 公開機器學習模型代碼可能會有哪些風險?
公開機器學習模型代碼可能會有哪些風險?

作為個人開發者,應不應該將自己的項目或模型、數據等進行開源?公開這些數據有哪些風險?本文作者是斯坦福大學博士,長期從事開源機器學習研究,經常接觸和處理敏感數據,他結合自己的經驗,為這個問題提供了一些建議。
公開機器學習模型代碼可能會有哪些風險?
OpenAI 最近因為創造了多項機器學習新任務的最優性能記錄,但卻不開放源代碼而遭到越來越多的指摘。OpenAI發推表示,“由于擔心這些技術可能被用做惡意目的,不會放出訓練后的模型代碼。“
對OpenAI這個決定的批評之聲不少,比如這樣會對其他團隊重現研究這些研究結果造成阻礙,而研究結果的可重現性是確保研究真實的基礎。而且,這樣做也可能導致媒體對人工智能技術產生一種由于未知而生的恐懼。
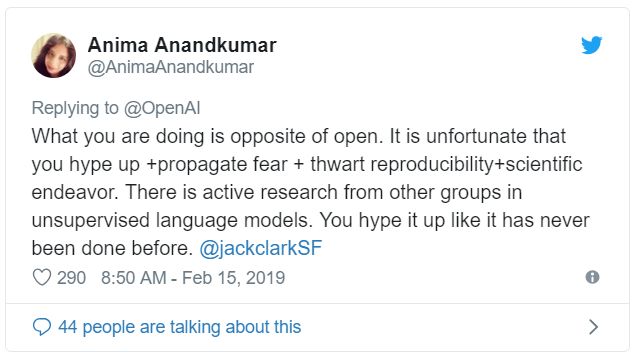
上面這段Twitter引起了我的注意。Anima Anandkumar在彌合機器學習的研究和實際應用之間的差距方面擁有豐富的經驗。我們是亞馬遜AWS的同事,最近還在一起討論了如何將機器學習技術從博士實驗室推向市場的問題。
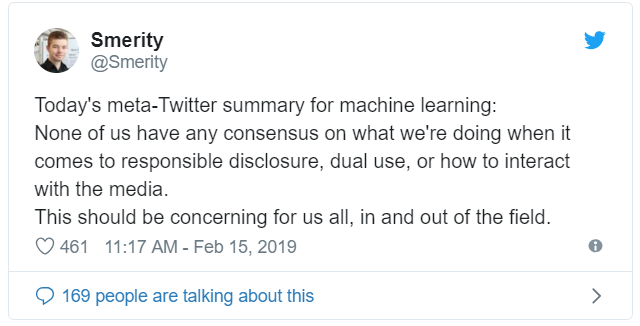
Stephen Merity對社交媒體的回應進行了總結,他表示,機器學習社區在這方面的經驗其實不多:
OpenAI不公開模型源代碼是對是錯?這事各位可以自行判斷。不過在我看來,OpenAI在兩個方面做得不夠好,應該就是否可以檢測到虛假內容進行調查,并以多種語言發布模型,以對抗對英語產生的單語種偏見。
對于個人機器學習項目而言,下面給出一些關于是否應該公開發布模型或數據集的決策時的一些常見問題:
在開源我的模型之前是否應該三思?
是的。如果你的模型是基于私有數據構建的,則可以對其進行逆向工程以提取出這些數據。
如果我的模型100%來自公共數據,那我是否還要考慮將模型開源?
是的。如果要在新的語言環境重新發布數據,已發布的數據可能會變成敏感數據,而且,聚合后的數據(包括機器學習模型)可能比分散的各個數據點更加敏感。你需要考慮:重新構建數據或數據模型會產生哪些影響,要不要由我自己或我所在的組織公開發布?
即使單個數據點并非敏感數據,聚合數據被視為敏感也是很常見的情況。這是許多軍事組織的標準做法:當他們匯總來自一組來源的數據時,他們會根據其敏感程度重新評估該匯總信息。聚合通常是統計學或無監督機器學習的結果,但是基于該數據構建的監督模型同樣適用。
所以,你應該經常自問:我的模型中的聚合數據是否比單個數據點更為敏感?
我應該如何評估開源風險?
在安全性方面考慮,可以將每個策略視為“可被攻破的”。風險防范的基本目標是使攻破某些安全措施的成本高于被保護數據的價值。
所以要考慮的問題是,從你的研究論文中復制模型的成本,是否值得為那些想要出于負面目的使用這些技術的人付出這樣的努力?應該要明確這一點。這是決定是否將模型開源的一個重要因素。
我最近與Facebook進行了長時間的會談,討論的是出任一個職位,專門負責發現假新聞。從一個行內人的角度來看,我最想知道的是這樣一件事:我能否以編程的方式成功檢測這種模型輸出,以便對抗假新聞?
我認為在Facebook上打擊假新聞是任何人都可以做的最重要的事情之一,來自OpenAI的這項研究將會對此有所幫助。而且,如果能夠創建一個可以識別生成內容的模型池,那么假新聞可能會更難以蒙混通過自動檢測系統。
如果你能夠定量地證明,對項目數據的惡意使用可以進行更容易/更難的打擊,這也將是你做出是否開源的決策過程中的另一個重要因素。
這算是機器學習中的新問題嗎?
其實不算是,你可以從過去的經驗中學到很多東西。
如果你面臨類似的困境,請尋找具有深度知識的人來討論受影響最大的社區(最好是來自該社區內部的人士),以及過去遇到類似的機器學習問題相關問題的人。
我是否應該平衡機器學習的負面應用和正面應用?
是的。發布具有積極應用意義的模型,很容易對世界產生積極影響。而限制具有許多負面應用領域的模型的發布,很難對世界產生積極影響。
這其實是OpenAI的另一個失敗之處:缺乏多樣性。OpenAI比任何其他研究團隊都更多地發布了僅適用于英語模型和研究成果。從全球來看,英語每天僅占全世界對話的5%。在句子中的單詞順序、標準化拼寫和“單詞”作為機器學習功能單元上,英語是一個異類。
OpenAI的研究依賴于以下三個方面:單詞順序,單詞特征,拼寫一致性。這些研究能夠適用于世界上大多數語言嗎?我們不知道,因為沒有測試。OpenAI的研究確實表明,我們需要擔心這種類型的英語生成內容,但并沒有表明,今天的假新聞的流傳,更有可能通過除英語之外的其他100多種語言進行。
如果你不想進入假新聞等應用程序的灰色區域,那么可以選擇一個本質上更具影響力的研究領域,例如低資源語言中與健康相關的文本的語言模型。
我需要在多大程度上考慮項目應用實例的敏感性?
當我為AWS的命名實體解析服務開發產品時,必須考慮是否要將街道級地址識別為顯式字段,并可能將坐標映射到相應地址。我們認為這本身就是敏感信息,不應該在一般解決方案中進行產品化。
在任何研究項目中都要考慮這一點:是否能夠隱含或明確地識別出模型中的敏感信息?
只是因為其他人都開源了自己的模型,因此我也應該開源嗎?
當然不是,你應該對自己項目的影響力保持一份懷疑。無論你是否贊同OpenAI的決定,都應該做出明智的決定,而不是盲目跟隨他人。
-
人工智能
+關注
關注
1806文章
49008瀏覽量
249289 -
開源
+關注
關注
3文章
3678瀏覽量
43813 -
機器學習
+關注
關注
66文章
8501瀏覽量
134576
原文標題:斯坦福博士:個人開發者要不要開源項目模型和代碼?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論