") 萬用NLP模型Transformer的升級(jí)版
萬用NLP模型Transformer的升級(jí)版

谷歌官方博客今天發(fā)文,詳細(xì)解釋了萬用NLP模型Transformer的升級(jí)版——Transformer-XL,該模型利用兩大技術(shù),在5個(gè)數(shù)據(jù)集中都獲得了強(qiáng)大的結(jié)果。
要正確理解一篇文章,有時(shí)需要參考出現(xiàn)在幾千個(gè)單詞后面的一個(gè)單詞或一個(gè)句子。
這是一個(gè)長期依賴性(long-range dependence)的例子,這是序列數(shù)據(jù)中常見的現(xiàn)象,處理許多現(xiàn)實(shí)世界的任務(wù)都必須理解這種依賴。
雖然人類很自然地就會(huì)這樣做,但是用神經(jīng)網(wǎng)絡(luò)建模長期依賴關(guān)系仍然很具挑戰(zhàn)性。基于Gating的RNN和梯度裁剪(gradient clipping)技術(shù)提高了對(duì)長期依賴關(guān)性建模的能力,但仍不足以完全解決這個(gè)問題。
應(yīng)對(duì)這個(gè)挑戰(zhàn)的一種方法是使用Transformers,它允許數(shù)據(jù)單元之間直接連接,能夠更好地捕獲長期依賴關(guān)系。
Transformer 是谷歌在 17 年做機(jī)器翻譯任務(wù)的 “Attention is all you need” 論文中提出的,引起了相當(dāng)大的反響,業(yè)內(nèi)有“每一位從事 NLP 研發(fā)的同仁都應(yīng)該透徹搞明白 Transformer”的說法。
參考閱讀:
Transformer一統(tǒng)江湖:自然語言處理三大特征抽取器比較
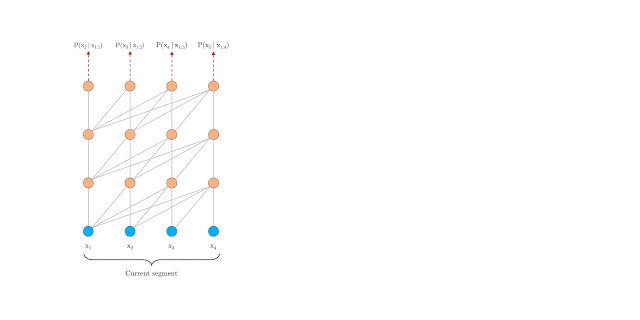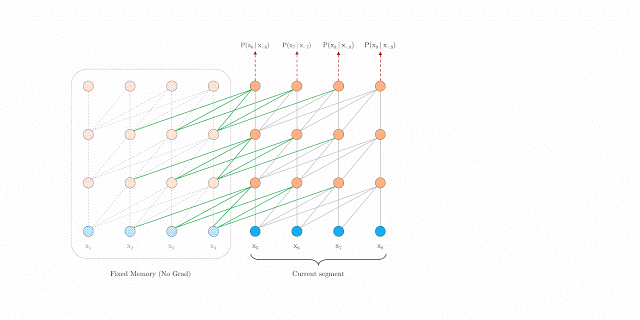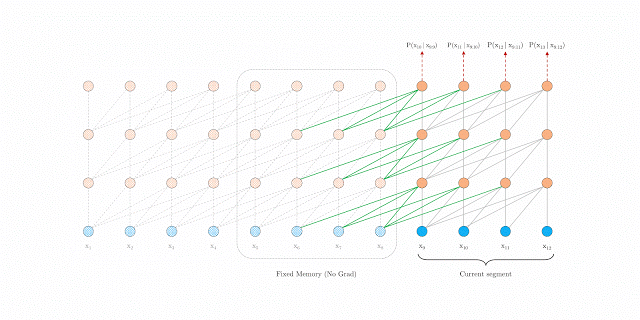
然而,在語言建模中,Transformers目前使用固定長度的上下文來實(shí)現(xiàn),即將一個(gè)長的文本序列截?cái)酁閹装賯€(gè)字符的固定長度片段,然后分別處理每個(gè)片段。

vanillaTransformer模型在訓(xùn)練時(shí)具有固定長度上下文
這造成了兩個(gè)關(guān)鍵的限制:
算法無法建模超過固定長度的依賴關(guān)系。
被分割的片段通常不考慮句子邊界,導(dǎo)致上下文碎片化,從而導(dǎo)致優(yōu)化低效。即使是對(duì)于長期依賴性不顯著的較短序列,這也是特別麻煩的。
為了解決這些限制,谷歌提出一個(gè)新的架構(gòu):Transformer-XL,它使自然語言的理解超出了固定長度的上下文。
Transformer-XL由兩種技術(shù)組成:片段級(jí)遞歸機(jī)制(segment-level recurrence mechanism)和相對(duì)位置編碼方案(relative positional encoding scheme)。
論文:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(https://arxiv.org/abs/1901.02860)
論文詳細(xì)解讀:谷歌、CMU重磅論文:Transformer升級(jí)版,評(píng)估速度提升超1800倍!
Segment-level的遞歸機(jī)制
在訓(xùn)練期間,為前一個(gè)segment計(jì)算的representation被修復(fù)并緩存,以便在模型處理下一個(gè)新的segment時(shí)作為擴(kuò)展上下文重新利用。
這個(gè)額外的連接將最大可能依賴關(guān)系長度增加了N倍,其中N表示網(wǎng)絡(luò)的深度,因?yàn)樯舷挛男畔F(xiàn)在可以跨片段邊界流動(dòng)。
此外,這種遞歸機(jī)制還解決了上下文碎片問題,為新段前面的token提供了必要的上下文。
在訓(xùn)練期間具有segment-level recurrence的Transformer-XL
相對(duì)位置編碼
然而,天真地應(yīng)用 segment-level recurrence是行不通的,因?yàn)楫?dāng)我們重用前面的段時(shí),位置編碼是不一致的。
例如,考慮一個(gè)具有上下文位置[0,1,2,3]的舊段。當(dāng)處理一個(gè)新的段時(shí),我們將兩個(gè)段合并,得到位置[0,1,2,3,0,1,2,3],其中每個(gè)位置id的語義在整個(gè)序列中是不連貫的。
為此,我們提出了一種新的相對(duì)位置編碼方案,使遞歸機(jī)制成為可能。
此外,與其他相對(duì)位置編碼方案不同,我們的公式使用具有l(wèi)earnable transformations的固定嵌入,而不是earnable embeddings,因此在測(cè)試時(shí)更適用于較長的序列。
當(dāng)這兩種方法結(jié)合使用時(shí),在評(píng)估時(shí), Transformer-XL比vanilla Transformer模型具有更長的有效上下文。
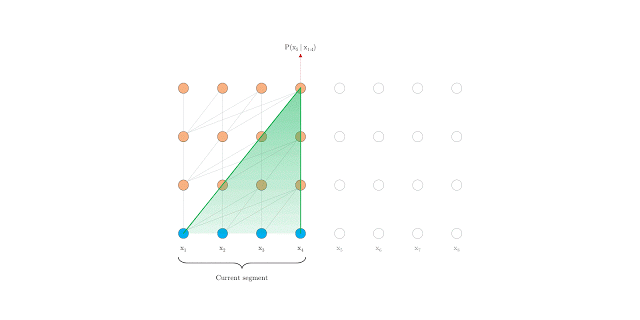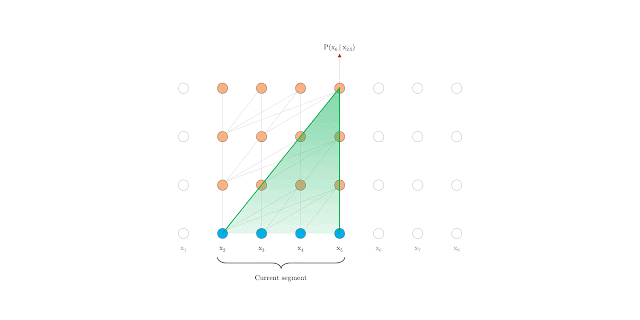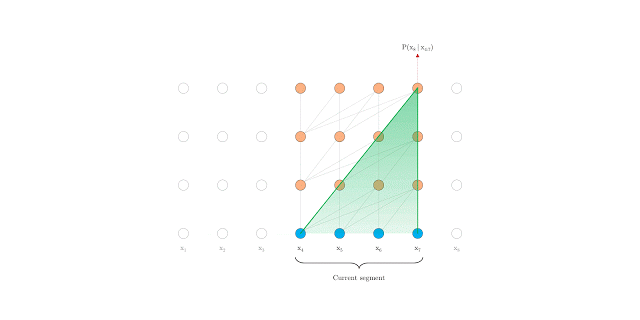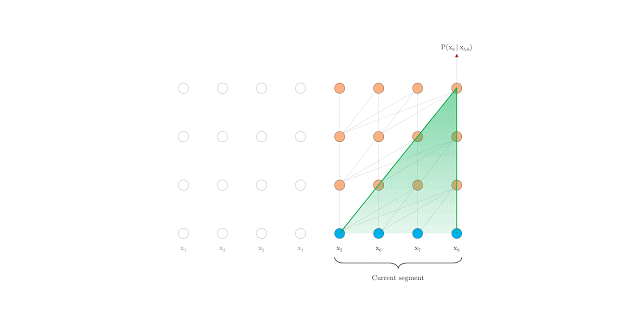
在計(jì)算時(shí)具有固定長度上下文的vanilla Transformer
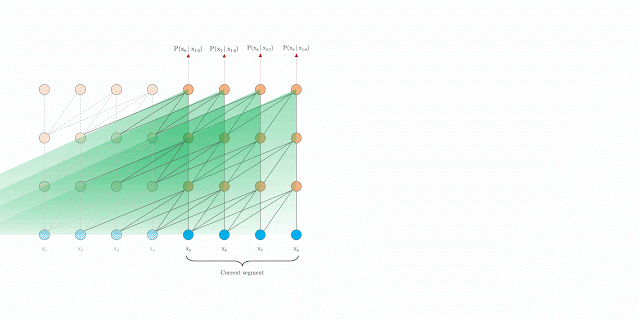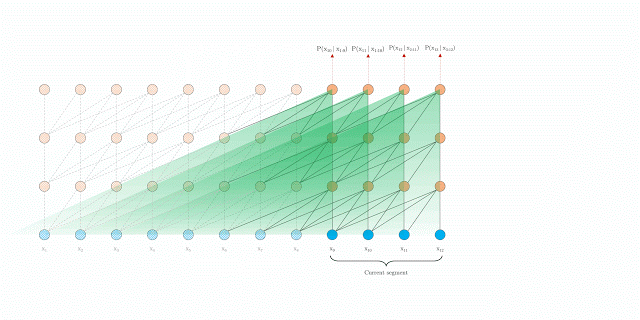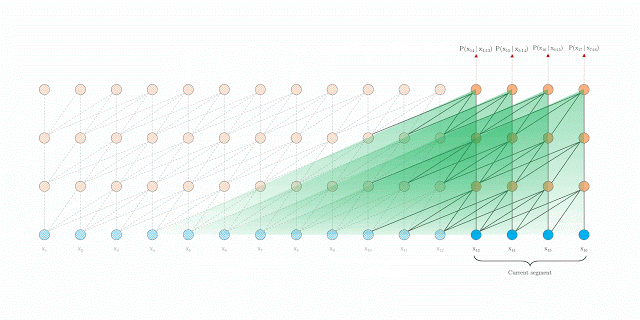
在評(píng)估期間具有segment-level 遞歸的Transformer-XL
此外,Transformer-XL能夠在不需要重新計(jì)算的情況下處理新段中的所有元素,從而顯著提高了速度(將在下面討論)。
結(jié)果
Transformer-XL在各種主要的語言建模(LM)基準(zhǔn)測(cè)試中獲得新的最優(yōu)(SoTA)結(jié)果,包括長序列和短序列上的字符級(jí)和單詞級(jí)任務(wù)。實(shí)驗(yàn)證明, Transformer-XL 有三個(gè)優(yōu)勢(shì):
Transformer-XL學(xué)習(xí)的依賴關(guān)系比RNN長約80%,比vanilla Transformers模型長450%,盡管后者在性能上比RNN好,但由于固定長度上下文的限制,對(duì)于建模長期依賴關(guān)系并不是最好的。
由于不需要重復(fù)計(jì)算,Transformer-XL在語言建模任務(wù)的評(píng)估期間比vanilla Transformer快1800+倍。
由于建模長期依賴關(guān)系的能力,Transformer-XL在長序列上具有更好的困惑度(Perplexity, 預(yù)測(cè)樣本方面更準(zhǔn)確),并且通過解決上下文碎片化問題,在短序列上也具有更好的性能。

Transformer-XL在5個(gè)數(shù)據(jù)集上的結(jié)果
Transformer-XL在5個(gè)數(shù)據(jù)集上都獲得了強(qiáng)大的結(jié)果:在enwiki8上將bpc/perplexity的最新 state-of-the-art(SoTA)結(jié)果從1.06提高到0.99,在text8上從1.13提高到1.08,在WikiText-103上從20.5提高到18.3,在One Billion Word上從23.7提高到21.8,在Penn Treebank上從55.3提高到54.5。
研究人員展望了Transformer-XL的許多令人興奮的潛在應(yīng)用,包括但不限于改進(jìn)語言模型預(yù)訓(xùn)練方法(例如BERT),生成逼真的、長篇的文章,以及在圖像和語音領(lǐng)域的應(yīng)用。
論文中使用的代碼、預(yù)訓(xùn)練模型和超參數(shù)都已全部開源:
https://github.com/kimiyoung/transformer-xl
-
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
140瀏覽量
15162 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25342 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22541
原文標(biāo)題:谷歌升級(jí)版Transformer官方解讀:更大、更強(qiáng),解決長文本問題(開源)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何使用MATLAB構(gòu)建Transformer模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論