") Facebook 人工智能團隊已經(jīng)創(chuàng)建并正在開放源代碼 PyTorch Biggraph
Facebook 人工智能團隊已經(jīng)創(chuàng)建并正在開放源代碼 PyTorch Biggraph
有效處理大規(guī)模圖對于促進人工智能的研究和應(yīng)用至關(guān)重要,但特別是在工業(yè)應(yīng)用中的圖,包含數(shù)十億個節(jié)點和數(shù)萬億個邊,這超出了現(xiàn)有嵌入系統(tǒng)的能力。
因此,F(xiàn)acebook 人工智能團隊已經(jīng)創(chuàng)建并正在開放源代碼 PyTorch Biggraph(PBG)。
PBG 是一個用于學習大規(guī)模圖嵌入的分布式系統(tǒng),特別適用于處理具有多達數(shù)十億實體和數(shù)萬億條邊的大型網(wǎng)絡(luò)交互圖。它在 2019 年的 SysML 會議上發(fā)表的大規(guī)模圖嵌入框架論文中提出。
PBG 比常用的嵌入軟件更快,并在標準基準上生成與最先進模型質(zhì)量相當?shù)那度搿S辛诉@個新工具,任何人都可以用一臺機器或多臺機器并行地讀取一個大圖并快速生成高質(zhì)量的嵌入。
PBG 對傳統(tǒng)的多關(guān)系嵌入系統(tǒng)進行了多次修改,使其能夠擴展到具有數(shù)十億個實體和數(shù)萬億邊的圖。PBG 使用圖分區(qū)來在單個機器或分布式環(huán)境中訓練任意量級的嵌入。研究人員在通用基準測試中展示了與現(xiàn)有嵌入系統(tǒng)相當?shù)男阅埽瑫r允許在多臺機器上擴展到任意大的圖和并行化。他們在幾個大型社會網(wǎng)絡(luò)圖以及完整的 Freebase 數(shù)據(jù)集上訓練和評估嵌入,其中包含超過 1 億個實體和 20 億條邊。
具體而言,PBG 通過攝取圖的邊列表來訓練輸入圖,每條邊由其源實體和目標實體以及可能的關(guān)系類型進行標識。它為每個實體輸出一個特征向量(嵌入),試圖將相鄰實體放置在向量空間中彼此靠近,同時將未連接的實體分開。因此,具有相似鄰近分布的實體最終將位于附近位置。
可以使用在訓練中學習的參數(shù)(如果有的話),用不同的方法配置每種關(guān)系類型來計算這個“接近度得分(proximity score)”,這允許在多個關(guān)系類型之間共享相同的基礎(chǔ)實體嵌入。
其模型的通用性和可擴展性使得 PBG 能夠從嵌入文獻的知識圖譜中訓練出多種模型,包括 TransE、RESCAL、DistMult 和 ComplEx。
PBG 的設(shè)計考慮到了規(guī)模化,并通過以下方式實現(xiàn):
圖分區(qū)(graph partitioning),這樣模型就不必完全加載到內(nèi)存中;
每臺機器上的多線程計算;
跨多臺機器的分布式執(zhí)行(可選),所有機器同時在圖的不相交部分上運行;
批量負采樣(batched negative sampling),允許處理的數(shù)據(jù)為> 100 萬邊/秒/機器。
作為一個示例,F(xiàn)acebook 還發(fā)布了包含 5000 萬維基百科概念的 Wikidata 圖的首次嵌入版本,該圖用于 AI 研究社區(qū)中使用的結(jié)構(gòu)化數(shù)據(jù)。這些嵌入是用 PBG 創(chuàng)建的,可以幫助其他研究人員在維基數(shù)據(jù)概念上執(zhí)行機器學習任務(wù)。
需要注意的是,PBG不適用于小規(guī)模圖上具有奇怪模型的模型探索,例如圖網(wǎng)絡(luò)、深度網(wǎng)絡(luò)等。
安裝步驟及更多信息,請參考 GitHub 相關(guān)介紹和 PyTorch-BigGraph 文檔:
https://github.com/facebookresearch/PyTorch-BigGraph
https://torchbiggraph.readthedocs.io/en/latest/
建立數(shù)十億個節(jié)點的嵌入圖

圖是表示多種數(shù)據(jù)類型的核心工具。它們可以用來對相關(guān)實體的網(wǎng)絡(luò)進行編碼,例如關(guān)于世界的事實。例如,像 Freebase 這樣的知識庫具有不同的實體(如“Stan Lee”和“New York City”),作為描述它們之間關(guān)系的節(jié)點和邊(例如“出生于”)。
圖嵌入方法通過優(yōu)化目標來學習圖中每個節(jié)點的向量表示,即具有邊的節(jié)點對的嵌入比沒有共享邊的節(jié)點對更接近,這類似于 word2vec 等詞嵌入在文本上的訓練方式。
圖嵌入是一種無監(jiān)督學習,因為它們只使用圖結(jié)構(gòu)學習節(jié)點的表示,而不使用基于任務(wù)的節(jié)點“標簽”。與文本嵌入一樣,這些表示可用于各種下游任務(wù)。
超大規(guī)模圖形嵌入
當前,超大規(guī)模圖形有數(shù)十億個節(jié)點和數(shù)萬億條邊,而標準的圖嵌入方法不能很好地擴展到對超大規(guī)模圖的操作,這主要有兩大挑戰(zhàn):首先,嵌入系統(tǒng)必須足夠快,以便進行實際的研究和生產(chǎn)使用。例如,利用現(xiàn)有的方法,訓練一個具有萬億條邊的圖可能需要幾周甚至幾年的時間。
另外,存儲也是一大挑戰(zhàn)。例如,嵌入每個節(jié)點具有 128 個浮點參數(shù)的 20 億個節(jié)點,這需要 1TB 的數(shù)據(jù),超過了商用服務(wù)器的內(nèi)存容量。
PBG 使用圖的塊分區(qū)來克服圖嵌入的內(nèi)存限制。節(jié)點被隨機劃分為 P 分區(qū),這些分區(qū)的大小可以使內(nèi)存容納兩個分區(qū)。然后,根據(jù)邊的源節(jié)點和目標節(jié)點,將邊劃分為 P2 簇(Buckets)。
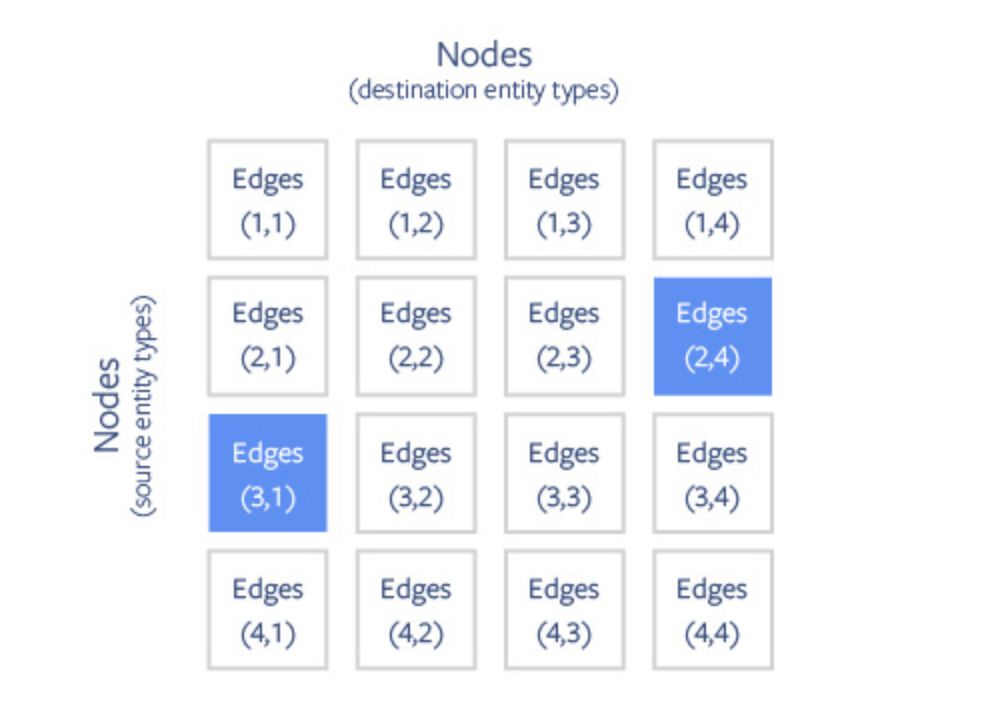
大規(guī)模圖的 PBG 分區(qū)方案。節(jié)點被劃分為 P 分區(qū),分區(qū)大小適合內(nèi)存。邊根據(jù)其源節(jié)點和目標節(jié)點的分區(qū)劃分為簇。在分布式模式下,可以并行執(zhí)行具有非重疊分區(qū)的多個存儲簇(如藍色方塊所示)。
節(jié)點和邊進行分區(qū)之后,就可以一次在一個簇上執(zhí)行訓練。bucket(i,j)的訓練只需要將節(jié)點分區(qū) i 和 j 嵌入存儲在內(nèi)存中。
PBG 提供了兩種方法來訓練分區(qū)圖數(shù)據(jù)的嵌入。在單機訓練中,嵌入件和邊在不使用時被交換到磁盤上。在分布式訓練中,嵌入分布在多臺機器的內(nèi)存中。
分布式訓練
PBG 使用 PyTorch 并行化原語(parallelization primitives)進行分布式訓練。由于一個模型分區(qū)一次只能由一臺機器調(diào)用,因此一次最多可以在 P/2 機器上訓練嵌入。只有當機器需要切換到新的簇時,模型數(shù)據(jù)才會進行通信。對于分布式訓練,我們使用經(jīng)典參數(shù)服務(wù)器模型,同步表示不同類型邊的共享參數(shù)。
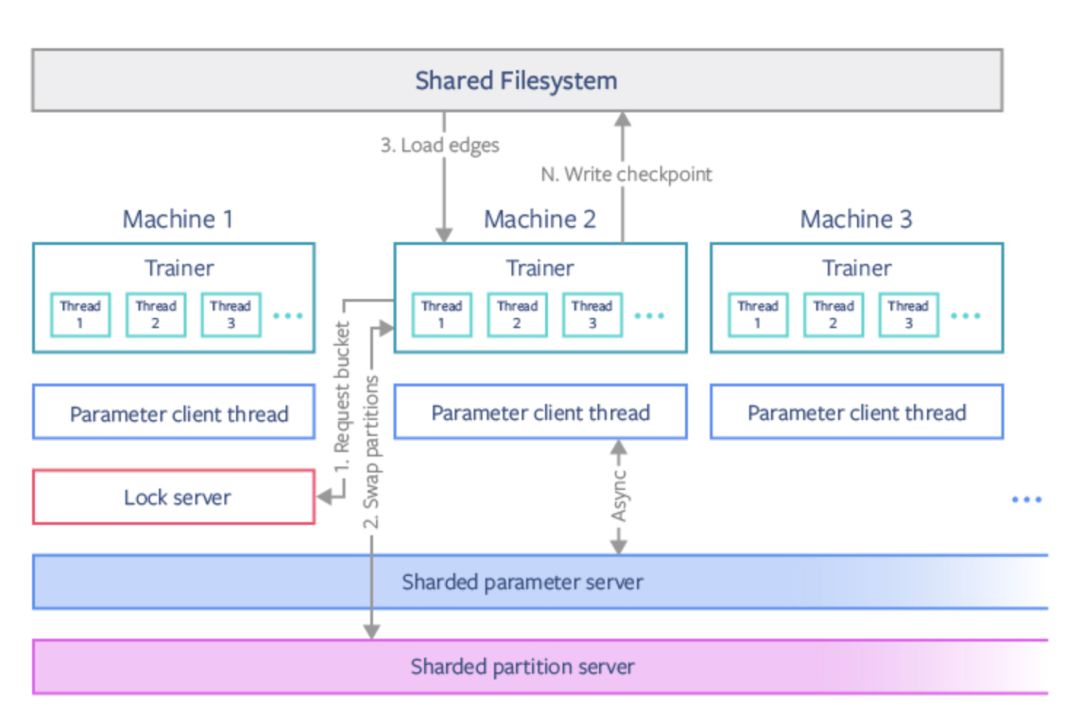
APBG 分布式訓練體系結(jié)構(gòu)。我們使用鎖服務(wù)器協(xié)調(diào)機器在不相交的存儲簇上進行訓練。分區(qū)模型參數(shù)通過分片分區(qū)服務(wù)器交換,共享參數(shù)通過分片參數(shù)服務(wù)器異步更新。
負采樣
圖嵌入和文本嵌入相似,構(gòu)造隨機的“假”邊與真正的邊一起作為負訓練樣例。這大大加快了訓練速度,因為每個新樣本只需更新一小部分權(quán)重。通常,這些消極的例子是由隨機源節(jié)點或目標節(jié)點的“腐蝕”真邊構(gòu)成的。然而,我們發(fā)現(xiàn)對標準負抽樣的一些修改對于大規(guī)模圖是必要的。
首先,我們注意到在傳統(tǒng)的圖嵌入方法中,幾乎所有的訓練時間都花在了負邊上。我們利用函數(shù)形式的線性特點,重用一批 N 個隨機節(jié)點,生成 N 個訓練邊的損壞負樣本。與其他嵌入方法相比,此技術(shù)允許我們以很小的計算成本在每個真邊上訓練許多負示例。
我們還發(fā)現(xiàn),為了生成在各種下游任務(wù)中有用的嵌入,一種有效的方法是破壞邊,將 50% 的節(jié)點和另外 50% 的節(jié)點(根據(jù)其邊數(shù)進行采樣)混合在一起。
最后,我們引入了“實體類型”的概念,它限制了如何使用節(jié)點構(gòu)造負樣本。例如,考慮一個包含歌曲、藝術(shù)家和流派節(jié)點的圖,并假設(shè)藝術(shù)家和歌曲之間存在“創(chuàng)作”關(guān)系。如果我們?yōu)檫@個關(guān)系統(tǒng)一抽樣源實體,我們將絕大多數(shù)抽樣歌曲(因為歌曲比藝術(shù)家多),但這些不是有效的潛在邊(因為歌曲只能由藝術(shù)家制作)。PBG 可以基于關(guān)系的實體類型限制構(gòu)造哪些負樣本。
評估 PyTorch-BigGraph
為了評估 PBG 的性能,我們使用了公開的 Freebase 知識圖,它包含超過 1.2 億個節(jié)點和 27 億條邊。我們還使用了一個較小的 Freebase 圖子集(FB15K),它包含 15000 個節(jié)點和 600000 條邊,通常用作多關(guān)系嵌入方法的基準。

T-SNE 繪制的由 PBG 訓練的 Freebase 知識圖嵌入。國家、數(shù)字和科學期刊等實體也有類似的嵌入。
可以看出,對于 FB15k 數(shù)據(jù)集,PBG 和最新的嵌入方法性能相當。

圖:FB15K 數(shù)據(jù)集的鏈路預測任務(wù)上嵌入方法的性能。PBG 使用其模型來匹配 transe 和復雜嵌入方法的性能。我們測量了 MRR,并在 FB15K 測試集上對鏈接預測進行 hit@10統(tǒng)計。Lacroix 等人使用非常大的嵌入維數(shù)實現(xiàn)更高的 MRR,我們可以在 PBG 中采用同樣的方法,但這里暫不涉及。
下面,我們使用 PBG 對完整的 Freebase 圖訓練嵌入。現(xiàn)代服務(wù)器可以容納這個規(guī)模的數(shù)據(jù)集 但 PGB 分區(qū)和分布式執(zhí)行既節(jié)約了內(nèi)存,也縮短了訓練時間。我們發(fā)布了 Wikidata 的首次嵌入,這是一個相似數(shù)據(jù)中更新的知識圖。

我們還評估了幾個公開的社交圖數(shù)據(jù)集的 PBG 嵌入,發(fā)現(xiàn) PBG 優(yōu)于其他競爭方法,并且分區(qū)和分布式執(zhí)行減少了內(nèi)存使用和培訓時間。對于知識圖、分區(qū)或分布式執(zhí)行使得訓練對超參數(shù)和建模選擇更加敏感。然而對于社交圖來說,嵌入質(zhì)量似乎對分區(qū)和并行化選擇并不敏感。
利用分布式訓練的優(yōu)勢進行嵌入
PBG 允許 AI 社區(qū)為大規(guī)模圖(包括知識圖譜)以及其他如股票交易圖、在線內(nèi)容圖和生物數(shù)據(jù)圖訓練嵌入,而無需專門的計算資源(如 GPU 或大量內(nèi)存)。我們還希望 PBG 將成為小型公司和機構(gòu)的有用工具,他們可能擁有大型圖數(shù)據(jù)集,但沒有將這些數(shù)據(jù)應(yīng)用到其 ML 應(yīng)用程序的工具。
雖然我們在 Freebase 等數(shù)據(jù)集上演示了 PBG,但 PBG 真正的設(shè)計意圖是處理比此圖大 10~100 倍的圖。我們希望這能鼓勵實踐者發(fā)布和試驗更大的數(shù)據(jù)集。計算機視覺(通過對標簽的 Deep Learning 來改進圖像識別質(zhì)量)和自然語言處理(word2vec、BERT、Elmo)的最新突破是對海量數(shù)據(jù)集進行未知任務(wù)預訓練的結(jié)果。我們希望通過對大規(guī)模圖的無監(jiān)督學習,最終能夠得到更好的圖結(jié)構(gòu)化數(shù)據(jù)推理算法。
-
Facebook
+關(guān)注
關(guān)注
3文章
1429瀏覽量
55009 -
人工智能
+關(guān)注
關(guān)注
1796文章
47704瀏覽量
240352 -
開源
+關(guān)注
關(guān)注
3文章
3408瀏覽量
42719 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13370
原文標題:Facebook開源圖嵌入“神器”:無需GPU,高效處理數(shù)十億級實體圖形 | 極客頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Tomcat開放源代碼的Web應(yīng)用服務(wù)器





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論