 麻省理工學院韓松團隊新突破:直接針對目標硬件平臺訓練專用的卷積神經網絡
麻省理工學院韓松團隊新突破:直接針對目標硬件平臺訓練專用的卷積神經網絡
基于讓人工智能可快速大規模布建的需求,自動機器學習(AutoML)和神經網絡架構搜索(NAS,Neural Architecture Search)成為相當受到關注的新領域,NAS 旨在利用算法自動設計出神經網絡,優點是快速且高效,缺點則是需要大量的運算能力,成本昂貴。
麻省理工學院(MIT)電子工程和計算機科學系助理教授韓松與團隊人員蔡涵和朱力耕設計出的 NAS 算法—ProxylessNAS,可以直接針對目標硬件平臺訓練專用的卷積神經網絡(CNN),而且在 1000 類 ImageNet 大規模圖像數據集上直接搜索,僅需 200 個 GPU 小時,如此便能讓 NAS 算法能夠更廣泛的被運用。該論文將在 5 月舉辦的 ICLR(International Conference on Learning Representations)大會上發表。
(來源:Han Lab)
AutoML 是用以模型選擇、或是超參數優化的自動化方法,而 NAS 屬于 AutoML 概念下的一個領域,簡單來說,就是用“神經網絡來設計神經網絡”,一來好處是可以加速模型開發的進度,再者,NAS 開發的神經網絡可望比人類工程師設計的系統更加準確和高效,因此 AutoML 和 NAS 是達成 AI 普及化遠景的重要方法之一。
DeepTech 采訪了韓松,他表示,AutoML 是個很有前景的方向,架構搜索只是 AutoML 的一部分,它能自動化地找到一些過去人類探索不到的結構,反過來幫助人們設計高效的模型。然而,過去 NAS 算法的硬件效率有待提高:搜索過程需要很久的時間、而且搜出的模型的推理速度難以保證。NAS 和硬件結合,能帶來很多新的設計策略。
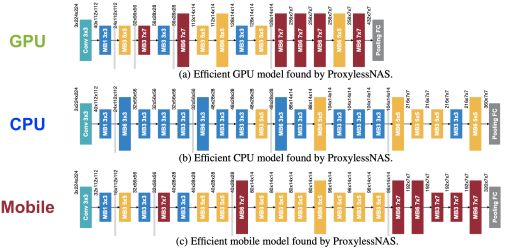
圖|ProxylessNAS為硬件定制專屬的高效神經網絡架構,不同硬件適合不同的模型。(來源: https://arxiv.org/pdf/1812.00332.pdf)
大幅減少計算成本
舉例來說,谷歌所開發的 NAS 算法,需要運行在 GPU 上 4.8 萬個小時,才能生成一個用來做圖像分類或檢測任務的 CNN。當然,谷歌擁有龐大的 GPU 數量和其他專用硬件的資源,這對許多其他人來說是遙不可及的方法。而這就是 MIT 研究人員希望解決 NAS 計算昂貴的問題。他們提出的 ProxylessNAS 算法,僅需 200 個 GPU 小時,就可以在 1000 類 ImageNet 的大規模圖像數據集上直接進行搜索,換算下來,比谷歌的 48,000 GPU 小時,快了 240 倍。而且,ProxylessNAS 可以針對特定的目標硬件平臺上定制專屬的深度學習模型,使其不僅準而且運行速度快。
“主要目標是實現人工智能在各種硬件平臺上的普及,在特定硬件上提供“一鍵加速”的解決方案,幫助 AI 專家和非 AI 專家、硬件專家和非硬件專家有效率地設計又準又快的神經網絡架構,”韓松說。同時,他也強調,NAS 算法永遠不會取代人類工程師,“目的是減輕設計和改進神經網絡架構所帶來的重復性和繁瑣的工作”。
圖|MIT 電子工程和計算機科學系助理教授韓松(來源:https://songhan.mit.edu/)
路徑級二值化和修剪
在該研究中,他們的做法是刪除非必要性的神經網絡設計組件,借此縮短計算時間、減少和內存開銷來運行 NAS 算法。另一項創新則是讓每個輸出的 CNN 在特定硬件平臺上(CPU、GPU 和移動設備)的運行效率比使用傳統方法所設計的模型來得快速。在測試中,研究人員的 CNN 在手機上的測量速度,比相似精度的 MobileNet-V2 快了 1.8 倍。

圖|硬件平臺上架構搜索過程 Demo (來源:韓松團隊)
CNN 能連接不同層(layer)的人工神經網路,受到大腦處理影像的視覺皮質(visual cortex)組織啟發,適合處理視覺方面的任務,是計算機視覺領域十分流行的架構。一個 CNN 架構是由多個可調整參數的計算層(稱為“過濾器”),以及這些過濾器之間可能的連接所組成。
這種連接方式多種多樣,由于可以選擇的架構數量(稱為“搜索空間”search space)非常龐大,所以想應用 NAS 在海量圖像數據集上創建一個神經網絡,計算量總是個很大的問題,所以工程師通常在較小的代理數據集上運行 NAS,再把將訓練好的 CNN 遷移到目標任務上,但是,這種方法降低模型的準確性,此外,把一樣的模型架構套用在所有的硬件平臺,也難以發揮各種硬件的最佳效率。
研究人員直接在 ImageNet 大型數據集上訓練和測試他們開發的新 NAS 算法,首先,他們創建一個搜索空間,包含了所有可能的 CNN“路徑”(路徑是指層和過濾器如何連接來處理數據),讓 NAS 算法可以自由尋找出一個最佳架構。
這種方法通常把所有可能的路徑存儲在內存中,如果用傳統的架構搜索辦法直接在千類 ImageNet 搜索,就會超過 GPU 內存的限制。為了解決此問題,研究人員利用了一種稱為“路徑級二值化”(path-level binarization)的技術,一次只在內存中存放一個采樣路徑,大幅節省內存的消耗。
接著,他們將這種二值化與“路徑級修剪”(path-level pruning)結合,通常該技術是用來學習神經網絡中有哪些神經元(neuron)可以被刪除,而且不會影響輸出。不過,研究人員 NAS 算法是采用修剪整個路徑以取代丟掉神經元,如此能夠完全改變神經網絡的架構。
在訓練過程中,所有路徑最初都被給予相同的選擇概率,然后,該算法跟蹤這些路徑,并記下輸出的準確性和損失,進而調整路徑的概率,借此優化準確性和效率。最后,該算法修剪掉所有低概率的路徑,僅保留最高概率的路徑,形成最終版的 CNN 架構。
圖|MIT News 報道韓松團隊新的神經網絡架構搜索算法(來源:MIT News)
為硬件定制網絡結構
另一項重要創新就是使 NAS 算法“hardware-aware”,也就是說,它會為一個硬件平臺量身定制專用的網絡結構,使得推理的延遲更低。
韓松解釋,hardware-aware 是指 NAS 搜出來的模型不僅準確率高,而且在硬件實測的速度也要快,使得搜出來的模型容易落地。然而,為了量測移動設備的模型推理延遲,大公司的作法是利用大量的手機來實測,成本很高;而 ProxylessNAS 則是給延遲建模,這樣可以讓延遲可導(make latency differentiable),便于對延遲進行端到端的優化,而且只要使用一臺手機,成本低、精度誤差小于 1 毫秒。
對于網絡中的每個所選層,算法利用上述的延遲預測模型來采樣,然后使用這些信息設計出一個快速運行的架構,同時實現高精度。在實驗中,研究人員的 CNN 在移動設備上的運行速度幾乎是現有 MobileNet-V2 模型的 2 倍。
韓松也提到一個有趣的結果,有些卷積核結構曾被誤以為效率太低,但在研究人員的測試中,這些架構在某些硬件上是高效的。
他指出,比如 7x7 這樣的大 卷積核最近幾年被比較少被人使用,因為 3 個 3x3 卷積核和 1 個 7x7 卷積核有同樣的感受野(receptive field),而 3 個 3x3 卷積核有 27 個權重,1 個 7x7 卷積核有 49 個權重,仿佛 7x7 不如 3 個 3x3 能讓模型更小。
但實際在 GPU 上 invoke kernel call 的代價很高,執行多個小型過濾器不如執行單個大型過濾器效率高,大的 kernel call 更適合 GPU 這樣并行度高的硬件。“所以在 GPU 上,ProxylessNAS 在較深的層自動選取了大量 7x7 的卷積核,這是很有意思的,”他說。
GPU 的并行運算特性能夠同時進行多個計算,因此,執行單個大型過濾器時,反而比處理多個小型過濾器更高效。“這打破了過去的想法”,“搜索空間越大,可以找到的內容就越多。你不知道某個東西是否會比過去人類經歷表現得更好,那就讓 AI 來探索,”韓松說。
他進一步指出,類似例子在量化中也有體現,如他們最近的工作 HAQ: Hardware-aware Automated Quantization (CVPR 19 oral paper) 發現,不同硬件,如邊緣設備(edge device)和云端設備(cloud device),對量化策略的偏好是不同的。不同層在不同硬件上所需的比特數也不一樣,有些層是計算受限,有些層是內存受限;在這樣大的設計空間,人類給每種網絡、每種硬件訂制專屬的量化策略費時費力,基于學習的策略可以做得更好。
他認為,這也說明研究 specialization 和 domain-specific hardware architecture 的重要性。最近越來越多好的深度學習工作都是算力推動的,比如用于自然語言預訓練的 Bert。很多場景落地也需要低功耗的硬件支持,比如端上智能和 AIoT。所以未來算法和算力的協同研究是值得關注的方向。
幫助人類減輕做瑣事或工作的負擔,一直是大家對 AI 的期望。這也就是為什么 AutoML 和 NAS 受到重視的原因之一,所以如果要讓 NAS 普及,除了克服上述的計算成本高之外,還有哪些需要一步改善的問題?面對這個提問,韓松給了兩個很明確的方向,一是設計空間(design space)的設計,目前的 NAS 性能好壞很大程度依賴設計空間的選取,這部分還有很多人為的經驗。二是對速度和資源的優化,為了讓 NAS 更容易在工業界落地,有兩個條件:搜索的過程占用的計算資源要低,搜索出的模型硬件效率要高——最終實現讓硬件效率和算法性能同步提升。
-
神經網絡
+關注
關注
42文章
4785瀏覽量
101273 -
機器學習
+關注
關注
66文章
8453瀏覽量
133152 -
數據集
+關注
關注
4文章
1210瀏覽量
24861
原文標題:麻省理工學院韓松團隊新突破:比傳統方法快240倍,讓神經網絡變"輕"、跑更快
文章出處:【微信號:deeptechchina,微信公眾號:deeptechchina】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
加州理工學院開發出超100GHz時鐘速度的全光計算機
麻省理工學院研發全新納米級3D晶體管,突破性能極限
麻省理工學院推出新型機器人訓練模型
美國佐治亞理工學院一行蒞臨達實智能調研
bp神經網絡和卷積神經網絡區別是什么
麻省理工學院研發RoboGrocery系統,雜貨店自動化裝袋新篇章
感謝東莞理工學院對我司導熱系數測試儀的認可

麻省理工與Adobe新技術DMD提升圖像生成速度
霍尼韋爾與南方泵業開展戰略合作,四川成都一家紅外熱成像專用圖像處理芯片服務商完成A+輪融資

瑞士蘇黎世聯邦理工學院新型四足機器人單腿完成開關門、移動任務
麻省理工學院開發出新的RFID標簽防篡改技術





 工商網監
工商網監
評論