 Facebook 2018 AI研究全回顧
Facebook 2018 AI研究全回顧

在過去的一年,Facebook經歷了很多波折和困難,但是在研究方面依舊涌現出了很多高質量的工作。近日,Facebook發文總結了去年在長期研究項目、高性能工具開發和平臺開發以及AI的實際應用等各個方面的工作。
隨著研究和工程實踐的深入,實現了更強大的智能系統、更優秀的開源工具、更穩定高效的開源平臺,諸多的研究論文和模型代碼為深度學習研究做出了眾多貢獻。同時,還將AI應用到了醫學和社會生活等領域,讓技術真正造福人類。那么,就讓我們一起看下這些工作都有哪些吧!
基于半監督和無監督學習的先進AI技術
實現人類水平的人工智能是每個從業者和研究人員最終的目標。在過去的一年,Facebook的研究人員利用更少的數據實現了更復雜的功能,讓人工智能的目標又近了一步。目前大多數機器學習都基于大量標記數據通過監督學習的方式來實現特定的任務,但耗時的數據標記工作極大地限制了技術的發展。所以如何充分釋放半監督和無監督學習的潛力,減少智能系統對于數據量的需求至關重要。在多語言理解和翻譯系統中,研究人員提出一種新的方法,基于無監督數據實現自然機器翻譯模型自動訓練遷移,并達到了與監督數據相比擬的效果。通過減少對于大規模標記數據的依賴,這一系統打開了向更多語言遷移的技術大門,甚至可以用于像烏爾都語一樣標記數據十分有限的語言。
多種語言的二維詞向量嵌入空間可以通過簡單的變換實現匹配。
此外,對于數據集資源有限的語言來說,需要用多種技術手段來實現。使用多語言模型融合同一語系多種方言間的相似性。通過多種技術的綜合,研究人員在自動翻譯系統中成功的新增了24種語言。同時在與紐約大學的合作中,在MutilNLI數據集中新增了14中語言,將有效助力自然語言理解的研究進程。同時,還發布了跨語言推理數據集XNLI,其中包括了烏爾都語和斯瓦希里語兩種小語種。利用半監督和非監督的方式有效減少了對于監督訓練數據的需求。研究人員還探索了數據監督的方式,結合監督和非監督數據,通過數據蒸餾的方法實現半監督學習。另外值得一提的是,研究人員探索了基于圖像標簽的圖像識別系統,創造性的利用現存的、非傳統標注的數據生成了大規模的自標記訓練數據集,其中包括了35億張來自Instagram的圖像。用戶為照片標記的標簽可以為圖像提供更為豐富的信息,將現存的圖像轉變為弱監督數據樣本。結果表明,這些手段不僅有效地提升了基于圖像的任務表現,更將圖像識別模型的準確率推高了1%。
圖像標簽可幫助計算機學習到比通常分類更為細的子分類信息,并補充圖中元素的信息。
加速AI研究產品化進程
AI作為一種基礎能力已經在產品的方方面面得到體現。2018年Facebook最主要的工作也集中在如何將AI方面的研究成果盡可能的產品化并部署到系統中,主要體現在PyTroch平臺和一系列工具的開發上。PyTroch自2018年發布以來已經躍居為GitHub上增長第二的開源項目。其靈活的接口對于研究AI研究的快速迭代十分友好,同時開源的框架設計有助平臺包容并蓄快速迭代和發展。隨著代碼體系的不斷完善,今年發布的PyTorch1.0實現了產品級別的框架,涵蓋了從原型研究到服務部署的全套流程。
包括Google、微軟和英偉達在內的大廠以及Fast.ai、Udacity等教育機構都在使用PyTorch來實現研究、產品開發和教育過程。近日,發布完整版的PyTorch1.0涵蓋了混合前端的新特性,可以在圖模式和eager模式下無縫切換,同時改進了分布式訓練流程,為高性能研究用戶提供了純cpp的編程接口。
研究人員也基于PyTorch開發了包括 QNNPACK 、FBGEMM等工具庫,使得移動端和服務器更容易地運行最新的AI模型。
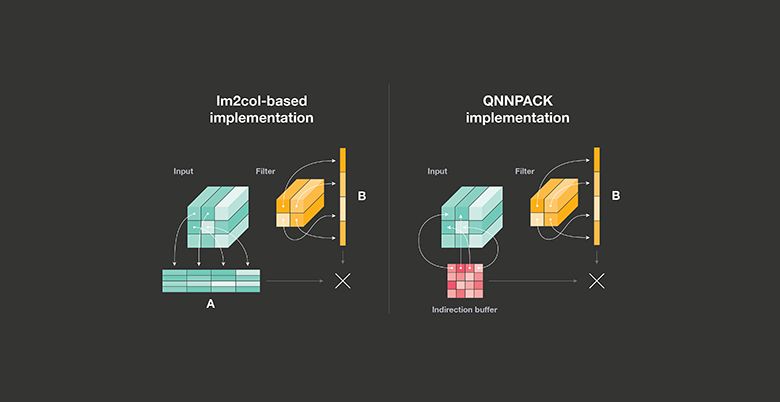
同時開發了PyText,加速了自然語言處理的研究發展。
在強化學習方面,Facebook開發了Horizon框架,利用強化學習在大規模生成系統中進行優化。它吸收了研究領域大量使用的基于決策的方式,并應用于十億級別的數據集上。在部署了這套框架后,使得優化視頻流和信息流更為高效。這套工具的開源搭建了強化學習研究和產品化之間的橋梁。
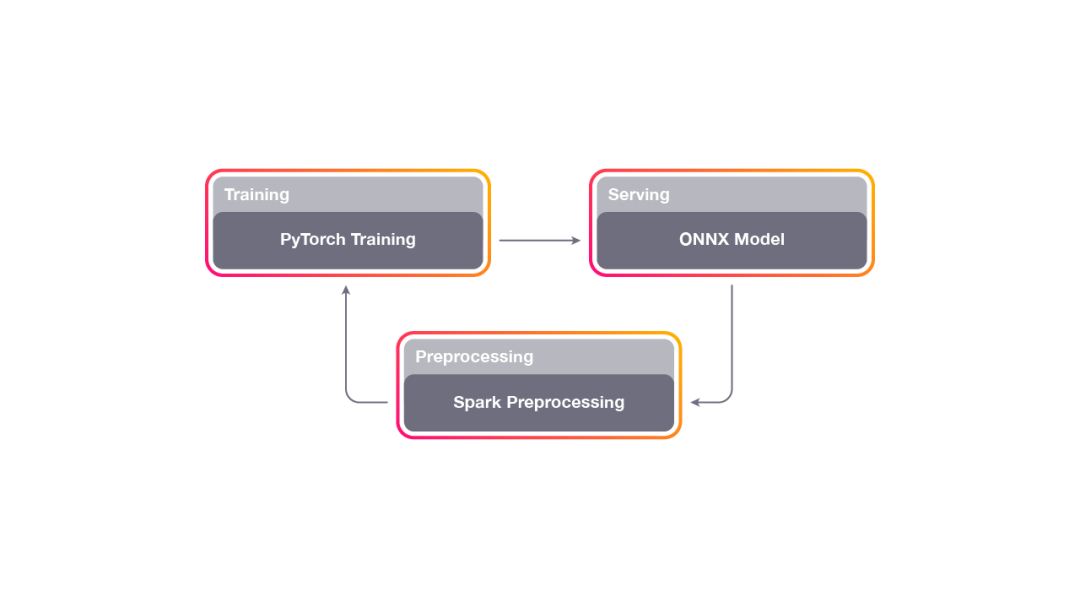
Horizon的流程圖解。首先對系統中的數據進行預處理,隨后離線訓練模型測量、最后對策略進行部署和測試,并循環改進整個流程。
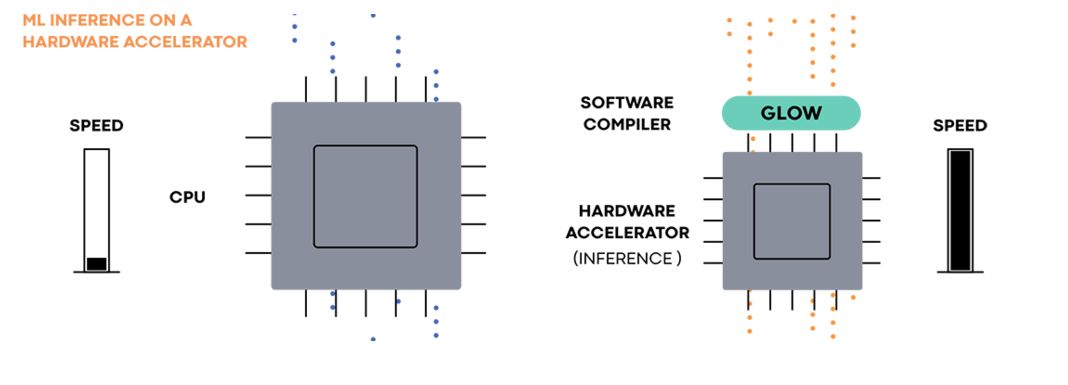
為了加速機器學習的運算過程,另一個稱為Glow的開源項目銜接了不同的編譯器、硬件平臺和深度學習框架,通過與廠家合作開發,在Intel,Cadence, Esperanto, Marvell,Qualcomm 等平臺上實現了高效的加速。
作為Open Computer Project的一部分,Facebook還推出了面向工業界機器學習用戶的Big Basin v2。
在VR/AR方面,研究人員結合深度學習進行了更深入的研究,在DeepFocus項目中發布了數據和模型。利用深度學習算法渲染出VR中的真實場景,包括了變焦多焦距和光場效果的智能渲染等。
用AI造福人類
將技術廣泛應用于改善人類生活的方方面面是每個技術從業者的追求。Facebook在過去一年——利用音頻視覺描述技術幫助視覺障礙的人,同時基于跨語言的自然語言處理和文本分析預測用戶的自殺傾向,及時拯救更多的人。
同時,研究人員還利用AI迅速精確地計量自然災害地區的受損狀況。為災難救援、受損評估和災后重建提供了高效準確定量的手段。
此外通過機器學習技術,研究人員還開發出了Rosetta系統,用于檢測圖像和視頻中的文本信息,并能在多種語言間進行語義的合規性檢查,大大減少了人工成本以及不良言論的出現和傳播。
Rosetta文本檢測的兩步架構
最后在醫學影像方面,fastMRI項目加速了核磁共振影像的檢測速度,加速了深度學習技術向醫學領域的遷移和發展。項目不僅發布了充足的數據集,同時也開源了基本模型供來自世界各地的研究人員學習改進。
核磁共振的原始數據和重建后膝蓋圖像
過去的一年里,研究人員還改進了Getafix, predictive test selection, SapFix, Sapienz, and Spiral等等一系列系統,提高了SLAM和AI in Marketplace等技術在產品中的應用,并發表了一系列研究成果,包括了著名的wav2letter++, 結合多詞的表示, 以及multilingual embeddings, 和audio processing等工作。
在新的一年里,更加扎實的工作和研究將在基礎設施研究、高精尖應用和AI造福社會等方面展開。希望2019,Facebook能帶來更多優秀的研究成果和高效的開源工具,推動AI技術更好發展。
-
圖像識別
+關注
關注
9文章
526瀏覽量
39096 -
人工智能
+關注
關注
1806文章
48996瀏覽量
249191 -
ai技術
+關注
關注
1文章
1308瀏覽量
25145
原文標題:別人家的盤點 | Facebook 2018 AI研究全回顧
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA全棧加速代理式AI應用落地
熱浪席卷,全志「慧眼」AI眼鏡首秀10分鐘搶光體驗樣機~

首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
直播回顧 技術解答 | 思瑞浦AI服務器應用方案

全志AIOT系列芯片助力AI玩具百花齊放
中軟國際攜手華為推出政務AI全棧解決方案
MWC 2025 | 廣和通發布全矩陣AI解決方案“星云”系列,創新變革端側AI






 工商網監
工商網監
評論