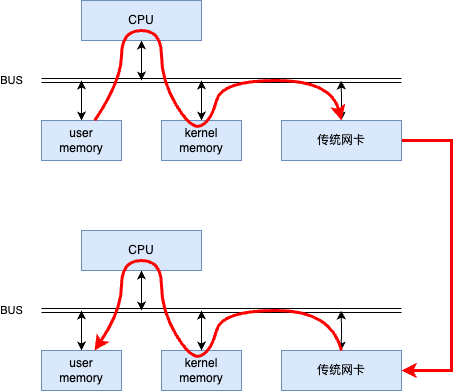
圖二:傳統網絡通信中數據的發送和接收
RDMA技術允許網絡設備直接訪問應用程序內存空間,實現了內核旁路(kernelbypass)。這意味著數據可以直接從發送方的內存傳輸到接收方的內存,無需CPU介入,減少了傳輸過程中的延遲。如下圖所示。
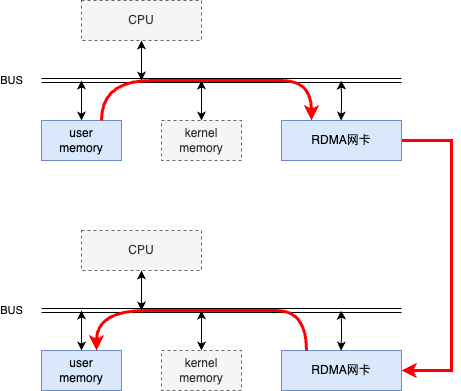
圖三:RDMA網絡通信中數據的發送和接收
對于Spark的Shuffle過程,這意味著數據塊可以更快地在節點間傳輸,因為它們不再需要在用戶空間和內核空間之間進行多次拷貝。
CPUOffloading:
在傳統的網絡通信中,CPU需要處理包括TCP協議棧在內的大量網絡協議處理任務,這不僅消耗了大量的計算資源,而且還增加了通信的延遲。
RDMA通過其協議和硬件的設計,允許網絡設備處理大部分數據傳輸的細節,從而釋放CPU資源。這意味著CPU可以專注于執行計算任務,而不是網絡數據的傳輸,從而提高了整體的計算效率。
在Spark中,這樣可以確保CPU更多地用于執行Map和Reduce階段之外的實際計算工作,而不是在網絡通信上。
RDMA技術在ApacheSpark中的應用
在Spark中集成RDMA
Spark允許將外部實現的ShuffleManager插入到其架構中。下圖中通過實現Spark的接口,可以創建專有的ShuffleManager從而將RDMA技術引入到Shuffle過程中。
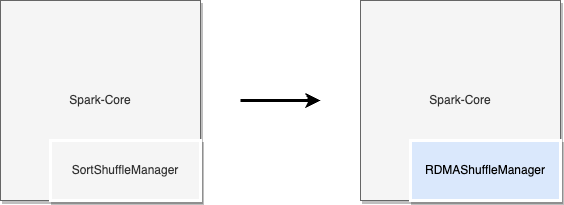
圖四:通過Spark接口將RDMA集成到ApacheSpark
RDMA加速的實現
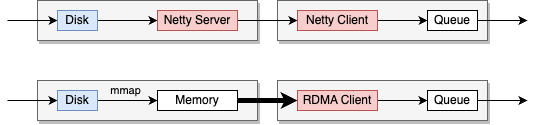
圖五:RDMA在SparkShuffle過程中的位置
上圖中展示了RDMA引入ApacheSpark前后的Shuffle過程中的數據傳輸方式。
在上半部分,展示了ApacheSpark使用Netty作為網絡傳輸層的傳統方法。數據從磁盤讀取,通過Netty服務器傳輸,然后由Netty客戶端接收,并放入隊列中供進一步處理。
在下半部分,展示了使用RDMA作為網絡傳輸層的方法。在這種方式中,Netty客戶端被RDMA客戶端替換,而由于RDMA單邊操作的特性,不再需要服務器端,Disk上的數據通過MMAP加載進入用戶空間的內存,之后Client使用RDMA直接在網絡上進行內存訪問操作,避免了數據在操作系統內存和網絡接口之間的多次復制,從而提高了數據傳輸速度,并減少了延遲和CPU負載。
性能數據和比較分析
為了驗證我們的實現,我們在多種數據集和查詢負載下進行了性能測試。測試結果如下圖所示
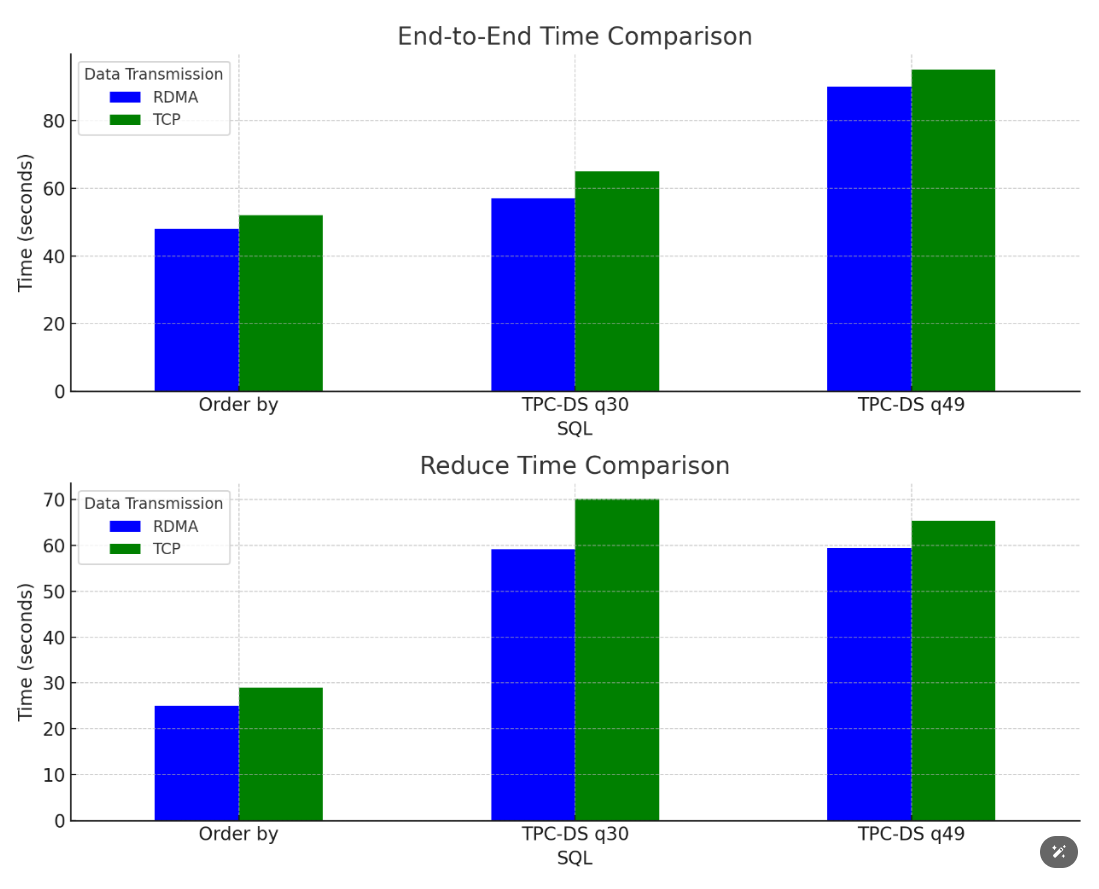
圖六:SQL的性能提升效果
這些測試結果表明,在多種場景下使用RDMA均能實現大約10%左右的性能提升。然而,值得注意的是,具體的加速效果會受到業務邏輯和數據處理工作負載的影響,因此我們推薦在實施RDMA解決方案前,對特定的應用場景進行詳細評估。
應用場景建議
通過RDMA和Spark的特性分析,結合測試,可得到針對RDMA技術在Spark中適用和不適用的場景的優化建議:
適合RDMA的場景
大數據量的復雜SQL操作:在處理包含復雜操作(如Orderby)的大數據量SQL查詢時,RDMA技術可顯著提升效率。
大量小數據分區:當分區數量較多,且每個分區處理的數據量較小,傳送的數據包較多時,RDMA的加速效果尤為顯著。
不適合RDMA的場景
數據量大幅減少的操作:如SQL中的Groupby聚合操作等,這些減少數據量的計算可能不會從RDMA中獲得顯著加速。
基于HDD的磁盤集群:在使用HDD磁盤的集群中,由于讀寫速度較慢,磁盤I/O所占的時間較長,這可能限制RDMA技術的加速潛力。
數據高度本地化:如果數據本地化良好,則意味著網絡傳輸占比較少,這種計算難以通過RDMA獲得加速。
總結
盡管面臨一些挑戰,RDMA技術在ApacheSpark中的應用仍然有著顯著的優勢,體現在以下幾個方面:
提高數據傳輸效率:RDMA通過提供低延遲和高帶寬的數據傳輸,顯著加快了Spark中的數據處理速度。這是因為RDMA直接在網絡設備和應用程序內存之間傳輸數據,減少了CPU的干預,從而降低了數據傳輸過程中的延遲。
減少CPU占用:RDMA的KernelBypass特性允許數據繞過內核直接從內存傳輸,減少了CPU在數據傳輸過程中的工作量。這不僅提高了CPU的有效利用率,還留出了更多資源用于Spark的計算任務。
改善端到端處理時間:在對比測試中,使用RDMA相比傳統的TCP傳輸方式,在端到端的數據處理時間上有顯著的降低。這意味著整體的數據處理流程更加高效,能夠在更短的時間內完成相同的計算任務。
優化Shuffle階段的性能:在Spark中,Shuffle階段是一個關鍵的、對性能影響較大的階段。RDMA通過減少數據傳輸和處理時間,有效地優化了Shuffle階段的性能,從而提升了整個數據處理流程的效率。
增強大規模數據處理能力:對于處理大規模數據集的場景,RDMA提供的高效數據傳輸和低延遲特性尤為重要。它使得Spark能夠更加高效地處理大數據量,提高了大規模數據處理的可擴展性和效率。
總而言之,RDMA技術在ApacheSpark中的應用顯著提升了數據處理的效率和性能。在未來,相信隨著數據量的持續增長和計算需求的日益復雜化,RDMA技術在ApacheSpark以及更廣泛的大數據處理和高性能計算領域的應用將越來越廣。
審核編輯 黃宇
-
數據集
+關注
關注
4文章
1224瀏覽量
25444 -
RDMA
+關注
關注
0文章
85瀏覽量
9289 -
SPARK
+關注
關注
1文章
106瀏覽量
20585
發布評論請先 登錄
RDMA簡介2之A技術優勢分析
Spark入門及安裝與配置
如何使用Apache Spark 2.0
Apache Spark 1.6預覽版新特性展示
Apache Spark 3.2有哪些新特性
一文詳細了解APACHE SPARK開源框架
利用Apache Spark和RAPIDS Apache加速Spark實踐
Apache Spark 靠什么幫助獲得市場頭把交椅?
NVIDIA ConnectX智能網卡驅動RDMA通訊技術在分布式存儲的應用
NVIDIA加速的Apache Spark助力企業節省大量成本






 工商網監
工商網監
評論